用Hbase协处理器Observer实现二次索引
需求
有一张uuid表,column为 phone,要求在插入uuid数据的时候,会有一个通过phone指向uuid的索引表。本文通过Observer的的动态装载协处理方式实现
实现
HBase创建uuid表和phone表
create 'phone','f1' create 'uuid','f1'
maven依赖
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
</dependencies>
Java代码
package com.me.hbase.Coprocessor;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.List;
public class TextObserver extends BaseRegionObserver {
static Connection connection = null;
static Table table = null;
private static final String FROM_FAMAILLY_NAME = "f1";
private static final String FROM_QUALIFIER_NAME = "phone";
private static final String TO_TABLE_NAME = "phone";
private static final String TO_FAMAILLY_NAME = "f1";
private static final String TO_QUALIFIER_NAME = "uuid";
static{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","slave2:2181");
try {
connection = ConnectionFactory.createConnection(conf);
table = connection.getTable(TableName.valueOf(TO_TABLE_NAME));
} catch (Exception e) {
e.printStackTrace();
}
}
public void prePut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final Durability durability) throws IOException {
try {
//通过put对象获取插入数据的rowkey
byte[] rowBytes = put.getRow();
String rowkey = Bytes.toString(rowBytes);
List<Cell> list = put.get(Bytes.toBytes(FROM_FAMAILLY_NAME), Bytes.toBytes(FROM_QUALIFIER_NAME));
if (list == null || list.size() == 0) {
return;
}
Cell cell2 = list.get(0);
//通过cell获取数据值
String stringValue = Bytes.toString(CellUtil.cloneValue(cell2));
//创建put对象,将二次索引插入进phone表
Put put2 = new Put(stringValue.getBytes());
put2.addColumn(Bytes.toBytes(TO_FAMAILLY_NAME), Bytes.toBytes(TO_QUALIFIER_NAME), rowkey.getBytes());
table.put(put2);
table.close();
} catch (Exception e1) {
return ;
}
}
}
java代码打包之后,放入HDFS
hdfs dfs -put /jar包路径..../hbase_observer-1.0-SNAPSHOT.jar /observer.jar hdfs dfs -chmod 777 /observer.jar
Hbase动态装载协处理器
alter 'uuid', METHOD=> 'table_att', 'Coprocessor'=>'hdfs://master:9000/observer.jar|com.me.hbase.Coprocessor.TextObserver|1001'
试验
hbase执行如下命令
//禁用 disable 'uuid' //安装 alter 'uuid', METHOD=> 'table_att', 'Coprocessor'=>'hdfs://master:9000/observer.jar|com.me.hbase.Coprocessor.TextObserver|1001' //启用 enable 'uuid' //试验插入数据 put 'uuid','uuid1','f1:phone','13811111111'
'Coprocessor'=>'hdfs://master:9000/observer.jar|com.me.hbase.Coprocessor.TextObserver|1001'参数说明:
- 一共四个参数,用|分割,最后一个params可省略
- jar_file_path,Java代码打成的jar包存放的绝对路径,最好是HDFS路径
- observer_class_path,observer类的包名加类名
- priority,优先级,就用固定的1001即可
- params,传递给observer的参数信息,相当于map,例如:id=123,name='hahaha',age=18
安装注意:
一定要把参数填对,路径填准确,不然会出现报如下错误:
ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Class com.me.hbase.Coprocessor.TextObserver cannot be loaded Set hbase.table.sanity.checks to false at conf or table descriptor if you want to bypass sanity checks at org.apache.hadoop.hbase.master.HMaster.warnOrThrowExceptionForFailure(HMaster.java:1819) at org.apache.hadoop.hbase.master.HMaster.sanityCheckTableDescriptor(HMaster.java:1680) at org.apache.hadoop.hbase.master.HMaster.modifyTable(HMaster.java:2207) at org.apache.hadoop.hbase.master.MasterRpcServices.modifyTable(MasterRpcServices.java:1188) at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:58547) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2339) at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:123) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:188) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:168)
测试结果:
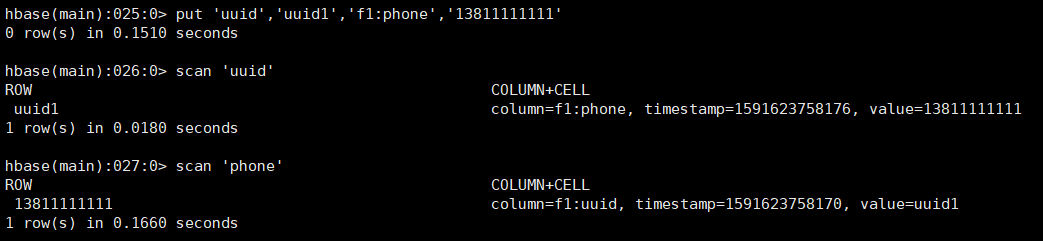
可以看到向uuid插入一条数据的时候,phone表自动会加一条指向uuid rowkey的数据
卸载协处理器方式
//禁用 disable 'uuid' //卸载 alter 'uuid',METHOD=>'table_att_unset',NAME=>'coprocessor$1' //启用 enable 'uuid'
扩展理论知识
Hbase 协处理器分2种:
1.Observer,类似于传统数据库的触发器。Observer会在固定的事件发生时被调用,比如:put操作之前有钩子函数 prePut,该函数在 put 操作
执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
2.Endpoint,类似于传统数据库的存储过程。客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执 行,势必效率低下。
协处理器详细理论:https://www.cnblogs.com/liuwei6/p/6837674.html
HBase Observer协处理装载方式分2种:
1.静态装载Coprocessor
如果一个Coprocessor是静态装载的,要卸载它就需要重启HBase。
2.动态装载Coprocessor
动态装载Coprocessor的一个优势就是不需要重启HBase。不过动态装载的Coprocessor只是针对某个表有效。因此,动态装载的Coprocessor又被称为表级Coprocessor。
详情参考:https://www.jianshu.com/p/d56584c45401

 浙公网安备 33010602011771号
浙公网安备 33010602011771号