
python3-基础8
模块与包
什么是模块
模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
#在python中,模块的使用方式都是一样的,但其实细说的话,模块可以分为四个通用类别:
1 使用python编写的.py文件,是被导入使用的
2 已被编译为共享库或DLL的C或C++扩展
3 把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包),包就是包含init的文件夹,也是被导入使用的
4 使用C编写并链接到python解释器的内置模块
导入模块干了那些事
1、执行源文件
2、以源文件为基础产生一个全局名称空间,如果调用源空间中的函数,用.就行,作用域关系在调用的时候就已经固定了。
3、再当前位置拿到一个模块名,指向2创建的名称空间
import 使用
别名 用 as
1 import spam as sm
2 print(sm.money)
一行中导入多个模块,用逗号隔开
import os,sys,spam
自定义模块、内置模块、第三方模块、包 等等
from ... inmport ... 用法
from...import * # *代表所有(除了横杆开头的名字,如 _money()),一般不建议用,
#也可以在模块开头增加 __all__=['money','x','y'] 来控制*的识别范围,
#_ 和 __all__ 只是对from...import * 有用
#from sys import * 把spam中所有的不是以下划线(_)开头的名字都导入到当前位置
#大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
#优点:使用源文件内的名字时无需加前缀,使用方便
#缺点:容易与当前文件的名称空间内的名字混淆
#可以起别名
# from spam import money as m
==============
'''
查找模块
模块只有在第一次导入时才会执行,之后的导入都是直接引用内存中已经存在的结果
import sys
print(sys.modules) #一个字典,存放的是已经加载到内存的模块
print(sys.path) #一个列表,存放的是当前执行文件的路径
模块的搜索路径
import sys
先从哪里找?
先从内存里找,然后再去硬盘上找
python文件修改完后一定要重启程序,重新加载一遍才会生效
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
比如找abc\abc.py模块,若内存中和硬盘中都找不到,那就要去sys.path中找,这就需要吧abc.py所在的目录路径添加到sys.path里去
sys.path.append(r'C:\Users\Administrator\PycharmProjects\python\abc') #将目录添加到最后
sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\python\abc') #将目前插到最前面,找到的更快
注意:自定义的模块一定不要与python自带的模块名重名
要明确 执行文件是谁,被导入的文件是谁
'''
'''
两种使用方法:
被当做脚本使用
被当做模块使用
__name__
#文件当做脚本运行时__name__等于__main__
#文件当做模块被加载运行时__name__等于模块名
写模块时添加如下代码(只有被当做脚本使用时,才会执行if里的代码):
if __name__ == '__main__':
#当做脚本使用
func1()
func2()
func3()
#导入模块实际上就是导入文件下的 __init__.py 文件
#开发者通过修改 __init__.py 文件,方便使用者调用函数
#1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
#2、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
#3、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
三步:
1、执行文件
2、产生名称空间
3、调用函数
绝对导入与相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
# 绝对导入: 以执行文件的sys.path为起始点开始导入,称之为绝对导入
# 优点: 执行文件与被导入的模块中都可以使用
# 缺点: 所有导入都是以sys.path为起始点,导入麻烦
# 相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入
# 符号: .代表当前所在文件的文件加,..代表上一级文件夹,...代表上一级的上一级文件夹
# 优点: 导入更加简单
# 缺点: 只能在导入包中的模块时才能使用
#注意:
1. 相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包内
2. attempted relative import beyond top-level package # 试图在顶级包之外使用相对导入是错误的,言外之意,必须在顶级包内使用相对导入,每增加一个.代表跳到上一级文件夹,而上一级不应该超出顶级包
软件开发规范:
bin 目录下是执行文件
conf 目录下是控制文件
lib 目录下是本程序需要依赖或开发的功能模块文件
log 目录下是日志文件
db 目录下存放数据文件
core 目录下存放核心的逻辑
Readme
示例 :
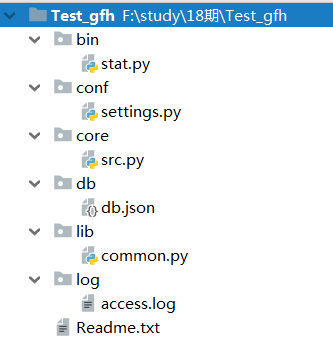
1 ############### 2 #===============>star.py 3 import sys,os 4 ##该文件所在位置:D:\第1层\第2层\第3层\第4层\第5层\test_gfh.py 5 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 获取当前运行脚本的绝对路径 6 ''' 7 如果直接在python console 中或者命令行中运行上面代码,则会报如下错误: 8 NameError: name '__file__' is not defined 9 10 原因是:‘__file__'这个参数代表的是python解释器正在执行的脚本文件,如果直接在命令行运行上面两行代码,则python解释器找不到正在执行的脚本文件,即我们将它写在一个脚本文件中,再在解释器中运行这个脚本文件就ok了 11 12 ''' 13 sys.path.append(BASE_DIR) #将路径添加到sys.path 14 15 from core import src 16 17 if __name__ == '__main__': 18 src.run() 19 #===============>settings.py 20 import os 21 22 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 23 DB_PATH=os.path.join(BASE_DIR,'db','db.json') 24 LOG_PATH=os.path.join(BASE_DIR,'log','access.log') 25 LOGIN_TIMEOUT=5 26 27 """ 28 logging配置 29 """ 30 # 定义三种日志输出格式 31 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ 32 '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 33 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' 34 id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' 35 36 # log配置字典 37 LOGGING_DIC = { 38 'version': 1, 39 'disable_existing_loggers': False, 40 'formatters': { 41 'standard': { 42 'format': standard_format 43 }, 44 'simple': { 45 'format': simple_format 46 }, 47 }, 48 'filters': {}, 49 'handlers': { 50 #打印到终端的日志 51 'console': { 52 'level': 'DEBUG', 53 'class': 'logging.StreamHandler', # 打印到屏幕 54 'formatter': 'simple' 55 }, 56 #打印到文件的日志,收集info及以上的日志 57 'default': { 58 'level': 'DEBUG', 59 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 60 'formatter': 'standard', 61 'filename': LOG_PATH, # 日志文件 62 'maxBytes': 1024*1024*5, # 日志大小 5M 63 'backupCount': 5, 64 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 65 }, 66 }, 67 'loggers': { 68 #logging.getLogger(__name__)拿到的logger配置 69 '': { 70 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 71 'level': 'DEBUG', 72 'propagate': True, # 向上(更高level的logger)传递 73 }, 74 }, 75 } 76 77 78 #===============>src.py 79 from conf import settings 80 from lib import common 81 import time 82 83 logger=common.get_logger(__name__) 84 85 current_user={'user':None,'login_time':None,'timeout':int(settings.LOGIN_TIMEOUT)} 86 def auth(func): 87 def wrapper(*args,**kwargs): 88 if current_user['user']: 89 interval=time.time()-current_user['login_time'] 90 if interval < current_user['timeout']: 91 return func(*args,**kwargs) 92 name = input('name>>: ') 93 password = input('password>>: ') 94 db=common.conn_db() 95 if db.get(name): 96 if password == db.get(name).get('password'): 97 logger.info('登录成功') 98 current_user['user']=name 99 current_user['login_time']=time.time() 100 return func(*args,**kwargs) 101 else: 102 logger.error('用户名不存在') 103 104 return wrapper 105 106 @auth 107 def buy(): 108 print('buy...') 109 110 @auth 111 def run(): 112 113 print(''' 114 购物 115 查看余额 116 转账 117 ''') 118 while True: 119 choice = input('>>: ').strip() 120 if not choice:continue 121 if choice == '1': 122 buy() 123 124 125 126 #===============>db.json 127 {"egon": {"password": "123", "money": 3000}, "alex": {"password": "alex3714", "money": 30000}, "wsb": {"password": "3714", "money": 20000}} 128 129 #===============>common.py 130 from conf import settings 131 import logging 132 import logging.config 133 import json 134 135 def get_logger(name): 136 logging.config.dictConfig(settings.LOGGING_DIC) # 导入上面定义的logging配置 137 logger = logging.getLogger(name) # 生成一个log实例 138 return logger 139 140 141 def conn_db(): 142 db_path=settings.DB_PATH 143 dic=json.load(open(db_path,'r',encoding='utf-8')) 144 return dic 145 146 147 #===============>access.log 148 [2017-10-21 19:08:20,285][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功] 149 [2017-10-21 19:08:32,206][MainThread:10900][task_id:core.src][src.py:19][INFO][登录成功] 150 [2017-10-21 19:08:37,166][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在] 151 [2017-10-21 19:08:39,535][MainThread:10900][task_id:core.src][src.py:24][ERROR][用户名不存在]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号