Claude Code 20分钟极速调优指南(附20分钟速查表)
Anthropic 给 Claude Code 的配置文件塞了 125 个以上的选项,但官方文档只写了大概 40 个。
其中 14 个被埋在 Claude.ai 网页里,要点三次才能找到。
还有 4 个,任何文档都没有记载。想找到它们,你得翻 GitHub 的 issues、蹲工程师在 Discord 里不小心说漏嘴,或者凌晨一点去扒 Claude Code 的程序文件。
大多数用户从注册那天起就没改过设置。结果呢?账单越来越贵,回答越来越跑偏,然后他们觉得是 AI 变笨了。
下面这 18 个设置,才是真正决定你 Claude 好用不好用的关键。
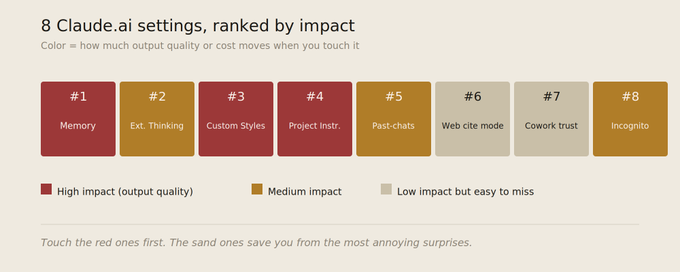
Claude.ai 网页版 8 个。
Claude Code 命令行版 7 个。
API 和后台控制台 3 个。
每个设置都告诉你:在哪儿改、改了有什么用、怎么一步到位。
第一部分:Claude.ai 网页版(8 个设置)
#1 记忆功能:别让 Claude 什么都记
在哪改: Settings -> Capabilities -> Memory
有什么用: 2026 年 3 月,Claude 上了记忆功能,免费用户和 Pro 用户都能用。默认情况下,Claude 觉得什么值得记就记什么。但大多数人不知道,记忆功能有三个重要控制:按项目隔离记忆、排除不想被记的话题、以及随时让 Claude"忘掉"某个话题。
为什么重要: 默认的记忆会"串台"。用了 4-6 周之后,记忆里全是各种零碎的东西——你有一次随口说了句"Python 我习惯用 tab 缩进",Claude 就永远记住了;A 项目的信息跑到 B 项目的对话里去了;之前设定的角色早就过时了还在生效。Claude 拿着错误的"你"的画像来回答,效果当然越来越差。
怎么改:
-
打开按项目隔离记忆:Settings -> Capabilities -> Memory -> Scope per Project。这样一来,项目 A 里的记忆不会跑到项目 B 里去。光这一步就能解决大部分"串台"问题。
-
在排除列表里加上你不想让 Claude 在别的对话里提起的话题。比如:离婚、病情、工资数目、客户名字。这些东西如果不排除,Claude 可能在任何对话里突然冒出来。
-
在任何对话里直接打字让 Claude 忘掉:忘掉你记住的关于[某个话题]的内容
Claude 会去你的记忆库里找到相关内容并删除,不需要进什么菜单或设置页面。
2 扩展思考:不是每个问题都需要"深度思考"
在哪改: 聊天输入框 -> 模型选择下拉菜单 -> Extended Thinking: Off / Light / Full
有什么用: 扩展思考就是让 Claude 在回答之前先"想一想"。Opus 模型默认开着的。这个开关可以按每个对话单独设置,比全局设置优先。
为什么重要: 做数学题、调试代码、制定复杂计划的时候,让 Claude 先想想确实有用。但如果你只是让它总结一下、翻译一下、改个格式、快速查个东西,那就纯属浪费——多等 3-12 秒不说,同样的答案还多花 20-40% 的 token(就是你的钱)。
怎么改: 默认设成 Light(让 Claude 自己判断需不需要深入思考),只在真正遇到难题时才切到 Full。我推荐给很多人试了,第一周就能省下 18-25% 的 Opus 费用。
3 自定义样式:这不是换个"语气",而是给 Claude 定规矩
在哪改: 聊天输入框 -> 样式选择器 -> Create New Style
有什么用: 样式功能一开始只是换个说话风格("正式 / 简洁 / 详解")。但自定义样式其实可以做到更多——它相当于一份"输出合同"。你写一段 200-1500 词的规则,之后每次用这个样式聊天,Claude 都会自动遵守这些规则。
为什么重要: 很多人用样式只是让回答"短一点"。但它的真正威力是:不用每次都重复粘贴同样的要求,就能让 Claude 每次回答都遵守同样的格式。比如:引用用什么格式、哪些词禁止使用、回答必须包含哪些部分、代码用什么语言、最多写多长、要不要追问。
怎么改: 给不同的工作场景各创建一个样式。比如我的:
# Style: Draft for X
Output contract:
- Open with one concrete number or named entity. No "I've been thinking..."
- Sentences under 18 words where possible.
- No em-dashes unless rhythm requires.
- No "delve", "leverage", "robust", "unlock", "game-changing".
- If listing 3+ items, use a hyphen list, not numbered.
- End on a statement, not a question.
If a draft exceeds 280 characters and the user didn't ask for a thread,
say so before answering.
轮换使用三个样式(写帖子用 Draft for X、审代码用 Code review、总结 PDF 用 Summarize PDF),替代了我 80% 以前需要反复粘贴的提示词。
4 项目指令:那个 70% 的人都没填的输入框
在哪改: 打开任意项目 -> 右上角 ⋯ -> Edit project instructions
有什么用: 项目是一个长期工作空间。"项目指令"这个输入框,相当于给项目里所有对话加了一段系统提示词。Anthropic 介绍项目功能时主要宣传的是知识上传,所以大家记住了那个,但同一个页面上的指令框却被忽视了——我见过的项目里,70% 这个框都是空的。
为什么重要: 没填的话,每次开新对话 Claude 都要从零开始了解你的背景。填了之后,就不用每次重新交代了。(比如你可以写:"这是一个投资研究项目,默认保持怀疑态度,一定要展示概率计算,永远不要推荐具体交易,只分析期望值。")
怎么改: 把它当成 Claude 的"说明书"。控制在 400 词以内,写清楚:Claude 扮演什么角色、默认什么态度、格式怎么写、什么不能做。每个月看一遍,删掉过时的内容。
5 搜索历史对话(Pro+ 专属)及搜索技巧
在哪改: Settings → Profile → Search past chats(需要手动开启)
有什么用: 让 Claude 在回答时可以搜索你以前的对话记录。仅限 Pro+ 用户。
为什么重要: 新账号就算升级到 Pro+,这个功能也是默认关着的。打开之后有个关键点:它是按关键词匹配搜索的,不是理解语义的搜索。你说"我们昨天讨论的中国机器人是什么",如果你的历史对话里没有出现过"中国机器人"或者"中国"和"机器人"这两个词,它就搜不到。
怎么改: 先打开它。然后记住正确的搜索方式——用具体的名词,不要用模糊的描述。"Polymarket Iran"能搜到,"我们上周聊的那个东西"搜不到。
6 网络搜索引用方式:别让引用标记毁了你复制的内容
在哪改: 聊天输入框 -> + -> Web search: On / Off
有什么用: 网络搜索可以按每个对话开关,但引用的显示方式由另一个设置决定:Settings -> Capabilities -> Web search citations: Inline / Footnotes / Hidden。
为什么重要: 默认是 Inline(内联引用),就是说引用标记直接插在文字中间。当你把 Claude 的回答复制粘贴到别的地方时,那些标记也跟着复制过去了,但在新地方它们完全没意义。Footnotes(脚注)模式就不一样了——回答干干净净,所有来源列在最后面。
怎么改: 只要你曾经把 Claude 的搜索结果复制到其他地方用过,就切到 Footnotes。只有你永远在 Claude 网页里看回答的,才保留 Inline。
7 受信任文件夹:Cowork 里那个容易被忘的"永久通行证"
在哪改: Settings -> Connectors -> Cowork -> Trusted folders
有什么用: Cowork 功能(2026 年 4 月正式上线)让 Claude 能访问你电脑上的文件夹。默认情况下,每次会话开始前都会问你"是否信任这个文件夹"。受信任文件夹列表就是跳过这个确认的——加进去之后再也不用点了。
为什么重要: 一旦文件夹加入受信任列表,Claude 每次开 Cowork 会话都会不声不响地读取它。如果你三月份测试时随手加了一个文件夹然后忘了,Claude 从那以后每次会话都在偷偷读它。
怎么改: 打开受信任文件夹列表,把不是当前正在用的项目都删掉。这个列表膨胀的速度比你想象的快得多。
8 隐身模式:不只是"隐藏对话"那么简单
在哪改: 侧边栏 -> New incognito chat(或按 Cmd/Ctrl + Shift + N)
有什么用: 隐身对话不会被保存、不会进入记忆、不可搜索、不会用于改善模型。关掉对话就彻底没了。
为什么重要: 很多人以为隐身只是让对话在侧边栏消失。实际上它一次性跳过了四样东西:记忆写入、对话历史保存、历史搜索索引、训练数据 opt-in(如果你开了的话)。
怎么改: 凡是涉及敏感内容的——工资、病情、家庭私事、法律文件、客户信息——都走隐身模式。三个快捷键就搞定,不用想太多。
第二部分:Claude Code 命令行版(7 个设置)
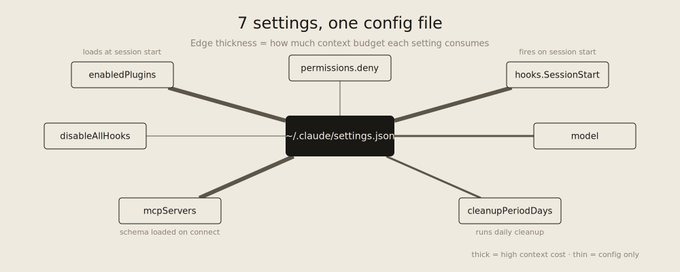
这些设置在 ~/.claude/settings.json(全局)或 .claude/settings.json(项目目录下)里改。项目级设置优先级更高。
Claude Code v2.1.105 里一共有 125+ 个配置项,但真正能让你感受到变化的,就是下面这 7 个。
9 插件管理:关掉比删掉更方便
在哪改: ~/.claude/settings.json -> enabledPlugins
有什么用: 控制哪些已安装的插件在启动时加载。安装插件很方便,卸载却比较麻烦。其实不用卸载,把值改成 false 就行。
为什么重要: 每个开启的插件都会把自己的规则、说明和工具定义加载到你的"上下文额度"里。三个你早就忘了的插件 = 还没开始打字就白烧了 3000-8000 个 token。
我自己查的时候发现开了 14 个插件,现在只留了 4 个。
怎么改:
{
"enabledPlugins": {
"formatter@acme-tools": true,
"deployer@acme-tools": false,
"analyzer@security-plugins": false,
"old-experiment@personal": false
}
}
设成 false 的插件还装着,但不加载。等你真需要的时候,用 /plugin enable name@marketplace 按需开启就行。
10 权限黑名单:有个 bug 你得知道
在哪改: ~/.claude/settings.json -> permissions.deny
有什么用: 禁止 Claude 执行某些操作或读取某些文件。比如:不让它执行 rm -rf(删库跑路命令)、不让它读取 .env(环境变量文件,可能含密码)、不让它在项目外面写文件。
为什么重要: 有个已知的 bug——deny 规则有时候不生效!GitHub 上已经有人报了好几个 issue。最出名的那个(anthropics/claude-code#11544)说的是钩子配置明明写对了却不加载,deny 也存在类似问题。你的配置文件里规则写得清清楚楚,但调试日志显示"0 matchers found"(没找到匹配规则),Claude 照样把文件读了。
怎么改:
{
"permissions": {
"deny": [
"Read(.env)",
"Read(.env.*)",
"Read(**/*secret*)",
"Bash(rm -rf:*)",
"Bash(sudo:*)"
]
}
}
光靠配置文件不够保险,还得在操作系统层面再加一道锁:chmod 600 .env,这样就算 Claude 想读,系统也会拒绝。别光信任 deny 列表,在 Claude Code 里输入 /permissions 检查一下。如果看不到你的规则,重启会话试试。
11 启动钩子:4 行代码帮我砍掉 30% 的上下文浪费
在哪改: ~/.claude/settings.json -> hooks.SessionStart
有什么用: 每次你在某个目录打开 Claude Code 时,SessionStart 钩子就会触发。你可以让它做任何事情:显示环境信息、检查 git 状态、加载说明文件、预热缓存。
为什么重要: 很多人往 CLAUDE.md 里塞了太多东西,导致它膨胀到 5000 token,因为每条项目规则都往里堆。有了 SessionStart,你就可以根据当前在哪个分支、哪个目录,只加载相关的规则。
怎么改:
{
"hooks": {
"SessionStart": [
{
"matcher": "startup",
"hooks": [
{
"type": "command",
"command": "cat .claude/context-$(git branch --show-current).md 2>/dev/null || true"
}
]
}
]
}
}
这样你在 main 分支就加载 context-main.md,在 feat/auth 分支就加载 context-feat-auth.md。每个文件都小小的,上下文额度再也不浪费了。
12 全局钩子开关:紧急刹车
在哪改: ~/.claude/settings.json -> disableAllHooks: true
有什么用: 一个开关直接禁用所有钩子。2026 年 3 月更新加的功能,大多数人不知道有这东西。
为什么重要: 当 Claude Code 突然开始"发神经"——莫名的命令在执行、启动就卡住、不知道谁在写文件——80% 的情况是某个钩子出了问题。一个个关太慢了,这个开关一键全关,方便你排查问题。
怎么改: 平时保持 false。出问题了就改成 true,重启看看问题消没消失。消失了就说明是某个钩子的问题,再一个一个开回来排查。没消失就说明问题在别处。
13 按项目选模型:别用大炮打蚊子
在哪改: .claude/settings.json(项目根目录下)-> model
有什么用: 给每个项目单独设置默认模型,覆盖你的全局设置。
为什么重要: 很多人全局设成 Opus,因为遇到难题时需要它。但 Opus 贵啊!如果你打开一个项目只是改改文档、写写脚本,这些事用 Haiku 做效果差不多,但只要 Opus 二十分之一的价格。
怎么改:
*// 在你的 /docs 项目中:*
{ "model": "claude-haiku-4-5-20251001" }
*// 在你的 /infra 项目中:*
{ "model": "claude-sonnet-4-6" }
*// 在你的 /core-engine 项目中:*
{ "model": "claude-opus-4-7" }
项目级的设置优先。打开哪个项目,就自动用哪个模型。省心又省钱。
14 MCP 服务器的开关:装了不代表要一直开着
在哪改: ~/.claude/settings.json -> mcpServers
有什么用: MCP 服务器就是让 Claude 能连接外部工具的桥梁。每连一个服务器,它的完整工具说明就会加载到你的上下文里,一个服务器就占 800 到 6000 个 token。
为什么重要: 很多人测试时连了一堆服务器,然后再也不管了。三个月后发现连了 12 个,实际在用的只有 3 个。那 9 个没用的服务器,每次启动会话白白消耗 25000-40000 个 token 的上下文空间。
怎么改: 用 enabled 标志保留配置但不加载。
{
"mcpServers": {
"github": { "command": "...", "enabled": true },
"postgres": { "command": "...", "enabled": true },
"slack": { "command": "...", "enabled": false },
"linear": { "command": "...", "enabled": false }
}
}
需要的时候再改成 true。平时我保持 2-3 个开着,做规划的时候开到 6 个。
15 数据保留天数:那个没人提但你该改的设置
在哪改: ~/.claude/settings.json -> cleanupPeriodDays
有什么用: 控制 Claude Code 保留对话记录、调试日志和会话数据的天数。默认 30 天。
为什么重要: Claude 的 Dreaming(深度学习)功能和历史对话搜索都要用到这些记录。30 天的话,Dreaming 只能学到你最近一个月的工作。改成半年,它就有 6 倍的学习素材。多占的磁盘空间也就 200MB 左右。
怎么改:
{ "cleanupPeriodDays": 180 }
改成 180 天后,Dreaming、记忆整合都能用上半年的数据。你自己想翻旧记录也方便——"三月份那个认证 bug 我是怎么跟 Claude 说的来着?"一搜就有。
合体版配置:7 个设置一锅端
把下面这个复制到 ~/.claude/settings.json,根据你自己的情况改改路径和插件名。改完重启 Claude Code,再跑一下 /permissions 和 /hooks 确认都加载成功了。
{
"model": "claude-sonnet-4-6",
"enabledPlugins": {
"formatter@acme-tools": true,
"old-experiment@personal": false
},
"permissions": {
"deny": [
"Read(.env)",
"Read(.env.*)",
"Read(**/*secret*)",
"Bash(rm -rf:*)",
"Bash(sudo:*)"
]
},
"hooks": {
"SessionStart": [
{
"matcher": "startup",
"hooks": [
{
"type": "command",
"command": "cat .claude/context-$(git branch --show-current).md 2>/dev/null || true"
}
]
}
]
},
"disableAllHooks": false,
"mcpServers": {
"github": { "command": "npx", "args": ["@modelcontextprotocol/server-github"], "enabled": true },
"postgres": { "command": "npx", "args": ["@modelcontextprotocol/server-postgres"], "enabled": false },
"slack": { "command": "npx", "args": ["@modelcontextprotocol/server-slack"], "enabled": false }
},
"cleanupPeriodDays": 180
}
项目级的模型覆盖放在项目根目录的 .claude/settings.json 里,最值得设的是:
*// .claude/settings.json (在一个文档项目中)*
{ "model": "claude-haiku-4-5-20251001" }
第三部分:API 和控制台(3 个设置)
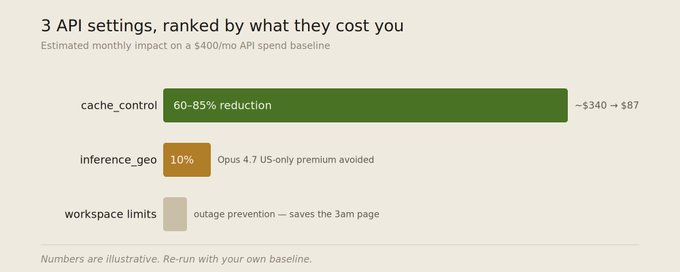
这些设置要么在你的代码里改,要么在 Anthropic 的后台控制台改。它们是全文里对成本影响最大的——每一个都可能让你的账单变动 30% 到 90%。
16 缓存断点:放对位置能省 75%
在哪改: API 请求体里的 cache_control 字段
有什么用: 把你发给 Claude 的提示词前面一段标记为"可缓存"。下次发送相同前缀的请求时,缓存的那部分只收大约 10% 的费用。
为什么重要: 这是 API 里最能省钱的设置。很多人知道有这功能,但断点位置放错了,只省了一部分。我自己把断点位置改对之后,每月账单从 $340 降到了 $87。
怎么改: 断点要放在不变的内容和每次变化的内容之间。断点前面的内容会被缓存,断点后面的每次重新计算。
*# 错误做法 — 断点放在用户消息后面,可复用的内容一个都没缓存*
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_question,
"cache_control": {"type": "ephemeral"}}
]
*# 正确做法 — 断点放在系统提示词后面,下次调用直接命中缓存*
messages = [
{"role": "system", "content": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"}},
{"role": "user", "content": user_question}
]
TTL(缓存有效期)有两种:5 分钟(默认)和 1 小时。如果你的系统提示词在不同会话间不变,用 1 小时的:
{"cache_control": {"type": "ephemeral", "ttl": "1h"}}
简单算笔账:写入缓存比正常输入贵 25%,但读取缓存只要正常输入 10% 的费用。也就是说,在有效期内只要读取 2 次以上就回本了。
17 推理区域:一个可能让你多花 10% 的隐藏收费
在哪改: API 请求里的 inference_geo 参数
有什么用: 指定 Claude 在哪个地理区域进行推理。比如只用美国服务器、只用欧盟服务器。
为什么重要: 选"仅限美国"的话,Opus 4.7 及以上版本会加收 10% 的费用。 这个加价在官方价格页上看不到,你只有在账单上才会发现。
怎么改: 如果你的合规要求并没有明确要求"数据必须留在某个地区",就不要设置 inference_geo。很多应用默认设了它"以防万一",因为法务随口说了一句"确保数据留在美国"。搞清楚这是合同硬性要求还是口头说说。如果是后者,别设这个参数,每次 Opus 调用直接省 10%。
如果确实需要设,记得把 10% 算进成本对比。Sonnet 原价 $3,加了区域费用变成 $3.30,这会影响你选 Opus 还是 Sonnet 的判断。
18 工作区速率限制:防止一个 bug 吃掉你所有配额
在哪改: Console -> Settings -> Workspaces -> [你的工作区] -> Per-feature rate limits
有什么用: 给每个工作区、每个功能单独设置调用频率上限,跟账户总限制是分开的。
为什么重要: 账户级限制防止你花超钱。工作区级限制防止你的线上产品被自己人搞挂。想象一下:你上线了一个新功能,结果有 bug,它不停地调 API,把你所有的配额都吃完了,然后你的正式产品就开始报 429 错误(请求太频繁被拒绝了)。工作区限制就是防这一出的——一个功能出问题,不会把别的功能也拖垮。
怎么改: 给不同用途各建一个工作区(在线聊天、批量处理、内部工具、实验功能)。每个工作区的速率限制设成你账户总额的 60-70%,剩下 30% 留给可能需要突发的那个工作区。
还有一个本文中第四个没写在文档里的设置:每个工作区里面,还有按功能的上限,但只有点进具体的功能卡片才能看到,工作区概览里看不到。默认是无限制。
如果你在一个工作区里放了三个功能,其中一个可能把另外两个的配额全抢走,而工作区级的限制拦不住。所以凡是做批量处理的功能,都要设按功能的上限。
第四部分:18 项检查清单
照着走一遍就行。12 个月内没碰过的,大概率以后也不会碰。
## Claude.ai 网页版
- [ ] #1 记忆:按项目隔离开启,排除列表已填
- [ ] #2 扩展思考:默认设为 Light
- [ ] #3 自定义样式:至少创建了一个工作流样式
- [ ] #4 项目指令:每个在用的项目都填了
- [ ] #5 历史对话搜索:开启(Pro+ 专属)
- [ ] #6 网络搜索引用:切到脚注模式
- [ ] #7 受信任文件夹:检查过,删掉了不用的
- [ ] #8 隐身模式:记住了快捷键
## Claude Code 命令行版
- [ ] #9 enabledPlugins:只留正在用的 = true
- [ ] #10 permissions.deny:env 文件 + sudo + rm -rf 已禁止,操作系统层面也加了锁
- [ ] #11 hooks.SessionStart:按分支自动加载对应说明文件
- [ ] #12 disableAllHooks:保持 false(但知道紧急开关在哪)
- [ ] #13 model:文档/运维/核心项目各设了对应模型
- [ ] #14 mcpServers:用 enabled 开关控制,别直接删
- [ ] #15 cleanupPeriodDays:设成 180
## API / 控制台
- [ ] #16 cache_control:断点放在系统提示词后面,长期不变的提示词用 1 小时 TTL
- [ ] #17 inference_geo:只在合规硬性要求时才设
- [ ] #18 工作区速率限制:按工作区 AND 按功能都设了上限
第五部分:每周跑一次的检查脚本
把下面这段存到 ~/bin/claude-audit.sh,每周跑一次。它会自动检查上面 7 个 Claude Code 设置和 1 个 API 缓存设置是否到位。
#!/usr/bin/env bash
*# claude-audit.sh — 检查 Claude Code 7 项设置 + 1 项 API 缓存是否偏移*
CLAUDE_DIR="$HOME/.claude"
SETTINGS="$CLAUDE_DIR/settings.json"
echo "=== 已启用的插件数量 ==="
jq '.enabledPlugins // {} | to_entries | map(select(.value==true)) | length' "$SETTINGS" 2>/dev/null
echo "目标:3-5 个。其他的按需临时开启。"
echo
echo "=== 已启用的 MCP 服务器数量 ==="
jq '.mcpServers // {} | to_entries | map(select(.value.enabled==true)) | length' "$SETTINGS" 2>/dev/null
echo "目标:3 个常开。其他的按需临时开启。"
echo
echo "=== permissions.deny 规则数量 ==="
jq '.permissions.deny // [] | length' "$SETTINGS" 2>/dev/null
echo "目标:>=5 条。至少要有 .env / sudo / rm -rf。"
echo
echo "=== SessionStart 钩子是否配置 ==="
jq '.hooks.SessionStart // [] | length' "$SETTINGS" 2>/dev/null
echo "目标:>=1 条。"
echo
echo "=== cleanupPeriodDays ==="
jq '.cleanupPeriodDays // 30' "$SETTINGS" 2>/dev/null
echo "目标:180。"
echo
echo "=== 按项目的模型覆盖 ==="
find . -maxdepth 3 -name "settings.json" -path "*/.claude/*" 2>/dev/null | while read f; do
model=$(jq -r '.model // "—"' "$f")
echo " $f → $model"
done
echo "目标:docs → haiku, infra → sonnet, core → opus。"
echo
echo "=== API cache_control 检查(需设置 API_KEY)==="
if [ -n "$ANTHROPIC_API_KEY" ]; then
echo "手动检查:超过 1K token 的系统提示词都应设 cache_control,TTL 用 1h。"
else
echo "跳过 — 设置 ANTHROPIC_API_KEY 后可启用。"
fi
保存后运行 chmod +x ~/bin/claude-audit.sh,每周跑一次,直到每项都达标。
第六部分:那些我没放进来的设置
发文章之前我删掉了四个候选设置,说说为什么,免得你白费功夫。
自适应推理开关。 Anthropic 默认就开着了,覆盖选项在 Settings → Capabilities → Reasoning mode。但我对比测试了 30 天,发现改不改结果没啥区别。相信默认值就好,不用管它。
技能自动激活。 可以切换 Claude 是自动加载技能还是需要你手动触发。我原以为这很重要,结果发现不重要。自动加载配合按需展开(先只加载摘要信息,需要时再加载完整内容)已经做得很好了。保持默认就好。
手机到电脑的远程控制。 功能有用,但跟设置审计无关。要么你的工作流需要它,要么不需要。没有什么隐藏开关能改变什么。
按工作区的回复长度上限。 可以强制每个回复在 800、2000 或 4000 token 处截断。在 Claude 特别话痨的场景下确实能省钱,但如果你需要它写长代码,截断会直接把代码截坏。按工作区试试可以,但不推荐作为默认设置。
附录:20分钟审计速查清单一览(完整18项版)
| 层面编号 | 审计项 | 核心操作 | 预期效果 | 适用场景 |
|---|---|---|---|---|
| ① | 记忆隔离 | 项目级记忆隔离 (设置 → 记忆 → 会话范围隔离) | 防止A项目记忆污染B项目,修复大部分记忆漂移 | Claude.ai |
| ② | 记忆排除 | 在记忆设置中添加排除列表(工资、客户名等敏感词) | 确保AI不在无关对话中主动提及敏感信息 | Claude.ai |
| ③ | 记忆删除 | 在对话中直接输入 “忘掉你关于[话题]的记忆” | 一键精准删除过期或错误记忆,无需翻菜单 | Claude.ai |
| ④ | 思考模式 | 将 Extended Thinking 从 Full 切换为 Light | 日常任务降低18-25%的Opus token消耗及3-12秒延迟 | Claude.ai |
| ⑤ | 项目指令 | 400字以内填满 Project Instructions 字段,每月修剪一次 | 避免每次对话冷启动,输出更精准 | Claude.ai |
| ⑥ | 过期记忆清理 | 设置 → 记忆 → 查看和编辑记忆,手动删除过时条目 | 清除僵尸记忆,防止Claude依据过时信息做出错误假设 | Claude.ai |
| ⑦ | 输出风格契约 | 创建 Custom Styles,粘贴200-1500字规范指令 | 替代80%的重复prompt,让输出一次就符合预期 | Claude.ai |
| ⑧ | 引用格式调整 | 设置 → Web搜索引用,从 Inline 改为 Footnotes | 正文干净,来源信息整齐排在文末,方便复制使用 | Claude.ai |
| ⑨ | 插件审计 | 在 settings.json 的 enabledPlugins 中,禁用不常用插件 | 每次对话节省3-8K tokens的预加载开销 | Claude Code |
| ⑩ | MCP 审计 | 在 mcpServers 中,为不常用服务器设置 "enabled": false | 每次对话节省800-6000 tokens的 schema 加载开销 | Claude Code |
| ⑪ | 权限双保险 | 配置 permissions.deny,同时在OS层执行 chmod 600 .env | 防止因Claude Code的Bug导致敏感文件被读取 | Claude Code |
| ⑫ | 分支感知注入 | 利用 hooks.SessionStart,按git分支自动加载对应上下文文件 | 降低约 30% 的上下文预算浪费 | Claude Code |
| ⑬ | 应急开关 | 启用 disableAllHooks: true,一键关闭所有Hook | 关键时刻快速诊断故障源 | Claude Code |
| ⑭ | 隐藏大招 | 将 cleanupPeriodDays 改为 180(隐藏设置) | Dreaming学习信号量提升6倍,行为预测更精准 | Claude Code |
| ⑮ | 模型选择 | 通过 /model 命令,按任务匹配不同模型 | 精准平衡性能与成本 | API |
| ⑯ | 缓存断点 | 在system prompt末尾、用户消息前设置cache_control断点,TTL设1小时 | 月成本大幅下降,降幅60-85% | API |
| ⑰ | 地理策略 | 检查并移除不必要的 inference_geo 参数 | 规避Opus 4.7+美国区域10%隐藏溢价 | API |
| ⑱ | 速率限制 | 在 API Console 配置 Workspace Rate Limits | 防止凌晨高并发造成账单激增或服务停摆 | API |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号