如何判断一个AI算力云平台是否靠谱?
2026年过了不到半年,因为小龙虾的横空出世,大大提高了C端用户的算力消耗量。
C端的coding plan和token plan 层出不穷,价格也不断上涨。
4月15日,阿里云宣布自7月15日起,DDoS高防(中国内地)弹性95费用上调50%(从每兆瓦月100元涨至150元),这是阿里云一个月内第三次调价。
这一轮全球涨价潮由海外率先引爆——亚马逊AWS年初率先上调AI算力价格,谷歌云随后跟进,最高涨幅达100%。
腾讯云、百度智能云也同步跟进。腾讯云4月9日宣布AI算力、容器、EMR全线上调5%;百度智能云AI算力与存储上调5%~30%。
这期间,B端算力的价格也在狂飙。
根据SemiAnalysis数据,H100一年期租赁价格变化:

涨幅接近40%。
市面上租赁GPU云服务器的价格也是涨了差不多40%。
更有甚者,很多时候你想租云服务器,还租不到。
这个时候租高性能的弹性算力是一种很划算的方法。
但问题是,现在算力云平台这么多,想要租赁算力的你、团队和公司,上哪儿去租到高性能的算力呢?
就算发现一家,你怎么确定它靠不靠谱呢?怎么知道它适不适合你呢?

我们假设你发现了一个AI算力云平台,你需要先了解这几点:
一、硬件算力硬条件
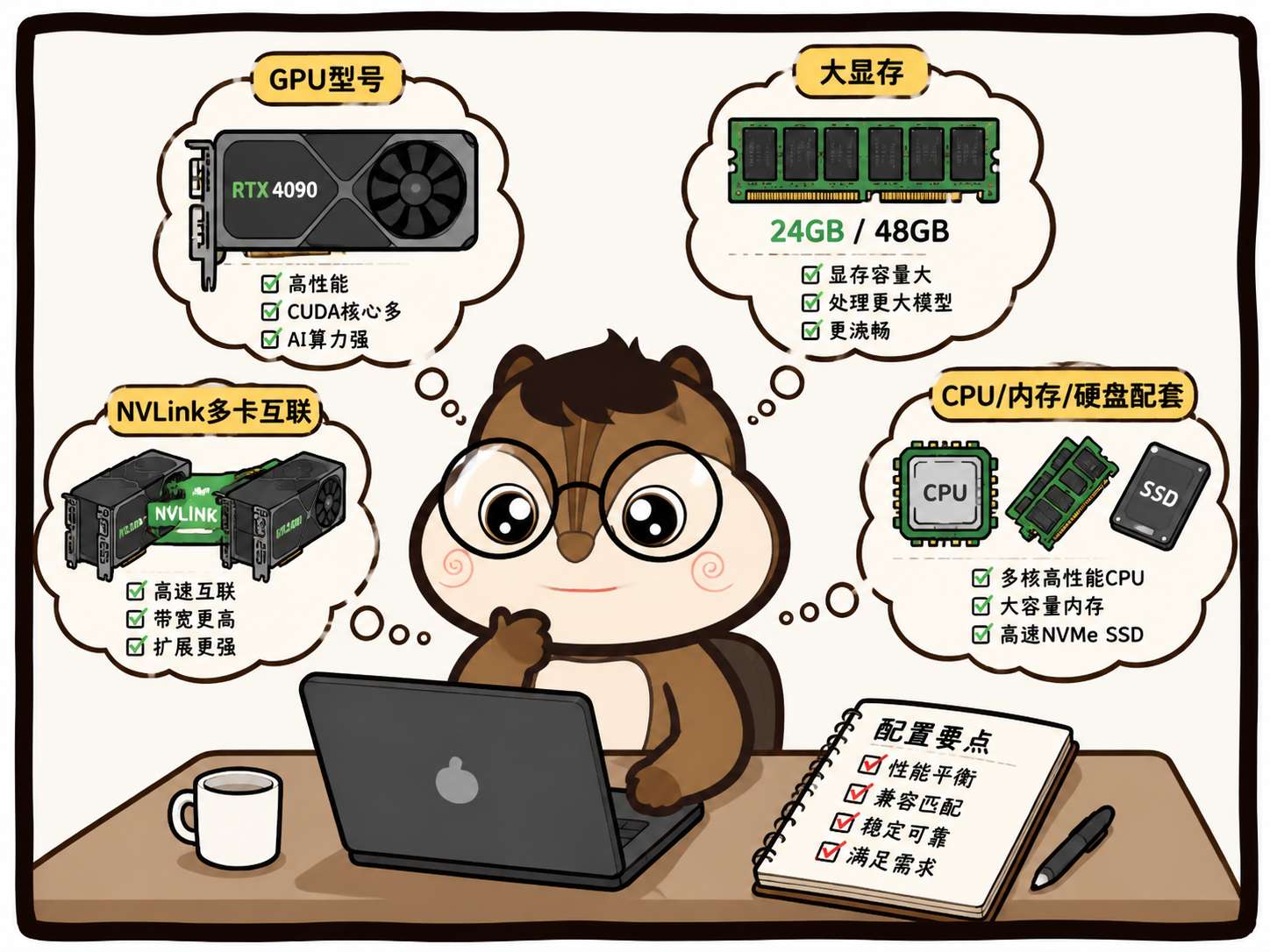
1. GPU 型号
这个不用多说,看这个平台有没有你要的卡型号。
2. 单卡显存
这个其实跟卡型号有关,你选卡型号其实很重要的一点就是选显存。
对于很多大模型微调和训练来说,显存不够根本跑不起来。
3. 多卡互联
你做多卡集群训练必看有没有有没有 NVLink、IB 高速网络。
高端的一般都是NVLink+IB网络。
一般的以太网通信瓶颈比较严重,拉低训练速度。
4. 配套配置
也不是只要看GPU的参数,也要看CPU的。
CPU:核心数、主频要够,负责数据预处理、任务调度
内存:内存太小会加载模型卡死、数据吞吐卡住
本地盘 / 共享存储:读写速度慢,数据集加载慢,拖慢整个训练流程-->训练、微调、推理
二、稳定性 & SLA 保障
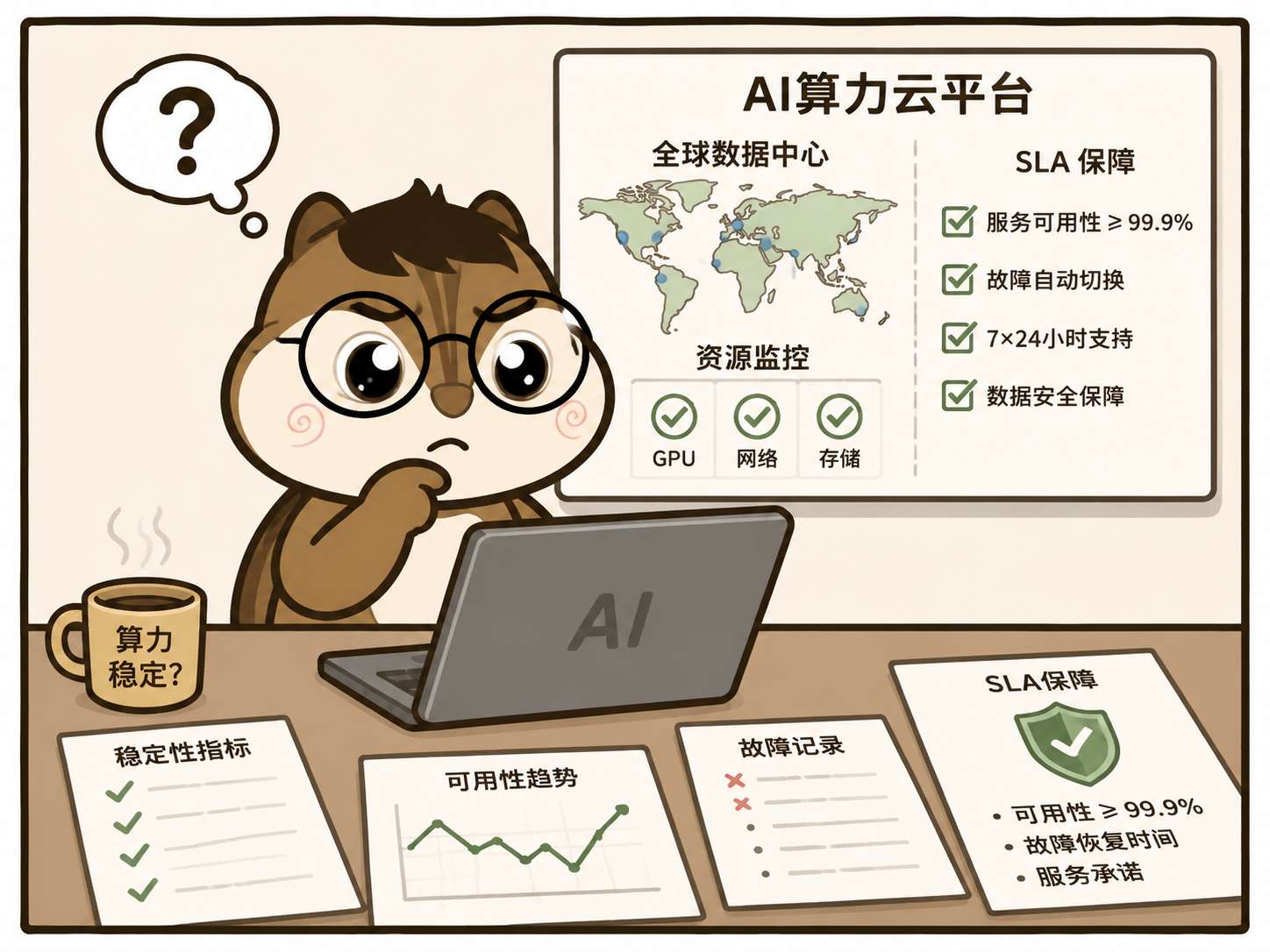
SLA保障是啥?
SLA 全称 Service Level Agreement,中文叫服务等级协议。
简单说:服务商跟客户签的一份「服务保质保证书」,约定好服务要达到什么标准、达不到怎么赔。
云厂商、算力平台、API 接口都会标 SLA,约定这些关键指标:
1. 服务可用性(Uptime):平台能让你正常用、不中断的时间占比。
这个是有量化指标的:“故障总时长”
“故障总时长” 核心标准如下:
- 99.99%:每月故障总时长<4.3 分钟,全年累计故障时长不超过 52 分钟
- 99.95%:每月故障总时长<21.5 分钟,全年累计故障时长不超过 4.3 小时
- 99.9%:每月故障总时长<43 分钟,全年累计故障时长不超过 8.7 小时
- 99.5%:每月故障总时长<216 分钟(3.6 小时)
- 99%:每月故障总时长<432 分钟(7.2 小时)
可用性百分比越高,代表平台承诺的服务中断时间越短,业务连续性越强。
企业级与科研级的长周期训练任务,建议优先选择 99.95% 及以上标准的平台,从源头规避任务中断风险。
2. 任务容错与自愈能力:降低中断损失的关键机制
针对长周期任务的潜在中断风险,平台需具备完善的容错与自愈能力:
比方说,实例自动迁移:当服务器节点出现故障时,平台可自动将任务迁移至健康节点继续运行,无需人工干预和重新部署,保障业务连续性。
3. 机房与网络基础设施:稳定性的底层支撑
平台的稳定性依赖于高标准的机房与网络基础设施:
-
机房等级:采用国内等保2.0三级以上机房,配备恒温恒湿环境、双路供电冗余、独立 UPS 与备用发电机组,有效规避断电、湿热、硬件故障等导致的服务中断。
-
网络质量:内网带宽直接决定多卡分布式训练的通信效率,公网带宽则影响模型下载、数据集传输与推理接口的访问速度,两者均需匹配业务场景的性能要求。
4. 正式 SLA 服务等级协议:政企采购的必备门槛
平台的稳定性承诺并非口头表述,而是明确写入盖章合同的正式约定,核心包含以下内容:
- 清晰的月度服务可用率承诺标准;
- 故障分级响应机制(如 P0 重大故障、P1 一般故障)及对应的响应与修复时效;
- 未达标赔付规则:若当月可用率未达到承诺标准,平台将按约定向客户提供算力时长、代金券或服务费用补偿。
对于国企、高校、大型企业而言,具备盖章版 SLA 协议是供应商准入的硬性条件之一,也是客户权益的重要保障。
三、价格 & 计费模式

现在通常有三种计费模式:
-
按使用量付费:一般只跑小任务或者做测试会选择这个。
-
按月付费:每个月的费用是固定的,你在包月的范围内付费使用算力。
那如果这个月用量超过了怎么办呢?
不用担心,还是可以额外购买。不至于让你的训练就此中断。
- 按GPU云服务器台数付费:这个成本比较高。一般都是要求独享的客户会选择这个。
另外就是,要提前搞清楚带宽和存储的付费规则。
有些是要额外付费的。
如果你对带宽和存储的要求比较高,也要问问厂商是否能达到你的要求,以及如何收费。
四、易用性 & 软件生态

1. 预封装环境镜像
要看平台提前装好:
- PyTorch、TensorFlow、PaddlePaddle 主流框架
- CUDA、CUDNN 适配版本
- Hugging Face、LLaMA、Qwen 等大模型常用依赖
这样你就不用自己装环境、配版本,开箱即用。
毕竟装环境也是一件挺麻烦的事。
2. 控制台管理能力
- 机器开机 / 关机 / 重装系统一键操作
- 任务排队、资源监控、GPU 利用率、温度、负载可视化
- 告警推送:机器异常、显存跑满、任务结束自动提醒
3. 开源生态兼容性
能不能无缝对接:
- Hugging Face 模型库
- LangChain 应用开发
- 各类微调、量化、部署开源工具链
这样客户原有代码不用大改就能迁上来。
4. 模型服务化能力
支持一键模型部署成 API 接口,直接给业务系统调用,不用自己搭推理框架。
五、技术服务 & 售后
这个对于公司和团队客户来说很重要。
1. 专属技术对接
对于团队和公司客户来说,普通的客服肯定是不够的。
需要配备懂大模型、懂训练、懂框架,能聊技术方案的工程师来聊方案和支持售后工作。
2. 7×24 小时故障响应
深夜训练任务崩了、机器失联,能随时找人处理,不是工作日和上班时间才管。
3. 方案定制能力
有一定经验的云厂商是可以给客户提供以下帮助的。
- 训推集群架构规划
- 模型适配硬件选型
- 多卡分布式训练调试
其实就等于给客户配备顾问了。
4. 故障协助排查
任务跑不起来、loss 异常、算力跑不满、网络卡顿,平台有人可以协助定位是环境问题、硬件问题还是代码问题。
一张表给你总结这五大维度:
| 评估维度 | 关键考察点 | 说明 |
|---|---|---|
| 硬件配置 | GPU型号、单卡显存、多卡互联方式、CPU核心数与主频、内存大小、本地盘/共享存储读写速度 | 显存不够模型跑不起来,网络不行多卡训练效率低,存储慢会拖累整个流程 |
| 稳定性与SLA | 服务可用性百分比、断点续训、实例自动迁移、机房等级、网络质量、是否提供盖章版SLA协议 | 可用性越高中断越少,断点续训能避免训练白费,盖章协议是政企采购的硬门槛 |
| 计费模式 | 按使用量付费、按月付费、按GPU台数付费、带宽和存储是否额外收费 | 小任务选按量,长期用选包月更划算,独享需求选按台数,注意隐藏收费项 |
| 软件生态 | 是否预装主流框架(PyTorch/TensorFlow等)、CUDA/CUDNN适配版本、控制台管理能力、开源生态兼容性、模型服务化能力 | 预装环境能省去配环境的麻烦,控制台要能监控资源、告警推送,最好能一键部署成API |
| 技术服务 | 是否配备懂技术的专属对接人、7×24小时故障响应、方案定制能力、故障协助排查 | 团队客户需要技术工程师对接,深夜出问题能随时找人处理,平台能帮忙定位是环境问题还是代码问题 |
看完上面这五大维度的评估标准,你是不是觉得选一个靠谱的算力平台,简直比训练一个大模型本身还复杂?
因为这确实不是一件简单的事。
没关系,市面上已经有平台把这些“麻烦事”都替你考虑周全了。
比如,九章智算云(Alaya NeW Cloud)。
我们来看看九章智算云有哪些特点?
1. 硬件配置与性能
先看硬件。
九章智算云背后有自研的智算操作系统做支撑,从单卡到万卡集群都能灵活调配。
平台提供Serverless、VKS(弹性容器集群)、DKS(专享容器平台) 等多种算力供给形态,支持从单卡到万卡集群的弹性扩展。
其底层采用NVLink+IB高速网络架构,确保多卡训练时的高效通信。
并配备高性能分布式存储系统DingoFS,实现存算运一体化,满足大模型训练对高吞吐、低延迟的极致要求。
2. 稳定性与SLA保障
再说稳定性。
它的智算操作系统是国内唯一在算力调度、模型训练、模型推理、数据处理四个领域都通过中国信通院认证的全栈AI系统。
平台内置智能调度中枢,通过强化学习、GANG调度、NUMA优化、故障感知与动态拓扑恢复等机制,实现资源利用最大化。
文档明确承诺99.95%及以上的SLA,支持断点续训和实例自动迁移,有效避免因单点故障导致的训练中断,保障长时间训练任务的连续性。
计费模式与性价比
计费模式也挺灵活。
九章智算云目前有3种计费方式:
- 按使用量计费:他们提出了算力标准化计量。他们把算力定义为“度”,1度算力等于312TFLOPS乘以1小时,用多少买多少,像交水电费一样清楚。所以你可以选择按使用量计费。使用了多少度,付多少度的钱。
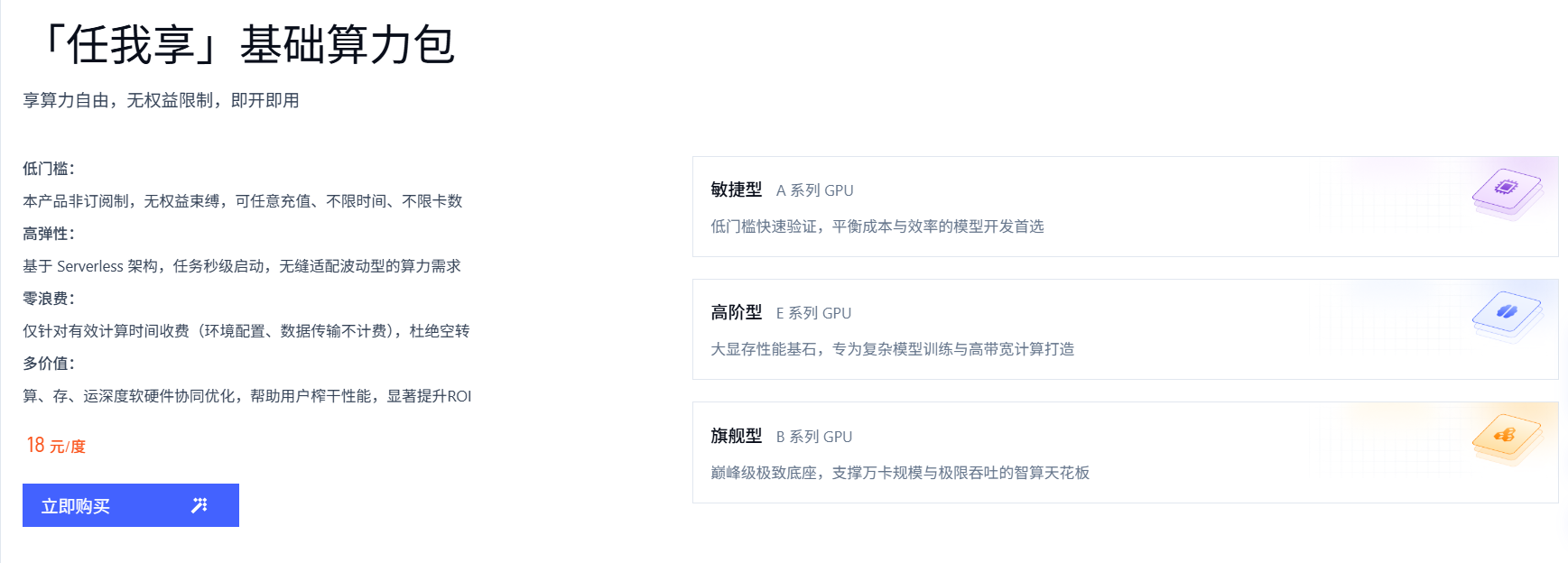
如果你是轻量算力使用者,这个适合你。
- 他们也提供按月付费。

比较多的公司团队和科研团队会选择这个付费方式。
- 你也可以选择租赁云服务器。
当然这个价格会更贵一些。
4. 软件生态与易用性
软件生态方面,平台预装了主流的模型框架和开发环境,开箱就能用,不用自己折腾版本匹配。
还提供了一整套从训练到推理再到部署的工具链,开发效率能提升好几倍。
如果你用的是Serverless模式,连机器都不用管,直接提交任务就行,启动只要几毫秒。
对比传统AI开发,开发效率提升4倍。
5. 服务与技术支持
九章智算云服务过两千多家客户,包括中核集团、北京电影学院、清华大学这些大机构,经验很丰富。
他们会给团队和企业客户配专属技术顾问,7×24小时随时响应,从方案规划到故障排查都有人陪着。
而且他们参与了国家算力互联网试验网和超算互联网平台的建设,运维能力和技术底子都很扎实。
最后给你一张表总结。
九章智算云 综合能力评估表
| 评估维度 | 平台表现 |
|---|---|
| 硬件配置 | 多形态算力供给,适配主流国产/国际芯片,NVLink+IB高速网络,存算运一体化 |
| 稳定性 | 99.95%+ SLA,断点续训,智能故障恢复,信通院四大领域全认证 |
| 计费模式 | 首创“度”计量,按需弹性,秒级计费,综合成本直降68% |
| 软件生态 | 开箱即用,预装主流模型,全生命周期工具链,开发效率提升4倍 |
| 服务支持 | 专属技术顾问,7×24小时响应,服务国家级项目,万P规模运维经验 |
最后还有一个小tip给到大家。
如果是公司或者团队用户,在付费前是可以做测试的。
你可以通过测试来基本了解这个平台是否能满足你的需求。
你也可以扫码添加他们的绿泡泡:ufcrystal 来了解更多。
最后的最后,如果你正在找一个性能强、稳定可靠、服务又到位的算力平台,九章智算云确实值得认真了解一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号