

PANDAS
pandas的使用
-
DataFrame的使用
-
列表产生
import plotly as py from plotly import figure_factory as ff import pandas as pd pyplt=py.offline.plot # 离线模式 data=pd.DataFrame([["20191001730","kx","4.00"], ["20191000456","fgy","1.00"] ], columns=("学号","姓名","成绩")) #表头 table=ff.create_table(data) #用plotly输出表格 pyplt(table,show_link=False)处理结果:
![]()
-
字典产生
import plotly as py from plotly import figure_factory as ff import pandas as pd pyplt=py.offline.plot # 离线模式 data=pd.DataFrame({'学号':['201910010288','20191001730','201011192983'], '专业':['计算机系','金融系','空间系'],'成绩':[66,99,120]}) #表头 table=ff.create_table(data) #用plotly输出表格 pyplt(table,show_link=False)处理结果:
![]()
-
对一些用法的说明
函数 用法 data.at[行,列] 找到位置 data.iloc[0] 第一行的信息 data['xxx'] 'xxx'列的信息
-
-
用Pandas读写各种类型的文件
-
读取csv和表格
读:read_csv()
写:to_csv()
-
read_csv()常用参数
参数 含义 sep/delimiter 列分隔符 header 列名,如果有自己的列名列表,传递None index_col 作为索引的列名 skiprows 要跳过的文件头行数 na_values 用于处理缺失数据的字符串 encoding 字符编码方式
举例:
(GB2312是中国制定的中文编码,GBK是GB2312的拓展,CP936是在GB2312的基础上开发的汉字编码)
import plotly as py from plotly import figure_factory as ff import pandas as pd import plotly.graph_objs as pygo pyplt=py.offline.plot # 离线模式 data=pd.read_csv('score.csv',encoding='GBK') #读取 table=ff.create_table(data) #用plotly输出表格 pyplt(table,show_link=False)![]()
-
-
写网页文件
基本和上一个相同
import plotly as py from plotly import figure_factory as ff import pandas as pd import plotly.graph_objs as pygo pyplt=py.offline.plot # 离线模式 data=pd.read_csv('score.csv',encoding='GBK') #读取 table=ff.create_table(data) #用plotly输出表格 pyplt(table,filename='scoregp.html',show_link=False) -
读写EXCAL
读:read_excal('文件名')
写:to_excal(‘文件名’)
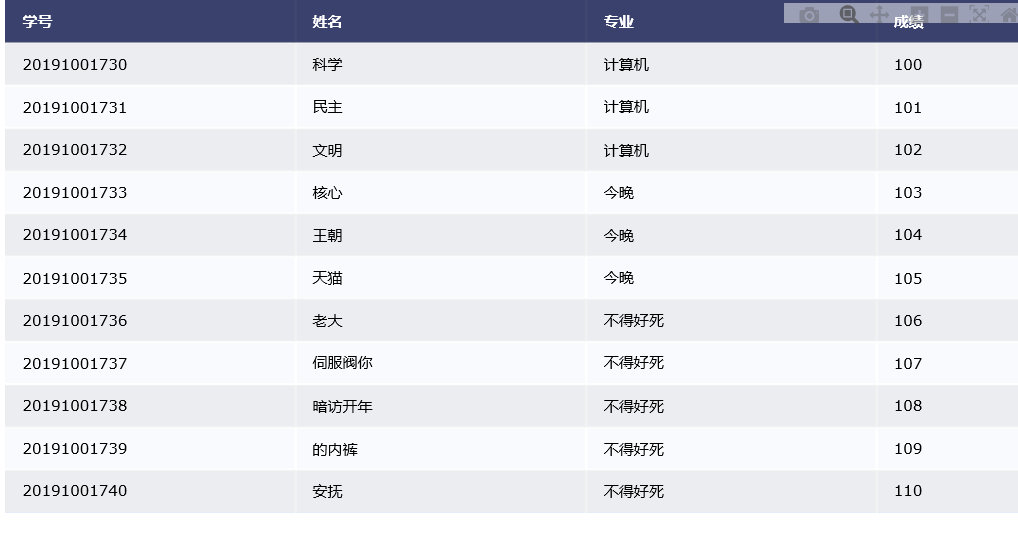
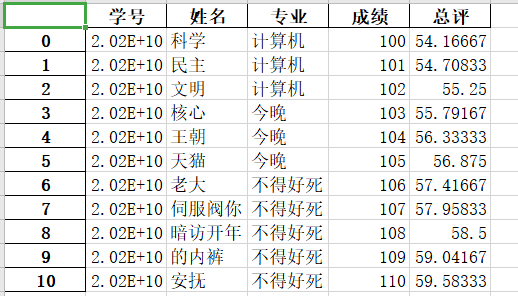
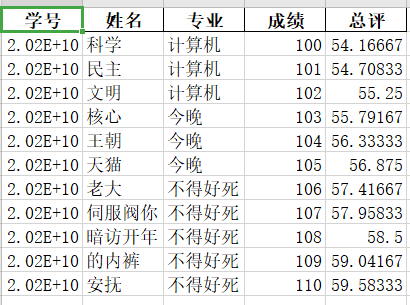
import plotly as py from plotly import figure_factory as ff import pandas as pd import plotly.graph_objs as pygo pyplt=py.offline.plot # 离线模式 data=pd.read_excel('score.xlsx') #读取 data['总评']=data['成绩']/120*65 data.to_excel('score.xlsx',index=0)没有index=0:
![]()
有index=0:
![]()
-


名字都是乱打的,不代表本人的任何观点和立场

 浙公网安备 33010602011771号
浙公网安备 33010602011771号