
Day3-数据类型
数据类型:
C是有类型的语言,C语言的变量,必须:在使用前定义,并且要确定类型
C以后的语言向两个方向发展:
- C++/Java更强调类型,对类型的检查更严格;
- JavaScript、Python、PHP不看重类型,甚至不需要事先定义
C语言的数据类型:
- 整数:char、short、 int、long、long long(划线的是是C99的类型)
- 浮点数:float、double、long double
- 逻辑:bool
- 指针
- 自定义类型
类型有何不同:
- 类型名称:int、long、double
- 输入输出时的格式化:%d、%ld、%lf
- 所表达的数的范围:char < short < int < float <double
- 内存中所占据的大小:1个字节到16个字节
- 内存中的表达形式:二进制数(补码)、编码
sizeof:是一个运算符,给出某个类型或变量在内存中所占的字节数
用法如:sizeof(int) sizeof(i)
注意:sizeof是静态运算符,它的结果在编译时刻就决定了,而且,不要在sizeof的括号里做运算,这些运算不会做的,它只会给出括号内数据在内存所占的字节数
- char: 1字节(8比特).
- short: 2字节
- int:取决于编译器(CPU) ,通常的意义是"1个字”
- long:取决于编译器(CPU),通常的意义是"1个字”
- long long: 8字节
整数在计算机内部的表达:计算机内部一切都是二进制。
1个字节可以表达的数:00000000-11111111(0-255)
二进制的负数如何表达?
三种方案:1.仿照十进制,有一个特殊的标志表示负数 2.取中间的数为0,如1000000表示0,比它小的是负数,比它大的是正数 3.补码
补码:补码的意义就是补码和原码可以加出一个溢出的“零“。
因为0-1=-1,(1)00000000-00000001=11111111,因此11111111被当作纯二进制看待是255,被当作补码看待是-1.
同理,对于-a,它的补码就是0-a,实际是,n是这种类型的位数
数的范围:
对于一个字节(8位,比如char),可以表达的是:00000000 - 11111111
其中: 00000000—>0,
11111111 ~10000000—> -1~ -128
00000001 ~01111111—> 1~127
unsigned
如果一个自变量常数想要表达自己是unsigned,可以在后面加u或U,如255U。同理,如果一个自变量常数想要表达自己是long,用l或L表示long(long)。
unsigned的初衷并非扩展数能表达的范围,而是为了做纯二进制运算,主要是为了移位
Unsigned数字只有0和正整数部分。
整数越界
整数是以纯二进制方式进行计算的,所以∶
- 11111111+1—>100000000—> 0
- 01111111+1—>10000000—>-128
- 10000000 - 1—>01111111—>127
整数的输入输出
只有两种形式: int或long long
%d: int
%u: unsigned.
%ld: long long
%lu : unsigned long long
8进制和16进制
- 一个以O开始的数字字面量是8进制
- 一个以Ox开始的数字字面量是16进制。
- %o用于8进制,%x用于16进制
- 8进制和16进制只是如何把数字表达为字符串,与内部如何表达数字无关
- 16进制很适合表达二进制数据,因为4位二进制正好是一个16进制位
- 8进制的一位数字正好表达3位二进制
- 因为早期计算机的字长是12的倍数,而非8
选择整数类型
为什么整数要有那么多种?
为了准确表达内存,做底层程序的需要。现在,没有特殊需要,就选择int
·现在的CPU的字长普遍是32位或64位,一次内存读写就是一个int,一次计算也是一个int,选择更短的类型不会更快,甚至可能更慢
现代的编译器一般会设计内存对齐,所以更短的类型实际在内存中有可能也占据一个int的大小(虽然sizeof告诉你更小)
unsigned与否只是输出的不同,内部计算是一样的
浮点数
- float字长32范围有效数字7,scanf中用%f,printf中用%f,%e,占4个字节(32位)
- double字长64范围有效数字15, scanf中用%lf,printf中用%f,%e(%e是指科学计数法),占8个字节(64位)
- printf输出inf表示超过范围的浮点数:
- printf输出nan表示不存在的浮点数
- 带小数点的字面量是double而非float
- float需要用f或F后缀来表明身份
- 两个浮点数如果直接用 f1 == f2,可能是失败的。可以用fabs(f1-f2)<1e-12
- 选择浮点类型:如果没有特殊需要,只使用double。现代CPU能直接对double做硬件运算,性能不会比float差,在64位的机器上,数据存储的速度也不比float慢。
字符类型
char是一种整数,也是一种特殊的类型:字符。这是因为:
·用单引号表示的字符字面量:'a', '1'
·’’也是一个字符
printf和scanf里用%c来输入输出字符
输出精度
在%和f之间加上.n可以指定输出小数点后几位,这样的输出是做4舍5入的
printf("%.3fn",-0.0049);
printf("%.30fn"-0.0049);
printf("%.3f\n",-0.00049);
字符计算:
一个字符加一个数字得到ASCII码表中那个数之后的字符
两个字符的减,得到它们在表中的距离
大小写转换:
字母在ASCII表中是顺序排列的
大写字母和小写字母是分开排列的,并不在一起
'a'-'A'可以得到两段之间的距离,于是a+'a'-'A"可以把一个大写字母变成小写字母,而a+'A'-'a'可以把一个小写字母变成大写字母
逃逸字符(转义字符):
用来表达无法印出来的控制字符或特殊字符,它由一个反斜杠“\”开头,后面跟上另一个字符,这两个字符合起来,组成了一个字符
自动类型转换:
当运算符的两边出现不一致的类型时,会自动转换成较大的类型
大的意思是能表达的数的范围更大
char -> short —> int —> long -> long long.
int —> float—> double
对于printf,任何小于int的类型会被转换成int;float会被转换成double
但是scanf不会,要输入short,需要%hd
强制类型转换:
要把一个量强制转换成另一个类型(通常是较小的类型),需要:(类型)值
比如:(int)10.2,(short)32
注意:这时候的安全性,小的变量不总能表达大的量:(short)32768
注意:只是从那个变量计算出了一个新的类型的值,它并不改变那个变量,无论是值,还是类型都不改变。
强制类型转换的优先级比四则运算(加减乘除)高。
布尔类型:bool
#include<stdbool.h>,之后就可以用bool、true和false。
逻辑运算:
逻辑运算是对逻辑量进行的运算,结果只有0或1.逻辑量是关系运算或逻辑运算的结果。
逻辑运算符:!(非)、&&(与)、||(或)
优先级: !>&&>||
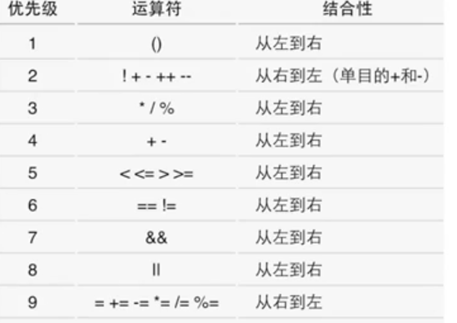
逻辑短路:逻辑运算是自左向右进行的,如果左边的结果已经能够决定结果了,就不会做右边的计算。比如:a==6 && b==1 、-a==6 && b+=1
- 对于&&,左边是false时就不做右边了
- 对于||,左边是true时就不做右边了
条件运算:条件、条件满足时的值和条件不满足时的值
比如:count = (count>20)?count-10:count+10
优先级高于赋值运算符,但是低于其他运算符。
条件运算符是自右向左结合的。
逗号运算:逗号用来连接两个表达式,并以其右边的表达式的值作为它的结果。逗号的优先级是所有的运算符中最低的,所以它两边的表达式会先计算;逗号的组合关系是自左向右,所以左边的表达式会先计算,而右边的表达式的值就留下来作为逗号运算的结果。
比如:i = (3+4,5+6) 输出i =11
i = 3+4,5+6 输出i = 7
一般在for循环中使用,如for (i=0,j=0;i<j;i++,j++)
进制转换
二进制
八进制
十进制
十六进制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号