Python3爬虫_suumo网示例_下载视频
准备工作:
- 打开pycharm安装好所需的包
- 在 Terminal 运行窗口 输入命令 :
pip install requests
pip install lxml
pip install selenium- 也可以在 菜单栏:File – Setting – Python Interperter – 下方 + 搜索对应的包名称进行安装
在IDE里面创建新项目把下载好的谷歌浏览器驱动(chromedriver.exe) 导入到文件夹中.
chromedriver驱动下载地址:
链接:https://pan.baidu.com/s/1LveV-yLS7rwLo0cTjKYFgg
提取码:1234
执行一下代码:
import requests
import time
import os
import re
import random
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class GetVideo(object):
def __init__(self,url):
self.url = url
self.url_list = url.split("/")
self.url_list.pop(-1)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3872.400 QQBrowser/10.8.4455.400'
}
def get_eval_data(self):
# 2.获取网页链接视频源码url
self.headers["Cookie"] ="PHPSESSID=1n9u3kih72g3f4tlqvobv42gf4"
page_text = requests.get(url=self.url, headers=self.headers).text
# print(page_text)
tree = etree.HTML(page_text)
self.headers["Host"] = "suumo.smbb.jp"
video_url = tree.xpath("//div[@class='block-inqfree2 clr']/iframe/@src")
# print(video_url[0])
self.headers["Referer"] = video_url[0]
# 3.正则提取视频 eval算法
get_video_url = requests.get(url=video_url[0], headers=self.headers).text
# print(get_video_url)
res = re.search("eval.*", get_video_url)
# print(res.group())
eval_str = res.group()
# 4.把eval算法存为本地html页面
l = eval_str.split("}return p")
eval_str = "%sdocument.getElementById('textareaID').innerText=p;}return p%s" % (l[0], l[1])
# print(eval_str)
with open('test.html', 'w', encoding='utf-8') as fp:
fp.write(f"""<!DOCTYPE html P LIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title> Crack Baidu统计构造函数</title>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta http-equiv="X- -Compatible" content="IE=EmulateIE7" />
<meta name="Author" content=www.gemingcao.com/>
<meta name="Keywords" content="" />
<meta name="Description" content="" />
</head>
<body>
<textarea id="textareaID" rows="25" cols="50"></textarea>
<script type="text/javascript">{eval_str}
</script>
</body>
</html>""")
def get_encmoviepath(self):
# 5.通过selenium 模拟登录获取 encmoviepath 链接地址
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
bro = webdriver.Chrome(executable_path='./chromedriver.exe', chrome_options=chrome_options)
bro.get(os.path.dirname(__file__) + "\\test.html")
encmoviepath = bro.find_element_by_id("textareaID").text
# print(encmoviepath)
encmoviepath_url = re.search("encmoviepath\..*'\);hls?", encmoviepath).group().split("');hls")
# print(encmoviepath_url[0])
# 6.访问encmoviepath链接 获取 正确的视频分段url
res = requests.get(url=f"https://suumo.smbb.jp/dvic/{encmoviepath_url[0]}", headers=self.headers)
return res.text
def save_video(self):
file_path = f"{os.path.dirname(__file__)}\\{self.url_list[-1]}_{int(time.time())}.mp4"
res_text = self.get_encmoviepath()
# 7.访问正确视频url 进行本地持久化存储
if "https" in res_text:
with open(file_path, 'wb+') as fp:
ulr_ts = re.findall("https.*", res_text)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3872.400 QQBrowser/10.8.4455.400'
}
if len(ulr_ts) >= 2:
# print(ulr_ts)
for u in ulr_ts:
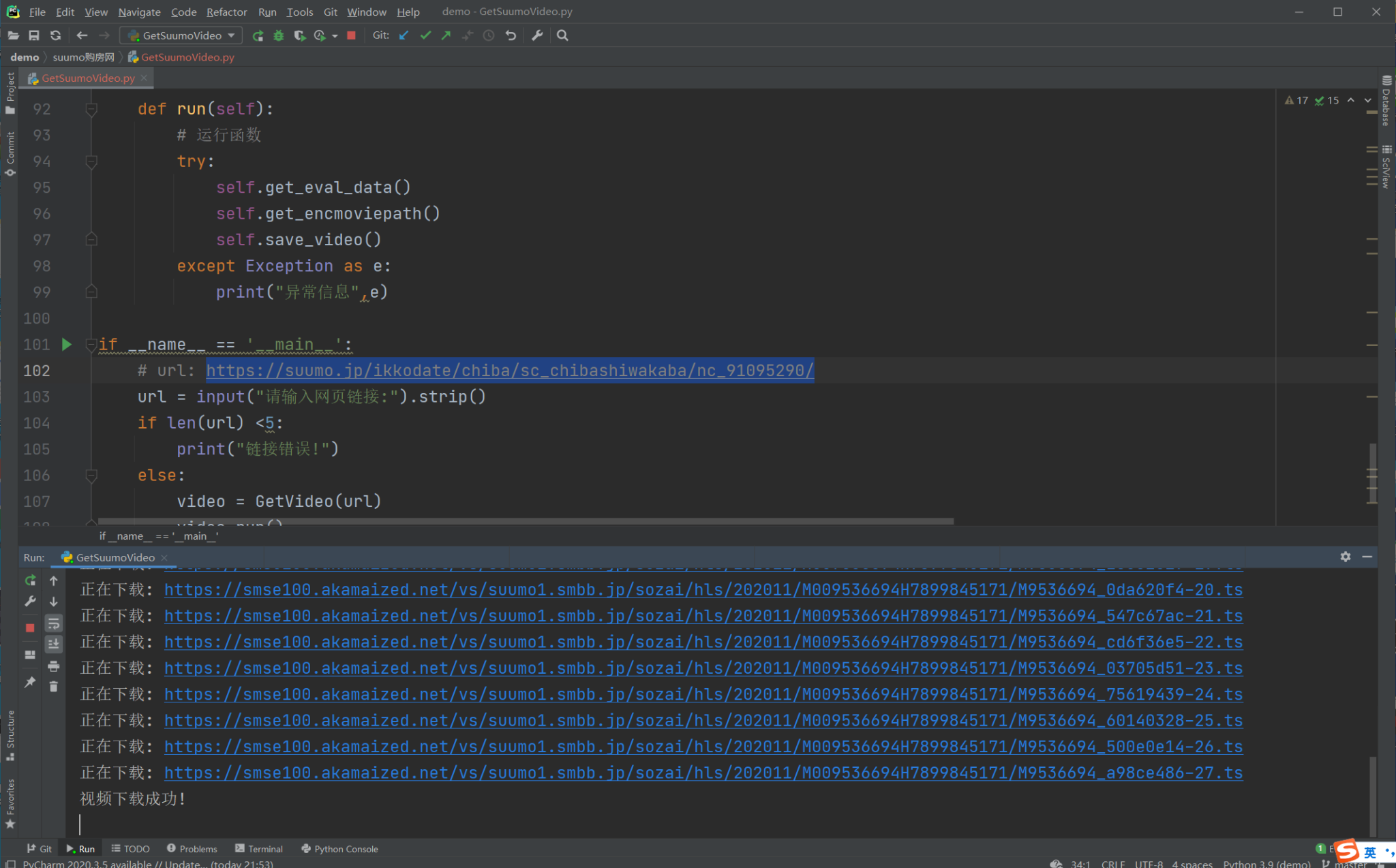
print("正在下载:", u)
get_video_url = requests.get(url=u, headers=headers)
fp.write(get_video_url.content)
time.sleep(random.randint(100, 500) / 1000)
print("视频下载成功!")
else:
print("没有可下载的视频连接")
def run(self):
# 运行函数
try:
self.get_eval_data()
self.get_encmoviepath()
self.save_video()
except Exception as e:
print("异常信息",e)
if __name__ == '__main__':
# 1. 用户输入url
# url: https://suumo.jp/ikkodate/chiba/sc_chibashiwakaba/nc_91095290/
url = input("请输入网页链接:").strip()
if len(url) <5:
print("链接错误!")
else:
video = GetVideo(url)
video.run()
执行结果图片:
学习更多的python3爬虫示例可以关注: Aitlo学习站
本文来自博客园,作者:Aitlo,转载请注明原文链接:https://www.cnblogs.com/Aitlo/p/15476145.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号