第四次作业
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
(1)Hadoop起源于Google的三大论文:
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
(2)Hadoop的发展:
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性

2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
名称结点(NameNode):1.负责文件和目录的创建、删除和重命名等 2.管理着数据结点和文件块的映射关系 3.处理客户端的访问请求
数据结点(DataNode):1.负责数据的存储和读取 2.根据名称结点的命令创建、删除和复制数据块 3.心跳机制,与名称结点保持通信。
第二名称结点(SecondaryNode):1.完成EditLog和FsImage的合并操作,减少EditLog文件大小,缩短名称结点重启时间
2.作为名称结点的”检查点“,保存名称结点中的元数据信息。
三者的关系:
名称节点与第二名称节点:
名称节点类似于数据目录。其主要有两大构件构成,FsImage和Editlog,FsImage用于存储元数据(长时间不更新、Editlog用于更新数据,但是随着时间推移,Editlog内存储的数据越来越多,导致运行速度越来越慢。所以引入第二名称节点,当第一节点中Editlog到一个临界值时,HDFS会暂停服务,由第二节点将拷贝出Editlog,复制、添加到Fslmage后方并清空原Editlog的内容。这里有一点要注意这种备份是冷备份的形式,即没有实时性,需要停止服务,等数据恢复正常后继续使用。
名称节点与数据节点:
HDFS集群有两种节点,以管理者-工作者的模式运行,即一个名称节点(管理者)和多个数据节点(工作者)。名称节点管理文件系统的命名空间。它维护着这个文件系统树及这个树内所有的文件和索引目录。数据节点是文件系统的工作者。它们存储并提供定位块的服务(被用户或名称节点调用时),并且定时的向名称节点发送它们存储的块的列表。
第二名称节点与数据节点:
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间,而数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
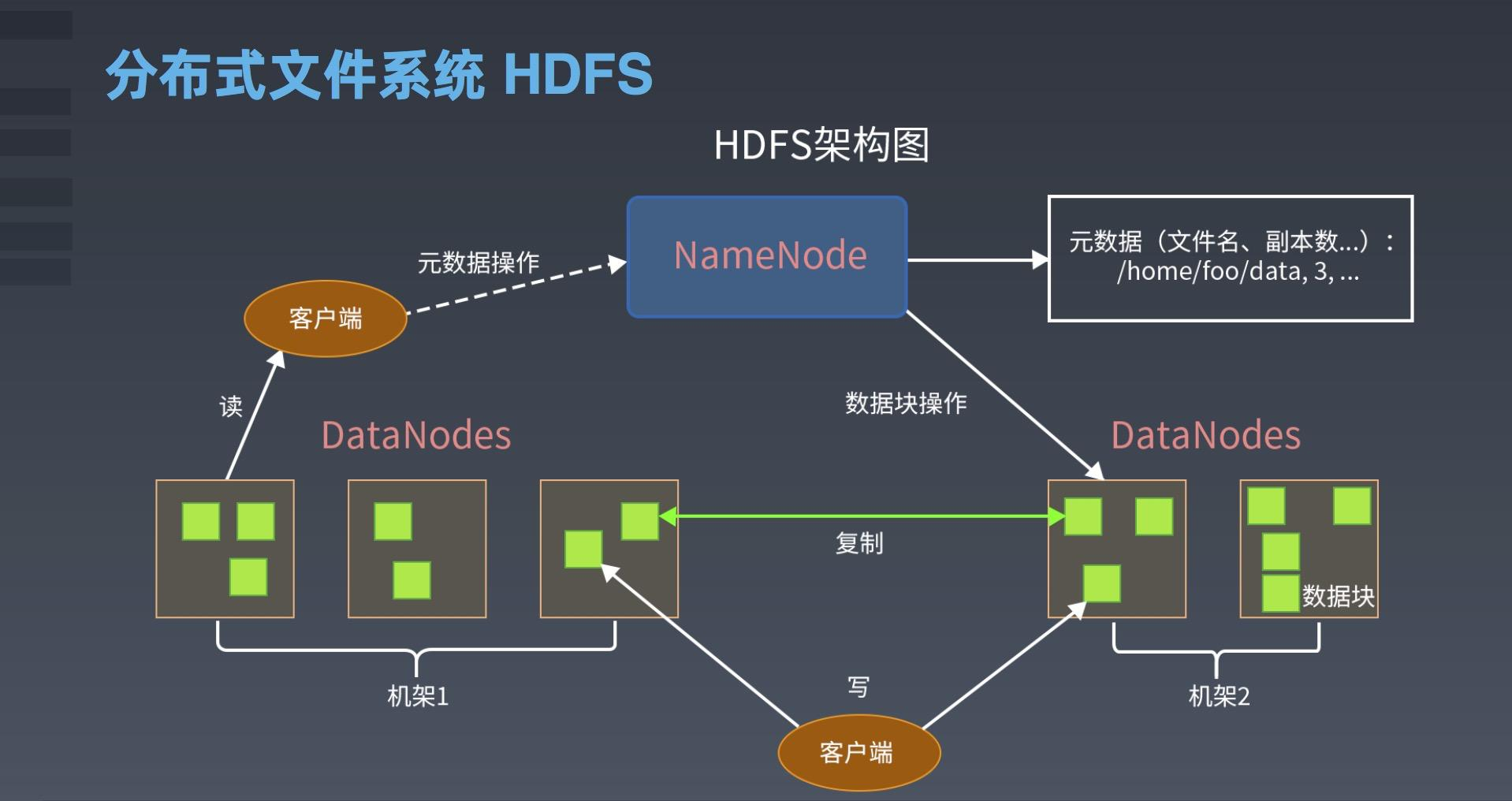
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
![]()
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 组件之间的相系关系
- 与HDFS的关联

(1)HMaster:
- 监控RegionServer
- 处理RegionServer故障转移、处理源数据变更
- 处理region的分配与移除
- 空闲时进行数据的负载均衡
- 通过ZK发布自己的位置给客户端连接:
(2)RegionServer
- 负责与hdfs交互,存储数据到hdfs中
- 处理hmaster分配的region
- 刷新缓存到hdfs
- 维护hlog
- 执行压缩
- 处理region分片
- 处理来自客户端的读写请求
(3)Client
- Client包含了访问Hbase的接口
- 维护对应的cache来加速Hbase的访问,比如MATE表的元数据信息
(4)Zookeeper
- Zookeeper主要负责master的高可用
- RegionServer的监控
- 元数据的入口以及集群配置的维护工作。
(5)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:提供元数据和表数据的底层分布式存储服务;数据多副本,保证的高可靠和高可用性。
-
5.理解并描述Hbase表与Region的关系。
Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上,但并不是存储的最小单元。
Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。HBase通过将region切分在许多机器上实现分布式。
6.理解并描述Hbase的三级寻址。
三级寻址对应了三层表:
(1) -ROOT-表:存储元数据表,即.MEAT.表的信息。它被“写死”在ZooKeeper文件中,是唯一的、不能再分裂的
(2) .META.表:存储用户数据具体存储在哪些Region服务器上。它会随存储数据的增多而分裂成更多个。
(3) 用户数据表:具体存储用户数据。它是最底层的、可分裂的寻址过程:(1) ZooKeeper找到-ROOT-表地址
(2) -ROOT-表中找到需要的.META.表地址
(3) .META.表找到所需的用户数据表地址
(4) 最后从用户数据表取出目标数据7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
![]()
(2G/1K)x(2G/1k)=242 即2ZB
所以上Hbase的数据表最大有2 -
-
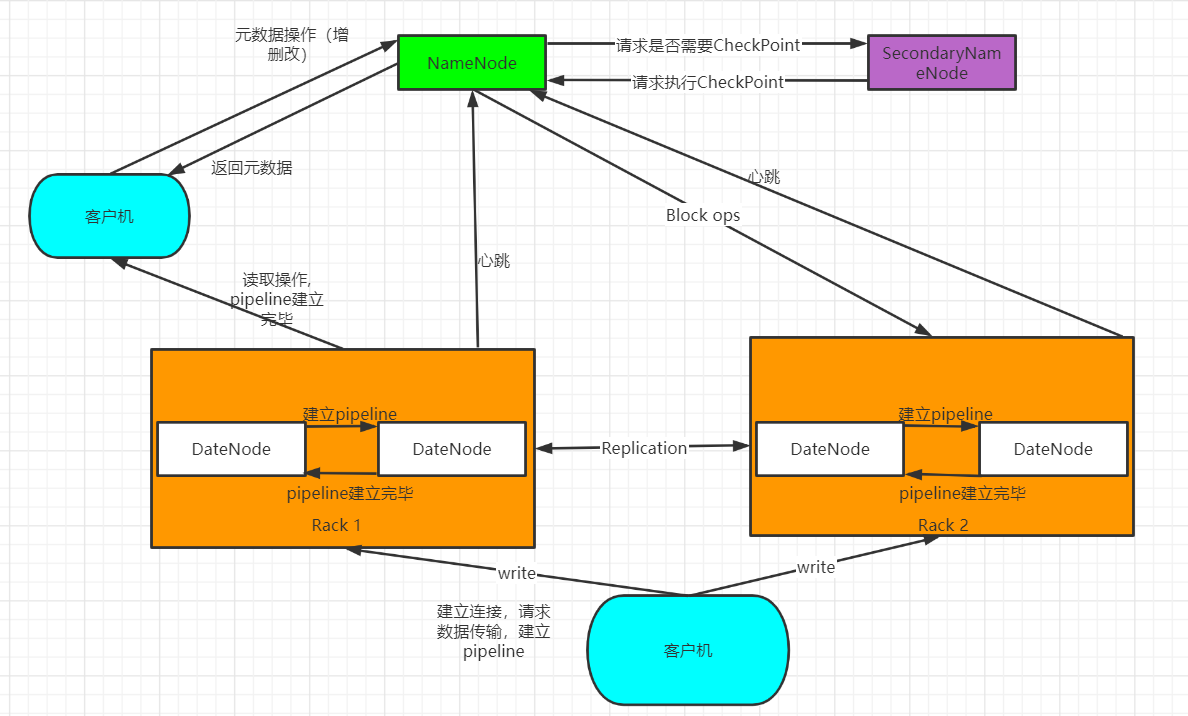
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
![]()
a)client客户端
每一个Job都会在用户端通过Client类将应用程序以及参数配置Configuration打包成Jar文件存储在HDFS,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask),将它们分发到各个TaskTracker服务中去执行。
b)JobTracker
JobTracker负责资源监控和作业调度。JobTracker监控所有的TaskTracker与job的健康状况,一旦发现失败,就将相应的任务转移到其它节点;同时JobTracker会跟踪任务的执行进度,资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用于可以根据自己的需要设计相应的调度器。
c)TaskTracker
TaskTracker会周期性地通过HeartBeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时执行JobTracker发送过来的命令 并执行相应的操作(如启动新任务,杀死任务等)。
d)Task
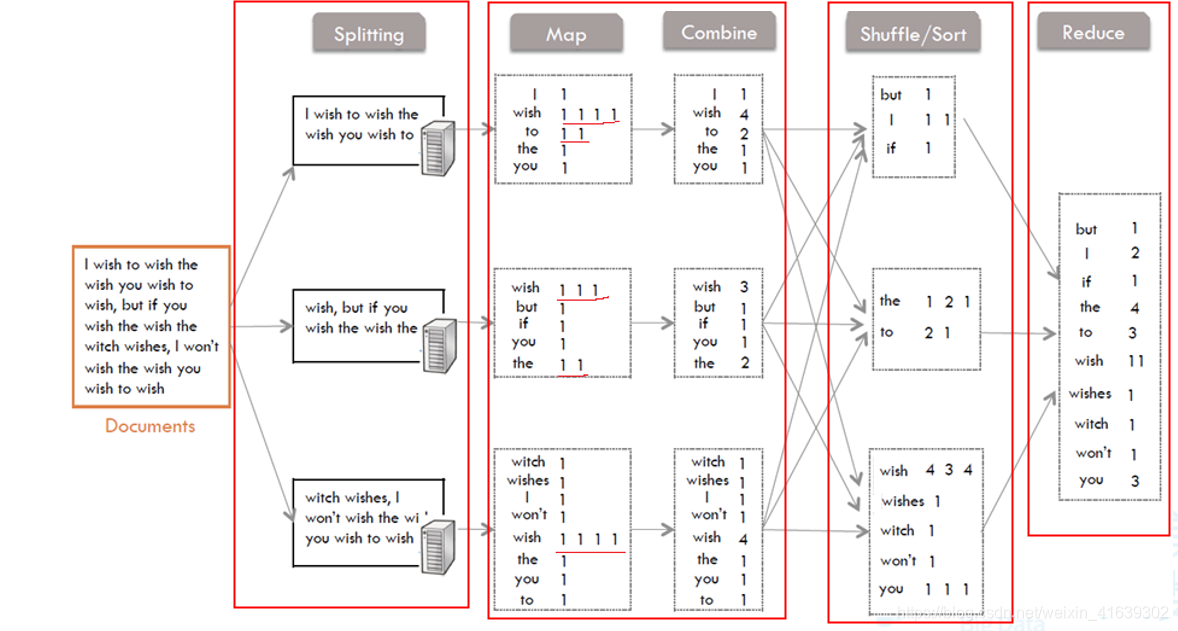
Task分为MapTask和Reduce Task两种,均由TaskTracker启动9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。
![]()
1、Splitting部分
把要读取的文件分成几个部分,分到不同的机器上实现并行处理。2、Map和Combine部分
从Splitting部分接收到文件的一部分,Map将字符切割后得到了一些键值对<key,value>,key就是每一个单词,value就是根据单词的出现频次得到的:(1,1,1,1,1…)出现多少次就有多少个1。
然后再由Combine进行局部的统计后,又得到了一些键值对<key,value>,这里的value就是Map中的1相加的结果。
3、Shuffle/Sort部分
这里是Mapper和Reducer的中间部分,它的每一个处理步骤都分散在map task和reduce task节点上,整体看来,就是对Map的结果进行分区、排序、分割。也就是对Combine中的value进行分区,排序后合并。
4、Reduce部分
接受经过Shuffle后得到的<key,value>,把各value的值相加,得到最后每一个单词的出现次数。 -
-
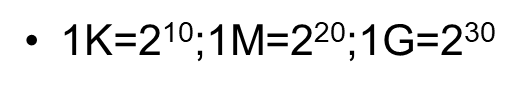

 浙公网安备 33010602011771号
浙公网安备 33010602011771号