
Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言
介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流;

图 1 项目介绍
1. 开发环境
Python: 3.6.3
BeautifulSoup: 4.2.0 , 是一个可以从HTML或XML文件中提取数据的Python库*
( BeautifulSoup 的中文官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ )
2. 介绍
首先需要知道什么是 HTML ( Hypertext Markup Language,超文本标记语言 ) :
HTML 是用来描述网页的一种语言*:
-
- HTML 指的是超文本标记语言 (Hyper Text Markup Language)
- HTML 不是一种编程语言,而是一种标记语言 (markup language)
- 标记语言是一套标记标签 (markup tag)
- HTML 使用标记标签来描述网页
代码实现主要分为三个模块:
1. 计时 / second cnt
因为是周期性爬取,所以需要计时器来控制;
2. 设置代理 / set proxy
为了应对网站的反爬虫机制,需要切换代理;
3. 爬虫 / web spider
利用 requests 请求网站内容,然后 beautifulsoup 提取出所需信息;
利用 requests.get() 向服务器发送请求 >>> 拿到 html 内容 >>> 交由 beautifulsoup 用来解析提取数据;
先看一个 requests 和 beautifulsoup 爬虫的简单例子:
requests :
>>> requests.get(html, headers=headers, proxies=proxies)
>>> # headers 和 proxies 是可选项 / optional
发送请求给网站,然后拿到返回的 HTML 内容,转换为 beautifulsoup 的对象,bs负责去提取数据;
1 from bs4 import BeautifulSoup 2 import requests 3 html = "https://www.xxx.com" 4 headers = { 5 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' 6 } 7 proxies = "114.231.xx.xx:xxxx" 8 9 resp = requests.get(html, headers=headers, proxies=proxies) 10 resp.encoding = 'utf-8' 11 12 bsObj = BeautifulSoup(resp.content, "lxml")
本文以爬取 https://www.ithome.com/blog/ 为例,把页面上的新闻爬取下来,过滤掉多余信息,拿到 新闻时间 & 新闻标题 ;
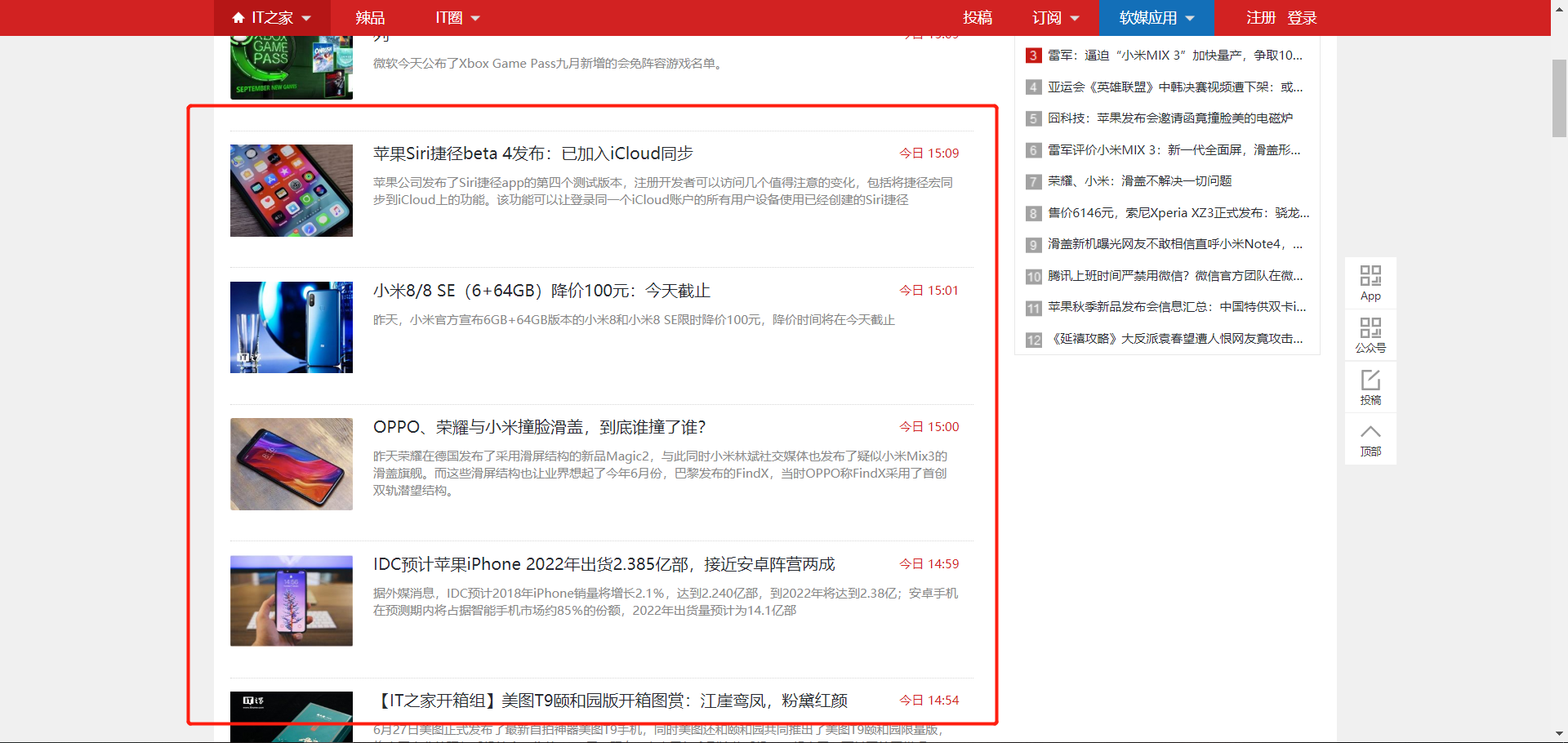
图 2 网站界面
拿到网站的 html 代码之后,如何剥离出自己想要的数据,参考图 3 的流程:
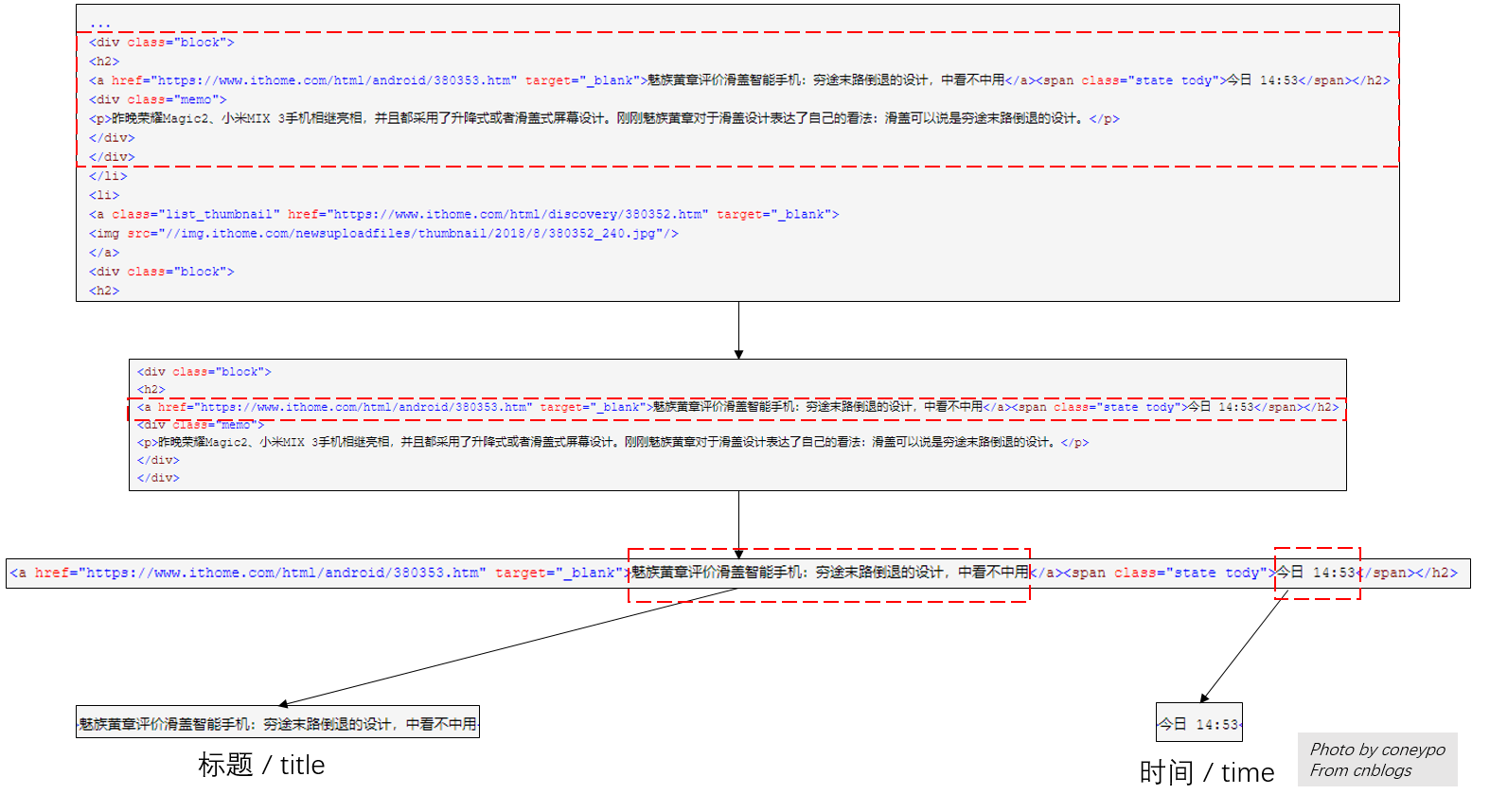
图 3 从 html 中 剥离数据的流程
首先看看 bsObj = BeautifulSoup(resp.content, "lxml") 拿到的 目标网站 ( https://www.ithome.com/blog/ ) 的 HTML 代码,这个HTML代码也就是浏览器打开网页然后F12得到的当前网页的代码;
HTML代码描述了网页的排版布局文本图片等内容,浏览器就是提供渲染HTML代码的功能;
拿到的 xxxx.com 的网页HTML代码:
...
<div class="block"> <h2> <a href="https://www.ithome.com/html/android/380353.htm" target="_blank">魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用</a><span class="state tody">今日 14:53</span></h2> <div class="memo"> <p>昨晚荣耀Magic2、小米MIX 3手机相继亮相,并且都采用了升降式或者滑盖式屏幕设计。刚刚魅族黄章对于滑盖设计表达了自己的看法:滑盖可以说是穷途末路倒退的设计。</p> </div> </div> </li> <li> <a class="list_thumbnail" href="https://www.ithome.com/html/discovery/380352.htm" target="_blank"> <img src="//img.ithome.com/newsuploadfiles/thumbnail/2018/8/380352_240.jpg"/> </a> <div class="block"> <h2> <a href="https://www.ithome.com/html/discovery/380352.htm" target="_blank">俄罗斯计划“世界级”研究中心,拟克隆猛犸象</a><span class="state tody">今日 14:48</span></h2> <div class="memo"> <p>俄罗斯科学家计划用保存的冰河时代遗骸的DNA,在一个耗资450万英镑的新侏罗纪公园中心克隆猛犸象</p> </div> </div> </li> <li> <a class="list_thumbnail" href="https://lapin.ithome.com/html/digi/380351.htm" target="_blank"> <img src="//img.ithome.com/newsuploadfiles/thumbnail/2018/8/380351_240.jpg"/> </a> <div class="block"> <h2>
...
然后我们就需要在这 HTML 代码中借助 find() 函数 提取出我们所需要的数据;
关于 find() 函数的参数:
# Author: coneypo # 返回查找到的内容 find(tag=None, attrs={}, recursive=True, text=None, **kwargs) # 返回查找到的内容列表 findAll(tag=None, attrs={}, recursive=True, text=None, limit=None, **kwargs) # tag 标签参数 tag='p' # attrs 属性参数 {'href':"www.xxx.com"} # recursive 递归参数 True: 递归向下查询/ False: 只查询一级标签 # text 文本参数 text="hello world" # limit 范围限制参数 保留查询结果的前n项 / findall(limit=1) 等于 find() # kwargs 关键词参数 id="header1"
关于 find() 函数的使用:
# 1. find(tagname) # 查找名为 <p> 的标签 find('p') # 2. find(list) # 查找列表中的所有标签,<p>,<body> find(['p', 'body']) # 3. find(dict) # 查找字典中标签名和值匹配的标签 <a href="www.xx.com" target="_blank"> find({'target': "_blank", 'href': "wwww.xx.com"}) # 4. find('id'='xxx') # 寻找id属性为xxx的<h1 id="myHeader">Hello World!</h1> find('id'='myHeader')

图 4 find() 函数的匹配
接下来就是利用 find() 一层层筛选 HTML 代码;
首先定位到 <div class="block" >;
>>> block = bsObj.find_all("div", {"class": "block"})
<div class="block"> <h2> <a href="https://www.ithome.com/html/android/380353.htm" target="_blank"> 魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用</a>
<span class="state tody">今日 14:53</span>
</h2> <div class="memo"> <p>昨晚荣耀Magic2、小米MIX 3手机相继亮相,并且都采用了升降式或者滑盖式屏幕设计。刚刚魅族黄章对于滑盖设计表达了自己的看法:滑盖可以说是穷途末路倒退的设计。</p> </div>
接下来就是要提取出 新闻标题 title 和 新闻时间 time;
注意 “block” 是用 find_all() 拿到的,返回的是一个 list 列表,遍历这个列表,去找 title & time;
对于单个的 "block",比如 block[i]:
提取新闻时间:
>>> block[i].find('span', {'class': "state tody"})
<span class="state tody">今日 14:53</span>
然后
>> block[i].find('span', {'class': "state tody"}).get_text()
得到 time 内容:
今日 14:53
提取新闻标题:
>>> block[i].find('a', {'target': "_blank"})
<a href="https://www.ithome.com/html/android/380353.htm" target="_blank">魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用</a>
然后
>> block[i].find('a', {'target': "_blank"}).get_text()
得到 title 内容:
魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用
这样就可以拿到了 新闻标题 titile 和 新闻时间 time了;
3. 代码实现
1. 计时器
这里是一个秒数计数功能模块,利用 datetime 这个库,获取当前时间的秒位,和开始时间的秒位进行比对,如果发生变化,sec_cnt 就 +=1;
sec_cnt 输出 1,2,3,4,5,6...是记录的秒数,可以由此控制抓包时间;
>>> time = datetime.datetime.now() # 获取当前的时间,比如:2018-08-31 14:32:54.440831
>>> time.second() # 获取时间的秒位
second_cnt.py:
1 # Author: coneypo 2 # Created: 08.31 3 4 import datetime 5 6 # 开始时间 7 start_time = datetime.datetime.now() 8 tmp = 0 9 # 记录的秒数 10 sec_cnt = 0 11 12 while 1: 13 current_time = datetime.datetime.now() 14 15 # second 是以60为周期 16 # 将开始时间的秒 second / 当前时间的秒 second 进行对比; 17 # 如果发生变化则 sec_cnt+=1; 18 if current_time.second >= start_time.second: 19 if tmp != current_time.second - start_time.second: 20 # print("<no 60>+ ", tmp) 21 sec_cnt += 1 22 print("Time_cnt:", sec_cnt) 23 # 以 10s 为周期 24 if sec_cnt % 10 == 0: 25 # do something 26 pass 27 tmp = current_time.second - start_time.second 28 29 # when get 60 30 else: 31 if tmp != current_time.second + 60 - start_time.second: 32 sec_cnt += 1 33 print("Time_cnt:", sec_cnt) 34 35 # 比如以 10s 为周期 36 if sec_cnt % 10 == 0: 37 # do something 38 pass 39 tmp = current_time.second + 60 - start_time.second
2. set_proxy / 设置代理
这个网站可以提供一些国内的代理地址: http://www.xicidaili.com/nn/ ;
因为现在网站可能会有反爬虫机制,如果同一个 IP 如果短时间内大量访问该站点,就会被拦截;
所以我们需要设置代理,爬这个代理网站页面,拿到的 proxy 地址传,给 requests.get 的 proxies 参数:
>>> requests.get(html, headers=headers, proxies=proxies)
两个函数:
get_proxy(): 从代理网站爬取代理地址,存入本地的"proxies.csv"中;
get_random_proxy(): 从本地的"proxies.csv"中,随机选取一个代理proxy;
注意,xicidali.com也有反爬虫机制,亲身体验短时间大量爬数据ip会被block,而且我们一次爬取可以拿100个代理地址,所以只需要爬一次代理网站就行了,存到本地的csv中;
要代理从本地的csv中随机获取proxy地址;
csv可以定期的用 “get_proxy()” 进行更新;
get_proxy.py :
1 # Author: coneypo 2 # Created: 08.31 3 # Updated: 09.01 4 # set proxy 5 # save to csv 6 7 from bs4 import BeautifulSoup 8 import requests 9 import csv 10 import pandas as pd 11 import random 12 13 path_proxy_csv = "proxies.csv" 14 15 16 # 从 xicidaili.com 爬取代理地址,存入本地csv中 17 def get_proxy(): 18 headers = { 19 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' 20 } 21 proxy_url = 'http://www.xicidaili.com/nn/' 22 resp = requests.get(proxy_url, headers=headers) 23 soup = BeautifulSoup(resp.text, 'lxml') 24 ips = soup.find_all('tr') 25 proxy_list = [] 26 for i in range(1, len(ips)): 27 ip_info = ips[i] 28 tds = ip_info.find_all('td') 29 proxy_list.append(tds[1].text + ':' + tds[2].text) 30 31 if len(proxy_list) == 0: 32 print("可能被屏蔽了") 33 else: 34 print("拿到的代理个数:", len(proxy_list)) 35 with open(path_proxy_csv, 'w', newline="") as csvfile: 36 writer = csv.writer(csvfile) 37 for i in range(len(proxy_list)): 38 print(proxy_list[i]) 39 writer.writerow([proxy_list[i]]) 40 41 42 # get_proxy() 43 44 45 # 从代理的 csv 中随机获取一个代理 46 def get_random_proxy(): 47 column_names = ["proxy"] 48 proxy_csv = pd.read_csv("proxies.csv", names=column_names) 49 50 # 新建一个列表用来存储代理地址 51 proxy_arr = [] 52 53 for i in range(len(proxy_csv["proxy"])): 54 proxy_arr.append(proxy_csv["proxy"][i]) 55 56 # 随机选择一个代理 57 random_proxy = proxy_arr[random.randint(0, len(proxy_arr) - 1)] 58 59 print(random_proxy) 60 return random_proxy 61 62 # get_random_proxy()
3. get_news_from_xxx / 爬虫
由计时器的 sec_cnt 控制爬虫的周期 >> 每次先去 “proxies.csv” 拿代理 >> 然后交给 requests 去拿数据 >> 拿到 HTML 之后交给 beautiful 对象 >> 然后过滤出新闻流:
伪代码如下:
1 while 1: 2 if 周期到了: 3 获取代理地址; 4 requests 给目标网站发送请求; 5 获取到的HTML内容交给BeautifulSoup: 6 过滤出新闻标题和时间;
get_news_from_xxx.py 完整的代码:
1 # Author: coneypo 2 # Created: 08.31 3 # Updated: 09.01 4 # web spider for xxx.com 5 6 from bs4 import BeautifulSoup 7 import requests 8 import random 9 import datetime 10 import csv 11 import pandas as pd 12 13 14 headers = { 15 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' 16 } 17 18 19 # 从 xicidaili.com 爬取代理地址,存入本地csv中 20 def get_proxy(): 21 headers = { 22 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' 23 } 24 proxy_url = 'http://www.xicidaili.com/nn/' 25 resp = requests.get(proxy_url, headers=headers) 26 soup = BeautifulSoup(resp.text, 'lxml') 27 ips = soup.find_all('tr') 28 proxy_list = [] 29 for i in range(1, len(ips)): 30 ip_info = ips[i] 31 tds = ip_info.find_all('td') 32 proxy_list.append(tds[1].text + ':' + tds[2].text) 33 34 if len(proxy_list) == 0: 35 print("可能被代理网站屏蔽了", '\n') 36 else: 37 print("拿到的代理个数:", len(proxy_list), '\n') 38 with open("proxies.csv", 'w', newline="") as csvfile: 39 writer = csv.writer(csvfile) 40 for i in range(len(proxy_list)): 41 # print(proxy_list[i]) 42 writer.writerow([proxy_list[i]]) 43 44 45 # 执行一次就可以了; 46 # 执行一次可以更新本地代理地址; 47 get_proxy() 48 49 50 # 从存放代理的 csv 中随机获取一个代理 51 def get_random_proxy(): 52 column_names = ["proxy"] 53 proxy_csv = pd.read_csv("proxies.csv", names=column_names) 54 55 # 新建一个列表用来存储代理地址 56 proxy_arr = [] 57 58 for i in range(len(proxy_csv["proxy"])): 59 proxy_arr.append(proxy_csv["proxy"][i]) 60 61 # 随机选择一个代理 62 random_proxy = proxy_arr[random.randint(0, len(proxy_arr)-1)] 63 64 print("当前代理:", random_proxy) 65 return random_proxy 66 67 68 # 爬取网站 69 def get_news(): 70 html = "https://www.ithome.com/blog/" 71 resp = requests.get(html, headers=headers, proxies=get_random_proxy()) 72 resp.encoding = 'utf-8' 73 74 # 网页内容 75 bsObj = BeautifulSoup(resp.content, "lxml") 76 # print(bsObj) 77 78 # 分析 79 block = bsObj.find_all("div", {"class": "block"}) 80 # print(block) 81 82 current_titles = [] 83 current_times = [] 84 85 # analysis every block 86 for i in range(len(block)): 87 # get Time 88 time_classes = ["state tody", "state other"] 89 for time_class in time_classes: 90 tmp = block[i].find_all('span', {'class': time_class}) 91 if tmp: 92 current_time = (block[i].find('span', {'class': time_class})).get_text() 93 current_times.append(current_time) 94 95 # get Title 96 if block[i].find_all('a', {'target': "_blank"}): 97 current_title = (block[i].find('a', {'target': "_blank"})).get_text() 98 current_titles.append(current_title) 99 100 for i in range(len(current_times)): 101 print(current_times[i], current_titles[i]) 102 return current_times, current_titles 103 104 105 get_news() 106 107 # 计时 108 start_time = datetime.datetime.now() 109 tmp = 0 110 sec_cnt = 0 111 112 while 1: 113 current_time = datetime.datetime.now() 114 115 # second 是以60为周期 116 # 将开始时间的秒second / 当前时间的秒second 进行对比 117 if current_time.second >= start_time.second: 118 if tmp != current_time.second - start_time.second: 119 # print("<no 60>+ ", tmp) 120 sec_cnt += 1 121 print("Time_cnt:", sec_cnt) 122 if sec_cnt % 10 == 0: 123 get_news() 124 print('\n') 125 tmp = current_time.second - start_time.second 126 127 # when get 60 128 else: 129 if tmp != current_time.second + 60 - start_time.second: 130 sec_cnt += 1 131 print("Time_cnt:", sec_cnt) 132 133 if sec_cnt % 10 == 0: 134 get_news() 135 print('\n') 136 tmp = current_time.second + 60 - start_time.second
最终的输出 log:
1 拿到的代理个数: 100 2 3 当前代理: 111.155.124.73:8123 4 今日 13:53 你应该跳过三星Galaxy Note 9等待S10的5个理由 5 今日 13:49 索尼CEO回应联机争议:PS上最好玩,为何要跨平台? 6 今日 13:43 顺丰冷运/买6送4,阳澄湖鲜活六月黄大闸蟹10只旗舰店58元 7 今日 13:35 华为Mate 9、P10系列GPU Turbo升级已全面开放 8 今日 13:35 自如熊林:没有意愿“对付”谁,是自如的责任定承担 9 今日 13:33 《暗黑4》?暴雪尚有一个未公布的3A级动作游戏 10 今日 13:12 经典重生:Palm新Logo曝光 11 今日 13:07 安卓系统各版本最新份额:“奥利奥”接近15%,6.0、7.0占大头 12 今日 12:49 新研究称:世界低估了中国对全球科学的贡献 13 今日 12:48 韩春雨接受校方调查结果:论文存缺陷,研究过程不严谨 14 08月31日 中粮出品/宁夏中卫原产,悦活优选100枸杞蜂蜜454g×2瓶39.9元 15 今日 12:35 手机QQ iOS版v7.7.8正式版更新:新增多款高颜值滤镜 16 今日 12:23 网游总量调控,游戏暴利时代或终结 17 今日 12:12 直降30元,网易云音乐氧气耳机开学季大促99元 18 今日 12:08 美团点评IPO定价区间敲定:每股60-72港币 19 今日 12:05 索尼HX99、HX95卡片相机发布:大变焦、能拍4K视频 20 今日 11:30 自如回应“阿里员工租甲醛房去世”:需客观全面调查 21 今日 11:30 夏末清仓,森马企业店纯棉印花T恤19.9元包邮 22 今日 11:27 1198元!vivo Y81s正式开售:千元机也有高颜值 23 今日 11:24 猪的器官能移植给人类吗?科学家研究出了测试程序 24 今日 11:16 小米8/MIX 2S开始推送MIUI 10稳定版:全新系统UI 25 今日 11:11 2030年8亿人将被机器人取代,但这些职业竟还能保住饭碗! 26 08月31日 直降400元,汪峰FIIL随身星Pro降噪耳机799元新低开抢 27 今日 11:01 生存游戏《人渣》现纳粹纹身引批评,开发商移除并致歉 28 今日 10:56 雷柏外设开学季大促:机械键盘低至94元 29 今日 10:46 苹果AR开发的下一个动作:Maps地图应用 30 今日 10:46 屏幕边框已死,笔记本设计迎来新时代 31 今日 10:45 可口可乐CEO喝够了可乐,于是51亿美元买下COSTA咖啡 32 今日 10:41 放弃悟空问答,今日头条的第一次战略性撤退 33 今日 10:40 狂甩不掉,ZTM M8防水运动蓝牙耳机旗舰店29.9元(40元券) 34 今日 10:36 MagicScroll可变形平板电脑问世:采用卷轴式柔性屏 35 今日 10:34 等谷歌牌手表的可以散了,Pixel Watch今年不会有 36 今日 10:27 佳能全幅无反相机EOS R规格、照片全泄露了 37 今日 10:07 IFA2018:主打设计!微星发布P65 Creator笔记本电脑 38 今日 10:01 翻版“药神”:代购印度抗癌药后加价销售,12人被判刑 39 今日 9:56 359元, 西部数据My Passport 1T移动硬盘开学季大促新低 40 今日 9:43 媒体:ofo已拖欠云鸟、德邦等多家物流供应商亿元欠款 41 今日 9:40 巴菲特:苹果若收购特斯拉,我会支持 42 08月31日 双星旗舰店网面运动鞋69→39元、啄木鸟弹力牛仔裤109→59元 43 今日 9:31 NASA称国际空间站打补丁成功,气压保持稳定 44 今日 9:29 疑似华为Mate 20 Pro真机现身!三摄设计大变样 45 今日 9:25 一波曝光之后,谷歌Pixel 3/3 XL已现身FCC网站 46 今日 9:24 《赛博朋克2077》可独行出击可双人行动,还可以买房 47 今日 9:19 2899元,索尼 PlayStation 4 Pro 游戏主机秒杀新低 48 今日 9:17 河北科大:未发现韩春雨团队主观造假 49 今日 9:12 米粉平均月收入7485元?网友:算上雷军了吧 50 08月28日 3000mAh大容量,耐时旗舰店8节5号/7号锂铁电池19.9元 51 今日 8:56 网传顺丰3亿条数据在暗网出售,官方回应:非顺丰数据 52 今日 8:49 出版署严控网游总量,腾讯网易股价大跌 53 今日 8:46 为什么接你电话的客服总是解决不了问题? 54 Time_cnt: 1 55 Time_cnt: 2 56 Time_cnt: 3 57 Time_cnt: 4 58 Time_cnt: 5 59 Time_cnt: 6 60 Time_cnt: 7 61 Time_cnt: 8 62 ...
你就可以每隔 10s 刷新下该网站上面的新闻流;
刷新周期在 line 87:
>>> if sec_cnt % 10 == 0:
# 请尊重他人劳动成果,转载或者使用源码请注明出处:http://www.cnblogs.com/AdaminXie
# 项目源码上传到了我的 GitHub,如果对您有帮助,欢迎 Star 支持下:https://github.com/coneypo/Web_Spider
# 请不要利用爬虫从事恶意攻击或者违法活动

 浙公网安备 33010602011771号
浙公网安备 33010602011771号