NUWA
类似通用的模型,主要处理CV方面,包括多项从文本到视觉的任务。
提出的关键点:
一、数据处理
将文本、图像、视频数据均处理成为一个\(H*W*T*D\)的张量(HW为空间维度长宽、T为时间维度、D为向量的长度).
文本通过BPE处理为\(1*1*s*d\)的张量,s为序列长度,d为向量维度。
图像使用VQ-VAE(VQ-GAN)训练一个码书,从而将图像用码书的某项来表示。具体训练使用VQ-VAE的方法:
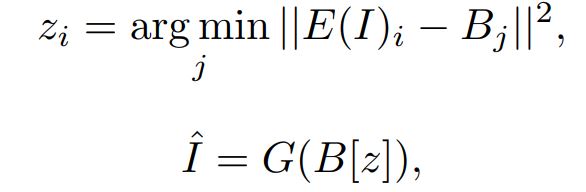
E即为一个encdoer将原始图像编码到特征空间,然后与码书B的进行比较,找到最接近的一项的下标。然后将码书这项经过decoder获得恢复图像\(\hat{I}\)。训练即将这个恢复图像和原始图像进行度量,训练码书和encoder-decoder。
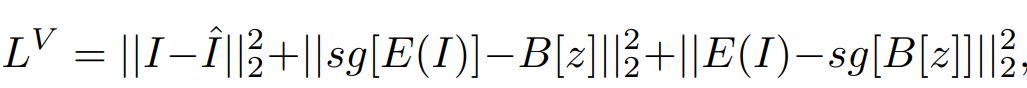
实际上码书就是一个隐藏空间的记录,用于将连续的隐空间向量转变为多个聚类中心,得到离散数目的隐空间向量。
但VQ-VAE的方法有局限,其难以处理数据的多样性,即泛化能力不足。因此引入VQ-GAN的做法:
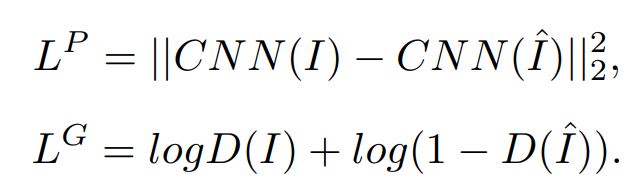
引入两个损失,perceptual loss和GAN loss。第一个感知loss应该是经过特征提取判断两个特征间的相似性。第二个对抗loss应该是经过判别器看是否能将两者(恢复的样本以及原始样本)区分出来。
最后,训练好后,将码书中的\(h*w*1*d\)的张量作为图像的token表示。
视频则和图像数据类似,仍保留2D的VQ-GAN的操作,原因是作者发现使用3D的VQ-GAN反而效果不好。
素描图像则看作是有特殊通道的图像。
二、3D Nearby Self-Attention(3DNA)
以往的self-attention考虑的是整个输入的每个位置之间的相关性,而这样的做法在图像上实际上有些弊端。首先是很多时候我们只会关注图像中的某部分因为很多都是背景。其次就是计算量会很大。因此作者提出了一个局部邻近区域的3D自注意力机制。看完论文的介绍感觉就是一个CNN和注意力机制的结合体。
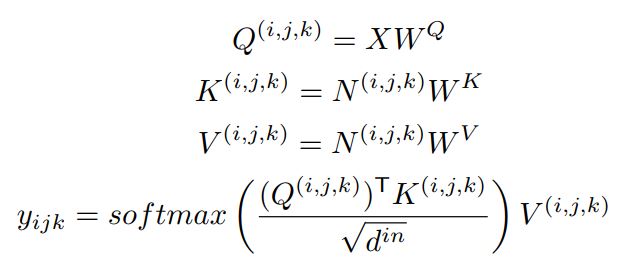
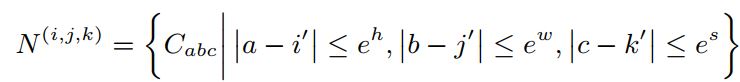
其中,C代表的是条件的输入而X是要去查询的输入。假设C是\(h^{'}*w^{'}*s^{'}*d^{in}\)的,而X是\(h*w*s*d^{in}\)的。那么对于在X中坐标为\((i,j,k)\)的位置,对应C中的坐标\((i^{'}, j^{'}, k^{'})\)则为\((\lfloor i\frac{h^{'}}{h}\rfloor, \lfloor j\frac{w^{'}}{w}\rfloor, \lfloor k\frac{s^{'}}{s}\rfloor)\).那么N就是通过这样的对应关系,从C中截取这部分周围一定范围\((e^{h}, e^{w}, e^{s})\),然后作为X的K与V的输入。直观上看,就像是一个固定大小的卷积核内进行了一个注意力机制。
三、3D encdoer-decoder
基于上面的3DNA模块,作者搭建了encoder-decoder的架构进行任务的处理。首先作者加入了位置编码。这里的位置编码将三个不同维度都进行了编码(空间的长宽以及时间维度)。条件C以及输入Y都添加位置编码。
首先encoder是L层的3DNA。其输入为条件C,经过L层的自注意力处理,得到\(C^{(L)}\).每层间的输入输出结果关系为:
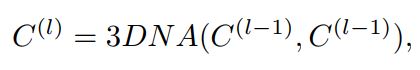
然后是decoder,也为L层的3DNA。其输入为输入Y以及encoder得到的\(C^{(L)}\).每层进行的是Y自身的self-attention以及Y与\(C^{(L)}\)之间的attention:
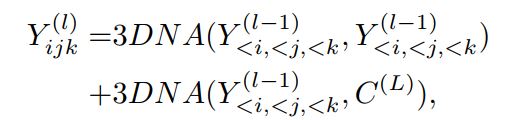
训练的loss为交叉熵损失。比如视频预测任务,即为decoder得到结果与Ground True之间的交叉熵损失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号