网络安全解题WP
1.HACKED创建
1.1 神奇二维码
题目链接:

拿到附件是一个二维码,扫码发现一个base64值
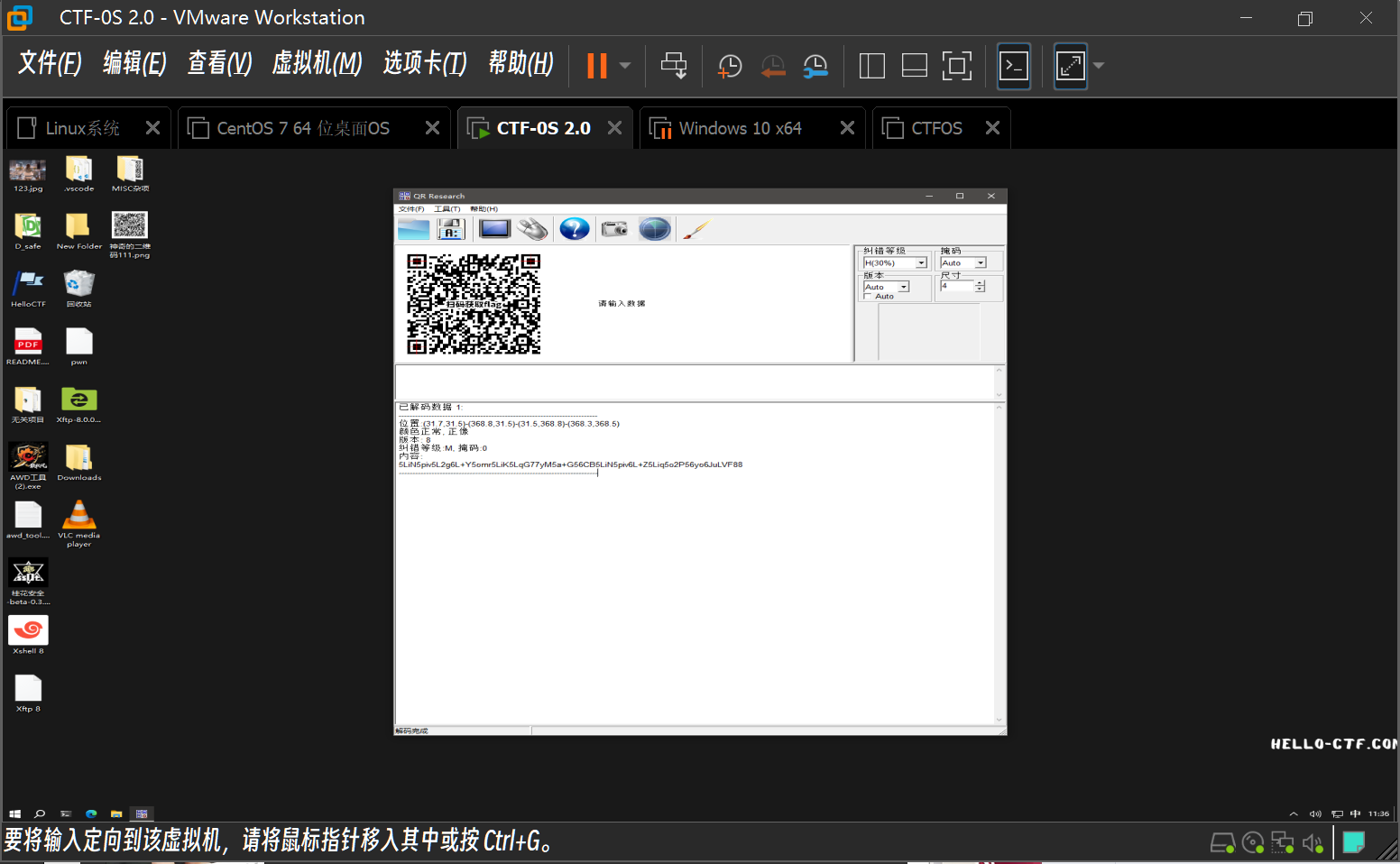
进行base64解析![]
拷贝的被骗了
一、大体思路
一般我们尝尝考察的就是二维码是不是有隐写,然后使用010 Editor这种分析工具去分析文件的结构构成,再考虑图片的隐写的常规思路
二、解题过程
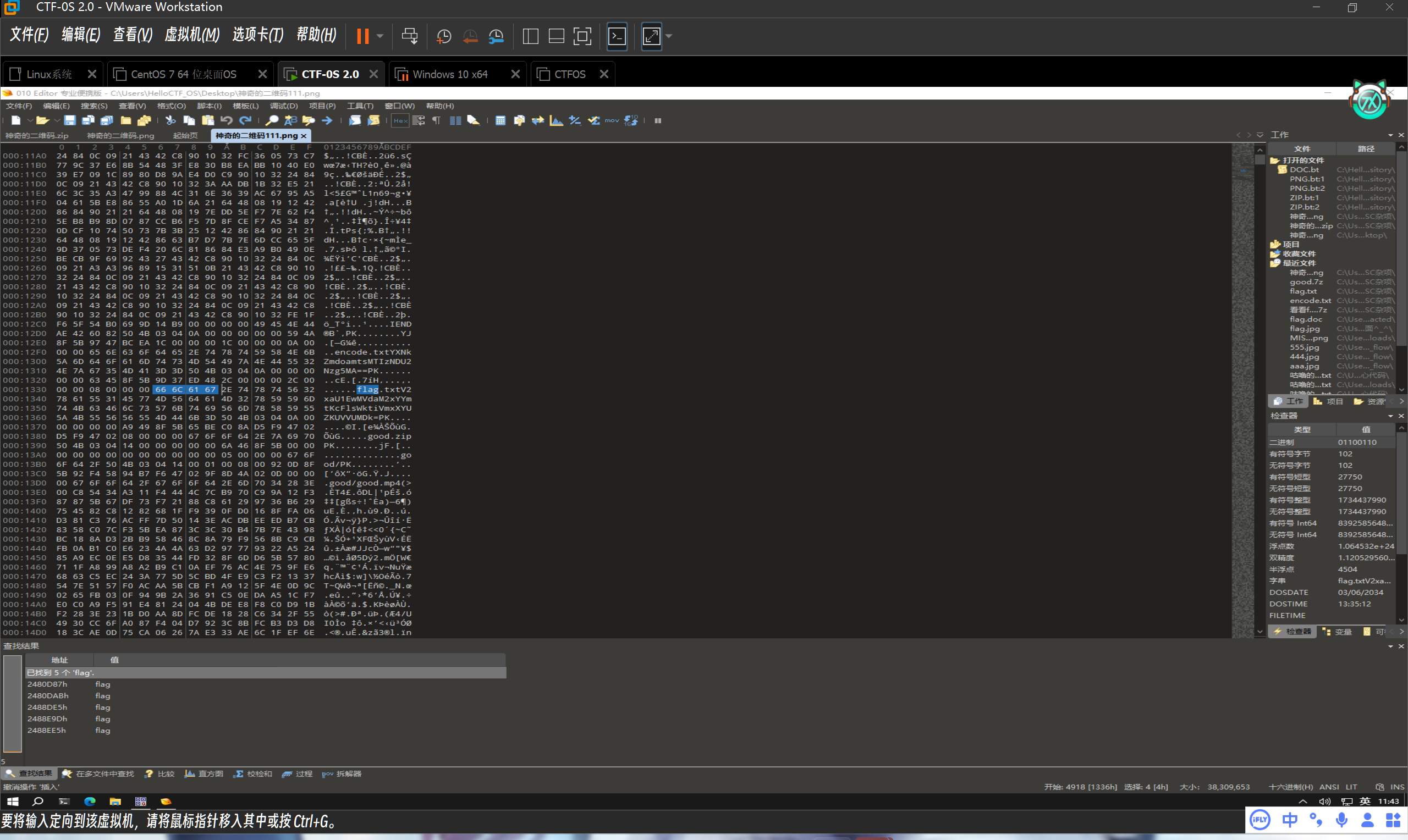
分析一下文件的大小,正常的二维码一般的字节大小都不会超过1MB,可能是一个二维码嵌套文件,用010分析
在010分析中发现出现了flag的字样,还是一个文件,那就是证实了,这个文件存在嵌套
用binwalk,formost分离工具分离文件
binwalk -e [file]
CTFtools-all-in-one
获取到一个压缩包,直接解压
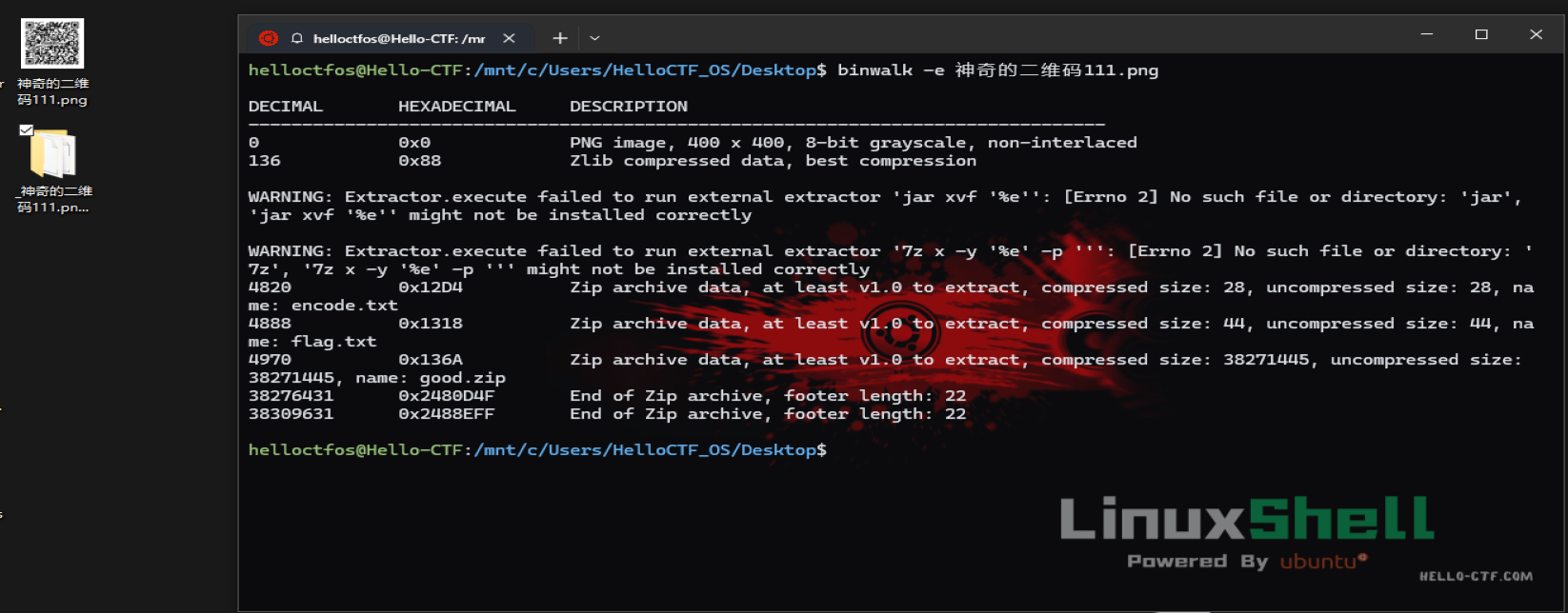
得到四个文件,说明已经解除第一层解码了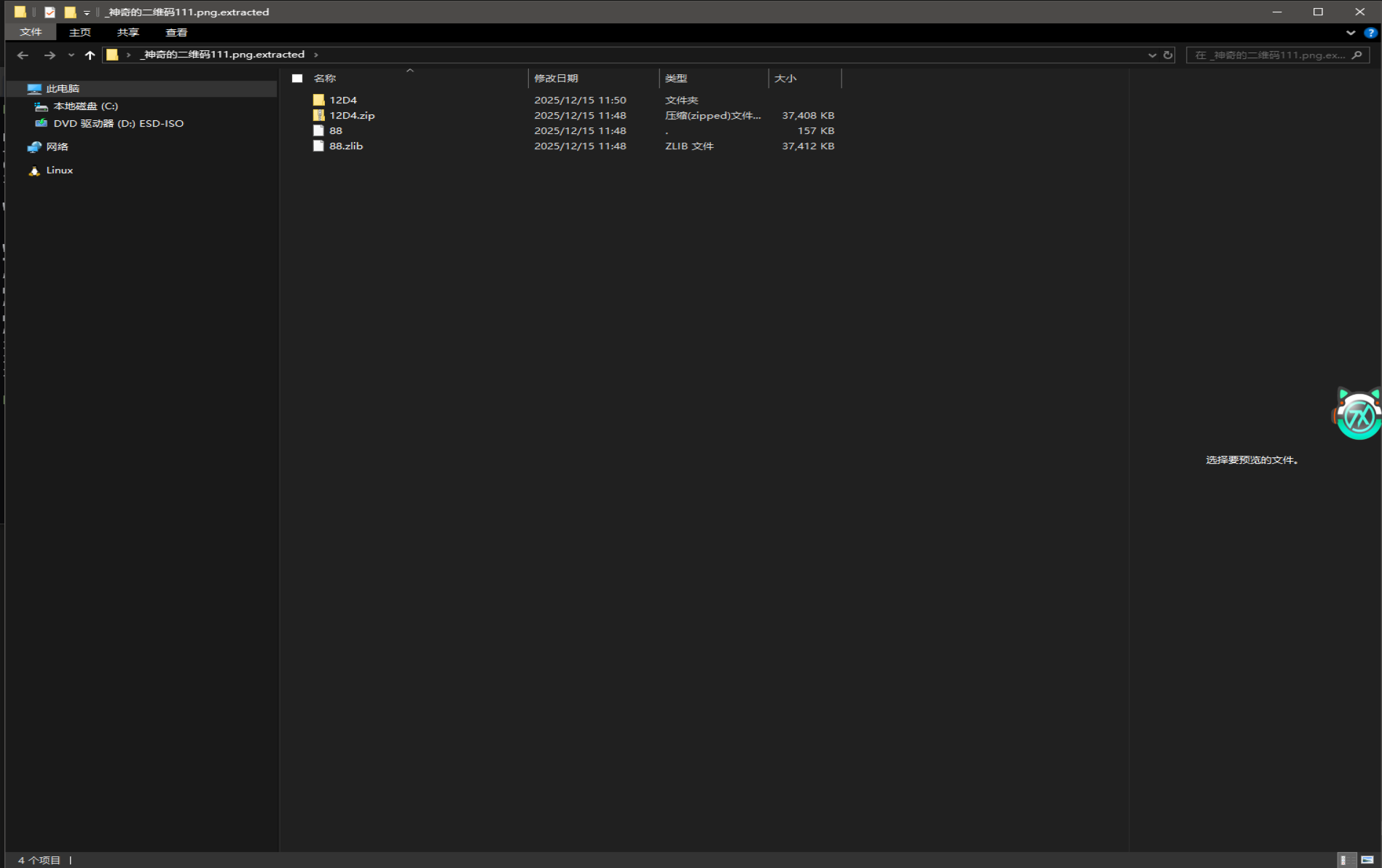
分别对压缩包进行解压,发现这两个压缩包都含有密码
肯定是打开flag.txt文件啦,没准flag直接给呢?(有这种好事吗?)

发现base64解码
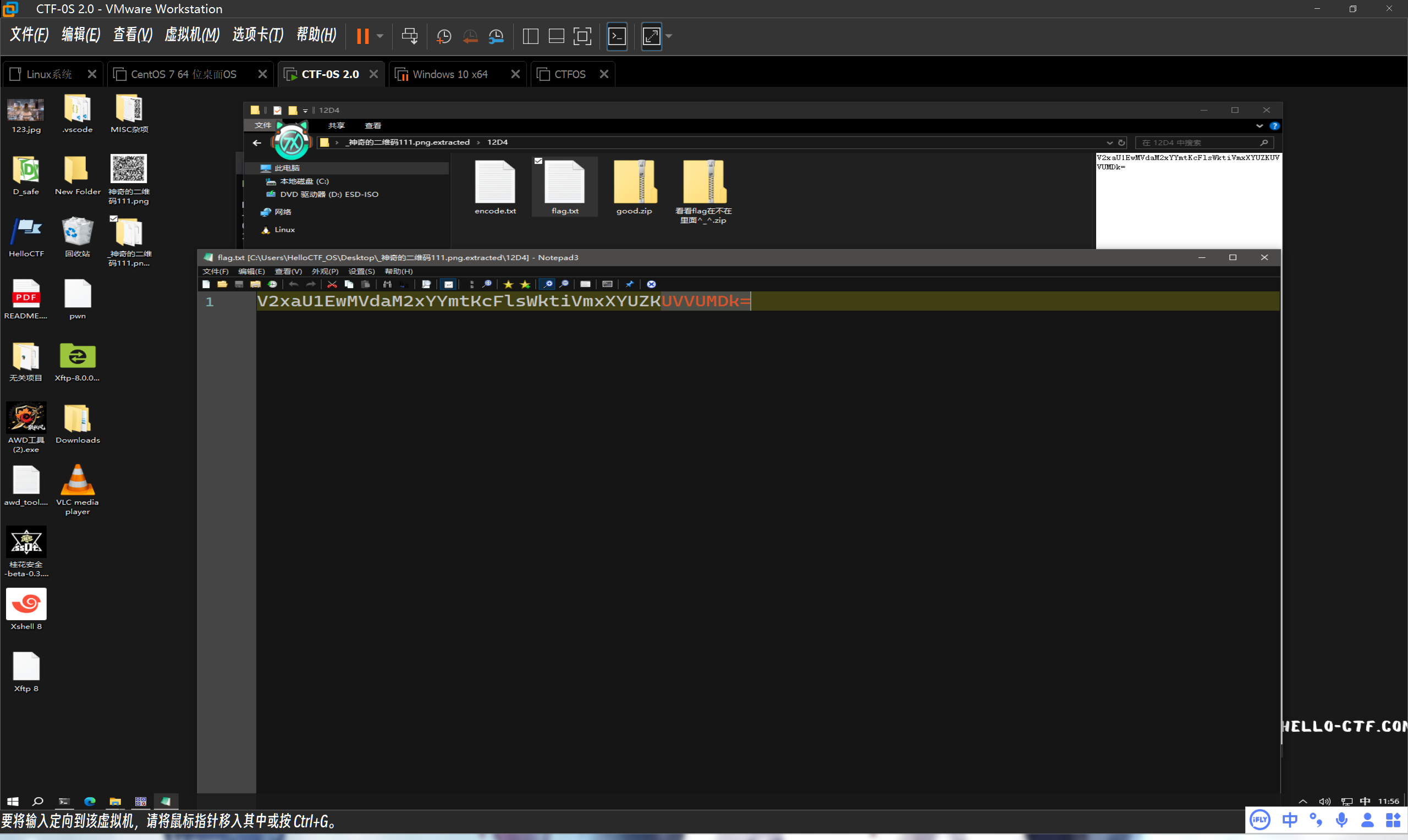
多次解密后获得到
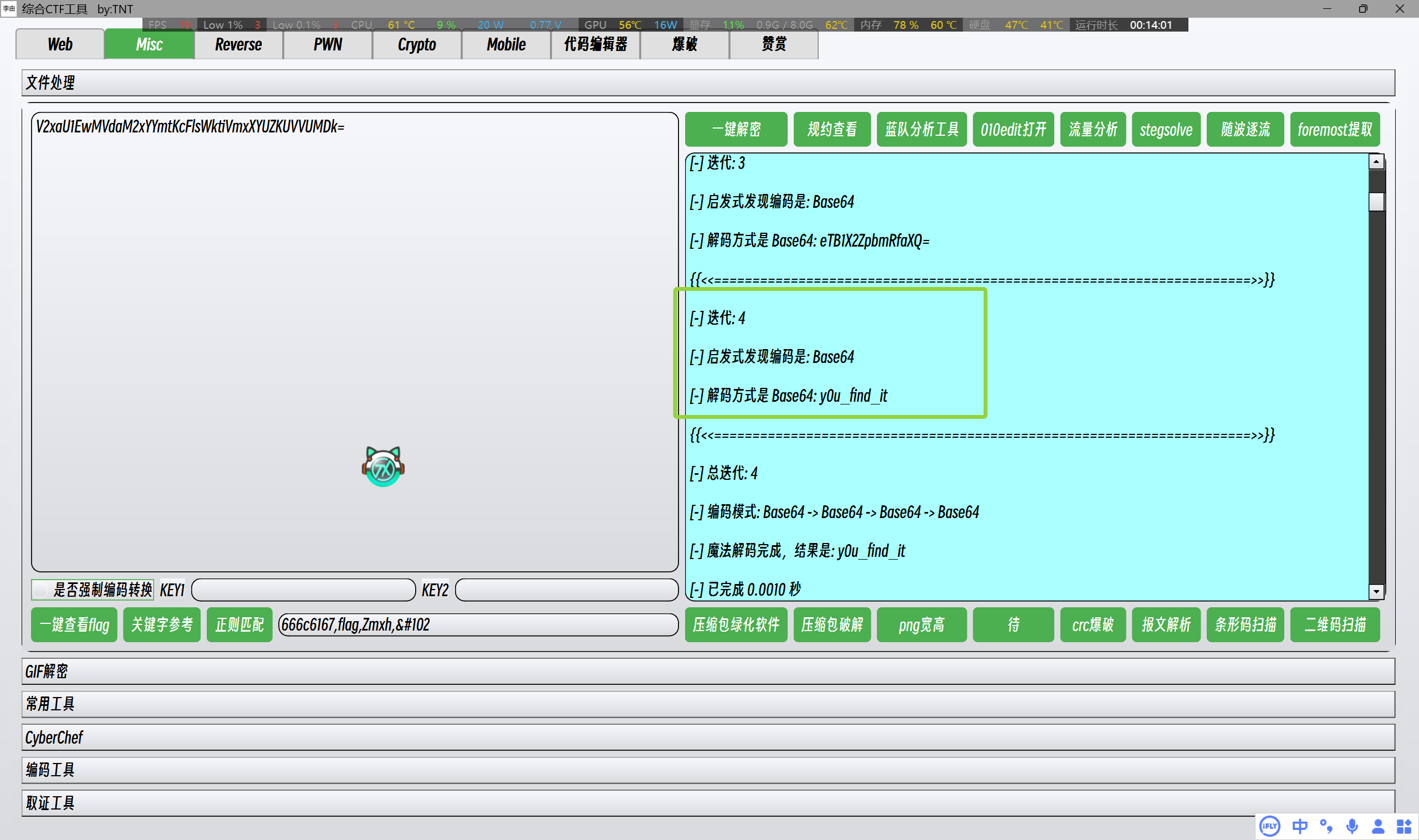
密码不对?!那就说明不是这个flag,狡诈的HACKED

说明这个密码可能是good.zip的密码,打开encode.txt又发现了base64,解析出来之后就是查看flag在不在里面的.zip的密码
得到一个图片,用binwalk和010分析他就是一个简单的图片而已。看来这个出题人的第二个坑(tips:完成到这里说明你已经很厉害了呢,完成了50%)
还记得我们刚刚获取到的y0u_find_it吗?这个可能是good.zip文件密码,解压里面的文件看看,得到了两个文件
对 真的是最后一步文件.7z解析发现出现HACKED生日.txt,不过这个压缩包也带了加密。那么密码可能就出现在good.mp4里边
题目提示了出现摩斯密码,在视频中出现了摩斯密码(考察摩斯解码)
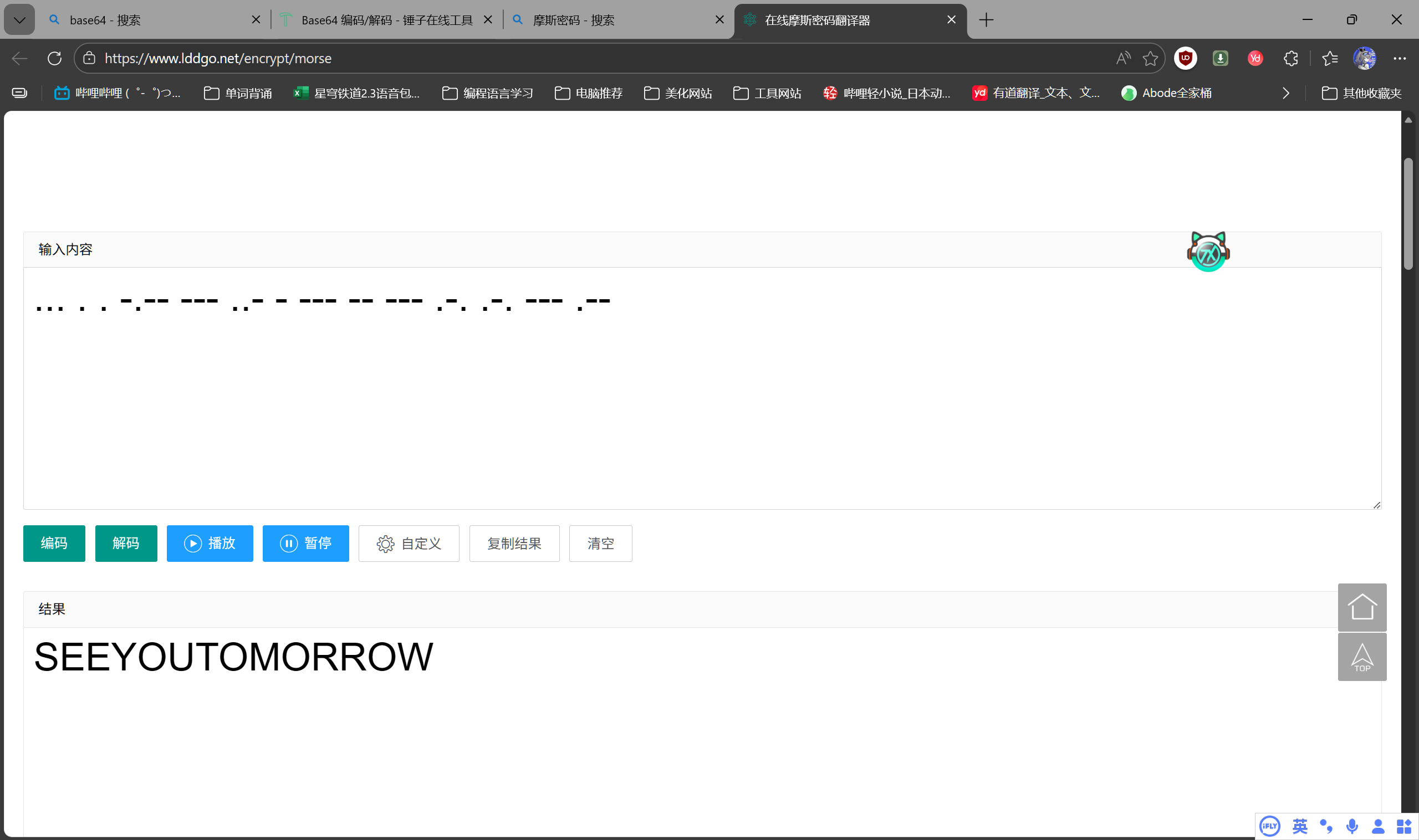
摩斯密码如下
... . . -.-- --- ..- - --- -- --- .-. .-. --- .--
(彩蛋ing)
获取到了最终的flag信息
2.Unictf
2.1 MISC
2.1.1 Silent Resolver
附件已经上传至gitee.com/ASUS-HACKED
题目链接:Silent Resolver | CTF+

这题一题经典的流量分析题目
附件是一个traffc.pcapng格式文件,对其进行协议解析,发现大量的UDP协议UDP协议是什么?作用是什么?_udp是什么协议-CSDN博客
一、什么是 UDP 协议(人话版)
UDP = User Datagram Protocol(用户数据报协议)
一句话概括:
UDP 是“发完就算,不管你收没收到”的传输协议
1.和 TCP 的核心区别
| 对比项 | TCP | UDP |
|---|---|---|
| 是否连接 | 需要三次握手 | ❌ 不需要 |
| 是否可靠 | ✔ 保证到达、顺序正确 | ❌ 不保证 |
| 是否有重传 | ✔ 有 | ❌ 没有 |
| 是否有流 | ✔ 有流的概念 | ❌ 一个包一个包 |
| 速度 | 较慢 | 🚀 很快 |
| 常见用途 | HTTP / HTTPS / SSH | DNS / 视频 / 游戏 / CTF |
👉 UDP 更像“扔纸条”,TCP 像“打电话确认你听到了”。
2.UDP 包结构(CTF 会考)
一个 UDP 包非常简单:
[ Source Port ][ Dest Port ][ Length ][ Checksum ][ Data... ]
重点只有一个:Data(载荷)
👉 CTF 中 99% 的信息都藏在 UDP Payload 里
3.CTF 流量分析里,UDP 常见“坑点”
下面这些你在题里几乎一定会遇到 👇
UDP 没有“会话”,包是散的
TCP 有 Stream(Follow TCP Stream)
UDP 没有
在 Wireshark 里你会发现:
- Follow UDP Stream → 内容很碎
- 顺序可能是乱的
- 丢包也没人管
👉 你要自己“拼包”
顺序可能是乱的(非常重要)
UDP 不保证顺序:
包 5
包 2
包 9
包 1
CTF 常见做法:
- 用 时间戳
- 用 序号字段
- 用 IP ID / 自定义字段
👉 很多 UDP 题 必须排序后才能还原数据
一个 UDP 包 ≠ 一段完整数据
常见套路:
- 一个 flag 被拆成几十 / 上百个 UDP 包
- 每个包只有几字节
你需要:
- 提取所有 UDP payload
- 拼接
- 再解码(base64 / base32 / hex / xor)
UDP 经常被用来“藏数据”
因为它:
- 不可靠
- 不显眼
- 很少有人认真看
CTF 中 UDP 常用来:
| 隐藏方式 | 举例 |
|---|---|
| 明文拼接 | 每包一个字符 |
| 编码 | Base64 / Base32 / Hex |
| XOR | 固定 key |
| 位运算 | 每包一 bit |
| 时间信道 | 包的时间间隔 |
你之前遇到的 Base32 拼 UDP 包,就是典型玩法 😄
4.CTF 中分析 UDP 的标准流程(实战版)
Step 1️⃣ 只看 UDP
Wireshark filter:
udp
或者:
udp.port == 53
udp.port == 12345
Step 2️⃣ 找“异常的 UDP”
重点关注:
- 非常多的 UDP 包
- payload 长度固定
- 端口奇怪(不是 53 / 123 / 67)
- 同一对 IP 疯狂通信
Step 3️⃣ 导出 Payload
Wireshark:
Statistics → Conversations → UDP → Follow Stream
或者:
File → Export Packet Dissections → As Raw Data
Step 4️⃣ 自己写脚本处理(CTF 必会)
典型 Python 操作:
from scapy.all import rdpcap, UDP
pkts = rdpcap("traffic.pcap")
data = b""
for p in pkts:
if UDP in p:
data += bytes(p[UDP].payload)
print(data)
然后你会继续:
- base64 / base32 解码
- xor
- 转 hex
- 当文件写出来再
file
二、Silent Resolver续解
回到题目本身
 会发现:
会发现:
- 所有 UDP 流量都被识别为 DNS
- 端口号为 53
1.DNS 的重要特性(小白版)
- DNS 基于 UDP
- DNS 查询中的 域名字段是明文
- 域名字段可以被用来偷偷传数据
👉 CTF 中非常经典的“DNS 隧道”套路
2.观察 DNS 查询内容
按照大小进行排序,优先观察大的DNS
Domain Name:
0003.cqjmaqefadcqaaaaaiabegkjk4wybteejyaaaaanqaaaaaqaaa.a1b2c3d4.exfil.unictf.local
逐段解释每一部分是干嘛的(0 基础版)
1️⃣ 0003 —— 分片序号
- 这是 编号
- 表示这是 第 3 片数据
👉 因为:
- UDP 没有顺序
- DNS 查询可能乱序到达
- 所以必须有“编号”字段
📌 这解释了为什么不能直接按抓包顺序拼
2️⃣ cqjmaqefadcqaaaaaiabegkjk4wybteejyaaaaanqaaaaaqaaa —— 真正的数据
观察它的特征:
- 只包含:
a–z+2–7 - 长度接近 52 字符
- 没有特殊符号
👉 这就是 Base32 编码后的数据
3️⃣ a1b2c3d4 —— 会话 / ID 标识
- 所有 DNS 查询里都一样
- 不参与解码
- 用来区分不同“数据传输会话”
👉 在真实 DNS 隧道里叫 Session ID
4️⃣ exfil —— 明示行为
exfil = exfiltration(数据外泄)- 出题人给你的 超强提示
5️⃣ unictf.local —— 域名伪装
local是保留域- 这个域名 根本不需要真实存在
- 只是为了让 DNS 查询合法
可以把每个 DNS Query 看成:
[序号].[Base32数据].[会话ID].exfil.unictf.local

逐步按照编号提取到如下的 DNS Query
0001.wgczzoor4hic6nzn2a44nloyy4qk4jb4utekjorf37cc4ob4wd.a1b2c3d4.exfil.unictf.local: type A, class IN
0002.klrsjqwy4n6pgcxiz5zvjthsrcpxgbgdddqpgzhc4mrofgxaka.a1b2c3d4.exfil.unictf.local: type A, class IN
0003.cqjmaqefadcqaaaaaiabegkjk4wybteejyaaaaanqaaaaaqaaa.a1b2c3d4.exfil.unictf.local: type A, class IN
0004.aaaaaaaaaaaaaaeaaeaaaaaamzwgczzoor4hiuclaudaaaaaaa.a1b2c3d4.exfil.unictf.local: type A, class IN
0005.aqaaiagyaaaac6aaaaaaaa.a1b2c3d4.exfil.unictf.local: type A, class IN
ffff.1818be0b.a1b2c3d4.exfil.unictf.local: type A, class IN
注意哈:有重复的,就选一个同一个就行
如果你细心的话就会发现0004的base32解析之后

说明这个是一个压缩包文件的片段,我们需要组合,同时注意的是
DNS 里的 Base32 ≠ Python 默认
Base32Python 的 base64.b32decode 要求的是:
-
RFC4648 Base32
-
字符集:
A-Z 2-7 -
长度必须是 8 的倍数
-
需要 padding(=)
DNS exfil 里几乎从来不用“标准 Base32”,因为:
=在 DNS label 里不合法- 大小写、长度都会被破坏
- 所以出题人通常用:
- 无 padding Base32
- 自定义 alphabet
- Base32hex
- 或 压缩后再 Base32
“Base32 是有分块边界的”
这是最核心的一点。
Base32 的本质是:
5 个 bit 一组编码
也就是说:
- 每一段的结尾,可能是“半个字节”
- 如果你在“非对齐位置”硬拼,整个 bit 流就乱了,中间随便拼字符串 = 直接破坏 bit 流
但 DNS exfil 的常见做法是:
每个 label:
单独 Base32
单独对齐
不能简单字符串拼接
正确的流程是
- 按序号排序
- 只拼 Base32 字符串(去掉 ffff)
- 只在“整体末尾”补 padding
- 一次性 Base32 decode
所以这题无法避免的是得手搓代码
脚本如下
import base64
raw = """
0001.wgczzoor4hic6nzn2a44nloyy4qk4jb4utekjorf37cc4ob4wd.a1b2c3d4.exfil.unictf.local
0000.kbfqgbauaaaaacaajbsskxfwamzbcoaaaaadmaaaaaeaaaaamz.a1b2c3d4.exfil.unictf.local
ffff.1818be0b.a1b2c3d4.exfil.unictf.local
0002.klrsjqwy4n6pgcxiz5zvjthsrcpxgbgdddqpgzhc4mrofgxaka.a1b2c3d4.exfil.unictf.local
0005.aqaaiagyaaaac6aaaaaaaa.a1b2c3d4.exfil.unictf.local
0004.aaaaaaaaaaaaaaeaaeaaaaaamzwgczzoor4hiuclaudaaaaaaa.a1b2c3d4.exfil.unictf.local
0003.cqjmaqefadcqaaaaaiabegkjk4wybteejyaaaaanqaaaaaqaaa.a1b2c3d4.exfil.unictf.local
"""
chunks = {}
for line in raw.strip().splitlines():
parts = line.split(".")
idx = int(parts[0], 16)
if idx == 0xffff:
continue
chunks[idx] = parts[1]
# 拼接 Base32 字符串(不是 bytes)
payload = "".join(chunks[i] for i in sorted(chunks)).upper()
# 只在整体补 padding
pad = "=" * ((8 - len(payload) % 8) % 8)
payload += pad
decoded = base64.b32decode(payload)
open("out.zip", "wb").write(decoded)
print("OK, ZIP written")
2.1.2 工厂应急流量分析
附件已经上传至gitee.com/ASUS-HACKED
题目链接:工厂应急流量分析 | CTF+
任务 1:谁把阀门打开了?
找到 Modbus 打开阀门指令的相关信息。
提交格式:flag{0xtransaction_id_0xfunction_code_0xcoil_address}
flag:
一、Modbus协议
什么是Modbus
Modbus 是一种工业控制协议,常用于:
- PLC(可编程逻辑控制器)
- 阀门、传感器、电机
- 工业自动化系统
一句话理解:
Modbus = 用来控制设备“开 / 关 / 读状态”的工业协议
1.Modbus 常见通信方式
在 CTF / 流量分析中,最常见的是:
| 类型 | 说明 |
|---|---|
| Modbus TCP | 跑在 TCP 上(端口 502)⭐ |
| Modbus RTU | 串口通信(抓包里很少) |
2.Modbus TCP 的“特征”(非常重要)
1.固定端口:502
Wireshark 里直接过滤:
tcp.port == 502
2.协议结构(重点)
Modbus TCP 报文 = 两部分
[ MBAP Header ][ PDU ]
3.MBAP Header(7 字节)
| 字段 | 长度 | 含义 |
|---|---|---|
| Transaction ID | 2 字节 | 请求编号(你 flag 里要的) |
| Protocol ID | 2 字节 | 固定为 0x0000 |
| Length | 2 字节 | 后续长度 |
| Unit ID | 1 字节 | 从站 ID |
4.PDU(真正的指令)
| 字段 | 含义 |
|---|---|
| Function Code | 功能码(你 flag 的第二部分) |
| Data | 地址 / 值 |
3.Modbus 常见 Function Code(必须认识)
| 功能码 | 十六进制 | 作用 |
|---|---|---|
| Read Coils | 0x01 |
读开关状态 |
| Read Holding Registers | 0x03 |
读数据 |
| Write Single Coil | 0x05 |
写一个开关(开/关)⭐ |
| Write Multiple Coils | 0x0F |
写多个开关 |
“打开阀门” ≈ 写线圈(Write Coil)
什么是 Coil?为什么和阀门有关?
- Coil = 线圈 = 开关
- 工业里:
- 阀门
- 继电器
- 开关量
👉 阀门开/关 = Coil 0 / 1
4.Write Single Coil 的数据格式
Function Code: 0x05
Coil Address: 2 bytes
Value:
0xFF00 → ON(打开)
0x0000 → OFF(关闭)
二、解题思路
根据题目要求找到三个编码:transaction_id、function_code、coil_address
筛选出符合的协议

分析第一条中观察到
Transaction Identifier(transaction_id):15437
function_code: Write Single Coil(5)
coil_address(Data):ff00
注意这里都需要转成hex(Modbus协议规范里,所有寄存器地址、功能码、CRC校验都是以字节为单位写的,用hex最直观)

flag{0x3c4d_0x05_0x0015}
任务 2:被读取的 NodeId
找到通过 OPC UA 协议读取的
NodeId。
提交格式:flag
一、OPC UA 协议
1.什么是 OPC UA 协议
OPC UA(Open Platform Communications Unified Architecture)是一种工业自动化通信协议,用于工业设备(PLC、传感器、HMI)与上位系统(SCADA、MES、客户端软件)之间的数据交换。它是 OPC 经典协议的升级版本,具有以下特点:
- 平台无关:可以在 Windows、Linux、嵌入式系统上运行。
- 安全性高:支持加密(TLS)、签名和认证。
- 结构化数据:数据以节点(Node)形式组织,每个节点有唯一标识 NodeId。
- 可扩展:支持对象、变量、方法等复杂数据类型。
在 CTF 或流量分析中,OPC UA 常用来模拟工业控制系统的数据交换,比如读取设备状态、传感器数据等。
2. OPC UA 协议的流量特征
在抓包工具(如 Wireshark)中,OPC UA 流量通常有这些特征:
- TCP/UDP 协议
- 默认使用 TCP 端口 4840(有些实现也可能使用其他端口)。
- 消息类型
OPC UA 协议消息通常有三类:- Hello / Acknowledge / OpenSecureChannel:建立连接,协商加密。
- Read / Write / Browse / Call:读写数据、浏览节点、调用方法。
- CloseSecureChannel / Error:关闭连接或返回错误。
- 消息结构
- OPC UA 消息是二进制编码(有些实现也支持二进制 + XML)。
- 主要字段:
- NodeId:每个节点的唯一标识(客户端要读取的数据目标)。
- AttributeId:节点的属性(如 Value、DisplayName)。
- DataType:节点存储的数据类型。
- Value:实际读到的数据。
- 典型特征:
- 固定头部(MessageType, MessageSize, SequenceNumber)
- 可见的操作名:ReadRequest、ReadResponse、BrowseRequest、BrowseResponse。
3.要注意的信息
当抓取 OPC UA 流量时,为找到 NodeId,可以按如下步骤分析:
- 抓取流量
- 使用 Wireshark 或 tcpdump,抓取目标设备的 TCP 4840 端口流量。
- 在 Wireshark 中选择 “Decode As → OPC UA” 或直接使用内置 OPC UA 解码器。
- 找到 ReadRequest 消息
- ReadRequest 中包含字段
NodeToRead,这就是客户端请求的 NodeId。 - NodeId 包含两部分:
ns=X:命名空间编号s=Path/To/Node或i=数字:节点路径或数字标识
- ReadRequest 中包含字段
- 对应的 ReadResponse 消息
- 可以验证请求是否正确,返回的 Value 对应 NodeId 的数据值。
- 其他技巧
- 如果流量加密(TLS),需要在 CTF 提供的环境下解密。
- BrowseRequest/Response 可以帮助发现节点结构。
二、解题思路
wireshark中筛选
tcp.port == 4840
对第一个流量包进行分析,找到符合的信息
ReadRequest
flag{ns=2;s=Valve/Status}

任务 3:控制站域名解析结果
找出控制站域名 ctrlws.factory.local 的解析 IP。
提交格式:flag
一、IP 协议
1.IP 是干嘛的?
IP(Internet Protocol) 是网络通信中最基础的一层协议之一,它的作用只有一句话:
负责把数据包从“源 IP”送到“目标 IP”
你可以把它理解成「快递地址」。
- IP 地址 = 主机在网络中的唯一地址
- 不关心数据内容是什么
- 只关心:
👉 从哪来(Source IP)
👉 到哪去(Destination IP)
2.IP 协议的典型特征
在 Wireshark 中,IP 协议通常有这些关键信息:
- Source Address(源 IP)
- Destination Address(目的 IP)
- Protocol(上层协议)
- TCP
- UDP
- ICMP
- TTL(生存时间)
⚠️ 重点:
IP 层 不会出现域名,只会出现 IP 地址。
👉 域名 → IP 的转换是由 DNS 完成的
3.流量分析中 IP 需要注意什么?🔍
在做流量分析时,IP 层主要用于:
- 判断通信双方是谁
- 找出异常通信(比如内网 → 可疑 IP)
- 配合 DNS,确认某个域名最终解析到了哪个 IP
在这道题中:
目标不是直接找 IP 包,而是:
- 先找到
ctrlws.factory.local- 再找到它解析成了哪个 IP
4.域名是怎么变成 IP 的?(DNS 简述)
DNS 的作用一句话版本:
DNS = 把域名翻译成 IP 的电话簿
ctrlws.factory.local → 192.168.1.100
在流量里会发生什么?
- 客户端发送 DNS Query(查询)
- DNS 服务器返回 DNS Response(响应)
- 响应里包含:
- 域名
- 对应的 IP(A 记录)
💡 所以:
想找域名对应的 IP,一定要看 DNS 响应包
二、解题思路
在wireshark过滤器搜索
dns && dns.qry.name contains "ctrlws.factory.local"
flag{192.168.1.10}

任务 4:连接建立时间
确定SCADA(源:192.168.1.5)到控制站(目的:192.168.1.10)上首个成功发起的时间点(UTC)。
提交格式:flag
一、TCP协议
1.TCP 是干什么的?
TCP(Transmission Control Protocol,传输控制协议) 是 Internet 核心协议之一,作用是:
在网络上可靠地把数据从一台主机发送到另一台主机
特点:
- 面向连接(Connection-Oriented)
- 先建立连接,才能发送数据
- 保证数据完整、按顺序到达
- 使用三次握手(Three-Way Handshake)建立连接
- 连接成功 → 才算通信成功发起
2.TCP 特征
在 Wireshark 中,TCP 典型特征:
| 特征 | 说明 |
|---|---|
| Flags | 包的控制位,如 SYN、ACK、FIN 等 |
| Source Port / Destination Port | 上层应用端口(SCADA可能是502) |
| Sequence Number / ACK Number | 数据序号,保证数据按顺序 |
| 三次握手标志 | SYN → SYN+ACK → ACK(成功建立连接) |
核心概念:首个成功发起通信 = 第一个 TCP 三次握手完成的时间点
3.流量分析中需要注意的信息
在 TCP 流量分析中,小白需要注意:
- IP 地址
- 确认流量是 SCADA → 控制站
- 过滤源 IP 和目标 IP
- 端口号
- SCADA 系统常用端口:502(Modbus TCP)、20000(DNP3 TCP)等
- 结合端口过滤更精准
- TCP Flags
SYN:发起连接SYN, ACK:回应ACK:确认- 完整三次握手 = 连接成功
- 时间戳
- 题目要求 UTC 时间
- Wireshark 默认可能是相对时间,需要切换到 UTC
二、解题思路
wireshark中搜索
tcp && ip.src==192.168.1.5 && ip.dst==192.168.1.10(IP搜索)
tcp.flags.syn==1 && tcp.flags.ack==0 && ip.src==192.168.1.5 && ip.dst==192.168.1.10
(TCP三次握手)

flag{2025-03-15T09:00:01Z}
任务 5:HTTP 请求痕迹
提取 SCADA (192.168.1.5)对控制站(192.168.1.10)发起的 HTTP 请求的 Host 与 URI。
一、HTTP协议
1.什么是http协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是应用层协议,作用是
客户端向服务器发送请求,服务器返回响应
在 SCADA 系统中,有些 Web 界面或 API 通常也会通过 HTTP 传输指令或数据。
2. HTTP 的特征
- 明文协议(HTTP)
- 数据可以直接被抓包看到
- 典型请求结构:
GET /path/to/resource HTTP/1.1
Host: server.example.local
User-Agent: SCADAClient/1.0
...
- Host → 服务器域名或 IP
- URI → 请求路径(资源位置)
- 请求方法 → GET、POST、PUT、DELETE 等
✅ 核心信息就是 Host + URI
3.流量分析中 HTTP 需要注意的信息
- 源/目的 IP
- 确认是 SCADA → 控制站流量
- 端口号
- HTTP 默认端口 80(明文),HTTPS 443(加密)
- SCADA 系统的 Web/HTTP 服务可能使用非标准端口
- 请求类型
- HTTP 请求才有 Host 和 URI
- 可能加密
- 如果是 HTTPS,需要抓取 TLS 握手前的 SNI(Server Name Indication)才能看域名,但 URI 无法直接看到
⚠️ 题目通常用 HTTP 明文,否则无法提取 URI
二、解题思路
1.在wireshark过滤栏目中搜索
http && ip.src==192.168.1.5 && ip.dst==192.168.1.10
2.找到 HTTP 请求包
-
选中某一个 HTTP 包
-
展开 Wireshark 的 Hypertext Transfer Protocol 栏
-
找到:
GET /api/status HTTP/1.1 Host: ctrlws.factory.localHost→ 服务器域名或 IPURI→ 请求路径(GET/POST 的/api/status)

flag{ctrlws.factory.local_/api/status}
任务 6:ICMP Echo Request 序列号
攻击者(192.168.1.100)对控制站发起了 ICMP Echo Request(ping)。找出该 ICMP 请求的序列号(Sequence Number)。
提交格式:flag
一、 ICMP协议
1.什么是ICMP协议
ICMP(Internet Control Message Protocol) 是网络层协议,用来:
传递网络状态和错误信息
它不是用来传输数据的,而是用来“探测”和“反馈”。
2.什么是 Echo Request(ping)?
我们平时用的 ping 命令,本质就是:
- ICMP Echo Request(请求)
- ICMP Echo Reply(回应)
流程非常简单:
攻击者 → Echo Request → 控制站
攻击者 ← Echo Reply ← 控制站
3. ICMP Echo Request 的典型特征
在 Wireshark 中,ICMP Echo Request 有这些明显特征:
| 字段 | 含义 |
|---|---|
| Type | 8(表示 Echo Request) |
| Code | 0 |
| Identifier | 用来区分 ping 会话 |
| Sequence Number | 每发一次 ping 就递增 |
| Source IP | 发起 ping 的主机 |
| Destination IP | 被 ping 的主机 |
本题只关心:Sequence Number
4.流量分析中 ICMP 要注意什么信息 🔍
小白分析 ICMP 时,只需要盯住这几件事:
- IP 地址
- 确认是攻击者 → 控制站
- ICMP 类型
- Echo Request = Type 8
- Echo Reply = Type 0(⚠️不要看错)
- Sequence Number
- 在 ICMP 报文内部
- 十六进制 / 十进制
- Wireshark 通常显示十进制
- 题目要求十六进制
二、解题思路
1.在wireshark过滤栏输入
icmp && ip.src==192.168.1.100 && ip.dst==192.168.1.10
2.在Internet Control Message Protocol下看到
Type: 8 (Echo (ping) request)
Code: 0

注意:如果是
Type: 0 (Echo reply)
那就不是我们要的包。
3.找到 Sequence Number
观察发现
Identifier(BE):22136(0x5678)
Identifier(LE):30806(0x7856)
Sequence Number(BE):291(0x0123)
Sequence Number(LE):8961(0x2301)
什么选 BE,而不是 LE?
1️⃣ 网络协议的铁律:Network Byte Order
👉 所有网络协议(包括 ICMP)在“协议语义层”统一使用:
大端序(Big Endian,BE)
这条规则非常重要,你可以记成一句话:
协议字段一律信 BE,LE 只是 Wireshark 为你“换个角度看内存”
ICMP 标准里怎么定义的?
ICMP Echo Request 的字段定义是:
0 8 16 31
+---------------+---------------+---------------+
| Type (8) | Code (8) | Checksum |
+---------------+---------------+---------------+
| Identifier (16 bits) |
+---------------+---------------+---------------+
| Sequence Number (16 bits) |
+---------------+---------------+---------------+
Identifier:16 位整数(网络字节序)
Sequence Number:16 位整数(网络字节序)
网络字节序 = Big Endian
Wireshark 为什么会显示 BE / LE 两个?
这是 Wireshark 在帮你做字节序转换,而不是协议本身有两种值。
假设数据包里真实的两个字节是:
01 23
| 解释方式 | 结果 |
|---|---|
| Big Endian | 0x0123 = 291 |
| Little Endian | 0x2301 = 8961 |
真实协议含义是 BE
👉 LE 只是 “如果你把这两个字节当成小端解释,会得到什么”
flag{0x0123}
任务 7:SNMP Get 请求的 OID
SCADA 对控制站发起了 SNMP Get 请求。找出该请求查询的 OID(Object Identifier)。
提交格式:flag
一、 SNMP Get
1.什么是 SNMP Get
SNMP(Simple Network Management Protocol) 是一种:
用于“查询/管理设备状态”的应用层协议
在工业控制(SCADA)环境中,常用于:
- 查询设备运行状态
- 读取寄存器 / 传感器数据
- 监控控制站、PLC、交换机等
2.什么是 SNMP Get 请求?
SNMP 常见操作有:
| 操作 | 含义 |
|---|---|
| GetRequest | 读取某个变量(最常见) |
| GetNextRequest | 读取下一个 OID |
| SetRequest | 修改设备参数 |
| Response | 设备返回数据 |
GetRequest = “我要读取这个 OID 的值”
3.OID 是什么?
OID(Object Identifier) 是:
SNMP 中每一个“可查询对象”的唯一编号
它是一个“树状路径”,例如:
1.3.6.1.2.1.1.1.0
含义不用记,记住一件事就够:
SNMP Get 请求里,一定会明确写出 OID
4.SNMP Get 请求的典型特征 🔍
在流量里,SNMP Get 有这些明显特征:
| 特征 | 说明 |
|---|---|
| 协议 | SNMP |
| 传输层 | UDP |
| 默认端口 | 161 |
| PDU Type | GetRequest |
| Variable Bindings | 里面有 OID |
在 Wireshark 中通常会看到:
SNMP
└─ PDU: GetRequest
└─ Variable bindings
└─ 1.3.6.1.x.x.x.x
5.流量分析时需要注意什么(小白重点)⚠️
分析 SNMP Get 时,记住这 5 点就够:
- 方向
- SCADA → 控制站
- 端口
- UDP 161(几乎必考)
- PDU 类型
- 一定是
GetRequest
- 一定是
- Variable Bindings
- OID 就在这里
- 不是 Response
- Response 里也有 OID,但题目问的是 请求
二、解题思路
1.在wireshark中搜索
udp.port == 161 && ip.src == 192.168.1.5
打开一个UDP包

因为 SNMP 是应用层协议,OID 本身就是“应用数据”
所以在 Wireshark 里,它属于 Data(Payload),而不是像 IP/TCP 那样的固定头字段
协议分层视角(这是根本原因)
以太网
└─ IP
└─ UDP
└─ SNMP
└─ GetRequest-PDU
└─ Variable Bindings
└─ OID ← 在这里
关键点:
- IP / UDP:有固定头结构
- SNMP:应用层协议
- OID:不是“头部字段”,而是“应用层数据内容”
👉 所以 OID 天然就属于 Data(Payload)
SNMP 协议本身是“数据驱动”的 SNMP 的设计理念
SNMP 并不是:
“我有一个叫 OID 的固定字段”
而是:
“我携带一组变量(Variable Bindings),每个变量用 OID 来标识它是谁”
也就是说:
SNMP 报文 = 管理请求 + 一堆变量
而 OID 本身:
- 是 变量的名字
- 是 业务语义
- 不属于协议头
👉 业务数据 = Data
flag{1.3.6.1.2.1.1.5.0}
2.2 Crypto
2.2.1.NTRU
A faint whisper in the polynomial ring, where sparse noise veils the message.
附件已经上传至gitee.com/ASUS-HACKED
源代码
"""
NTRU Challenge - Public Parameters
"""
N = 31
p = 257
q = 12289
h = [9603, 11838, 1242, 5868, 12249, 3130, 3722, 5910, 5879, 7672, 1119, 339, 10748, 7310, 6370, 9353, 10589, 10739, 10213, 2560, 5132, 4889, 11292, 2649, 2556, 8037, 3146, 9533, 11563, 1554, 304]
c = [91, 11459, 932, 4345, 12153, 9504, 5147, 7268, 2493, 8891, 8712, 5785, 11608, 7683, 11327, 8453, 10380, 6004, 7849, 1622, 6154, 10369, 10278, 769, 11676, 11492, 4564, 5445, 10909, 11502, 12216]
if __name__ == "__main__":
print("NTRU Challenge Parameters:")
print(f"N = {N}")
print(f"p = {p}")
print(f"q = {q}")
print(f"r_weight = 4")
print("h (first 5):", h[:5], "...")
print("c (first 5):", c[:5], "...")
print()
print("Encryption: c = r * h + m (mod q, x^N-1)")
print(f"where r has only 4 non-zero coefficients (±1)")
print("Goal: recover the message m containing the flag")
已知参数
你给出的参数如下:
N = 31 # 多项式的模 x^N - 1
p = 257 # 明文系数模数
q = 12289 # 密文系数模数
h = [...] # 公钥,多项式系数
c = [...] # 密文,多项式系数
r_weight = 4 # r 多项式只有 4 个 ±1 非零项
加密公式是:
c(x)=r(x)∗h(x)+m(x)(modq,xN−1)c(x) = r(x) * h(x) + m(x) \pmod{q, x^N-1}c(x)=r(x)∗h(x)+m(x)(modq,xN−1)
其中:
- r(x)r(x)r(x) 是随机多项式,只包含 4 个 ±1,其他系数都是 0
- m(x)m(x)m(x) 是明文多项式,系数在 [0,p−1][0, p-1][0,p−1]
- h(x)h(x)h(x) 是公钥
- c(x)c(x)c(x) 是密文
我们的目标是 恢复明文 m(x)m(x)m(x)。
问题分析
这是一个经典的 小重数 NTRU 解密问题,通常有几个特点:
- r 非常稀疏:只有 4 个 ±1
- 所以
r * h是一个“稀疏多项式卷积”,在 q 模下 - 如果你尝试暴力枚举所有 r 的组合(±1,位置选择),复杂度是 (314)⋅24=31460\binom{31}{4} \cdot 2^4 = 31460(431)⋅24=31460 种。
- 这个数量很小,可以直接 暴力穷举。
- 所以
- 小 N:N = 31
- 可以直接用 循环卷积来计算
r * h - 然后对
c - r*h mod q,得到 m 的可能值
- 可以直接用 循环卷积来计算
- p 与 q 的关系:p = 257, q = 12289
- 通常,NTRU 的明文系数较小(0~p-1),而 q 大很多
- 所以计算
(c - r*h) % q后,如果系数 < q/2,直接 mod p 可以得到明文
解题策略
因为 r 很稀疏,可以暴力穷举:
- 枚举 r 的 4 个非零位置
- 枚举 ±1 的组合
- 对每个 r,计算:
mcandidate=(c−r∗h) mod qm_{\text{candidate}} = (c - r * h) \bmod qmcandidate=(c−r∗h)modq
- 判断 m 是否有效(所有系数 < p)
因为 p = 257,q = 12289,明文系数一般会落在 0~256,如果 (c - r*h) % q 的每个系数都 < 257,说明找到正确 r,得到明文。
暴力算法复杂度
- 选择 4 个非零位置:(314)=31465\binom{31}{4} = 31465(431)=31465
- 每个位置 ±1:24=162^4 = 1624=16
- 总共枚举:31465∗16≈503,44031465 * 16 ≈ 503,44031465∗16≈503,440 种
- 现代计算机秒杀,几秒钟就可以完成
所以这是一个 经典的稀疏 NTRU 破解题。
解密脚本
import itertools
N = 31
p = 257
q = 12289
h = [9603, 11838, 1242, 5868, 12249, 3130, 3722, 5910, 5879, 7672,
1119, 339, 10748, 7310, 6370, 9353, 10589, 10739, 10213, 2560,
5132, 4889, 11292, 2649, 2556, 8037, 3146, 9533, 11563, 1554, 304]
c = [91, 11459, 932, 4345, 12153, 9504, 5147, 7268, 2493, 8891,
8712, 5785, 11608, 7683, 11327, 8453, 10380, 6004, 7849, 1622,
6154, 10369, 10278, 769, 11676, 11492, 4564, 5445, 10909, 11502, 12216]
r_weight = 4
def poly_mul(a, b):
res = [0] * N
for i in range(N):
for j in range(N):
res[(i + j) % N] += a[i] * b[j]
return [x % q for x in res]
def center_lift(x):
return x - q if x > q // 2 else x
print("[*] Brute forcing r...")
cnt = 0
for positions in itertools.combinations(range(N), r_weight):
for signs in itertools.product([-1, 1], repeat=r_weight):
cnt += 1
r = [0] * N
for pos, s in zip(positions, signs):
r[pos] = s
rh = poly_mul(r, h)
m = [(c[i] - rh[i]) % q for i in range(N)]
m_centered = [center_lift(x) for x in m]
if all(-p//2 <= x <= p//2 for x in m_centered):
print("[+] Found valid r!")
print("r =", r)
print("m_centered =", m_centered)
# 转 ASCII
flag = ''.join(chr(x % 256) for x in m_centered if x != 0)
print("[+] FLAG:", flag)
exit()
print("[-] No solution found")
2.2.2 Subgroup-Weaver
Within the Sanctum of Impermanence, the Subgroup-Weaver maintains the Great Veil—a tapestry woven from the duality of the Spark and the Void. Every secret is fused into this ephemeral shroud, crafted to mirror the secret's essence with absolute precision in both length and form. To the uninitiated, the Veil appears as a sea of perfect, unreadable chaos, where every pulse of energy is destined to vanish the moment its purpose is fulfilled, ensuring a silence that seems unbreakable. Yet, the guardian's masterpiece is not as absolute as the void itself; even within the heart of the flickering storm, a faint, primordial resonance lingers. To pass, one must look beyond the mask of disorder and discern the truth hidden within the eternal, shifting dance of the two primal forces.
附件已上传至gitee.com/ASUS-HACKED
附件代码
from random import randint, randbytes
from Crypto.Util.number import bytes_to_long
from secret import flag
key = randbytes(64)
def gen(bits):
return sum(randint(1, 7) % 2 * 2**i for i in range(bits))
def otp():
return bytes_to_long(key) ^ gen(len(key) * 8)
while input('> ') != key.hex():
print(otp())
print(f'your prize: {flag}')
题目回顾(给小白看的)
题目代码核心如下:
key = randbytes(64)
def gen(bits):
return sum(randint(1, 7) % 2 * 2**i for i in range(bits))
def otp():
return bytes_to_long(key) ^ gen(len(key) * 8)
程序会不断输出 otp(),
只有当你输入 正确的 key.hex() 时,才会给你 flag。
一、这题在考什么?(一句话版)
👉 伪随机数有偏差 + OTP 重复使用 = 可以用统计方法恢复密钥
二、先解释基础概念(零基础必写)
什么是 OTP(一次性密码)
OTP(One-Time Pad)加密规则:
密文 = 明文 XOR 密钥
但前提是:
- 密钥必须完全随机
- 每次只能用 一次
这题哪里违反了 OTP 原则?
问题 1:密钥被重复使用
key = randbytes(64) # 固定不变
问题 2:随机数不是均匀的
randint(1, 7) % 2
| 值 | 结果 |
|---|---|
| 1,3,5,7 | 1 |
| 2,4,6 | 0 |
➡ 1 的概率是 4/7
➡ 0 的概率是 3/7
⚠️ 这不是 50% : 50% 的随机数
三、关键漏洞(重点)
otp() 实际是:
otp_bit = key_bit XOR gen_bit
因为 gen_bit = 1 的概率更高:
otp_bit更有可能是 key_bit 的反值
📌 这就是突破口
四、攻击思路(小白也能懂)
核心思想:多取几次,投票决定
-
程序可以无限输出
otp() -
对每一位 bit:
- 统计 0 / 1 出现次数
- 出现次数多的 = 常态
-
因为 otp 更偏向
~key:key_bit = 常态值 XOR 1
这就是统计攻击
五、攻击流程(写清步骤)
1️⃣ 连接远程服务
2️⃣ 连续请求 800 次 otp
3️⃣ 对 512 个 bit 分别统计
4️⃣ 恢复 key
5️⃣ 提交 key.hex() 得到 flag
最终 Exploit(完整正确代码)
from pwn import *
HOST = 'nc1.ctfplus.cn'
PORT = 32181
KEY_BYTES = 64
BITS = KEY_BYTES * 8
SAMPLES = 800 # ⭐ 提高采样次数,基本必过
io = remote(HOST, PORT)
bit_count = [0] * BITS
log.info("Collecting OTP samples...")
for _ in range(SAMPLES):
io.sendline(b'') # 随便输入,保证 != key.hex()
line = io.recvline().decode().strip()
# 服务端格式:"> 123456789..."
otp = int(line.split()[-1])
for i in range(BITS):
bit_count[i] += (otp >> i) & 1
log.info("Recovering key...")
key = 0
for i in range(BITS):
# otp 更偏向 NOT key
majority = 1 if bit_count[i] > SAMPLES // 2 else 0
key_bit = majority ^ 1
key |= key_bit << i
key_hex = key.to_bytes(KEY_BYTES, 'big').hex()
log.success(f"Recovered key: {key_hex}")
# 提交 key
io.sendline(key_hex.encode())
# 接收 flag
print(io.recvline().decode())
io.close()
3.NSSCTF
3.1 MISC-流量分析(SQL注入-布尔盲注)
3.1.1 [闽盾杯 2021]日志分析

打开附件发现大量的%url编码,先转化一下观察

0x00 前言
在 CTF 比赛中,流量分析是常见题型。当我们拿到一份 Web 服务器日志(如 access.log)时,如果发现大量相似且带有 SQL 关键字的请求,通常意味着网站遭受了 SQL 注入攻击。本文将手把手教你如何从这些杂乱的日志中“还原”出被黑客窃取的 Flag。
0x01 第一步:环境感知(找寻判别准则)
黑客进行的是布尔盲注。这种攻击就像是在玩“海龟汤”,黑客问一个是非题,服务器只能通过页面反馈来回答“对”或“错”。
首先,我们要找到服务器回答“对”和“错”时的不同表现。观察 access.log 开头:
- 正常请求:
id=1返回长度为 675。 - 真值探测:
id=1' AND 7113=7113(恒等式,必为真)返回长度为 675。 - 假值探测:
id=1' AND 2512=1676(必为假)返回长度为 678。
关键结论:
- HTTP 200 675 代表 SQL 条件为 真 (True)
- HTTP 200 678 代表 SQL 条件为 假 (False)
0x02 第二步:逻辑拆解(黑客是怎么猜的?)
黑客使用 sqlmap 工具,利用 ORD(MID()) 函数配合二分查找法来获取数据。
以提取密码(password)第 1 个字符为例:
...MID(...,1,1))>110$\rightarrow$ 返回 678 (假):说明该字符 ASCII 值 $\le$ 110。...MID(...,1,1))>109$\rightarrow$ 返回 675 (真):说明该字符 ASCII 值 $>$ 109。- 推导:大于 109 且小于等于 110 的整数只有一个,那就是 110。
- 转化:查 ASCII 码表,110 对应字母
n。
0x03 第三步:自动化脚本(从日志到 Flag)
由于日志有上千行,手动提取不现实。我们需要写一个脚本完成三件事:URL解码->正则匹配 -> 逻辑还原。
Python 脚本参考:
import urllib.parse
import re
def extract_flag_from_log(file_path):
# 存储结果:{字符位置: 最大的 True 判定 ASCII 值}
# 逻辑:如果 MID(...) > X 为真 (675),则该位字符 ASCII >= X+1
results = {}
# 正则表达式:匹配解码后的 password 盲注语句
# 捕获组:1=位置, 2=比较的ASCII值, 3=响应长度
pattern = re.compile(r"password.*?,(\d+),1\)\)>(\d+).*? 200 (\d+)")
try:
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
# 1. 先进行全局 URL 解码
decoded_line = urllib.parse.unquote(line)
# 2. 匹配关键信息
match = pattern.search(decoded_line)
if match:
pos = int(match.group(1)) # MID 截取的字符位置
threshold = int(match.group(2)) # 比较的数值 X
resp_len = int(match.group(3)) # 长度 (675/678)
# 3. 核心判定逻辑:675 为真 (True)
if resp_len == 675:
# 记录该位置出现的最大的“真”阈值
if pos not in results or threshold > results[pos]:
results[pos] = threshold
# 4. 排序并还原字符
if not results:
print("未发现匹配的布尔盲注数据,请检查日志格式。")
return
sorted_positions = sorted(results.keys())
final_flag = ""
print(f"{'位置':<6} | {'最大 True 阈值':<15} | {'判定字符'}")
print("-" * 40)
for p in sorted_positions:
char_ascii = results[p] + 1
char = chr(char_ascii)
final_flag += char
print(f"{p:<8} | {results[p]:<15} | {char}")
print("-" * 40)
print(f"最终识别出的 Flag: {final_flag}")
except FileNotFoundError:
print(f"错误:找不到文件 {file_path}")
if __name__ == "__main__":
# 指定你的文件名
extract_flag_from_log('access.log')//得换你的log名称哈,别直接跑了
0x04 总结
- 解码是前提:Web 日志会对特殊字符编码,不解码就看不出 SQL 语句。
- 长度是灵魂:布尔盲注的本质就是观察响应长度的微小差异。
- 最后一位 + 1:由于黑客用的是
> X判定,所以我们找到的最后一个“真”的值X,其实目标字符就是X + 1。
为什么是布尔盲注?
- 看“长相”:重复且规律的请求
当你打开 access.log,发现黑客不是在翻阅不同的页面,而是在疯狂刷新同一个地址,且参数极其相似时,就要怀疑是盲注了。
- 普通用户:访问
/index.php,然后访问/news.php。 - 黑客(盲注):连续发送几百个
/api/forum.php/?id=1...,只有最后面的那一小段代码在变。
- 看“核心”:标志性的 SQL 函数
在日志中,如果我们看到了以下三个函数组合出现,那几乎可以“秒定”是布尔盲注:
MID()或SUBSTR():这是“切片刀”,负责把密码切成一个一个的字母。ORD()或ASCII():这是“转换器”,负责把字母变成数字(比如把 'a' 变成 97)。> 某个数字:这是“问句”,负责问服务器:“这个字母的 ASCII 码是不是大于 100?”
- 看“反馈”:响应长度的二元变化
这是最关键的一点!“布尔”的意思就是“非黑即白”。
在日志的末尾,你会发现无论黑客怎么变换参数,服务器返回的状态码永远是 200(代表请求成功),但是返回的页面长度(Length)却只有两种结果:
- 结果 A:675
- 结果 B:678
这就好比你在问服务器问题,它不说话,但如果你问对了,它点一下头(返回 675);如果你问错了,它摇一下头(返回 678)。
3.1.2 [鹤城杯 2021]流量分析
示例代码
tshark -r timu.pcapng -e http.request.uri -T fields -Y 'http.request.uri' > 1.txt
脚本
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main()
{
FILE* file = fopen("1.txt","r");
if(file == NULL)
{
printf("无法打开1.txt文件,检查是否 存在");
return 1;
}
char line[1024];
int flag;
while(fgets(line,sizeof(line),file)){
char* pos = strstr(line,"))=");
if(pos!=NULL)
{
int num = atoi(pos + 3);
if(num>flag) flag = num;
else{
printf("%c",flag);
flag = -1;
}
}
}
fclose(file);
return 0;
}
4.蓝桥杯模拟-春秋GAME
4.1 Find the flag
题目信息:
Find the flag
赛题地址:https://static2.ichunqiu.com/icq/resources/fileupload/CTF/BSRC/2017/BSRC3-1/findtheflag.cap
备用地址:网络安全: 科协ss0t网络安全学习资料分享仓库 - Gitee.com
首先我们打开流量分析就发现了这个问题,流量包太大了,Wireshark无法解析出来,我们需要使用修复工具对这个包进行重构

这个网站是修复pcap文件的,我们使用它修复一下
pcapfix - online pcap / pcapng repair service


OK,那我们就使用常规思路分析流量包吧
常规思路在 CTF 流量分析(Traffic Analysis)中,面对动辄几万条的报文,盲目翻阅是大忌。高效的解题思路通常遵循“由宏观到微观,从异常找线索”的原则。
以下是一套标准的解题流程:
- 统计分析(宏观建模)
在动手抓包前,先看统计数据。这能帮你快速判断题目背景(是 Web 攻击、内网渗透、还是某种协议传输)。
- 协议分级(Protocol Hierarchy): 观察哪种协议占比最高。
- HTTP/HTTPS 占大头:通常是 Web 渗透或 Webshell 管理。
- TCP/UDP 占比异常:可能存在端口扫描、DDoS 或自定义私有协议。
- ICMP/DNS 异常:可能存在隐蔽隧道(ICMP/DNS Tunneling)。
- 端点统计(Endpoints): 查看哪个 IP 发包最频繁。通常发包量巨大的 IP 就是攻击者(黑客)或受害者(服务器)。
- 会话统计(Conversations): 寻找异常的长连接或特定端口(如 4444, 8888, 7777 等)的交互。
- 过滤器筛选(精准打击)
根据初步判断,使用 Wireshark 过滤器缩小范围:
- 找 Web 攻击: 搜索常见的攻击关键字。
http contains "select"或http contains "union"(SQL 注入)。http contains "etc/passwd"(任意文件读取)。http.request.method == "POST"(查看上传的文件或 Webshell 的交互)。- 找敏感行为: *
tcp.flags.reset == 1(可能有端口扫描)。
http.response.code == 200(确认攻击是否成功,404 或 403 通常表示失败)。
- 追踪流与还原(深入挖掘)
找到一个可疑点后,通过 "Follow TCP/HTTP Stream" 还原完整的攻击过程。
- Webshell 流量: 重点看执行了什么命令。如果是 base64 加密,直接丢进 CyberChef 解码。
- 文件传输: 如果发现流量中有
PK(Zip)、JFIF(JPG)、PNG等文件头。
- 使用 "Export Objects -> HTTP" 直接提取。
- 或者手动提取 Hex 原始数据并还原。
- 数据导出: 有时 Flag 隐藏在大量重复的数据包中(如 ICMP 数据位、TCP 的 ID 字段、TTL 字段),这时需要写 Python 脚本配合
scapy库进行批量提取。
- 常见“坑点”与 Flag 位置
如果常规协议里找不到,检查以下“隐蔽空间”:
- 非预期协议: 比如 Flag 被藏在
ICMP的 Data 字段中,每包一个字节,拼起来就是 Flag。- USB 流量: 键盘(Keyboard)或鼠标(Mouse)流量。需要提取坐标或按键码,通过脚本绘图或映射成文字。
- TLS 解密: 题目可能会提供一个
.key文件或 SSL KEYLOG 文件,需要配置 Wireshark 进行解密才能看到内容。- 隐写术: 导出的图片、压缩包本身可能还有层隐写(Outguess, Steghide, 暴力破解等)。

协议分级观察
1.寻找“大流量”:谁占领了带宽?
在统计图中,“百分比”和“字节”是最直观的指标。
- 观察重点: 截图显示 IPv4 下的 TCP 协议占据了约 83.8% 的字节数。
- 分析思路: 这说明核心线索就在 TCP 流中。如果 TCP 占比极高,通常意味着有大文件传输、反弹 Shell 或者频繁的 Web 访问。
- 异常提醒: 如果发现某个平时很小的协议(比如 ICMP 或 DNS)字节数异常大,那极大概率是隐蔽隧道传输。
2.定位“应用层”:黑客在做什么?
小白最容易理解的就是应用层协议,因为这对应具体的行为。
- HTTP (Hypertext Transfer Protocol): 截图中显示 HTTP 占了约 15.7% 的字节。
- 关注点: 既然有 HTTP,就说明有网页浏览或 API 调用。
- 子项分析: 注意看它下面的
Line-based text data和JavaScript Object Notation (JSON),这代表流量里有纯文本和 JSON 数据。
- DNS (Domain Name System): 占据了 6.1% 的字节。
- 分析思路: 正常的 DNS 包很小,如果字节数偏多,要怀疑是不是在通过 DNS 请求字段“夹带私货”(比如传输 Flag 片段)。
然后我们追踪找到http层的Line字段

哎呀啥也没有,那直接搜一下看看会不会出flag

哎?从1159到1184字段都出现了flag信息,
难不成想告诉我们flag就在这里?

看到右边的Hex编码,出现了一个类似flag的倒影 lf 字符,看看下一条是不是也是这样?

那我们的猜想就是,从编号1159到1184中的Identificantion中都是整个flag的分组倒影,每两个字符为一个倒影

实现脚本
from scapy.all import *
# 1. 加载流量包
pcap_file = 'PIHM3Ov5XLHAw4iX.pcap' //得换你的流量包名字哈,别直接跑啊
packets = rdpcap(pcap_file)
hex_list = []
last_id = None
# 表头,改用简单的字符串加法,避免 f-string 解析错误
print("包编号".ljust(8) + " | " + "原始 ID(Hex)".ljust(12) + " | " + "修复后 ID(Hex)".ljust(12) + " | " + "字符")
print("-" * 60)
# 2. 遍历并处理
for i in range(1158, 1184):
pkt = packets[i]
if IP in pkt:
current_id = pkt[IP].id
# 去重逻辑
if current_id != last_id:
raw_hex = f"{current_id:04x}"
fixed_hex = raw_hex[2:] + raw_hex[:2]
# 使用 ljust 对齐,彻底规避复杂的 f-string 对齐语法
line = f"{i+1}".ljust(8) + " | " + \
f"0x{raw_hex}".ljust(12) + " | " + \
f"0x{fixed_hex}".ljust(12) + " | " + \
bytes.fromhex(fixed_hex).decode(errors='ignore')
print(line)
hex_list.append(fixed_hex)
last_id = current_id
else:
print(f"{i+1}".ljust(8) + " | " + f"0x{current_id:04x}".ljust(12) + " | (跳过重复)".ljust(12) + " | -")
# 3. 最终结果
full_hex = "".join(hex_list)
print("-" * 60)
print(f"[+] 最终拼接 Hex: {full_hex}")
try:
flag = bytes.fromhex(full_hex).decode('utf-8', errors='ignore')
print(f"[+] 最终还原 Flag: {flag}")
except Exception as e:
print(f"[!] 转码异常: {e}")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号