Redis-day2-五种数据结构类型与数据持久化AOF+RDB
五种数据结构类型
字符串:
key [value]
特点:单个key对应单个value,比如name 张三(只能是定义单条)
哈希:
key [value] key [value] …
特点:一个key对应一个value(支持N多条),如name 张三 age 18 …
列表:
key element [element …]
特点:一个key对应多个元素值,如张三 18 男 178cm…
1.字符串
Redis 的 String 类型可以是字符串(简单的字符串、复杂的字符串(例如 JSON、XML))、数字(整数、浮 点数),甚至是二进制(图片、音频、视频),但是值最大不能超过 512MB。
- key [value]
- 特点:单个key对应单个value,比如name 张三(只能是定义单条)
1)添加、重置、删除值
所有内部指令大小写均可,还可用tab键补全,默认补全自动变为大写
格式:
set key value
# 添加/重置值都为set
127.0.0.1:6379> set name 张三
OK
127.0.0.1:6379> get name
张三
127.0.0.1:6379> set name 李四
OK
127.0.0.1:6379> get name
李四
# 删除
127.0.0.1:6379> del name
1
127.0.0.1:6379> get name
此处已为空
2)判断key是否存在
# 新增后存在
127.0.0.1:6379> set name 张三
OK
127.0.0.1:6379> EXISTS name
1
# 删除后不存在
127.0.0.1:6379> del name
1
127.0.0.1:6379> EXISTS name
0
3)ttl过期时间
定义过期格式: set name 张三 ex 10
ex:秒
px:毫秒
查看过期格式: ttl name
过期值:
-1:永久不过期
-2:已过期
设定一个值,默认为永久不过期
# 不过期
127.0.0.1:6379> set name 张三
OK
127.0.0.1:6379> ttl name
-1
# 已过期
127.0.0.1:6379> del name
1
127.0.0.1:6379> ttl name
-2
# 定义五秒后过期
127.0.0.1:6379> set name 张三 ex 2
OK
127.0.0.1:6379> ttl name
2
127.0.0.1:6379> ttl name
1
···
127.0.0.1:6379> ttl name
-2
# 定义100000毫秒后过期
127.0.0.1:6379> set name 张三 px 100000
OK
127.0.0.1:6379> ttl name
99
127.0.0.1:6379> ttl name
98
···
127.0.0.1:6379> ttl name
-2
合并定义值与过期时间:
# 定义值与秒
127.0.0.1:6379> setex name 2 张三
OK
# 定义值与毫秒
127.0.0.1:6379> psetex name 100000 张三
OK
4)判断创建、更新key
格式:
setnx name 张三 # 判断创建
setxx name 张三 # 判断更新
nx:判断创建
xx:判断更新
1.判断一个key不存在则创建,存在则忽略
127.0.0.1:6379> setex name 10 zhangsan
OK
(integer) 10
127.0.0.1:6379> ttl name
(integer) 9
127.0.0.1:6379> ttl name
···
# 当key “张三” 已存在时,定义为李四后获取还是张三
127.0.0.1:6379> set name 李四 nx
127.0.0.1:6379> get name
张三
# 当key不存在时,则会自动判断创建
127.0.0.1:6379> del name
1
127.0.0.1:6379> set name 李四 nx
OK
127.0.0.1:6379> get name
李四
合并set和nx(创建时判断):
# 当key存在时则不建
127.0.0.1:6379> get name
李四
127.0.0.1:6379> setnx name 张三
0
# 当key不存在时则创建
127.0.0.1:6379> del name
1
127.0.0.1:6379> setnx name 张三
1
=====================================================================
2.判断一个key存在则更新,不存在则忽略
# 当key存在时,更新为李四
127.0.0.1:6379> set name 张三
OK
127.0.0.1:6379> set name 李四 xx
OK
# 当key不存在时,则忽略
127.0.0.1:6379> del name
1
127.0.0.1:6379> set name 李四 xx
此处为空
127.0.0.1:6379> get name
此处为空
5)mset定义多个值
mset:定义多个key value
mget:获取多个key value(可用*获取所有key,但需一对一指定获取value,无法获取所有value)
# 定义
127.0.0.1:6379> mset name 张三 age 18 male man
OK
# 获取所有key
127.0.0.1:6379> keys *
age
name
male
# 获取多个value
127.0.0.1:6379> mget name age male
张三
18
man
6)getset先获取后赋值
GETSET命令,先获取,后赋值,赋值后需重新get
127.0.0.1:6379> get name
张三
127.0.0.1:6379> getset name 李四
张三
127.0.0.1:6379> get name
李四
7)setrange更新值
按照下标去更新,指定从第三个字符开始更新
127.0.0.1:6379> set name egon
OK
127.0.0.1:6379> setrange name 2 EGON
6
127.0.0.1:6379> get name
egEGON
8)getrange截取
从0开始算,Peng : 0123
127.0.0.1:6379> get name
Peng
# 获取0~3位
127.0.0.1:6379> getrange name 0 3
Peng
# 从第一为开始获取,-1代表所有
127.0.0.1:6379> getrange name 1 -1
eng
# 2:从第二位开始显示
#-1:从结尾不减显示
#-2:从结尾往前删1位显示,-3从结尾往前删两位显示,以此类推
127.0.0.1:6379> get name
123456
127.0.0.1:6379> getrange name 2 -2
345
9)计数
- Redis当中的计数器是具有原子性的
格式:
INCR # 递增
DECR # 递减
decrby # 指定递增
decrby # 指定递减
strlen # 获取字符串长度
append # 末未追加
# 递增
127.0.0.1:6379> incr num
1
127.0.0.1:6379> incr num
2
127.0.0.1:6379> incr num
3
···
# 递减
127.0.0.1:6379> decr num
2
127.0.0.1:6379> decr num
1
127.0.0.1:6379> decr num
0
127.0.0.1:6379> decr num
-1
···
# 指定递增
127.0.0.1:6379> incrby num 10
10
127.0.0.1:6379> incrby num 10
20
127.0.0.1:6379> incrby num 10
30
# 指定递减
127.0.0.1:6379> decrby num 10
20
127.0.0.1:6379> decrby num 10
10
127.0.0.1:6379> decrby num 10
0
# 获取字符串长度
127.0.0.1:6379> get name
123456
127.0.0.1:6379> strlen name
6
# 末位追加
127.0.0.1:6379> set name 123
OK
127.0.0.1:6379> append name 321
6
127.0.0.1:6379> get name
123321
2.哈希
哈希类型是指键值对里的 value 本身存储的也是一个个的 KV 键值对,类似于 python 中的 dict 和 java 中的 map 集合。
- key [value] key [value] …
- 特点:一个key对应一个value(支持N多条),如name 张三 age 18 …
怎样用一个key存一个人的信息呢?
1)定义、获取值
格式参数:
help @hash # 帮助
hset # 定义 key [value] key [value] ...
hget # 指定key获取value
hmget # 获取指定信息(支持多个)
hgetall # 获取所有信息
# 定义一个人的信息
127.0.0.1:6379> hset people name Peng age 18 male man hobby "play table tennis"
(integer) 0
# 获取单个值(无法获取指定的多个信息,如hget people name age)
127.0.0.1:6379> hget people name
"Peng"
# 获取多个值
127.0.0.1:6379> hmget people name age male
1) "Peng"
2) "18"
3) "man"
# 获取所有 key value
127.0.0.1:6379> hset people name Peng age 18 male man hobby "play table tennis"
(integer) 0
127.0.0.1:6379> hgetall people
1) "name"
2) "Peng"
3) "age"
4) "18"
5) "male"
6) "man"
7) "hobby"
# 只获取所有key
127.0.0.1:6379> hkeys people
1) "name"
2) "age"
3) "male"
4) "hobby"
# 只获取所有value
127.0.0.1:6379> hvals people
1) "Peng"
2) "18"
3) "man"
4) "play table tennis"
2)修改、删除值
# 修改信息(若指定新的key与value,会自动追加到后面)
127.0.0.1:6379> hset people name zhangsan like Sings
(integer) 1
127.0.0.1:6379> hgetall people
1) "name"
2) "zhangsan" # 修改的value
3) "age"
4) "26" # 修改的value
5) "male"
6) "man"
7) "hobby"
8) "swimming"
9) "like" # 新增key
10) "Sings" # 新增value
# 指定删除多条数据
127.0.0.1:6379> hdel people name age
(integer) 2
# 删除所有数据
127.0.0.1:6379> del people
(integer) 1
127.0.0.1:6379> hgetall people
(empty array)
3)计数(递增、递减)
格式:
hincrby # 正数递增,负数递减(整数)
hincrbyfloat #
# 定义id的值为1
127.0.0.1:6379> hset people id 1
# 计数(增加)
(integer) 0
127.0.0.1:6379> hincrby people id 20
(integer) 21
127.0.0.1:6379> hincrby people id 20
(integer) 41
# 计数(递减)
127.0.0.1:6379> hincrby people id -10
(integer) 31
127.0.0.1:6379> hincrby people id -10
(integer) 21
# 递增(小数)
127.0.0.1:6379> hset people id 20
(integer) 0
127.0.0.1:6379> HINCRBYFLOAT people id 1.1
"22.1"
127.0.0.1:6379> HINCRBYFLOAT people id 1.1
"23.2"
# 递减(小数)
127.0.0.1:6379> HINCRBYFLOAT people id -1.1
"22.1"
127.0.0.1:6379> HINCRBYFLOAT people id -1.1
"21"
# PS:144.98999999999999999 # 出现此结果,是精度不够的问题,永远接近
# 获取[key value]的个数,有几个定义项
127.0.0.1:6379> hset people2 name zhangsan age 12 male man
(integer) 3
127.0.0.1:6379> hlen people2
(integer) 3
# 获取某个字段的长度,当前为4位
127.0.0.1:6379> hget people name
"Peng"
127.0.0.1:6379> hstrlen people name
(integer) 4
# 设置过期时间
127.0.0.1:6379> expire people 12
127.0.0.1:6379> ttl people
(integer) 12
127.0.0.1:6379> ttl people
(integer) 11
···
127.0.0.1:6379> ttl people
(integer) -2
127.0.0.1:6379> hgetall people
(empty array) # 直到过期,定义过的信息将自动清空
3.列表
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部 (右边)一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过 40 亿个元素)。
-
key element [element …]
特点:一个key对应多个元素值,如张三 18 男 178cm…
-
redis列表就是redis的字符串类型的集合,按照插入顺序排序
1)lpush左右侧追加
格式:
查看:
lrange # 查看,需指定范围,如0 -1,从0开始,-1为所有,-2从末位减1位...
列表存在则追加,不存在则创建:
lpush # 左侧插入()
rpush # 右侧插入(列表存在则追加,不存在则创建)
列表存在则追加,不存在则忽略:
lpushx # 左侧追加
rpushx # 右侧追加
# 左侧插入(头部追加)
127.0.0.1:6379> lpush people3 zhangsan 18
(integer) 2
127.0.0.1:6379> lrange people3 0 -1
1) "18"
2) "zhangsan"
# 右侧插入(尾部追加)
127.0.0.1:6379> rpush people3 178cm man
(integer) 4
127.0.0.1:6379> lrange people3 0 -1
1) "18"
2) "zhangsan"
3) "178cm"
4) "man"
# 列表存在则左侧追加
127.0.0.1:6379> lpushx people3 home
(integer) 5
127.0.0.1:6379> lrange people3 0 -1
1) "home"
2) "18"
3) "zhangsan"
4) "178cm"
5) "man"
# 从右边追加数据(只有当list存在时才会从右边依次追加元素)
127.0.0.1:6379> rpushx people3 end
(integer) 6
127.0.0.1:6379> lrange people3 0 -1
1) "home"
2) "18"
3) "zhangsan"
4) "178cm"
5) "man"
6) "end"
2)linsert指定位置追加
格式:
指定在某个key前追加
linsert people before [原有key] [新key]
指定在某个key后追加
linsert people after [原有key] [新key]
# 指定在某个key前追加一条(前提列表存在)
127.0.0.1:6379> lrange people3 0 -1
1) "home"
2) "17"
3) "18"
4) "zhangsan"
# 指定在某个key后追加一条(前提列表存在)
127.0.0.1:6379> linsert people3 after 18 19
(integer) 8
127.0.0.1:6379> lrange people3 0 -1
1) "home"
2) "17"
3) "18"
4) "19"
3)lset重新赋值
格式:
lset people [下标序号] [新值]
# 修改数据(指定下标修改数据,下标从零开始)
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "2"
4) "1"
127.0.0.1:6379> lset people3 3 222
OK
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "2"
4) "222"
4)lrem移除values
格式:
lrem people [删除次数] [要删除的内容]
# 移除values(从上往下移除:第一个数为删除的个数,第二个数为要删除的名字)
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "3"
4) "3"
5) "3"
6) "2"
7) "1"
127.0.0.1:6379> lrem people3 4 3 # 删除4次,目标内容为3
(integer) 3
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "2"
4) "1"
5)ltrim剪切保留字符
格式:
ltrim # 剪切保留字符串
# 剪切字符串(将只保留剪切后的字符串,从0位开始)
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "2"
4) "222"
127.0.0.1:6379> ltrim people3 0 2 # 只保留0~2位(即0,1,2,其实是三位)
OK
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "2"
6)llen查看value个数
格式:
llen # 查看value个数
lindex # 按下表查询数据
# 查看value个数
127.0.0.1:6379> LLEN people
5
127.0.0.1:6379> LRANGE people 0 -1
234
shanghai
man
yangge
abc
# 根据下标查询数据,从0开始
127.0.0.1:6379> lrange people3 0 -1
1) "5"
2) "4"
3) "2"
127.0.0.1:6379> lindex people3 2
"2"
7)lpop/rpop左右删除单条
格式:
lpop # 左侧删除一条
rppop # 右侧删除一条
以此为例:
127.0.0.1:6379> lrange people3 0 -1
1) "1"
2) "2"
3) "3"
# 左侧删除一条
127.0.0.1:6379> lpop people3
"1"
127.0.0.1:6379> lrange people3 0 -1
1) "2"
2) "3"
# 右侧删除一条
127.0.0.1:6379> rpop people3
"3"
127.0.0.1:6379> lrange people3 0 -1
1) "1"
2) "2"
8)rpoplpush剪切到新列表
格式:
rpoplpush people3 people4 # 将people3里的右侧一个值剪切到people4
# 剪切
127.0.0.1:6379> lrange people3 0 -1 # 本来people3有1,2
1) "1"
2) "2"
# 将people3里的右侧一个值剪切到people4
127.0.0.1:6379> rpoplpush people3 people4
"2"
# 查看
127.0.0.1:6379> lrange people3 0 -1 # people3内剩下1
1) "1"
127.0.0.1:6379> lrange people4 0 -1 # people4内存增2
1) "2"
9)blpop实时获取值
# 实时获取某一个值
准备两个终端窗口(窗口1::实时监控,窗口2:插入值)
# 窗口1:当前无值是是卡住状态的
127.0.0.1:6379> blpop people3 1000
此处为卡住状态(空)
# 窗口2:插入值
127.0.0.1:6379> lpush people3 hello
(integer) 1
# 窗口1:插入值后则自动打印并结束监控
127.0.0.1:6379> blpop people3 1000
1) "people3"
2) "hello"
(222.50s)
127.0.0.1:6379>
4.无序集合
Redis 的 Set 是 string 类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储 40 多亿个成员)。
1)sadd新增数据
# 增加数据
127.0.0.1:6379> sadd people4 1
(integer) 1
127.0.0.1:6379> sadd people4 12
(integer) 1
127.0.0.1:6379> sadd people4 123
(integer) 1
127.0.0.1:6379> sadd people4 1234
(integer) 1
# 查看数据
127.0.0.1:6379> smembers people4
1) "1"
2) "12"
3) "123"
4) "1234"
2)删除、移动
# 删除
127.0.0.1:6379> srem people4 1234 123
(integer) 2
127.0.0.1:6379> smembers people4
1) "1"
2) "12"
# 移动数据:将people4内的1移动至people5
127.0.0.1:6379> smove people4 people5 1
(integer) 1
127.0.0.1:6379> smembers people4
1) "12"
127.0.0.1:6379> smembers people5
1) "1"
3)交集、并集、差集
127.0.0.1:6379> SADD people5 1 2 3 4
(integer) 4
# 返回集合当中的个数
127.0.0.1:6379> scard people5
(integer) 4
# 随机返回两个数据
127.0.0.1:6379> srandmember people5 3
1) "2"
2) "1"
3) "3"
# 判断一个数据是否存在一个集合中
127.0.0.1:6379> SISMEMBER mysqlset abc
(integer) 0
127.0.0.1:6379> SISMEMBER mysqlset 1
(integer) 1
# 随机删除两个成员
127.0.0.1:6379> smembers people5
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> spop people5 2
1) "1"
2) "2"
127.0.0.1:6379> smembers people5
1) "3"
2) "4"
# 定义三组数据
127.0.0.1:6379> sadd people5 1 2 3 4
(integer) 4
127.0.0.1:6379> sadd people6 2 3 4 5
(integer) 4
127.0.0.1:6379> sadd people7 3 4 5 6
(integer) 4
# 返回多个集合中的交集(只显示三个彼此共同拥有的相同值)
127.0.0.1:6379> sinter people5 people6 people7
1) "3"
2) "4"
# 返回多个集合的并集(显示三个彼此都有的所有值)
127.0.0.1:6379> sunion people5 people6 people7
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
# 返回集合的差集(后两者相对于第一个,共同缺少的值)
127.0.0.1:6379> sdiff people5 people6 people7
1) "1"
5.有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一 个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的, 但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大 的成员数为 2^32 - 1 (4294967295, 每个集合可存储 40 多亿个成员)。
1)增删改
格式:
zadd # 增
zrem # 删
zrange # 查
# 添加数据
127.0.0.1:6379> zadd people4 1 name 2 age
(integer) 2
# 查询数据
127.0.0.1:6379> zrange people4 0 -1
1) "name"
2) "age"
3) "male"
#删除数据
127.0.0.1:6379> zrem people4 name age male
(integer) 3
127.0.0.1:6379> zrange people4 0 -1
(empty array)
6.常用命令
1)查看所有key
keys * # 查看所有key
127.0.0.1:6379> keys *
1) "people"
2) "male"
3) "age"
4) "Peng"
5) "people4"
6) "1"
7) "num"
8) "a"
9) "b"
10) "people2"
2)查看key类型
type [key_name] # 查看key类型
127.0.0.1:6379> type people
hash
3)随即返回一个key
randomkey # 随即返回一个key
127.0.0.1:6379> randomkey
"age"
127.0.0.1:6379> randomkey
"1"
4)删除key
del [key]
127.0.0.1:6379> del people people2
(integer) 2
5)查看key是否存在
exists [key1 key2 key3...]
127.0.0.1:6379> exists peole
(integer) 0
6)重命名
127.0.0.1:6379> rename people cat
OK
7)查看key生存时间
# 以秒为单位
ptth keya
-1
# 以好买哦为单位
pttl a
-1
-1:永不过期
-2:已过期
数据持久化AOF+RDB
1.Redis 数据安全问题
前面我们提到,Redis 是一个缓存中间件,它的最大特点是使用内存从而使其性能强悍,但是使用内存的方式有一个致命的特点,就是数据没办法持久化保存。
然而 Redis 持久化存储有两种持久化方案:
RDB(Redis DataBase)
将内存中的数据进行快照存储到磁盘
AOF(Append-Only File)
可回放的命令日志记录 redis 内的所有操作
它们各有特点也相互独立。Redis4 之后支持 RDB-AOF 混合持久化的方式,结合了两者的优点,可以通过 aof-use-rdb-preamble 配置项可以打开混合开关。
2.快照持久化(RDB)
RDB(Redis DataBases)是将内存中的数据进行快照(Snaptshot)存储在磁盘内,是Redis默认的持久化方案。
1)自动触发
RDB持久化默认的三种触发策略,可在redis.conf中进行配置:
save 900 1 # 900 秒内有一个 key 变化
save 300 10 # 300 秒内有 10 个 key 变化
save 60 10000 # 60 秒内有 1w 个 key 变化
快照文件名为 dump.rdb,该文件默认使用 LZF 压缩算法 。每当 Redis 服务重启的时候会从该 文件中加载数据进内存。
2)手动触发
RDB 持久化除了可以根据配置中的策略触发,也可以手动触发,直接使用 save 和 bgsave 命令回车即可。
save与bgsave的区别:
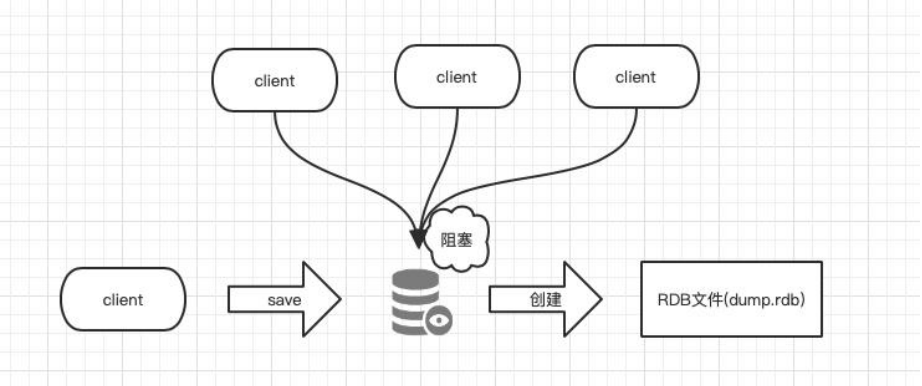
save:会阻塞服务器进程,在进行save时,服务器不能处理任何请求;
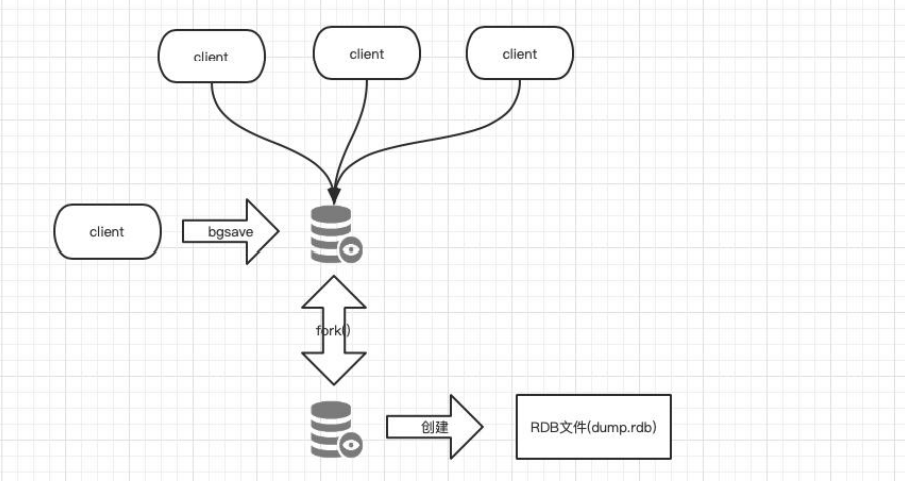
bgsave:会通过一个子进程在后台处理RDB持久化;
由子进程将内存中最新数据写入临时文件,此时父进程仍旧处理客户端操作,当子进程操作完毕后再将临时文件命名为dump.rdb,替换掉原来的dump.rdb文件,因此无论 bgsave 是否成功,dump.rdb 都不会受到影响。
PS:两者都是调用rdbSave函数,因此redis不允许两者同时运行,避免其竞争而导致文件数据不准确。
另外在主从全量同步、debug reload 以及 shutdown 的情况下也会触发 RDB 数据持久化。
3.RDB原理
save 原理图:
bgsave 原理图:
- RDB 的优点
- RDB 是一种表示某个即时点的 Redis 数据的紧凑文件。RDB 文件适合用于备份。例如,你可能想要每小时归 档最近 24 小时的 RDB 文件,每天保存近 30 天的 RDB 快照。这允许你很容易的恢复不同版本的数据集以容 灾。
- RDB 非常适合于灾难恢复,作为一个紧凑的单一文件,可以被传输到远程的数据中心。
- RDB 最大化了 Redis 的性能,因为 Redis 父进程持久化时唯一需要做的是启动(fork)一个子进程,由子进程完 成所有剩余工作。父进程实例不需要执行像磁盘 IO 这样的操作。
- RDB 在重启保存了大数据集的实例时比 AOF 要快。
- RDB 的缺点
- 当你需要在 Redis 停止工作(例如停电)时最小化数据丢失,RDB 可能不太好。你可以配置不同的保存点(save point)来保存 RDB 文件(例如,至少 5 分钟和对数据集 100 次写之后,但是你可以有多个保存点)。然而,你 通常每隔 5 分钟或更久创建一个 RDB 快照,所以一旦 Redis 因为任何原因没有正确关闭而停止工作,你就得 做好最近几分钟数据丢失的准备了。
- RDB 需要经常调用 fork()子进程来持久化到磁盘。如果数据集很大的话,fork()比较耗时,结果就是,当数据 集非常大并且 CPU 性能不够强大的话,Redis 会停止服务客户端几毫秒甚至一秒。AOF 也需要 fork(),但是你 可以调整多久频率重写日志而不会有损(trade-off)持久性(durability)。
- RDB 优缺点总结
- 优点:速度快,适合于用作备份,主从复制也是基于 RDB 持久化功能实现的。
- 缺点:会有数据丢失、导致服务停止几秒
4.配置数据持久化
1)配置持久化
1.创建持久化文件存储目录(若不手建,在配置文件内指定会自动创建)
[root@k8s-master1 ~]# mkdir /usr/local/redis/data
2.修改持久化文件存储目录
[root@k8s-master1 ~]# vim /usr/local/redis/conf/redis.conf
dir /usr/local/redis/data
3.开启数据持久化(RDB触发机制,默认就是是开启的)
[root@k8s-master1 ~]# vim /usr/local/redis/conf/redis.conf
save 900 1 # 900秒内至少有1个key被改变则做一次快照
save 300 10 # 300秒内至少有10key被改变做一次快照
save 60 10000 # 60秒内至少有10000个key被改变则做一次快照
4.Redis服务在data目录下会生成备份数据文件(dump.rdb)
[root@k8s-master1 ~]# systemctl start redis
[root@k8s-master1 ~]# ll
总用量 0
drwxr-xr-x 2 root root 134 4月 30 20:35 bin
drwxr-xr-x 2 root root 24 5月 1 10:36 conf
drwxr-xr-x 2 root root 22 5月 1 10:37 data
[root@docker redis]# cd data/
[root@docker data]# ll
总用量 4
-rw-r--r-- 1 root root 92 5月 1 10:37 dump.rdb
2)配置文件详解
[root@k8s-master1 ~]# vim /usr/local/redis/bin/redis.conf
# 配置快照(rdb)促发规则,格式:save <seconds> <changes>
# save 900 1 900 秒内至少有 1 个 key 被改变则做一次快照
# save 300 10 300 秒内至少有 300 个 key 被改变则做一次快照
# save 60 10000 60 秒内至少有 10000 个 key 被改变则做一次快照
# 注释掉上方默认规则,使用 svae “”
dbfilename dump.rdb
# rdb 持久化存储数据库文件名,默认为 dump.rdb
stop-write-on-bgsave-error yes
# yes 代表当使用 bgsave 命令持久化出错时候停止写 RDB 快照文件,no 表明忽略错误继续写文件。
rdbchecksum yes
# 在写入文件和读取文件时是否开启 rdb 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
dir "/etc/redis"
# 数据文件存放目录,rdb 快照文件和 aof 文件都会存放至该目录,请确保有写权限
rdbcompression yes
# 是否开启 RDB 文件压缩,该功能可以节约磁盘空间
3)停止备份设置
config set save “” # 命令行方式直接执行
save “” # 在配置文件中就设置
4)手动开始备份
save # 会立即生成 dump.rdb,但是会阻塞往 redis 内存中写入数据。
bgsave # 后台异步备份。
如果是使用 flushdb 命令,会把之前的快照更新成当前的空状态,所以执行了 flushdb 后更新的快照是没有数据的。
5)save 与 bgsave 对比
| 命令 | save | bgsave |
|---|---|---|
| IO 类型 | 同步 | 异步 |
| 是否阻塞 | 是 | 否(阻塞发生在fork) |
| 优点 | 不消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端 命令 | 创建fork,消耗内存 |
5.持久化(AOF)
总结:
RDB:将数据通过二进制快照方式保存下来
AOF:将数据通过命令文本的方式保存下来
混合:二进制快照+命令文本方式(取两者优点)
1)简介
AOF(Append-Only File)记录 Redis 中每次的写命令,类似 mysql 中的 binlog,服务重启时会重新执行 AOF 中的 命令将数据恢复到内存中,RDB(按策略持久化)持久化方式记录的粒度不如 AOF(记录每条写命令),因此很多生产 环境都是开启 AOF 持久化。AOF 中记录了操作和数据,在日志文件中追加完成后才会将内存中的数据进行变更。
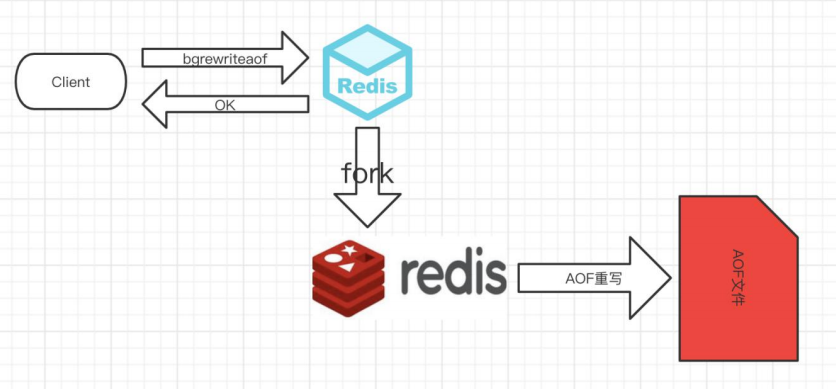
2)原理
- 客户端的请求写命令会被 append 追加到 AOF 缓冲区内;
- AOF 缓冲区根据 AOF 持久化策略[always,everysec,no]将操作 sync 同步到磁盘的 AOF 文件中;
- AOF 文件大小超过重写策略或手动重写时,会对 AOF 文件 rewrite 重写,压缩 AOF 文件容量;
- Redis 服务重启时,会重新 load 加载 AOF 文件中的写操作达到数据恢复的目的;
3)AOF 配置
开启了 AOF 之后,RDB 就默认不使用了,使用下面的配置开启 AOF 以及策略。
如果使用 AOF,推荐选择 always 方式持久化,否则在高并发场景下,每秒钟会有几万甚至百万条请求,如果使用 everysec 的方式的话,万一服务器挂了那几万条数据就丢失了
# 开启 AOF 持久化
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# AOF 文件存储路径 与 RDB 是同一个参数
dir "/opt/app/redis6/data"
# AOF 策略,一般都是选择第一种[always:每个命令都记录],[everysec:每秒记录一次],[no:看机器的心情高兴了就记录]
appendfsync always
# appendfsync everysec
# appendfsync no
# aof 文件大小比起上次重写时的大小,增长 100%(配置可以大于 100%)时,触发重写。[假如上次重写后大小为10MB,当 AOF 文件达到 20MB 时也会再次触发重写,以此类推]
auto-aof-rewrite-percentage 100
# aof 文件大小超过 64MB 时,触发重写
auto-aof-rewrite-min-size 64mb
# 是否在后台写时同步单写,默认值 no(表示需要同步).这里的后台写,表示后台正在重写文件(包括 bgsave和 bgrewriteaof.bgrewriteaof 网上很多资料都没有涉及到。其实关掉 bgsave 之后,主要的即是 aof 重写文件了).no 表示新的主进程的 set 操作会被阻塞掉,而 yes 表示新的主进程的 set 不会被阻塞,待整个后台写完成之后再将这部分 set 操作同步到 aof 文件中。但这可能会存在数据丢失的风险(机率很小),如果对性能有要求,可以设置为 yes,仅在后台写时会异步处理命令。
no-appendfsync-on-rewrite no
# 指 redis 在恢复时,会忽略最后一条可能存在问题的指令。默认值 yes。即在 aof 写入时,可能存在指令写错的问题(突然断电,写了一半),这种情况下,yes 会 log 并继续,而 no 会直接恢复失败。
aof-load-truncated
4)AOF 持久化策略
AOF 分别有三种备份策略,分别是[always:每个命令都记录],[everysec:每秒记录一次],[no:看机器的心情高兴了就记录],针对这三种策略给出如下说明。
1> 策略说明
| 策略 | 说明 | 优点 |
|---|---|---|
| always | 每次执行,都会持久化到 AOF 文件中 | 不丢失数据 |
| everysec | 每秒持久化一次 | 减少 IO |
| no | 根据服务器性能持久化 | 全自动 |
2> 策略抉择
| 命令 | Always | Everysec |
|---|---|---|
| 优点 | 不丢失数据 | 每秒一次 fsync,减少 IO |
| 缺点 | IO 开销大 | 丢 1 秒钟的数据 |
5)AOF 重写配置
AOF 持久化机制记录每个写命令,当服务重启的时候会复现 AOF 文件中的所有命令,会消耗太多的资源且 重启很慢。因此为了避免 AOF 文件中的写命令太多文件太大,Redis 引入了 AOF 的重写机制来压缩 AOF 文件体积。 AOF 文件重写是把 Redis 进程内的数据转化为写命令同步到新 AOF 文件的过程。
| 配置名 | 含义 |
|---|---|
| appendonly | 开启 AOF 持久化功能 |
| auto-aof-rewrite-min-size | 触发重写的最小尺寸 |
| auto-aof-rewrite-percentage | AOF 文件增长率 |
| aof_current_size | AOF 当前尺寸 |
| aof_base_size | AOF 上次启动和重写的尺寸(单位:字节) |
6)AOF 重写触发机制
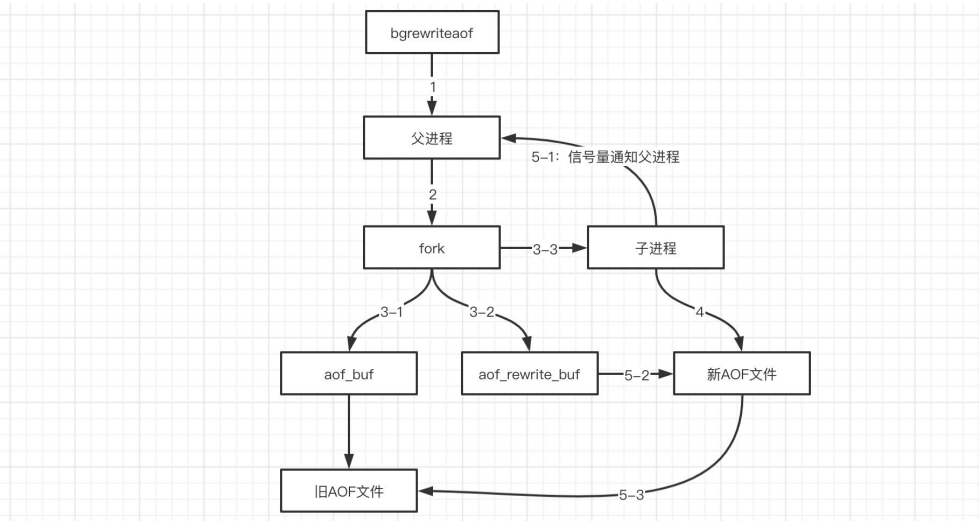
根据配置,AOF 持久化触发机制如下:
1. aof_current_size > auto-aof-rewrite-min-size
2. (aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage
7)AOF 重写流程
6.RDB与AOF抉择
1)RDB 与 AOF 比较
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 块 | 慢 |
| 数据安全性 | 丢数据 | 根据策略的不同,丢数据的情况也不同 |
| 轻重 | 重 | 轻 |
2)RDB与AOF之间的优劣势
1> RDB 的优点
- 压缩后的二进制文件,适用于备份、全量复制及灾难恢复。
- RDB 恢复数据性能优于 AOF 方式。
2> RDB 的缺点
- 无法做到实时持久化,每次都要创建子进程,频繁操作成本过高
- 保存后的二进制文件,不同版本直接存在兼容性问题
3> AOF 的优点
- 以文本形式保存,易读
- 记录写操作保证数据不丢失
4> AOF 的缺点
- 存储所有写操作命令,且文件为文本格式保存,未经压缩,文件体积高
- 恢复数据时重放 AOF 中所有代码,恢复性能弱于 RDB 方式。
3)AOF与RDB混合
看了上面的 RDB 和 AOF 的介绍后,我们可以发现,使用 RDB 持久化会有数据丢失的风险,但是恢复速度快, 而使用 AOF 持久化可以保证数据完整性,但恢复数据的时候会很慢。于是从 Redis4 之后新增了混合 AOF 和 RDB 的模式,先使用 RDB 进行快照存储,然后使用 AOF 持久化记录所有的写操作,当重写策略满足或手动触发重写 的时候,将最新的数据存储为新的 RDB 记录。这样的话,重启服务的时候会从 RDB 何 AOF 两部分恢复数据,即保证了数据完整性,又提高了恢复的性能。
开启混合模式后,每当 bgrewriteaof 命令之后会在 AOF 文件中以 RDB 格式写入当前最新的数据,之后的新 的写操作继续以 AOF 的追加形式追加写命令。当 redis 重启的时候,加载 aof 文件进行恢复数据:先加载 rdb 的 部分再加载剩余的 aof 部分。
1> 混合配置
修改下面的参数即可开启 AOF,RDB 混合持久化
aof-use-rdb-preamble yes
2> 混合模式的使用
开启混合持久化模式后,重写之后的 aof 文件里和 rdb 一样存储二进制的快照数据,继续往 redis 中进行写 操作,后续操作在 aof 中仍然是以命令的方式追加。因此重写后 aof 文件由两部分组成,一部分是类似 rdb 的二 进制快照,另一部分是追加的命令文本。
# step: 进入 Redis, 写入数据
[root@alvin-test-os redis]# redis-cli --raw
127.0.0.1:6379> set name alvin
OK
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> set add 上海
OK
127.0.0.1:6379> exit
# Step 2: 查看备份文件
[root@alvin-test-os redis]# ll data/
总用量 8
-rw-r--r--. 1 root root 121 11 月 24 15:39 appendonly.aof
-rw-r--r--. 1 root root 116 11 月 24 15:39 dump.rdb
[root@alvin-test-os redis]# cat data/appendonly.aof | grep add
add
[root@alvin-test-os redis]# cat data/appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$4
name
$5
alvin
*3
$3
set
$3
age
$2
18
*3
$3
set
$3
add
$6
上海
# Step 3: 启动备份
[root@alvin-test-os redis]# redis-cli --raw
127.0.0.1:6379> BGREWRITEAOF
Background append only file rewriting started
127.0.0.1:6379> exit
# Step 4: 查看配置文件发现 AOF 备份文件变成了二进制文件
[root@alvin-test-os redis]# cat data/appendonly.aof
REDIS0009� redis-ver6.0.9�
�edis-bits�@�ctime��_used-mem��4
aof-preamble���namealvinadd 上海 age���6����&[root@alvin-test-os redis]#
# Step 5: 再次写入文件
[root@alvin-test-os redis]# redis-cli --raw
127.0.0.1:6379> set company 上海老男孩
OK
127.0.0.1:6379> exit
# Step 6:再次查看备份文件发现被分成了两份,一份二进制,一份 AOF 备份
[root@alvin-test-os redis]# cat data/appendonly.aof
REDIS0009� redis-ver6.0.9�
�edis-bits�@�ctime��_used-mem��4
aof-preamble���namealvinadd 上海 age���6����&*2
$6
SELECT
$1
0
*3
$3
set
$7
company
$15
上海老男孩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号