补交2,4,5,7
02
1、安装Linux操作系统


2、安装关系型数据库MySQL

3、安装大数据处理框架Hadoop,查看IP

04
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。
Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
Hadoop的历史版本
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
、HDFS 采用主/从架构,主节点即NameNode 从节点即:DataNode
2、NameNode即是模式, 并完成外模式和模式之间的映像,模式和内模式之间的映像。
3、NameNode存放HDFS全局命名空间,充当全局数据目录;存储全局文件系统树,目录-文件-文件块信息
NameNode存放的数据块信息是在启动时扫描所有数据节点重构;
在运行过程中周期性受到数据节点发送的数据块列表信息重构而得;
4、在客户端读取数据过程中,将数据块和数据节点映射按远近排序列表发送给客户端;
5、在客户端写数据过程中,检查文件是否存在、是否有权限;将待写入文件分成若干文件块,并根据数据节点的繁忙和磁盘容量程度,分配数据块和数据节点对应关系列表反馈给客户端;
6、HDFS文件块默认是64M,普通文件块的大小为521字节;
相互关系:
名称节点管理文件系统的命名空间。它维护着这个文件系统树及这个树内所有的文件和索引目录。这些信息以两种形式将文件永久保存在本地磁盘上:命名空间镜像和编辑日志。名称节点也记录着每个文件的每个块所在的数据节点,但它并不永久保存块的位置,因为这些信息会在系统启动时由数据节点重建。
名称结点的工作机制:
名称节点启动时,会将FsImage的内容加载到内存当中,然后执行EditLog文件中的各项操作,使得内存中的元数据保存最新。这个操作完成后,就会创建一个新的FsImage文件和一个空的EditLog文件。名称节点启动成功并进入正常运行状态以后,HDFS中的更新操作都会被写入到EditLog,而不是直接写入FsImage
05


07
1.理解HBase表模型及四维坐标:行键、列族、列限定符和时间戳。
2.启动HDFS,启动HBase,进入HBaseShell命令行。
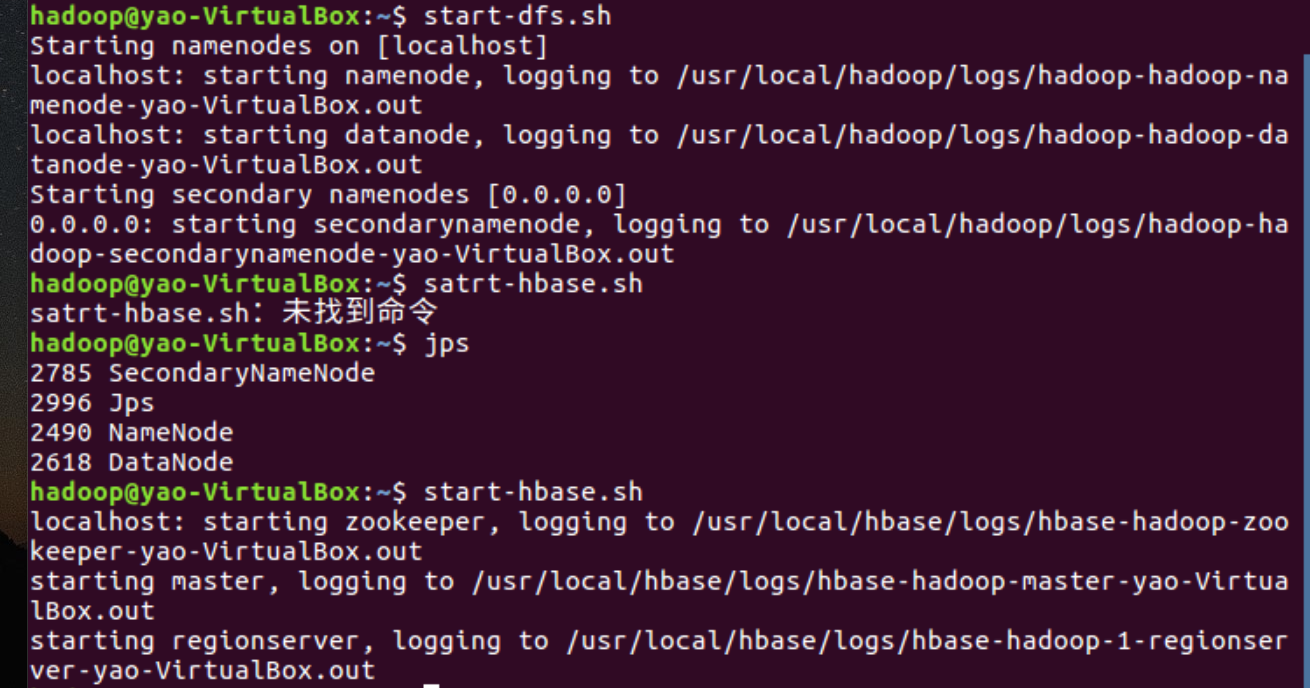

3.列出HBase中所有的表信息list
4.创建表create

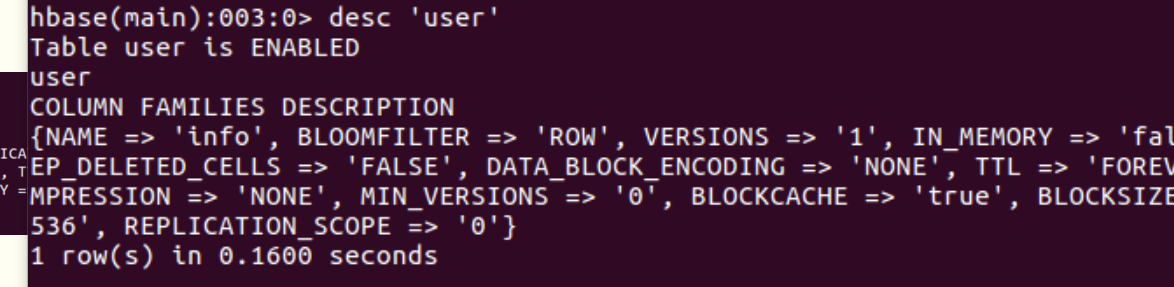
5.查看表详情desc
6.插入数据put

7.查看表数据scan,get


 浙公网安备 33010602011771号
浙公网安备 33010602011771号