AI大视觉(八) | Yolov3 如何调整先验框进行解码?
本文来自公众号“AI大道理”
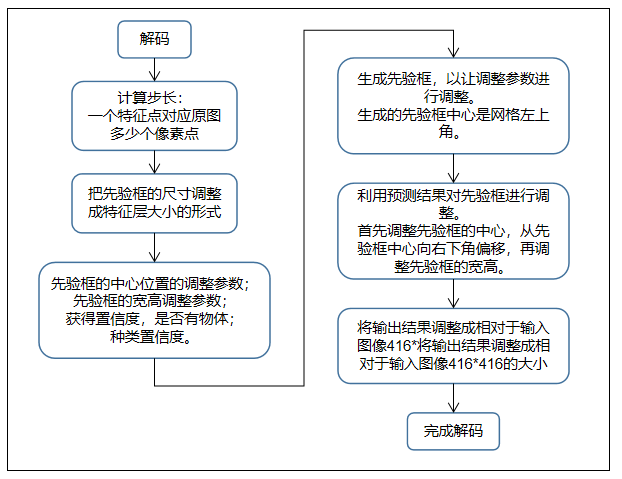
解码就是将预测得到的调整参数应用于先验框,从而得到预测框。

![]() 解码原理
解码原理
YOLOv3借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。
YOLOv3预测边界框中心点相对于对应cell左上角位置的相对偏移值,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1),把边界框中心点约束在当前cell中。
根据边界框预测的4个offsetstx,ty,tw,th,可以按如下公式计算出边界框实际位置和大小:
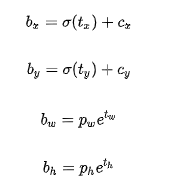
![]()
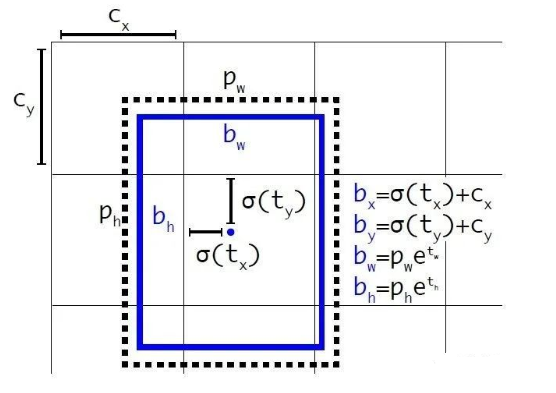
(cx,xy)为cell的左上角坐标,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为((1,1)。
由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。
而pw和ph是先验框的宽度与长度,它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。
这里记特征图的大小为(W,H),可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间)
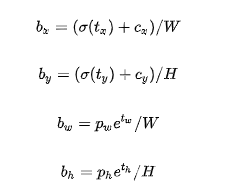
![]()
将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了,这就是YOLOv3边界框的解码原理。
![]()
![]() 解码过程
解码过程
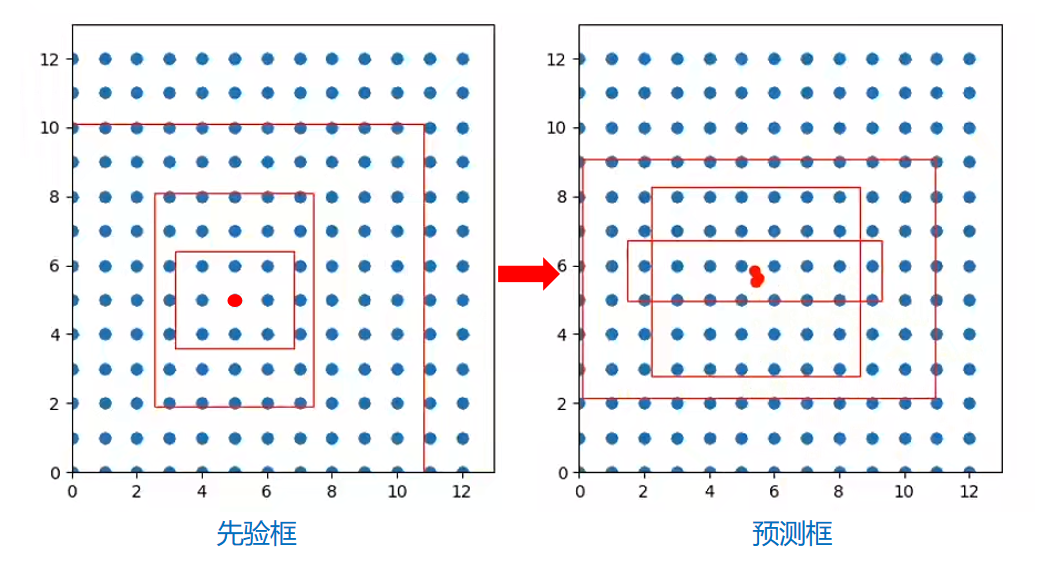
(1)生成先验框
以13*13这个特征层为例,一共有13*13个网格,每个网格有3个先验框。
生成的先验框的中心是网格的左上角。
先验框的宽高可以自己设定或者通过K-means聚类得到。
(2)缩放先验框
解码是在特征层上进行的,所以需要缩放先验框至特征层大小的比例,计算出先验框在特征层上对应的框高。
(3)调整先验框
解码每次只能对一个特征层进行解码,因此需要进行3次循环解码。
yolov3网络的预测结果得到一维的参数,这些参数包含了宽高的调整参数、中心的调整参数、置信度、类别概率等。
先验框的中心位置的调整参数,sigmoid使得每个物体由左上角的网格点进行预测,因为0-1的话中心只能往右下角偏移。
得到这些调整参数利用解码原理中的公式作用到先验框,对先验框进行调整,获得最终的预测框。
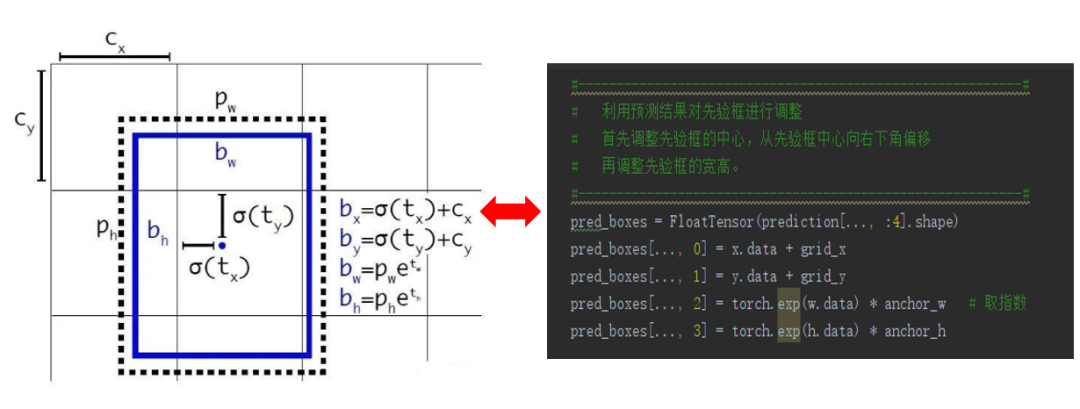
![]()
![]()
(4)得到预测框
此时获得的scaled_anchors大小是相对于特征层的。
先验框的调整是在特征图上进行调整的,然后再放大到原图上得到最终的预测框。
![]()
![]() 总结
总结
Yolov3 的解码就是利用预测结果的调整参数,从而调整先验框得到预测框的过程。
调整是在特征图上进行的,因此需要先根据特征图大小缩放先验框,然后利用公式作用到先验框上,实现先验框的调整。
再将调整后的先验框放大到原图上,得到预测框。
这就是整个解码过程了。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号