南大&港中文发布 DiffThinker:生成式推理新范式!
 扩散即推理! 性能超越GPT-4V
扩散即推理! 性能超越GPT-4V
目前主流的多模态大模型(如 GPT-4V, LLaVA)在处理复杂的视觉推理任务(如拼图、逻辑找规律等)时,受限于自回归生成的模式。 这些模型主要通过文本预测来描述答案,缺乏在视觉空间中直接进行思维推演的能力。
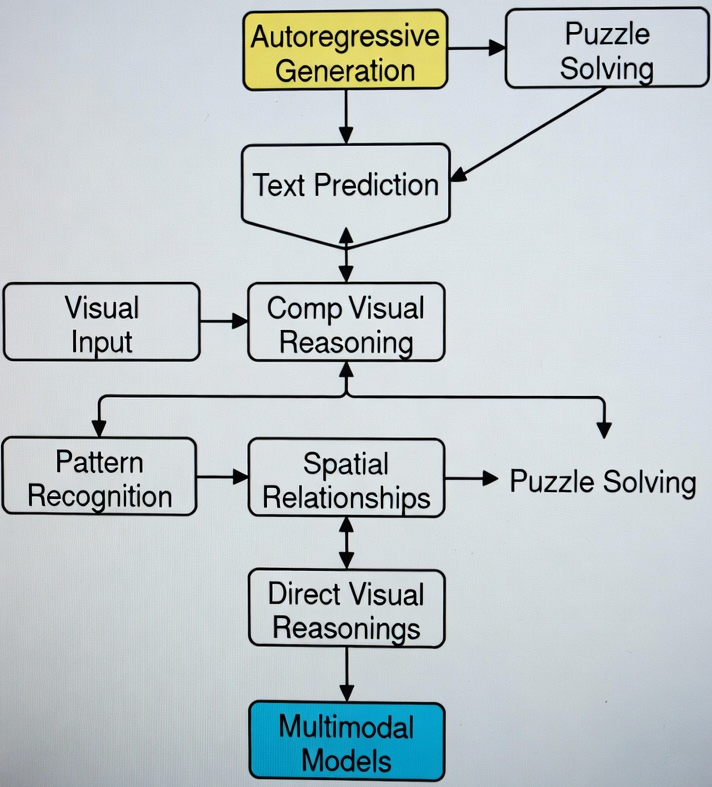
传统方法对离散文本标签存在高度依赖性,以此刻画视觉逻辑的方式,致使模型仅能感知图像的表层特征,却无法在认知层面重构其背后的潜在规律。 这种语言表征与空间逻辑的割裂,成为当前通用人工智能实现深度视觉推理的核心瓶颈。 正是在此行业背景下,迫切需要重塑模型 “边推理边生成” 的直觉式视觉推理能力。
近期,南京大学联合港中文团队发布了论文《DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models》,提出了一种将生成式扩散过程与多模态逻辑推演深度耦合的全新技术范式。 打破了传统多模态模型仅依赖自回归文本预测来描述逻辑的局限,首次系统性地将扩散模型作为核心推理引擎,构建了在潜在空间中进行视觉构思的思维机制。
认知困局:传统MLLM的表征瓶颈
在通用人工智能(AGI)的演进图谱中,多模态大语言模型(MLLM)虽然在语义理解和跨模态对话上取得了里程碑式的突破, 但在面对需要严密空间推理与抽象逻辑归纳的任务时,却频繁遭遇认知天花板。这一现象并非孤立存在 ,而是深深植根于当前主流架构的表征缺陷之中。
现有的主流MLLM在处理视觉任务时, 本质上仍是在执行“图像到文本(Image-to-Text)”的翻译过程。 这种将连续的高维视觉信息强行压缩为离散文本Token的做法,在处理瑞文标准推理测验(RPM)或复杂迷宫导航等任务时显得捉襟见肘。
架构解析:非对称双流与隐式纠缠的完美耦合
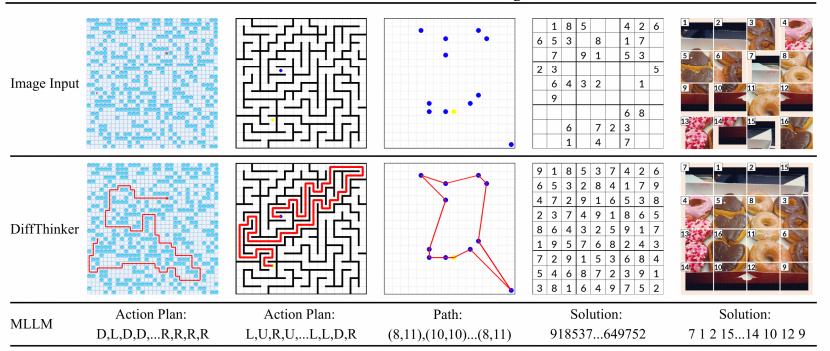
针对上述痛点,本文正式提出了DiffThinker(Diffusion-based Thinker)。这不仅仅是一个新的模型架构, 更是一种全新的计算范式:将多模态推理重构为原生的“图像到图像(Image-to-Image)”生成任务 ,利用扩散模型的去噪过程来模拟人类的思维推演。
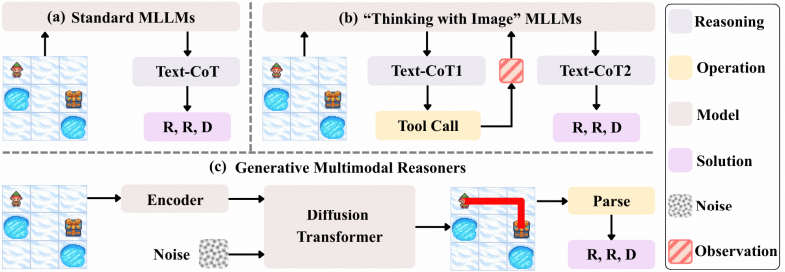
DiffThinker的整体设计体现了“感知-思考-生成”的闭环逻辑。 该模型由一个强大的视觉感知前端和一个深度定制的条件扩散模型后端组成。 与传统模型直接输出答案不同,DiffThinker将问题图像映射到潜在空间,通过扩散模型在特征层面进行迭代,最终“画”出符合逻辑的解。
这种架构首次实现了在像素级精度上对逻辑规律的直接响应。
扩散即推理:潜在空间的思维链
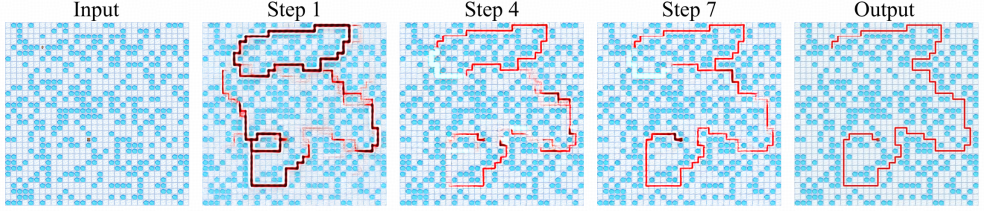
DiffThinker技术优越性的核心在于其独特的推理机制。 引入了基于Transformer的扩散骨干网络,通过流匹配(Flow Matching)算法优化生成路径。 在这个过程中,去噪的每一步不再仅仅是恢复图像细节,而是在逐步剔除不符合逻辑的候选解,使潜在特征向“真理”收敛。
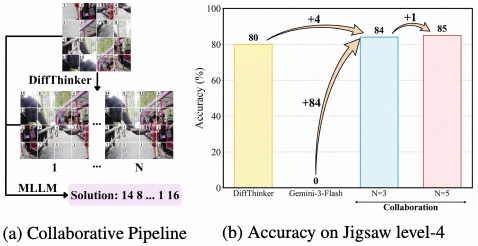
为了增强模型在复杂场景下的适应性,设计了“潜在空间交互机制”。 该机制允许模型在推理过程中动态调用历史视觉信息,形成类似于人类回看与比对的短期记忆能力,确保了长链条推理的连贯性。
逻辑对齐与跨模态约束
生成式模型面临的最大挑战是逻辑漂移。 为此,DiffThinker 集成了“跨模态注意力对齐模块”。该模块就像一个严厉的逻辑考官,实时计算生成特征与输入条件之间的注意力权重,强行约束扩散过程必须严格遵循题目给定的几何与物理规则,从而杜绝了天马行空的无效生成。
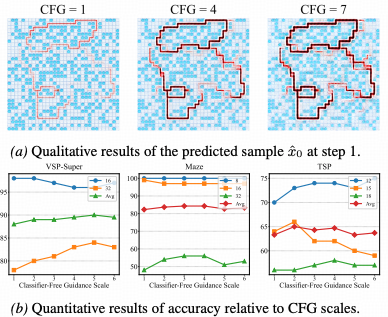
动态计算:像人类一样深思熟虑
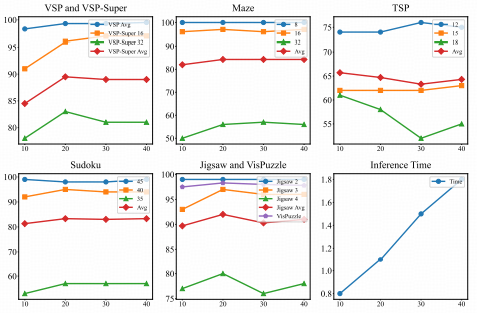
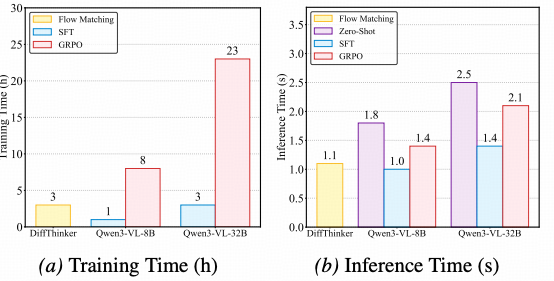
DiffThinker展现出了类人的思考时间特性。实验结果表明,扩散步数(Timesteps)与推理精度之间存在显著的正相关关系。 面对简单问题,模型可以快速生成答案;而面对复杂逻辑,增加采样步数能显著提升输出的准确性。 这种可调节的计算消耗,为不同场景下的推理部署提供了极大的灵活性。
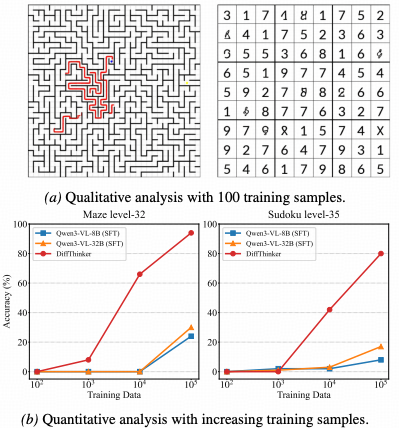
性能飞跃:测验中突破机器智能上限
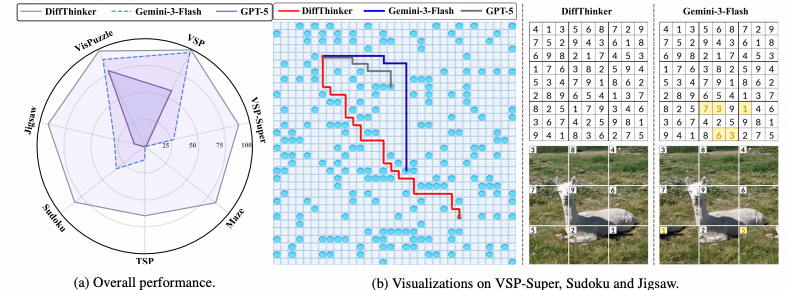
为了验证DiffThinker在多模态逻辑推理任务中的真实效能,研究团队在包括瑞文标准推理测验(RAVEN)、程序生成矩阵(PGM)等权威基准上进行了广泛的定量与定性评估。 实验结果表明,通过引入生成式思维链,模型不仅在准确率上大幅超越了现有的自回归大模型,更在视觉生成的一致性与逻辑泛化性上树立了新的行业标杆。
突破基准:SOTA模型 vs DiffThinker
首先对比了DiffThinker与当前最先进的自回归模型在纯视觉逻辑任务上的表现。传统模型呈现出一个反直觉的“伪智能”现象:即便参数量成倍增加,其在涉及长程空间规划的任务中,错误率并未显著下降,反而往往在推理数步后陷入发散。
相比之下,DiffThinker 凭借扩散过程的自我修正能力,始终保持了逻辑轨迹的收敛与精确。
核心性能:超越GPT-4V的逻辑准确率
将DiffThinker与当前最先进的多模态大模型(包括 GPT-4V, LLaVA-Next, Gemini 等)进行横向对比。
实验显示,DiffThinker在极具挑战性的“非语言推理”任务上取得了SOTA的成绩。与传统的判别式模型相比,DiffThinker在处理复杂的几何变换(如旋转、镜像、数量递增)时,平均准确率提升了显著的百分点。 这证明了:在解决视觉逻辑问题时,“生成即推理”范式比单纯的“看图选答案”具有更高的逻辑上限。
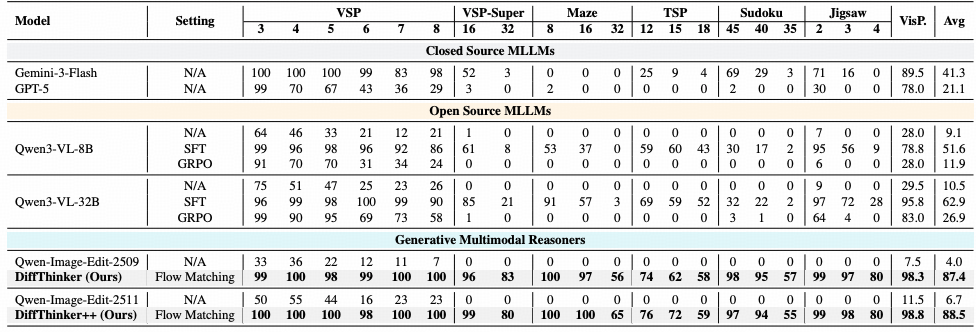
质量评估:像素级的逻辑自洽性
面对需要精细纹理对齐和空间结构保持的任务时,基线模型往往会出现模糊、伪影或几何结构崩塌(如正方形变成了不规则多边形)。而DiffThinker生成的图像不仅清晰度极高,更重要的是完美复现了题目中隐含的逻辑规律(如颜色的渐变序列或图形的周期性排布)。 这种高保真生成,验证了扩散模型在潜在空间中对逻辑特征的精确捕获。
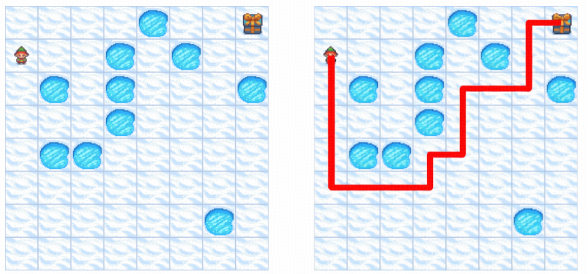
泛化验证:应对复杂多变的推理场景
针对高阶逻辑的一致性验证,构建了包含多重嵌套规则的3x3高维矩阵推理任务。即便题目中同时存在几何拓扑变换(如旋转、镜像)与视觉属性演变(如色彩递变、纹理映射)的深度耦合,DiffThinker依然展现出了卓越的多维约束解耦能力。
总结与展望:开启视觉直觉与深度逻辑的共生时代
DiffThinker的成功不仅是算法结构的优化,更是对推理本质的一次深刻重构。它向我们展示了: 真正的多模态智能不应仅是文字的堆砌,更应是感官生成与逻辑推演的有机统一。
作为该领域的先锋尝试,DiffThinker为未来自动驾驶、科学图像分析以及复杂的人机协同任务奠定了关键的技术基石。 随着生成式推理范式的不断演进,我们正见证AI从能言善辩向深思熟虑的本质转化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号