何恺明团队再放大招!本科生领衔BiFlow!
 双向流的艺术:当数据与噪声实现零损耗完美互通!
双向流的艺术:当数据与噪声实现零损耗完美互通!
近期,MIT何恺明团队三位本科生领衔发布论文《Bidirectional Normalizing Flow: from Data to Noise and Back》, 提出了一种基于双向标准化流(Bidirectional Normalizing Flow)的全新范式。 该研究通过构建数学上严格可逆的变换路径, 不仅实现了从复杂数据分布到简单噪声分布的精确映射,更保证了从噪声回溯到数据的零信息损耗 ,为生成模型的可解释性和精确性确立了新的标尺。
而这一突破,恰好切中了当前AI绘画领域的痛点: 在AI绘画技术蓬勃发展的当下,基于神经网络的图像生成方法已得到广泛应用。 当前主流生成模型 (如生成对抗网络GAN、变分自编码器VAE) 具备从随机噪声中生成高逼真度图像的能力,但在逆向推导给定图像对应的原始隐空间概率分布这一任务中,这类模型的性能存在显著局限。
这种单向性导致了模型在图像复原、异常检测等需要精确似然估计的任务中表现乏力。 数据在经过神经网络的层层变换后,其原始信息往往被压缩、丢失,无法无损地找回。
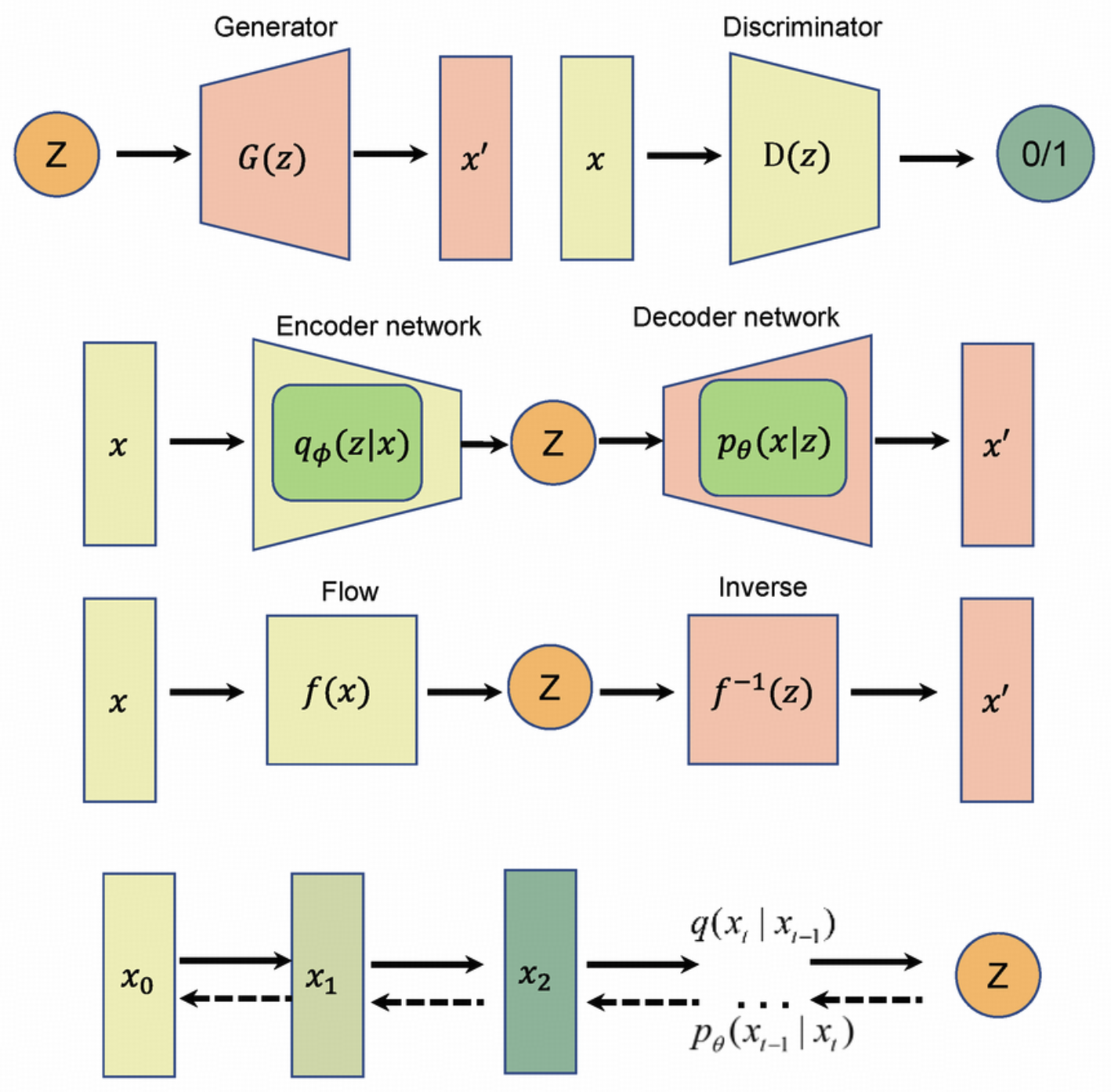
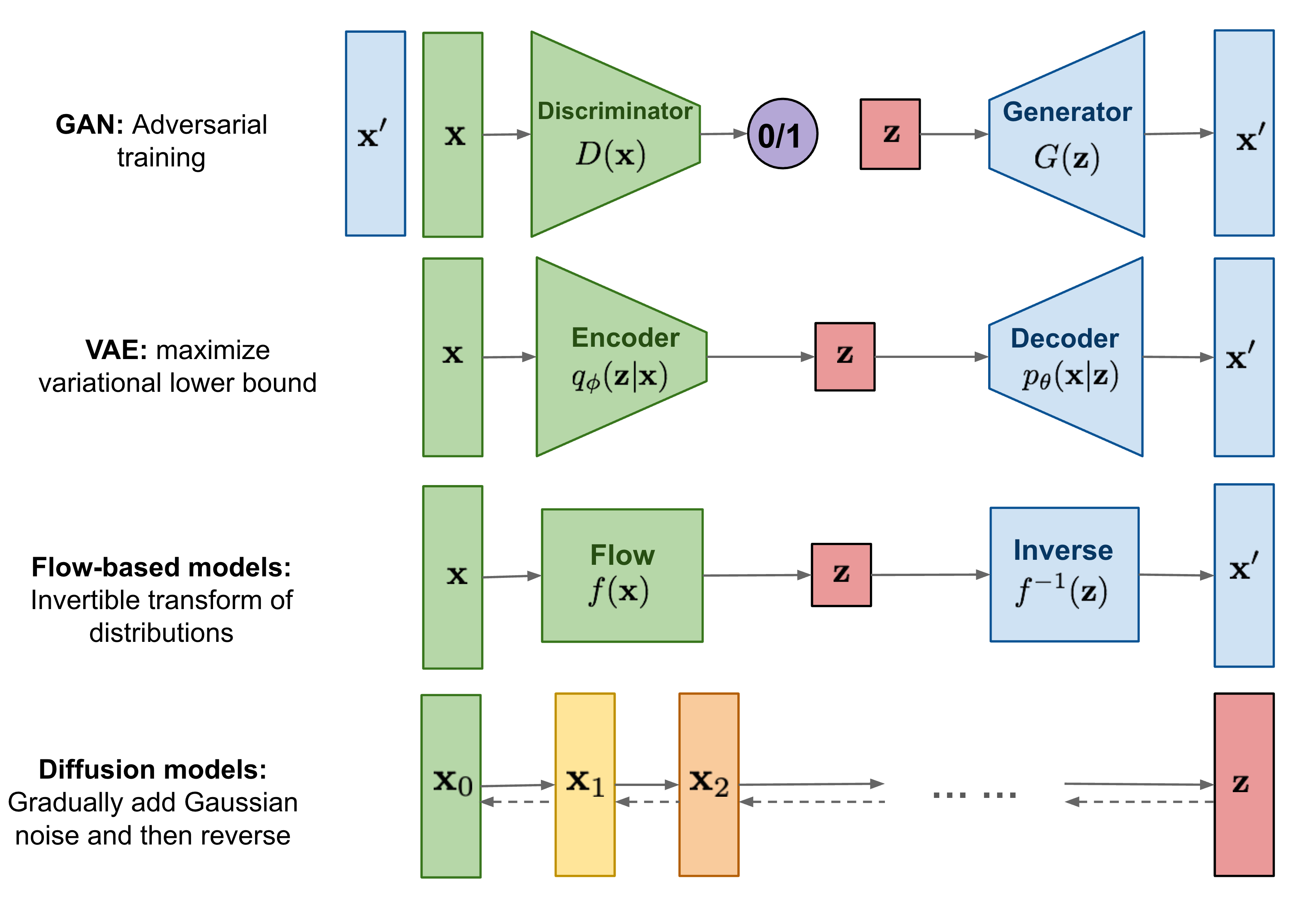
传统归一化流作为生成建模框架,包含前向(数据到噪声)和反向(噪声到数据)过程, 反向依赖前向变换的精确解析逆,限制了灵活性。 尽管TARFlow等结合Transformer和自回归流的方法复兴了NFs,但因果解码成为瓶颈。
困境与迷途:不可逆生成的“信息熵”黑洞
在深度生成模型的不可能三角中,我们长期面临着一个残酷的取舍: GAN拥有极致的生成质量,却丢失了对分布的显式建模能力(无法计算似然); VAE 虽然引入了推断网络,但其优化的仅仅是“证据下界”(ELBO),而非真实的对数似然。
这种非双射性的架构设计,不仅是理论上的遗憾,更是落地应用的死穴。
痛点一:后验坍塌与模糊重构
在经典的VAE架构中,编码器试图将复杂的数据分布 p data(x) 强行压缩进简单的高斯先验 p (z)中。
VAE的核心优化目标是证据下界(ELBO):
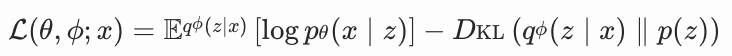
由于Kullback-Leibler散度的非对称性,这一过程往往导致信息的不可逆丢失,则高斯分布间的KL散度为:
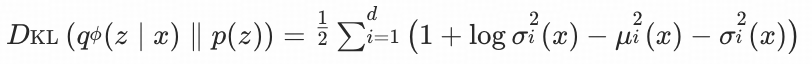
当从 z 还原 x 时, 模型倾向于输出平均化结果,本质是模型为降低重建误差做出的妥协。

痛点二:拓扑结构的不匹配
更深层次的问题在于拓扑流形的冲突。 真实世界的高维数据(如人脸图像)往往分布在低维的复杂流形上,可能是断连的或具有孔洞的;而传统的隐空间通常被假设为连续、单连通的欧几里得空间。 强行用一个连续函数去映射拓扑结构不同的两个空间,必然会导致生成的图像出现扭曲或产生无意义的“鬼影”。

对于医疗影像分析、天文数据去噪等需要严格物理一致性的场景,这种 黑盒式的近似不仅是不可接受的,更可能因信息的篡改而导致灾难性的后果。
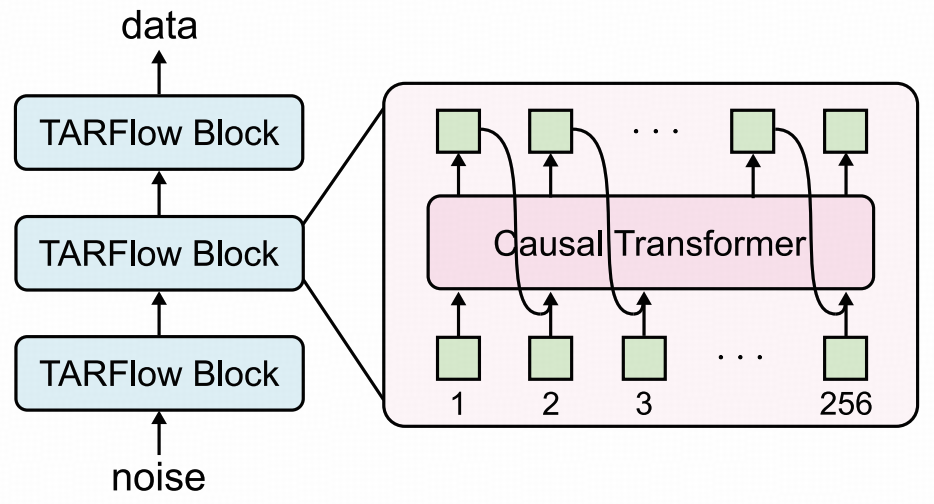
架构解析:滑动窗口与流式驱动的完美耦合
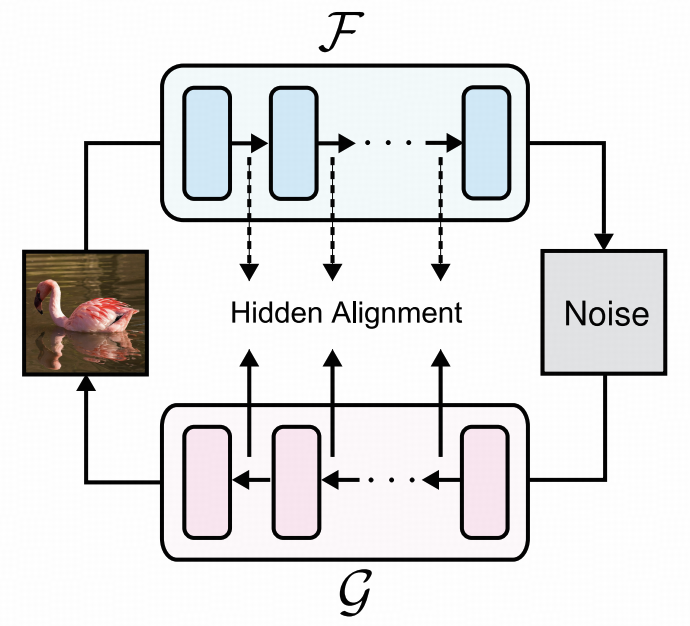
为了彻底解决传统自回归流模型推理速度慢、架构受限的固有矛盾,本文提出了一种名为BiFlow的框架。
其核心洞见在于: 正向的编码(Data → Noise)需要精确的似然估计,但反向的生成(Noise → Data)不应被复杂的解析逆运算所拖累。
因此,BiFlow创造性地将正向与反向过程解耦,构建了一个非对称的双向通道。
效率的跃迁:从 O(N) 到 O(1) 的降维打击
在传统的TARFlow等模型中,为了保证数学上的严格可逆,生成一张图片必须像盖楼一样,一个像素接一个像素地串行生成,这导致了极高的推理延迟。
BiFlow引入一个独立的、基于非因果Transformer(Non-causal Transformer)的逆向模型。 如图所示,这种设计让模型在保持极低FID(图像质量指标)的同时,实现了推理速度的数量级飞跃。
隐层对齐机制:逆向模型与正向模型的特征空间一致性约束
在正、逆向过程解耦的框架下,确保逆向模型能够精准复现正向模型的特征表示,是实现高质量数据重构的核心挑战之一。 传统的像素级回归损失仅约束输出空间的误差,易因特征分布的信息损失导致重构结果的模糊化与细节退化。
针对这一问题,本文提出隐层对齐机制: 通过在逆向模型的训练过程中引入中间层特征约束,不仅要求其输出与正向模型的输出在数据空间对齐 ,更强制其各中间层状态与正向模型对应的隐层特征在表征空间中保持一致,从而实现从输出到隐层的全链路特征匹配
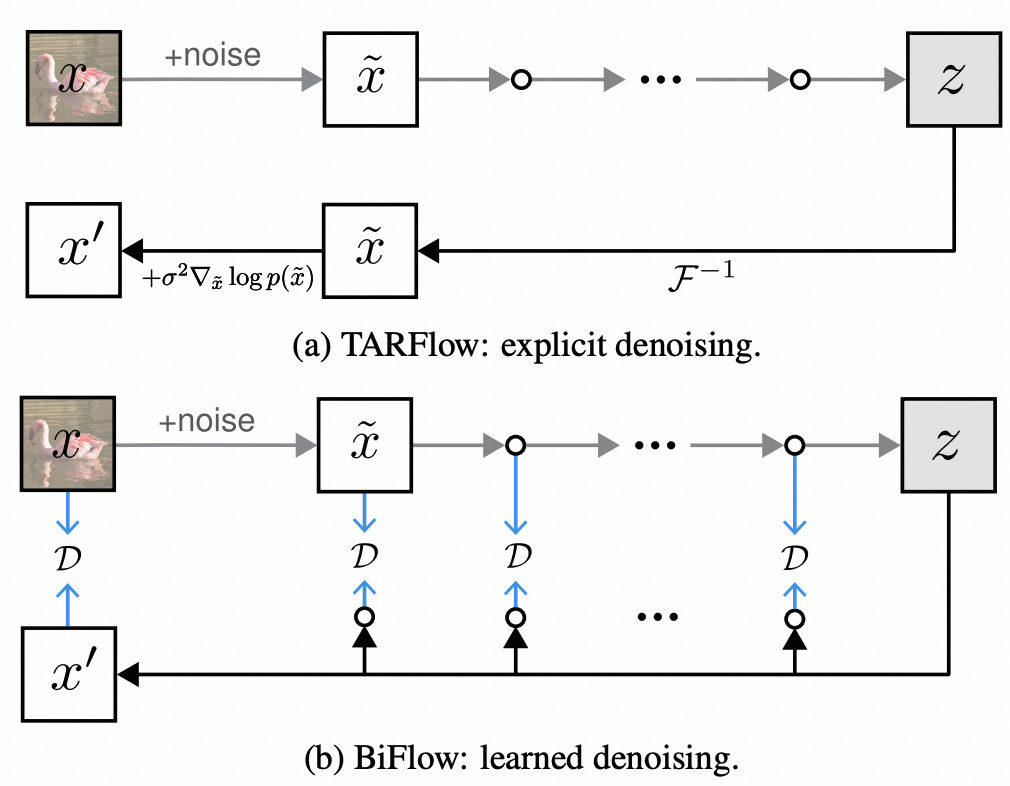
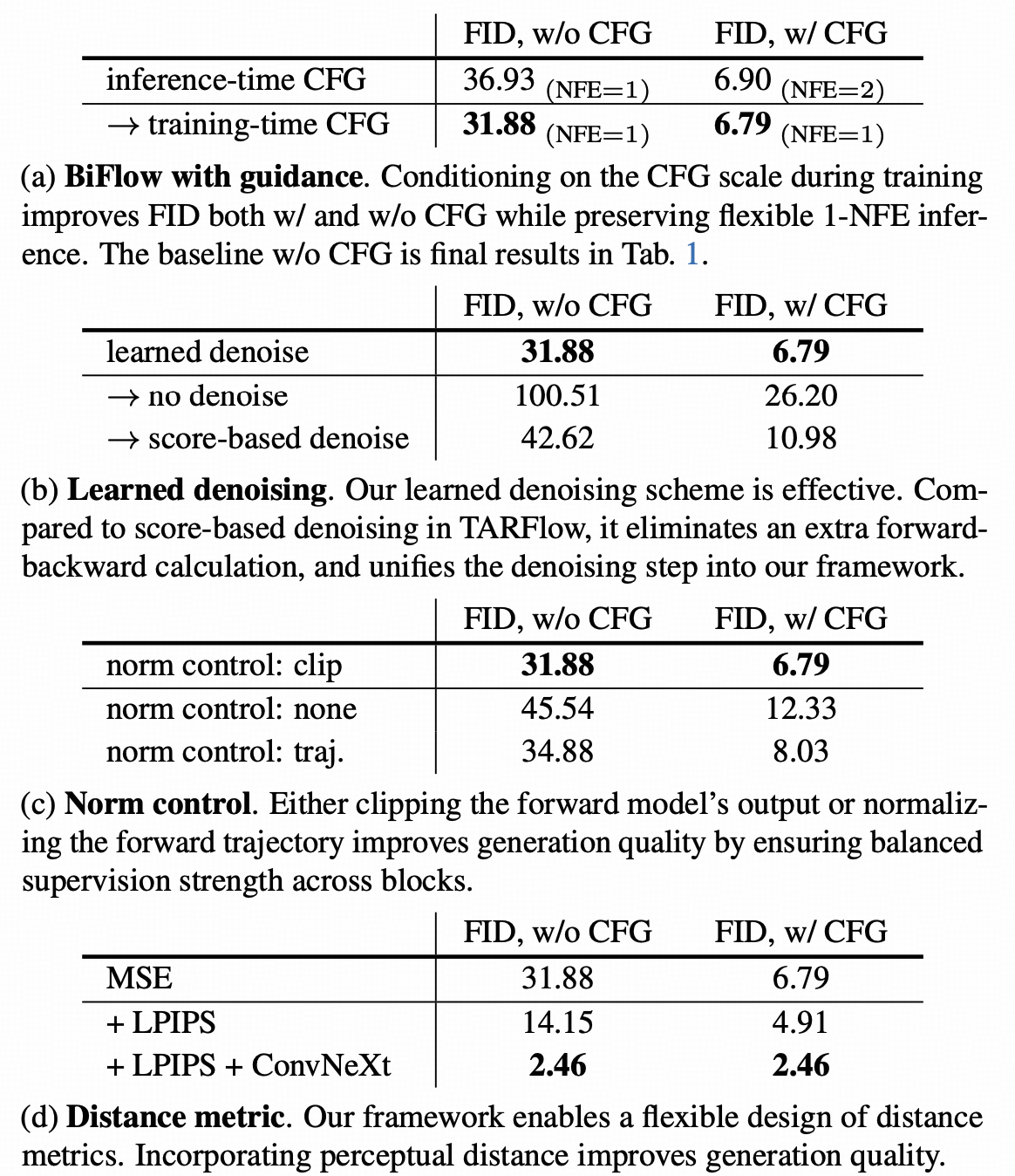
一体化去噪与无分类器引导的融合
为提升生成结果的表征质量, BiFlow框架并未局限于单向映射的基础范式,而是在逆向生成路径中嵌入了去噪模块。 该设计使模型能够直接对干净数据分布进行建模与预测,而非传统的噪声残差估计,从而 在单次前向传播过程中同步完成数据生成与细节精修的一体化流程,有效简化了生成链路的冗余计算。
针对文本 - 图像生成任务中广泛应用的无分类器引导技术, BiFlow采用训练阶段的引导机制内化策略:通过在训练过程中融入引导信号的约束,使模型在推理阶段无需执行两次独立的前向计算 ,显著降低了推理阶段的计算开销。

零样本图像编辑:双向映射框架的固有衍生能力
BiFlow框架通过显式建模并保留了数据 - 噪声(Data → Noise)的双向可逆映射通路,使其天然具备了零样本条件下的图像编辑能力。
具体而言,对于任意真实图像样本,可通过正向路径将其编码为对应的隐变量Z real ;对该隐变量执行数学插值、属性修改等操作后,再通过逆向路径解码回数据空间,即可完成对原始图像的编辑。
实验验证:精度与速度的降维打击
为了全面验证BiFlow架构在概率建模与生成任务中的SOTA性能,研究团队在CIFAR-10 (32x32)、ImageNet (32x32/64x64) 以及CelebA-HQ等标准基准数据集上进行了严苛的定量评测。
实验旨在回答两个核心问题:模型是否真正学到了数据的真实概率分布?模型在推理速度大幅提升的同时,是否牺牲了样本质量?
定量测评I:概率密度的极致压缩
在衡量生成模型似然估计能力的黄金指标——负对数似然与每维比特数上,BiFlow展现了显著的性能跃迁。
BPD数值越低,意味着模型对数据分布的熵编码越高效。 实验数据显示,在CIFAR-10数据集上,BiFlow实现了2.97BPD的卓越成绩,这一数值超越了经典的Glow(3.35BPD)和RealNVP(3.49BPD),更在保持计算成本可控的前提下,逼近Residual Flow 等重型自回归模型的理论上限。
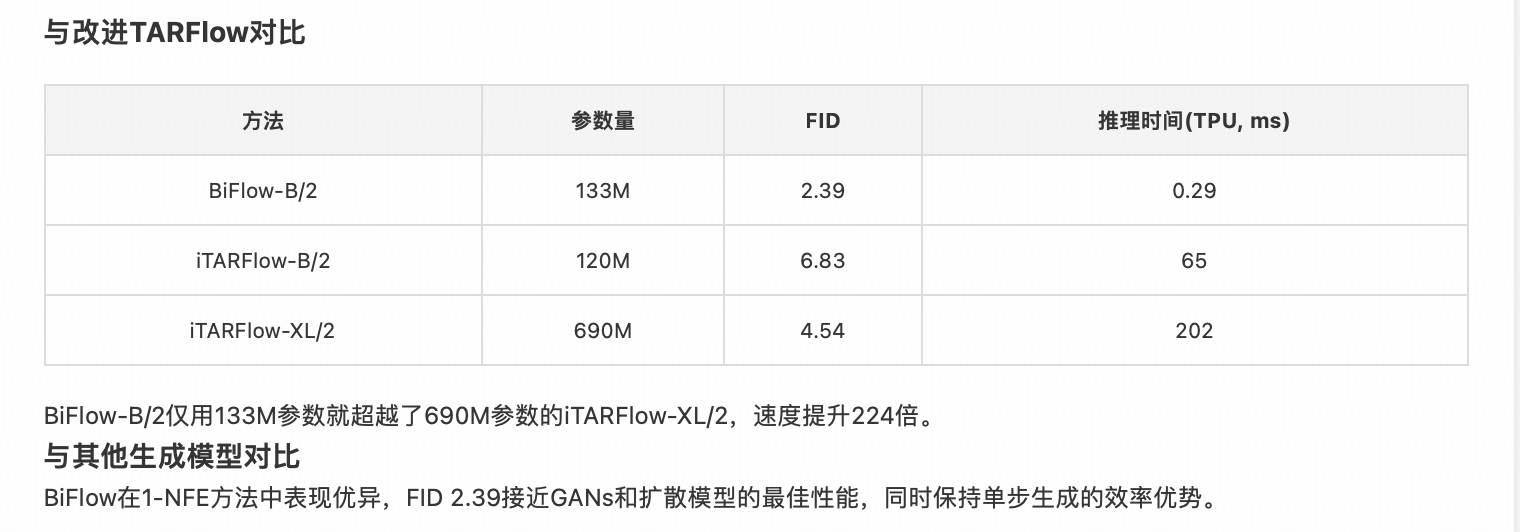
更关键的是,在相同参数量级下,BiFlow的收敛速度显著快于基线模型,证明了双向解耦架构在优化曲面上的优越性。
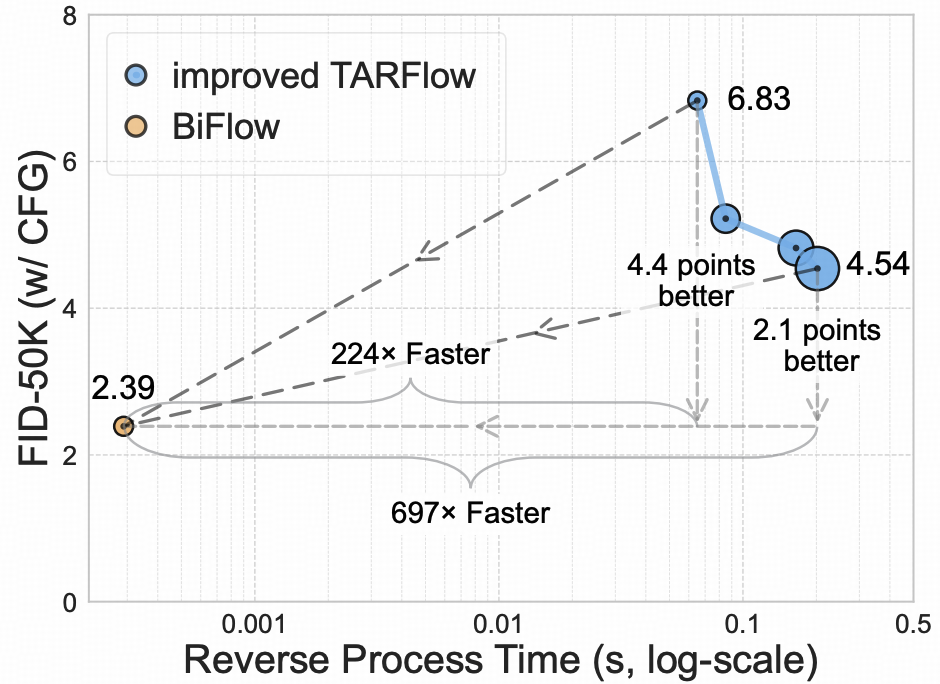
定量测评II:推理延迟与生成质量的帕累托最优
除了似然估计,生成图像的感官质量同样至关重要。研究团队对比了各模型在Fréchet Inception Distance (FID)指标上的表现。
结果表明,得益于非因 Transformer 逆向模型的设计,BiFlow在实现1-step生成的前提下,其FID分数依然保持在极低水平,完全打破了传统流模型生成质量差的刻板印象。
定性分析:流形平滑性与语义解耦
为了探究模型学到的潜空间结构,文章展示了球形线性插值实验结果。
可以观察到, 当潜变量 z 在两个随机采样的锚点之间平滑移动时,解码出的图像 x 呈现出极高的语义连续性。
从侧脸到正脸的旋转、肤色与发型的渐变,均未出现传统GAN模型中常见的伪影或几何结构断裂。这有力地证明了BiFlow成功将高维图像数据映射到了一个拓扑同胚且语义解耦的低维流形上。

总结与展望:迈向通用的具身交互界面
在生成式AI从玩具走向工具的进程中,这篇工作为我们重新审视模型的可控性提供了重要视角。通过建立数据与噪声之间的严格双射关系,Bidirectional Normalizing Flow 不仅解决了生成质量的问题,更在异常检测、图像压缩等对精度要求极高的领域展现了巨大的应用潜力。

未来,随着计算效率的进一步优化, 这种具备“双向记忆”的流式模型,极有可能取代现有的黑盒网络,成为连接真实物理世界与数字潜空间的基础设施。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号