pwn笔记1&2
pwn1&2
[本文章由 AI-ruo 提供]
第一节
一、前置准备工作
1、虚拟机的安装——VMware( 可以参考大佬的博客(https://blog.csdn.net/m0_51545690/article/details/123213579) )
2、Linux操作系统的安装——Ubuntu的安装(可以参考大佬的博客https://blog.csdn.net/weixin_43899764/article/details/106382109)
3、反编译软件的安装——Ida的安装
4、前置知识的积累——C语言、Linux基础
5、知识的积累《汇编语言》(第四版)【王爽 著】
6、刷题网站https://buuoj.cn/
https://adworld.xctf.org.cn/home/index
https://www.ctfer.vip/about/about
二、初识PWN
1、什么是PWN
- 破解、利用成功(程序的二进制漏洞)
- 攻破(设备、服务器)
- 控制(设备、服务器)
2、PWN的攻击手段
exploit:用于攻击的脚本与方案
payload:攻击载荷,是对目标进程被劫持控制流的数据
shellcode:调用攻击目标的shell的代码
3、Linux操作基础
ls : list 的缩写,通过 ls 命令不仅可以查看 Linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。
cd[目录名] : change Directory 的缩写,切换当前目录至[目录名]
cd.. :返回至上一级目录
rm : 删除一个目录中的一个或多个文件或目录
clear :用于清除屏幕
checksec : 检查可执行文件属性 *这是一个shell脚本
4、Ida基础
1、左侧为信函数框
2、右侧为信息框(伪代码框)
*伪代码:由别的语言反编译过来生成的代码而非能够运行的代码(不能运行但能大概表示含义)
3、shift+f12打开字符串页面
4、ctrl+x查找引用了当下所指的目标的函数
5、打pwn题的流程
1、下载题目
2、反编译
3、编写攻击脚本
4、夺取控制权
5、获取flag
三、二进制基础
1、语言的编译与链接
(0)语言分成两种:编译型语言和解释型语言
*编译型语言的共同特点:都需要经历一系列流程最后生成一个可执行文件
(1)从C源代码到可执行文件的生成过程
+ 编译:由C语言代码生成汇编代码
+ 汇编:由汇编代码生成机器码
+ 链接:将多个机器码的目标文件链接成一个可执行文件
2、 Linux下的可执行文件格式ELF
(1)可执行文件
-
什么是可执行文件
- 广义:文件中的数据是 $\textcolor{Orange}{ 可执行代码 } $ 的文件
.out、.exe、.sh、.py - 狭义:文件中的数据是 $\textcolor{red}{ 机器码 } $ 的文件
.out、.exe、.dll、.so
- 广义:文件中的数据是 $\textcolor{Orange}{ 可执行代码 } $ 的文件
-
可执行文件的分类
-
Windows:PE(Portable Executable)
可执行程序 .exe
动态链接库 .dll
静态链接库 .lib
-
Linux:$\textcolor{red}{ELF} $ (Executable and Linkable Format)
可执行程序 .out
动态链接库 .so
静态链接库 .a
-
(2)ELF文件结构
-
ELF文件头表(ELF header)
- 记录了ELF文件的组织结构
-
程序头表/段表(Program header table)
- 告诉系统如何创建进程
- 生成进程的可执行文件必须拥有此结构
- 重定位文件不一定需要
-
节头表(Section header table)
-
记录了ELF文件的节区信息
-
用于链接的目标文件必须拥有此结构
-
其它类型目标文件不一定需要
-
(3)磁盘与内存中的ELF
-
磁盘中的ELF(可执行文件)
-
Linking View
-
ELF Header Program Header Table option :$\textcolor{red}{Section 1} $ …… :$\textcolor{red}{Section n} $ …… …… Section Header Table
-
-
内存中的ELF(进程内存映像)
-
Execution View
-
ELF Header Program Header Table option :$\textcolor{red}{Segment 1} $ …… :$\textcolor{red}{Segment n} $ …… …… Section Header Table
-
注意:磁盘中为section(节)变成了内存中为 Segment(段)
- section(节)是segment(段)的子集
- 【段包括节 节属于段】【很多个节结合在一起组成了段】
- 拥有相同权限的节会被组合成段【权限类型(三种):可读、可写、可执行】
- 目的:方便管理
3、进程虚拟地址空间
(1)什么是虚拟内存
- 物理内存只有一份 但虚拟内存可以有很多份且大小与物理内存相等
- 虚拟内存 用户空间 每个进程一份
- 虚拟内存 内核空间 所有进程共享一份(用户所编写的代码是影响不到系统底层)(但是用户代码可以调用内核代码)
- 虚拟内存 mmap 段中的动态链接库仅在物理内存中装载一份
- $\textcolor{red}{stack} $ 栈 [栈溢出——最常见的漏洞]
- $\textcolor{red}{heap} $ 堆
(2)段与节
-
代码段(Text segment)包含了代码与只读数据
$\textcolor{red}{.text} $ 节[用于存放一些其他数据]
.rodata 节
.hash 节
.dynsym 节
.dynstr 节
$\textcolor{red}{.plt} $ 节
.rel.got 节
…… -
数据段(Data segment)包含了可读可写数据
.data 节 [存放一些已初始化的全局变量]
.dynamic 节
.got 节
$\textcolor{red}{.got.plt} $ 节
$\textcolor{red}{.bss} $ 节 [缓冲区 用于存放一些未初始化的全局变量]
…… -
栈段(Stack segment)
- 用来存放我们函数调用的一些东西
[注意]
- 一个 段 包含多个 节
- 段视图用于进程的内存区域的 rwx权限划分
- 节视图用于ELF文件 编译链接时 与 在磁盘上存储时 的文件结构的组织
3、程序的编译与链接
(1)大端序与小端序
- 小端序 [我们所主要关注的格式]
- 低地址存放数据低位、高地址存放数据高位
- 大端序 [基本用不上]
- 低地址存放数据高位、高地址存放数据低位
4、程序的装载与进程的执行
(1)进程的执行过程
- CPU发出一个命令通过地址总线传输给内存内存再通过数据总线将数据传输给cpu
[重要] 什么是栈
栈是一种数据与结构
特点:后进先出【最重要的工作方式】
第二节
三、二进制基础[续]
4、程序的装载与进程的执行[续]
(2)寄存器$\textcolor{red}{[重要!]} $
·什么是寄存器
- 寄存器是CPU中进行信息存储的部件
- 特点:容量小 速度快(以字节为单位)
·部分寄存器的功能
- RIP[64位]/EIP[32位]:存放当前执行的指令的地址
- RSP[64位]/ESP[32位]:存放当前栈帧的栈顶地址
- RBP[64位]/EBP[32位]:存放当前栈帧的栈底地址
- RAX[64位]/EAX [32位]:通用寄存器。存放函数返回值
(3)链接的执行过程
·静态链接的执行过程
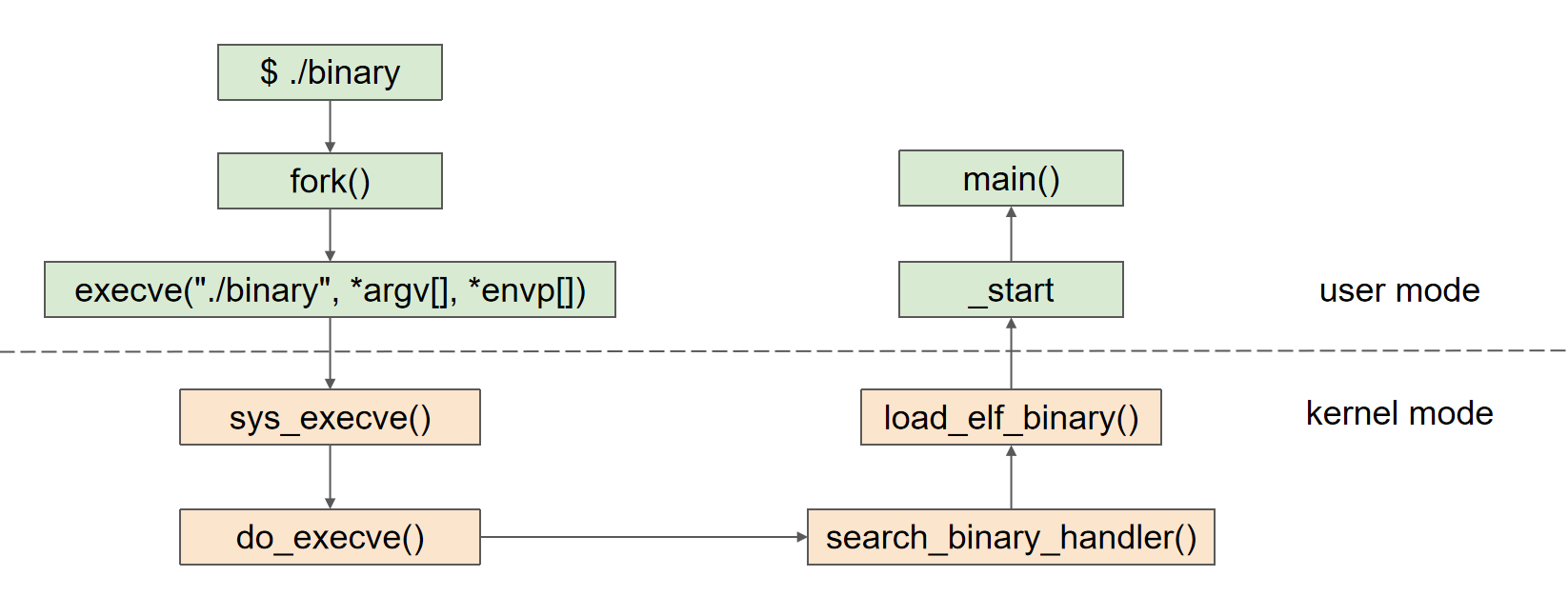
-
fork() 预加载函数
-
execve("./binary", *argv[], *envp[]) 系统函数的外包装函数
- 目的:实现由user mode到kernel mode的转变
- 功能:执行下面的系统函数
-
sys_() 系统调用函数
[静态链接会把所有的库都载入]
·动态链接的执行过程
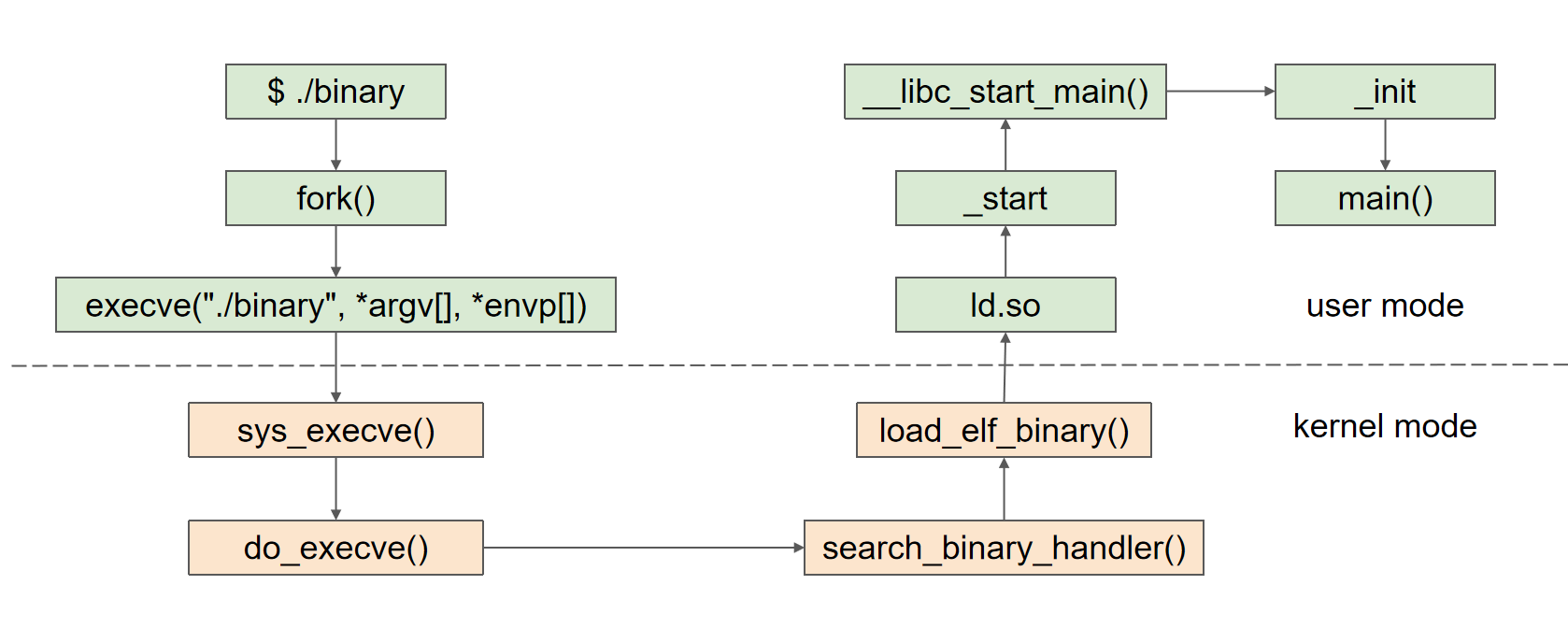
- ld.so 链接文件
- _init 初始化函数
5、x86&amd64汇编简述
(1)常用汇编指令
·MOV
MOV DEST, SRC ; 把源操作数传送给目标
eg:MOV EAX,1234H ; 执行结果(EAX) = 1234H [将一个值传给一个寄存器]
MOV EBX, EAX 执行结果EAX里的值被放在EBX里[将寄存器里的值传给另一个寄存器]
MOV EAX, [00404011H] ; [ ] 表示取地址内的值 [将地址上的值放到寄存器里]
MOV EAX, [ESI]
·LEA
LEA REG, SRC ; 把源操作数的有效地址送给指定的寄存器
e.g:LEA EBX, ASC ; 取 ASC 的地址存放至 EBX 寄存器中
LEA EAX, 6[ESI] ; 把 ESI+6 单元的32位地址送给 EAX
·PUSH (入栈) $\textcolor{red}{[重要!]} $
PUSH VALUE ; 把目标值压栈,同时SP指针-1字长
e.g:PUSH 1234H
PUSH EAX
·POP (出栈) $\textcolor{red}{[重要!]} $
POP DEST ; 将栈顶的值弹出至目的存储位置,同时SP指针+1字长
e.g:POP EAX
·LEAVE
在函数返回时,恢复父函数栈帧的指令
等效于:
MOV ESP, EBP
POP EBP
·RET
在函数返回时,控制程序执行流返回父函数的指令
等效于:
POP RIP(这条指令实际是不存在的,不能直接向RIP寄存器传送数据)
(2)两种汇编格式
- 分别是 intel 和 AT&T
- intel无符号 而AT&T 有$符号(加载立即操作数前) 和 %符号(加在寄存器前)
- intel将后面的数据传到前面 AT&T将前面的数据传到后面
四、栈溢出基础
1、C语言函数调用栈
(1)什么是函数调用栈
-
函数调用栈是指程序运行时内存一段连续的区域用来保存函数运行时的状态信息,包括函数参数与局部变量等
程序运行时会有一段虚拟内存,在虚拟内存里会开辟一个空间被称为栈(stack)
- 每调用一个函数就会开辟一个栈帧
- 一片一片的栈帧连在一起构成了栈
- 栈帧是栈的子集
- 栈帧的大小取决于调用的函数的内容和我们对他的操作
-
称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶
- 栈顶会随着我们压入的函数不断地往低地址动
- 栈底一般是不会动的 知道我们开了一个新的栈帧 我们的栈底会到下一个函数那里
- sp(栈顶)和bp(栈底)这两个寄存器就决定了一个栈帧的位置
- sp和bp中间就是目前我们在调用的函数的栈帧
-
在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态
-
函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大
(2)栈的工作原理
·函数状态涉及的三个寄存器
- ESP:用来存储函数调用栈的栈顶地址,在压栈(PUSH)和退栈(POP)时发生变化
- EBP:用来存储当前函数状态的基地址(即栈底地址),在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。
- EIP:用来存储即将执行的程序指令的地址,cpu 依照 eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
·函数调用时寄存器的变化
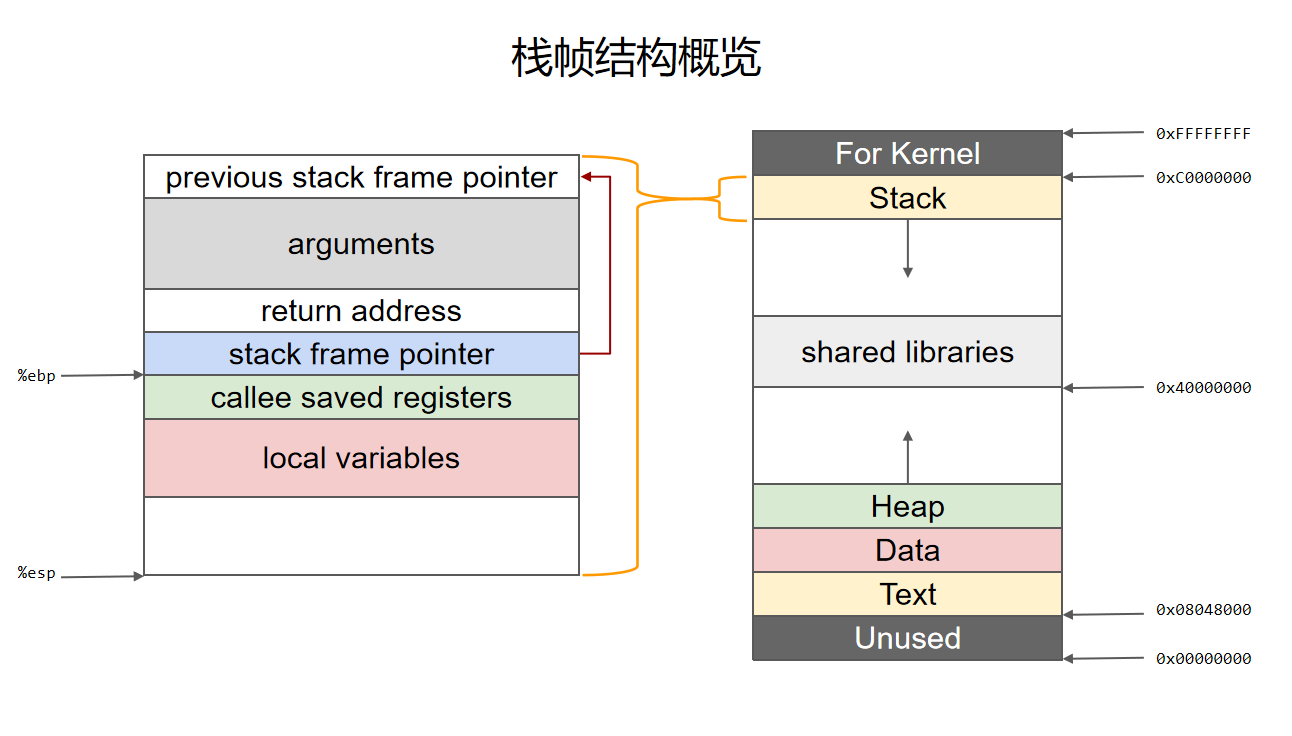
变化的核心任务是将调用函数(caller)的状态保存起来,同时创建被调用函数(callee)的状态。
-
首先将被调用函数(callee)的参数按照逆序依次压入栈内。如果被调用函数(callee)不需要参数,则没有这一步骤。这些参数仍会保存在调用函数(caller)的函数状态内,之后压入栈内的数据都会作为被调用函数(callee)的函数状态来保存。
-
然后将调用函数(caller)进行调用之后的下一条指令地址作为返回地址(return address)压入栈内。这样调用函数(caller)的 eip(指令)信息得以保存。
- 在压栈的过程中,esp 寄存器的值不断减小(对应于栈从内存高地址向低地址生长)。压入栈内的数据包括调用参数、返回地址、调用函数的基地址,以及局部变量,其中调用参数以外的数据共同构成了被调用函数(callee)的状态。在发生调用时,程序还会将被调用函数(callee)的指令地址存到 eip 寄存器内,这样程序就可以依次执行被调用函数的指令了。
return address保存了调用函数的下一条指令
子函数调用完后需要回到父函数来 我们需要一个地址来帮我们重新定位到父函数来 我们就把他下一条指令的地址给存起来变成return address
-
再将当前的ebp 寄存器的值(也就是调用函数的基地址)压入栈内,并将 ebp 寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的 ebp(基地址)信息得以保存。同时,ebp 被更新为被调用函数(callee)的基地址。[MOV EBP ESP]
将调用函数的基地址(ebp)压入栈内,并将当前栈顶地址传到 ebp 寄存器内
-
再之后是将被调用函数(callee)的局部变量等数据压入栈内。
-
函数调用结束时丢弃被调用函数(callee)的状态,并将栈顶恢复为调用函数(caller)的状态。[MOV ESP EBP]
- 首先被调用函数的局部变量会从栈内直接弹出,栈顶会指向被调用函数(callee)的基地址。
- 然后将基地址内存储的调用函数(caller)的基地址从栈内弹出,并存到 ebp 寄存器内。这样调用函数(caller)的 ebp(基地址)信息得以恢复。此时栈顶会指向返回地址。 [POP EBP](此时ESO回到return address上)
- 再将返回地址从栈内弹出,并存到 eip 寄存器内。这样调用函数(caller)的 eip(指令)信息得以恢复
- 至此调用函数(caller)的函数状态就全部恢复了,之后就是继续执行调用函数的指令了。 [POP EIP]
当callee函数执行完后无需将其中内容删除而是改变寄存器的位置继续运行(删除会占用大量的系统资源)
- x86
使用栈来传递参数
使用 eax 存放返回值- amd64
前6个参数依次存放于 rdi、rsi、rdx、rcx、r8、r9 寄存器中
第7个以后的参数存放于栈中
2、ret2text
(1)引子
·攻击手段
-
我们首先要理解 程序是怎么工作的 研究透彻工作机制是怎么样的
-
然后我们可以在他工作机制里面找到一些可以利用的地方 找到一些小小的问题
-
再利用这些小小的问题完成我们的攻击
(2)缓冲区溢出(Buffer overflow)
本质是向定长的缓冲区中写入了超长的数据,造成超出的数据覆写了合法内存区域
·栈溢出(Stack overflow) $\textcolor{red}{[重要]} $
最常见、漏洞比例最高、危害最大的二进制漏洞
在 CTF PWN 中往往是漏洞利用的基础
·堆溢出(Heap overflow)
堆管理器复杂,利用花样繁多
CTF PWN 中的常见题型
·Data段溢出
攻击效果依赖于 Data段 上存放了何种控制数据
(3)ret2text详细步骤
- 数据会存放在local variables里 数据的读入也会读入到local variables里 但是我们读入一旦超过了我们所能存放的限制 那就不会停下来而会不断往上走 会把EBP的值改掉 会把Return Address的值改掉 将returnaddress改成我们恶意代码的地址就完成了一次攻击[篡改栈帧上的返回地址为程序中已有的后门函数]
- 控制程序执行指令最关键的寄存器是 eip[return address上存的是EIP的值 EIP的值可以让我们定位到原来程序的下一条指令]
- 我们的目标是让 eip 载入攻击指令的地址。
- 准备
- 首先,在退栈过程中,返回地址会被传给 eip,所以我们只需要让溢出数据用攻击指令的地址来覆盖返回地址就可以了。
- 其次,我们可以在溢出数据内包含一段攻击指令,也可以在内存其他位置寻找可用的攻击指令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号