Dynamic Graph CNN for Learning on Point Clouds
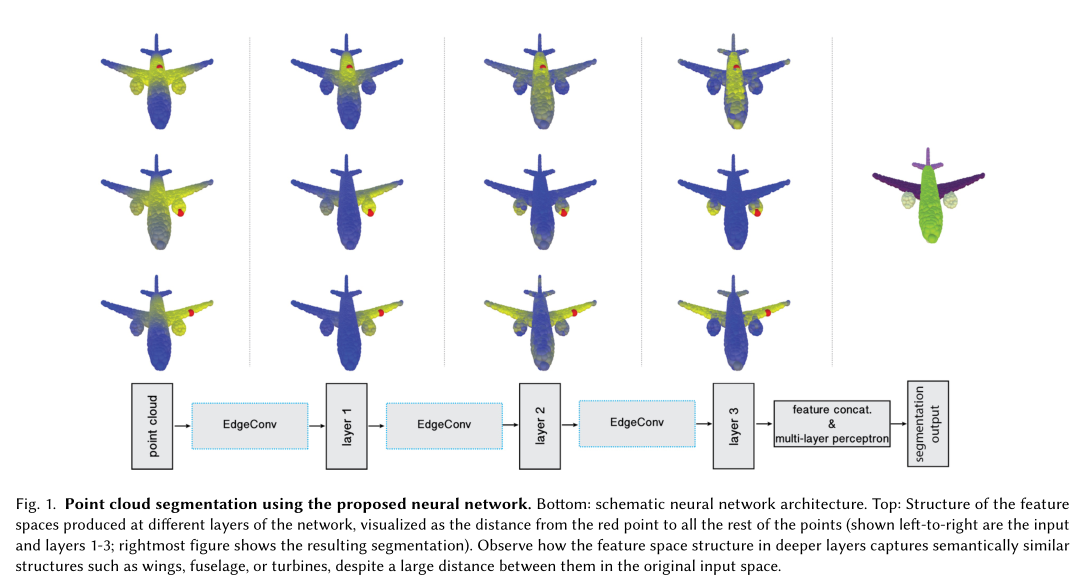
图为使用提出的神经网络对点云进行分割的结果。底部为神经网络架构示意图。顶部为在网络的不同层上生成的特征空间的结构,红点到其他所有点的空间距离可视化(从左到右是输入和第1-3层的结果);最右边的图显示了分割的结果。尽管他们在原始输入空间上由很长的距离,我们可以观察到深层的特征空间结构如何捕获相似的语义信息,例如机翼、机身和涡轮机。点云本身是缺乏拓扑信息的,因此设计一个可以恢复利用拓扑信息的模型可以极大的丰富点云的表达能力。为此,我们提出一种新的神经网络模块EdgeConv适用于基于CNN的高维任务在点云的分类和分割任务上。这个网络可以嵌入到现有的各种网络当中。和目前在点云的外部进行处理(体素化)与对每个点进行处理(PointNet)相比,\(\color{red}{EdgeConv\ 有以下几个吸引人的特性}\):
- 它结合了局部邻域信息。
- 它可以学习全局形状属性。
- 在多层叠加之后,它可以在特征空间上捕捉到潜在的长距离的语义特征。
Introduction
PointNet的方法实现了针对每个点进行独立操作,然后使用对称函数来实现置换不变性。关于PointNet的扩展补充也只是考虑了点的邻域信息而不是单独作用域每个点,以此去利用网络的局部特征去提升模型的表现,这些技术主要在局部尺度上独立处理点,以保持置换不变性。然后这种独立性忽略了点和点之间的几何关系,这带来了无法捕获局部特征的基本限制。\(\color{red}{这里不知道怎么去理解}\)
我的理解是原先的
PointNet没有考虑到局部特征,之后的补充方案例如PointNet++考虑了这个缺点并补上了局部特征这个东西。
文中讲,这种独立的处理忽略了点与点之间的关系,导致缺少利用点云的拓扑信息。
这里提出的方案很好的利用了点云的拓扑信息。
为了解决这个问题,此处提出了一种新的操作,称为EdgeConv,他在保持置换不变性的同时很好的捕获了局部集合结构。EdgeConv并不会直接在它嵌入的地方生成点的特征,而是生成描述点与其相邻点之间关系的边特征。
本文将EdgeConv直接嵌入到PointNet上,进行展示,可以发现其获得了巨大的性能提升。
主要贡献:
- 提出
EdgeConv,以更好地捕获点云局部集合特征,并保持置换不变性。 - 我们在下面展示了我们的模型可以通过在层与层之间动态的更新关系图来学习对点进行语义分组。
- 我们演示了
EdgeConv可以集成到多个现有的Pipline中进行点云处理。 - 我们对
EdgeConv进行了广泛的分析和测试,并表明他在基准数据集上实现了最佳性能。 - 这东西有源码。
相关工作
手工设计特征:集合数据处理和分析中的各种任务,包括分割、分类和匹配,都需要一些形状之间局部相似性的概念。传统上,这种相似性是通过构造捕获局部集合结构的特征描述符去建立起来的。
我们的方法
我们提出了一种受PointNet和convolution启发的方法。然而并不像PointNet那样单独处理每个点,而是以图神经网络的精神,通过构造局部邻域图并在相邻点对的边上应用卷积式运算来利用局部集合结构。不像图CNNs那样,我们的图不是固定的,而是在网络的每一层之后动态更新。我们在下面展示了这样一种被称为边缘卷积(EdgeConv)的操作,其性质介于平移不变性和非局部性之间。
和图CNN不一样的是,我们的图不是固定的,而是在网络的每一层之后动态更新。也就是说,点的k近邻集在网络的层与层之间变化,并根据嵌入序列计算。
边缘卷积
我们用\(X=\{\mathbf{x}_1\dots \mathbf{x}_n\} \subseteq \mathbb{R}^F\),在一般情况下\(F=3\),每个点有三个维度\(\mathbf{x}_i=(x_i,y_i,z_i)\)。在深度神经网络的结构中,每个后续的层对前面层的输出进行操作,因此更一般的讲,位数F代表给定层的维度。
我们计算一个表示局部点云结构的有向图\(\mathcal{G}=(\mathcal{V},\mathcal{E})\),其中\(\mathcal{V}=\{1,\dots,n\}\)和\(\mathcal{E}\subseteq \mathcal{V}\times\mathcal{V}\)分别是顶点和边。在最简单的情况下,我们在\(\mathbb{R}^F\)构造\(\mathcal{G}\)为\(X\)的knn。该图也包括自循环,这意味着每个节点也指向它自身,我们把边特征定义为\(e_{ij}=h_\Theta(\mathbf{x}_i,\mathbf{x}_j)\),其中\(h_\Theta:\mathbb{R}^F\times\mathbb{R}^F\rightarrow\mathbb{R}^{F'}\)是一个包含可学习参数\(\Theta\)的非线性函数。
\(h_\theta\)是一个包含可学习参数的非线性函数,用于提取两个点之间的拓扑关系的神经网络。
\(\square\)是一个聚合函数,用于聚合以\(\mathbf{x}_i\)为中心的\(k\)个点的拓扑关系特征集合。类似
PointNet的Pooling。
最后,我们通过对每个顶点发出的所有便相关联的边特征应用通道对称聚合操作\(\square(eg.,\sum\ or\ max)\)来定义EdgeConv操作。因此第\(i\)个顶点的EdgeConv输出由以下公式给出:
和图像上的卷积相似,我们将\(\mathbf{x}_i\)视为中心像素,\(\{\mathbf{x}_j:(i,j)\in\mathcal{E}\}\)包围在它附近。总的来讲,就是给定一个具有\(n\)个点的\(F\)维点云,EdgeConv生成一个具有相同点数目的\(F'\)维点云。
Edge函数和聚合操作的选择对于EdgeConv的性能具有至关重要的影响。例如当\(\mathbf{x}_1,\dots,\mathbf{x}_n\)表示规则网格上的图像像素,图\(\mathcal{G}\)表示每个像素周围固定大小的面片的连接性,选择\(\theta_m \cdot\mathbf{x}_j\)作为Edge函数,选择sum作为聚合函数操作产生标准卷积。
这里,\(\Theta=(\theta_1\dots,\theta_M)\)对\(M\)个不同滤波器的权重进行编码,每个\(\theta_m\)和\(x\)具有相同的维数,\(\cdot\)代表欧几里德内积。
第一种选择也没说啥东西,就输了\(\sum\)作为聚合函数,\(\theta_m\cdot\mathbf{x}_j\)作为边特征提取函数。也没说具体是个啥东西。
\(h\)的第二个选择是:
PointNet的操作是只编码全局形状信息,而不考虑局部邻域结构,因此可以将其视为EdgeConv的特例。
第二个就是啥都不管,直接退化成
PointNet,用同样的操作去做。也可以说PointNet是本文的一个特例。
第三种选择\(h\)是:
和
其中\(g\)是高斯核,\(u\)用来计算欧几里得空间内成对点的距离。
第三种选择就是
Atzmon\ et\ al等人的一篇工作中的方法。
第四种选择是:
这只编码了局部信息结构,将形状视为small patch的集合,但这样会失去全局结构。
第四种选择,只能获取局部信息结构,会丢失全局结构信息。
最后,本文采用的是第五种选择-非对称边函数
这明显的结合了由\(\mathbf{x}_j\)为中心的patch的全局性状结构和由\(\mathbf{x}_j-\mathbf{x}_i\)捕获的局部邻域信息,我们通过以下标志来定义运算符。
最终选择,不多说了。
第\(m\)层关于\(i,j\)的边特征,是在\(\theta_m\)的参数下计算\(\mathbf{x}_j-\mathbf{x}_i\),在加上对中心点\(\mathbf{x}_i\)的编码的
ReLU函数。
然后通过共享参数的神经网络,和一个聚合函数,得到最终关于\(\mathbf{x}_i\)的特征值。
它可以通过共享参数的MLP实现,
其中\(\Theta=(\theta_1\dots,\theta_M,\phi_1,\dots,\phi_M)\)
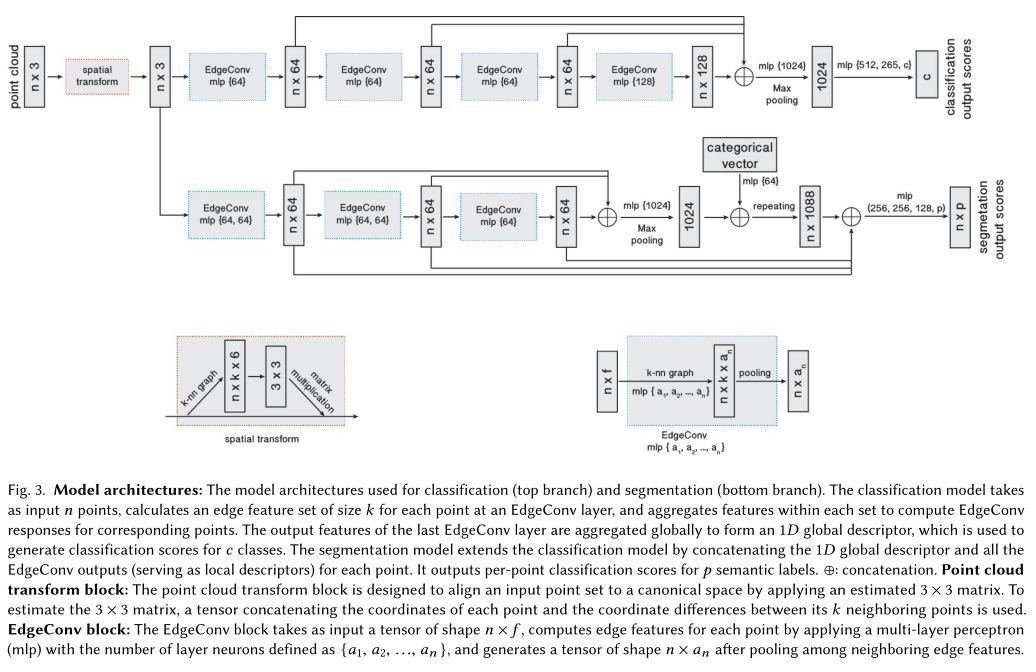
图3. 模型结构示意图:上半部分用于分类,下半部分用于分割。分类模型输入\(n\)个点其维度为\(f\),为EdgeConv上的每个点计算大小为\(k\)的边缘特征集合,并聚合每个集合内的特征以计算对应点的EdgeConv特征。最后一个EdgeConv层的输出特征被全局聚合,形成一个1D全局描述符,用于生成c类的分类分数。
STN:为了计算出\(3\times 3\)的矩阵,我们将\(n\)个点找出其距离的\(k\)个点,拼一个\(n\times k\times 6\)的矩阵,然后去学习\(3\times 3\)的矩阵。
EdgeConv 块:EdgeConv块的输入是一个\(n\times f\)的向量,通过多层感知机去计算每个点的边缘特征,多层感知机的神经元数量定义为\(\{a_1,a_2,\dots,a_n\}\),并在汇聚边缘特征值和生成\(n\times a_n\)的形状的张量。
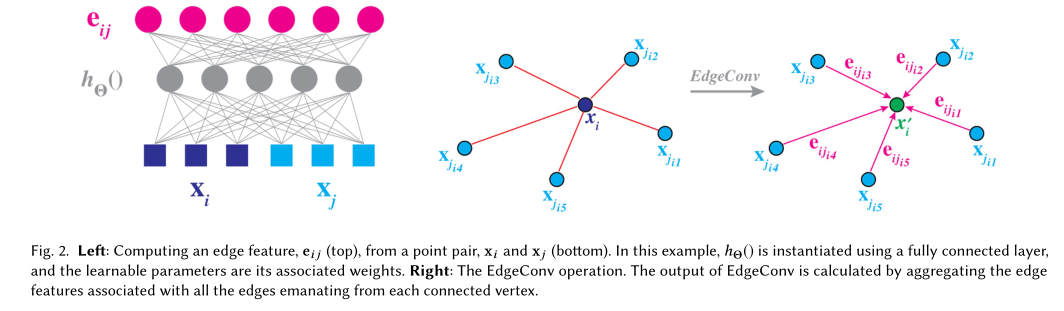
图:计算边特征,从一堆\(\mathbf{x}_i\)和\(\mathbf{x}_j\)。举个例子:假设这里的\(h_\Theta()\)是一个fully connected layer,
动态更新图
实验表明,每次都重新计算上一层输出的点在特征空间中的最近邻点的效果是最好的,这也是动态图CNN与普通图CNN的不同之处。因此,作者将这样的网络称为\(Dynamic\ Grapg\ CNN\),而且\(\color{red}{通过动态图的方法,其感受野会和点云直径一般大小。}\)
这样的话我们在每一层都可以获取到不同的图\(\mathcal{G}^{(l)}=(\mathcal{V}^{(l)},\mathcal{E}^{(l)})\),第\(l\)层的边来自于\((i,j_{i1}),\dots,(i,j_{ik_l})\)(总计\(k\)条边在\(l\)层,\(i\)表示第\(i\)个点,所以前面用\(k_l\)表示)。\(\mathbf{x}^{(l)}_{j_{i1}},\dots,\mathbf{x}^{(l)}_{j_{ik_{l}}}\)是距离\(\mathbf{x}_i^{(l)}\)最近的\(k_l\)。换言之,我们的结构学习如何构造每一层中使用的图形,而不是将其作为在评估网络之前构造的固定常量。在我们的实现中,我们在特征空间中计算两两距离矩阵,然后为每个点取最近的k个点。
不变性
置换不变性。观察下面层的输出
和一个置换算子\(\pi\)。层的输出\(\mathbf{x}'_i\)对于输入\(\mathbf{x}_j\)是置换不变的,因为max是一个对称函数。聚合点特征的全局最大池化算子也是置换不变的。
平移不变性。我们的操作符具有部分平移不变性,因为我们选择的Edge function7:\(h_\Theta(\mathbf{x}_i,\mathbf{x}_j)=\bar{h}_\Theta(\mathbf{x}_i,\mathbf{x}_j-\mathbf{x}_i)\),具有平移不变性,它利用的是相互点之间的拓扑集合信息。下面举例一个适用于\(\mathbf{x}_i\)和\(\mathbf{x}_j\)的平移不变性。我们可以证明,当移动\(T\)的时候,部分的Edge feature是被保留下来的。具体来说,对于平移之后的点云,我们有
如果我们取\(\phi_m=0\)去考虑\(\mathbf{x}_j-\mathbf{x}_i\)则我们的运算是对平移保持完全不变的。然而在这种情况下,我们的运算则退化成了上面的第四种方法。此处使用的第五种方案,既可以保留全局形状信息也考虑了局部集合结构,但是会损失部分平移不变性。
和已有方法对比

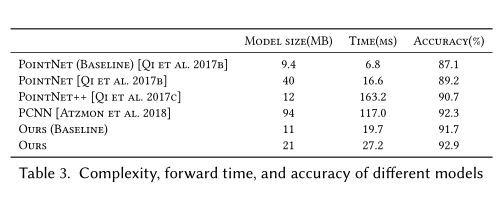
DGCNN和PointNet与graph CNNs相关。我们在表格1,展示了一些特定的参数设置。
PointNet是我们方法的一个特例,即\(k=1\)生成一个边集为空不带其他点一起玩的一个空的图\(\mathcal{E}=\emptyset\)。在PointNet模式下我们使用的方法是上述第二种方案,因为最近的聚合操作,所以它考虑了全局特征,没有考虑局部集合特征。PointNet++试图在使用一个个Patch上使用PointNet然后获取到局部信息。PointNet++首先根据点之间的欧氏距离构造图,并在每一层应用一个图粗化操作。对于每一层,使用最远点采样,在这一层之后,只有选中的点被保留。这样每一层操作之后,图会变得更小。相对于DGCNN其图在训练的时候是固定不变的,也就导致DGCNN的优点它并没有。PointNet++的边缘特征函数也是\(h_\Theta(\mathbf{x}_i,\mathbf{x}_j)=h_\Theta(\mathbf{x}_i)\),聚合函数是MaxPooling。
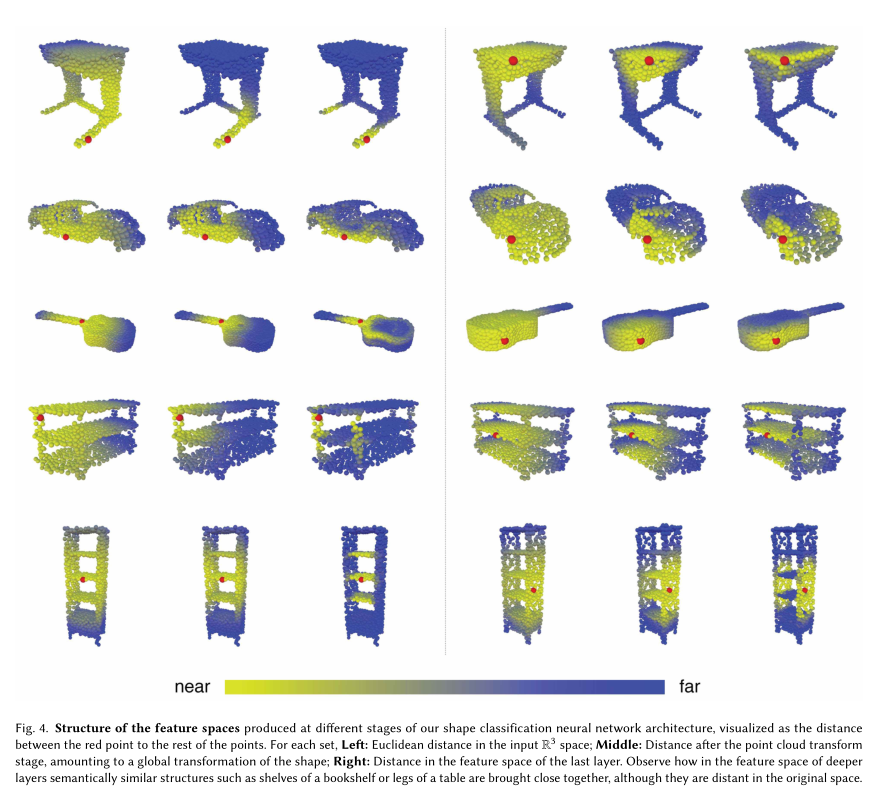
上图是我们的神经网络架构的不同阶段产生的特征空间的结构,可视化为红点到其余点的距离。
Left:输入的三维点在欧几里得空间内的距离。
Middle:在特征点Transform之后的点距离,相当于形态矫正之后空间距离。
Right:最后一层特征空间的点距离。
观察在深层次的特征空间中,语义相似的结构是如何结合在一起的,尽管他们在原始输入的空间中相距是比较远的。
评测
在这里我们将评估使用EdgeConv为不同的任务构架模型:分类,部件分割,语义分割。并将结果可视化,已说明和以前工作的主要区别。
分类
架构图和代码不一致的地方很多,具体必须参考代码实现方式。
代码部分只实现了分类,分割没有实现。
点击查看代码
class DGCNN(nn.Module):
def __init__(self, args, output_channels=40):
super(DGCNN, self).__init__()
self.args = args
self.k = args.k
self.bn1 = nn.BatchNorm2d(64)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
self.bn4 = nn.BatchNorm2d(256)
self.bn5 = nn.BatchNorm1d(args.emb_dims)
self.conv1 = nn.Sequential(nn.Conv2d(6, 64, kernel_size=1, bias=False),
self.bn1,
nn.LeakyReLU(negative_slope=0.2))
self.conv2 = nn.Sequential(nn.Conv2d(64 * 2, 64, kernel_size=1, bias=False),
self.bn2,
nn.LeakyReLU(negative_slope=0.2))
self.conv3 = nn.Sequential(nn.Conv2d(64 * 2, 128, kernel_size=1, bias=False),
self.bn3,
nn.LeakyReLU(negative_slope=0.2))
self.conv4 = nn.Sequential(nn.Conv2d(128 * 2, 256, kernel_size=1, bias=False),
self.bn4,
nn.LeakyReLU(negative_slope=0.2))
self.conv5 = nn.Sequential(nn.Conv1d(512, args.emb_dims, kernel_size=1, bias=False),
self.bn5,
nn.LeakyReLU(negative_slope=0.2))
self.linear1 = nn.Linear(args.emb_dims * 2, 512, bias=False)
self.bn6 = nn.BatchNorm1d(512)
self.dp1 = nn.Dropout(p=args.dropout)
self.linear2 = nn.Linear(512, 256)
self.bn7 = nn.BatchNorm1d(256)
self.dp2 = nn.Dropout(p=args.dropout)
self.linear3 = nn.Linear(256, output_channels)
def forward(self, x):
batch_size = x.size(0) # (32,3,1024)
x = get_graph_feature(x, k=self.k) # (32,6,1024,20)
x = self.conv1(x) # (32,64,1024,20)
x1 = x.max(dim=-1, keepdim=False)[0] # (32,64,1024)
x = get_graph_feature(x1, k=self.k) # (32,128,1024,20)
x = self.conv2(x) # (32,64,1024,20)
x2 = x.max(dim=-1, keepdim=False)[0] # (32,64,1024)
x = get_graph_feature(x2, k=self.k) # (32,128,1024,20)
x = self.conv3(x) # (32,128,1024,20)
x3 = x.max(dim=-1, keepdim=False)[0] # (32,128,1024)
x = get_graph_feature(x3, k=self.k) # (32,256,1024,20)
x = self.conv4(x) # (32,256,1024,20)
x4 = x.max(dim=-1, keepdim=False)[0] # (32,256,1024)
x = torch.cat((x1, x2, x3, x4), dim=1) # (32,512,1024)
x = self.conv5(x) # (32,1024,1024)
x1 = F.adaptive_max_pool1d(x, 1).view(batch_size, -1) # (32,1024)
x2 = F.adaptive_avg_pool1d(x, 1).view(batch_size, -1) # (32,1024)
x = torch.cat((x1, x2), 1) # (32,2048)
x = F.leaky_relu(self.bn6(self.linear1(x)), negative_slope=0.2) # (32,512)
x = self.dp1(x)
x = F.leaky_relu(self.bn7(self.linear2(x)), negative_slope=0.2) # (32,256)
x = self.dp2(x)
x = self.linear3(x) # (32,40)
return x
此处使用ModelNet40在分类任务上,评估模型,且此模型中包含未见过的形状。
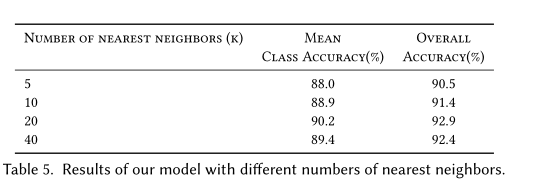
用于分类任务的网络架构如图三所示:我们使用EdgeConv层去提取集合特征。四个EdgeConv层使用三个共享的全连接层(64,64,128,256)。我们根据每个EdgeConv层的特征重新计算图形,并将新图形用于下一层。所有层的k最近邻数为\(20\),


 浙公网安备 33010602011771号
浙公网安备 33010602011771号