Learning Spatio-Temporal Transformer for Visual Tracking
Learning Spatio-Temporal Transformer for Visual Tracking
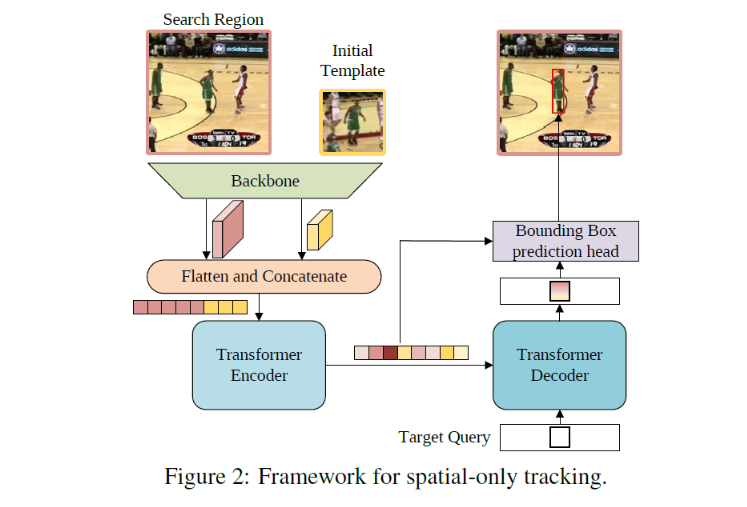
-
搜索区域(Search Region):这是图像中的一块区域,通常大于或等于目标的实际大小。搜索区域为模型提供了足够的上下文来识别和定位目标。
-
初始模板(Initial Template):这是目标在序列开始时的一个参考图像或框,模型使用它来识别后续帧中的相同目标。
-
骨干网络(Backbone):这是一个深度神经网络,通常是一个卷积神经网络,用于提取搜索区域和初始模板的特征表示。
-
平铺与串联(Flatten and Concatenate):从骨干网络中提取的特征被平铺成向量,并将搜索区域和初始模板的特征向量串联在一起,为Transformer Encoder提供输入。
-
Transformer Encoder:这部分接收上述平铺和串联的向量,通过多头自注意力机制和前馈神经网络处理这些向量,以增强对目标的空间特征的表示。
-
目标查询(Target Query):目标查询是一个特定的向量,用于代表跟踪任务中的目标。它在Transformer Decoder中被用来聚焦并识别目标的位置。
-
Transformer Decoder:接收来自Encoder的编码特征和目标查询,Decoder通过进一步的处理来精细化目标的位置信息。
-
边界框预测头(Bounding Box prediction head):最终,模型的这一部分基于Decoder的输出来预测目标的边界框,即确定目标在当前帧中的位置和大小。
创新点
-
结合CNN和Transformer:它利用卷积神经网络(CNN)强大的特征提取能力和Transformer的长范围依赖建模能力。在视觉跟踪中,这种结合可以提供对于空间特征的深度理解和对于时间序列信息的有效捕捉。
-
空间只跟踪(Spatial-only Tracking):框架专注于空间特征,这可能意味着它专门处理了目标的几何和外观信息,而没有考虑时间信息。这种方法对于某些特定类型的跟踪任务可能非常有效,尤其是在目标的运动模式复杂或难以预测时。
-
目标查询(Target Query):使用目标查询作为一种机制来保持跟踪目标的连续性是一个创新点。这个查询向量可以被看作是对目标的一种"记忆",帮助模型在连续的帧中保持对目标的关注。不懂
-
编码-解码器(Encoder-Decoder)结构:虽然Transformer的编码-解码器结构在自然语言处理中已经被广泛采用,但在视觉跟踪领域,这种结构的应用还是比较新颖的。它使得模型能够更加灵活地处理各种复杂场景,并提高了模型对目标位置的预测精度。
-
边界框预测头(Bounding Box Prediction Head):框架中可能还包含了一些创新的边界框预测机制,如直接预测边界框的形状和大小,而不仅仅是位置。这可以提高跟踪精度,尤其是在目标大小和形状变化显著的情况下。
-
自注意力机制的应用:在视觉跟踪领域内,Transformer的自注意力机制可能被用来捕捉目标在不同帧之间的关系,即使目标的外观发生了显著变化。
想法
-
对于鲁棒性问题考虑是否可以采用预测前进方向,虽然这样做对部分跟踪物体效果较差,又变相降低了鲁棒性,但是似乎能提高绝大部分动物跟踪物体效果。
-
对于目标跟踪DiMP网络利用判别式,个人认为充分采用背景信息与前景信息虽然能有效区分物体,但是略有反人类视觉直觉,此方法更偏向于目标检测。若有效提高鲁棒性,认为应当采用更新前几帧目标模板来平衡鲁棒性与漂移之间的问题,但是帧率估计要大大下降。
具体参照目标跟踪算法两大类方法:判别式和生成式的区别。一般来说,判别式充分利用了目标前景和背景信息,能更加有效地区分出目标,比单单运用目标区域特征进行模板匹配的方式,在复杂环境中的鲁棒性更强。
Siamese网络仅利用了初始帧的目标特征,后续帧都是据此来进行类似匹配的工作来进行判断的,没有利用到目标背景内容;而DIMP算法在Siamese网络的特征提取后,在线训练了一个分类器,该分类器可以将图像中的跟踪目标和背景区域区分出来,在后续帧的跟踪过程中,可从跟踪区域提取的特征上进行分类,得到属于跟踪目标的概率分数,这对跟踪结果的判定具有更高的参考价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号