Fully-Convolutional Siamese Networks for Object Tracking
引 言

方法
滑动匹配
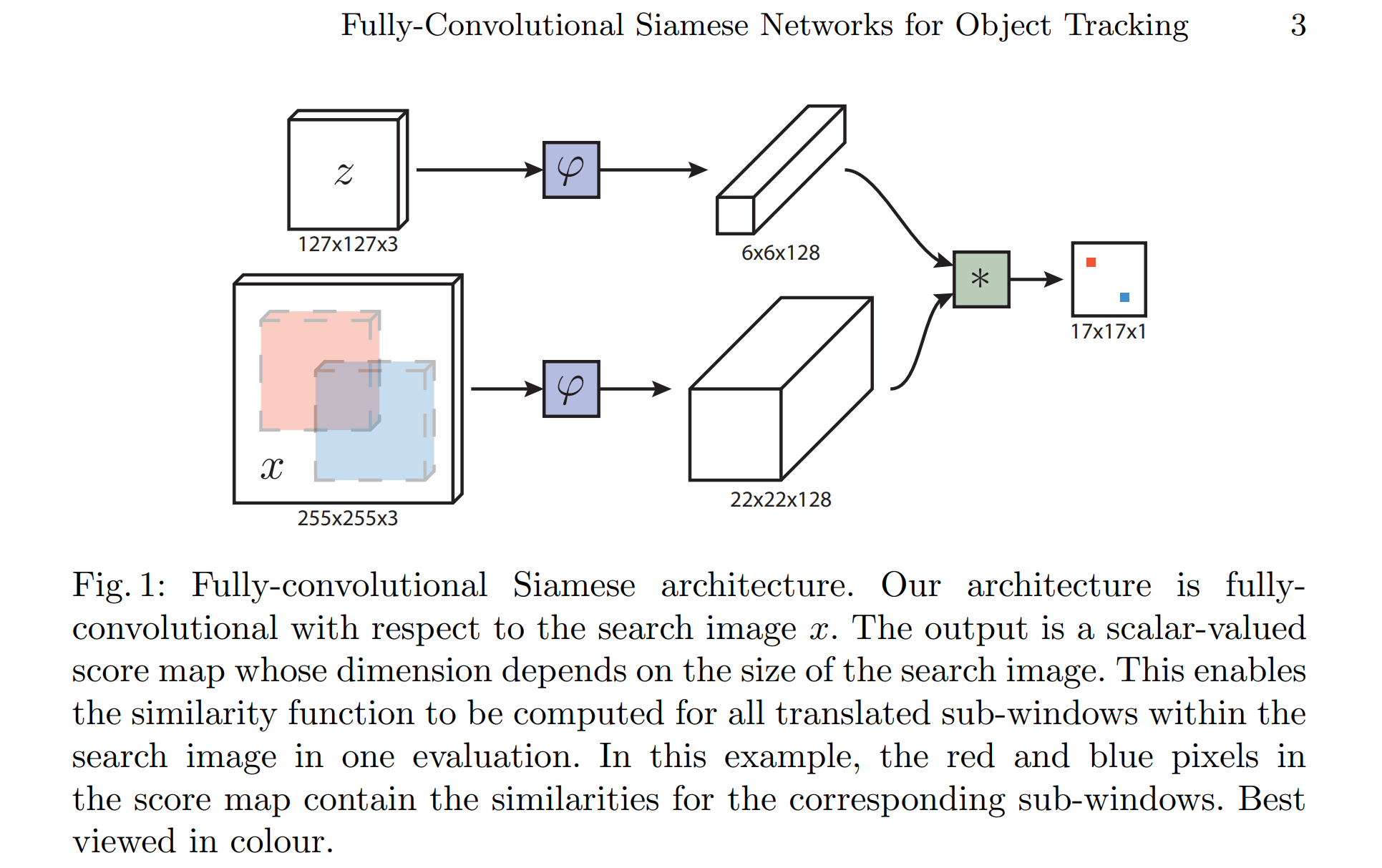

\(\varphi\) 为 AlexNet 求出特征矩阵;将第一帧的信息当做卷积核,对后面所有帧进行滑动匹配(卷积运算)。
head实现具体函数
self.net = Net( backbone=AlexNetV1(),# 采用AlexNet网络提取特征 head=SiamFC(self.cfg.out_scale)) # 自定义滑动匹配 def _fast_xcorr(self, z, x): nz = z.size(0) nx, c, h, w = x.size() x = x.view(-1, nz * c, h, w)# 将x整合成 nz 组 (-1,c, h, w) 的形式 out = F.conv2d(x, z, groups=nz) out = out.view(nx, -1, out.size(-2), out.size(-1)) return out
- 将x按照通道数(axis=2)划分8个,会将z按照batch(axis=3)划分8个。每个子x.shape为3,128,22,22,每个子z.shape为1,128,6,6。
- 每个子z与与子x(卷积核)进行卷积,得到子输出out.shape为3,1,17,17。共进行groups=B次卷积,并按照通道数(axis=3)堆叠。即最终输出out.shape为3,8,17,17。
学习率
学习率衰减采用指数衰减调整学习率:\(lr=le*gamma^{epoch}\)。
搜索区域
其中第一帧的groundtruth是已知的(x_min,y_min,w,h),那么模板图像z的大小即为:
\[s(w+2p)*s(h+2p)=A\\
p=(w+4)/4
\]
其中A=\(127^2\),s是对图像进行的一种变换,即进行(w+2p)x(h+2p)的扩展,再resize成127x127的大小。
而对于搜索区域x来说,以上一帧预测的bbox的中心为裁剪中心,裁剪出255x255大小的图片。这里,作者为了提高跟踪性能,选取了多尺度进行预测,分别是1.025^{-2,-1,0,1,2},其中255x255对应尺度为1。之后作者又尝试了三种尺度的SiamFC-3s,提升了FPS。这里认为最大峰值即为我们预测结果所在点。
# 选取多个尺度的最大峰值,我们认为最大峰值即为我们预测结果所在点 scale_id = np.argmax(np.amax(responses, axis=(1, 2))) # 提取出目标的峰值响应图,并进行归一化处理。首先,将峰值响应图的最小值减去,然后将其除以总和加上一个很小的数(避免除以零)。最后,使用汉宁窗口(Hann Window)对峰值响应图进行加权处理。 response = responses[scale_id] response -= response.min() response /= response.sum() + 1e-16 response = (1 - self.cfg.window_influence) * response + self.cfg.window_influence * self.hann_window # 通过`np.unravel_index`函数找到峰值响应图中的最大值所在的位置 loc = np.unravel_index(response.argmax(), response.shape)
这里特别指出,当模板和搜索图像不够裁剪时,要对不足的像素进行RGB通道的均值填充。

总结
SiamFC开创了将孪生网络结构应用在目标跟踪领域的先河,显著提高了深度学习方法跟踪器的跟踪速度,之后的相关深度学习跟踪器的方法也大多基于此方法进行改进和优化。所以该方法与KCF地位相近,都具有一定的里程碑意义。
但是,如今目标跟踪一般采取transformer实现,siam网络结构一般不再使用。
注意事项
复现时,ExperimentOTB类__init__方法中的OTB的download需要关闭,其中的OTB类中,__otb13_seqs,__otb50_seqs,__tb100_seqs数据集类别数组可能与数据集不相符,需要根据数据集进行相应调整。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号