基于KNN的发票识别
项目概况:
有一个PDF文件,里面的每页都是一张发票,把每页的发票单独存为一个PDF并用该发票的的发票号码进行文件的命名,发票号码需要OCR识别,即识别下图中红色方块的内容。

一:拆分PDF
现有一个PDF文件,里面有很多张发票图片,每张发票占一页

我们先把这整个PDF拆分为单独的PDF
使用PyPDF2这个包
代码如下,基本上每句都写了注释
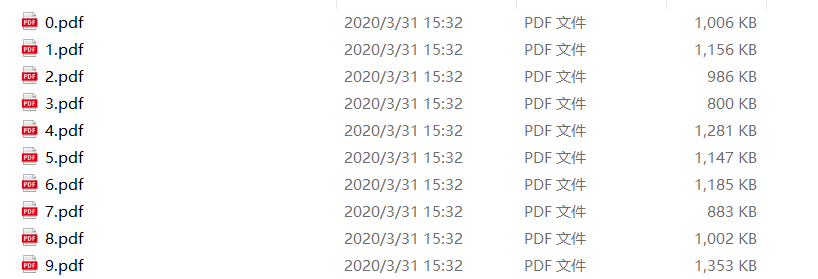
from PyPDF2 import PdfFileWriter,PdfFileReader def test1(file_path,folder_path,num,end_page,start_page=0): """ :param file_path: pdf文件路径 :param folder_path: 存放路径 :param num: 拆分后的pdf存在几个原pdf页数 :param end_page: 拆分到的最后一页 :param start_page: 起始的页数,默认为0 :return: """ # 打开PDF文件 pdf_file = PdfFileReader(open(file_path, 'rb')) # 获取pdf的页数 pdf_file_num = pdf_file.getNumPages() # 如果输入的end_page页数比pdf文件的页数大或者小于等于0,让停止的页数为pdf最大的页数 if end_page>pdf_file_num or end_page<=0: end_page=pdf_file_num # 从起始页到最后一页进行遍历 for i in range(start_page,end_page,num): #创建一个PdfFileWriter的对象 out_put = PdfFileWriter() # 给out_put这个对象传num数的页,项目中每个发票都只占了1页,所以num为1,如果发票占据2页,那么num为2 for k in range(num): out_put.addPage(pdf_file.getPage(i)) # 设置保存的路径 out_file = folder_path + "\\" + f"{i}.pdf" # 把out_put里面的数据写入到文件中 out_put.write(open(out_file, 'wb'))
运行结果如下:
二:把PDF变成图片,并进行切分
现在发票是PDF格式,我们需要转为图片格式,而且我需要的发票号码在发票的右上角,所以对图片进行大致的切分有助于提高后面的识别速率。
这里解释一下rect = page.rect,rect可以获取页面的大小,rect.tl,tl为topleft的缩写,也就是左上角的意思,所以有tl(左上),tf(右上),bl(左下),bf(右下)等坐标
import fitz def my_fitz(pdfPath, imagePath): """ :param pdfPath: pdf的路径 :param imagePath: 图片文件夹的路径,不是图片路径 :return: """ # 打开pdf文件 pdfDoc = fitz.open(pdfPath) for pg in range(pdfDoc.pageCount): page = pdfDoc[pg] rotate = int(0) # 每个尺寸的缩放系数为2,生成的图像的分辨率会提高,参数也可以自由设置,没有硬性要求 zoom_x = 2 zoom_y = 2 # 这个函数可以理解为,把zoom_x,zoom_y这两个参数保存起来 mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate) rect = page.rect # 页面大小 # mp为截取矩形的左上角坐标 mp=rect.tr-(500/zoom_x,0) # tem为截取矩形的右下角坐标 tem=rect.tr+(0,200/zoom_y) # clip为截取的矩形 clip = fitz.Rect(mp, tem) # 进行图片的截取 pix = page.getPixmap(matrix=mat, alpha=False,clip=clip) if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在 os.makedirs(imagePath) # 若图片文件夹不存在就创建 new_img_path = imagePath + '/' + '0.png' pix.writePNG(new_img_path) # 将图片写入指定的文件夹内 return new_img_path
运行结果如图所示:
![]()

三:检测边缘,把中间的数字截取出来
边缘检测我使用的CV2模块,注意使用cv2.threshold函数时,里面的图片必须为灰度图,不然会报错
import cv2 def my_croping(imgpath): # 读取图片的路径 img = cv2.imread(imgpath) # 把该图片转换为灰度图 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #设置固定级别的阈值应用于矩阵 ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 寻找边缘,返回的contours为边缘数据的集合 _, contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_TC89_L1) # 画出边缘,-1为画出所有的边缘,如果为任意自然数那么为contours的索引,(0,0,255)为颜色,最后的2是线条的粗细,数值越大,线条越粗 cv2.drawContours(img, contours, -1, (0, 0, 255), 2) # 展示图片 cv2.imshow("pic", img) # 等待,当参数为0时,为无限等待,直到有键盘指令 cv2.waitKey(0)
运行结果:

可见上一步骤的图片中的发票号码已经被圈起来了,但是有很多不必要的东西也被圈进来了,所以我们需要对初始的的contours进行筛选。
contours是一个包含多个列表的列表,我们需要的中间的数字,观察可知,中间数字的边缘比较大,所以我们只需要通过len()方法就可以进行初步的过滤
contours.sort(key=lambda x: len(x), reverse=True) for i in range(len(contours)): if len(contours[i]) > 10: continue else: contours = contours[:i] break
加入过滤后运行结果:

我们初步的缩小了范围,下面需要制定具体的规则来确定想要获得的对象
首先,我们先获取各个边缘所组成的矩形的坐标
rect_list=[] for i in range(len(contours)): cont_ = contours[i] # 找到boundingRect rect = cv2.boundingRect(cont_) print(rect) rect_list.append(rect)
运行结果如下:

从左到右分别是x,y,宽度,高度
很明显,我们要找的坐标是8个,宽度,高度差不多的坐标,n为阈值,初始为10,当两个矩阵的宽和高直接的差的绝对值在阈值范围内,填入集合,如果这样的元素超过8个,那么则找到号码对应的矩阵,在传入之前,用X坐标的大小进行排序,能减少很多时间
def xyhw(li): n=10 while n<30: for i in range(len(li)): tem_li=[li[i]] for k in range(i+1,len(li)): if abs(li[i][1]-li[k][1])+abs(li[i][2]-li[k][2])+abs(li[i][3]-li[k][3])<n: tem_li.append(li[k]) if len(tem_li)>=8: return tem_li n+=1
但是这个筛选完,还有一个问题,有时候会出现分割后NO没有分割掉的情况,所以需要过滤掉NO
def filter_li(li): if len(li)>8: li = li[:9] interval=li[0][0]-li[1][0] test_interval=li[-2][0]-li[-1][0] if test_interval/interval>1.5: li=li[:-1] return li
这样我们就可以获得号码的八个矩阵坐标,我们只需要把这八个矩阵融合即可
#进行排序 rect_list.sort(key= lambda x:x[0],reverse=True) #进行筛选 rect_list=filter_li(rect_list) #x0,y0为矩阵的左上角,x1,y1为矩阵的右下角 y0=rect_list[0][1] y1=rect_list[0][1]+rect_list[0][3] x0=rect_list[-1][0] x1=rect_list[0][0]+rect_list[0][2] print(y0,y1,x0,x1) #进行图片切割 cropImg = img2[y0:y1,x0:x1] #写入图片 cv2.imwrite(img_path,cropImg)
可以获得这样的图片:

四:把图片中的数字分别截取出来
第四步和第三步的原理一样,先边缘检测,然后获取矩形坐标后进行截图,比第三步简单不少,这里就不多赘述了
import cv2 import numpy as np def xyhw(li): n=10 tem_li=[] while n<30: for i in range(len(li)): tem_li=[li[i]] for k in range(i+1,len(li)): if abs(li[i][1]-li[k][1])+abs(li[i][2]-li[k][2])+abs(li[i][3]-li[k][3])<n: tem_li.append(li[k]) if len(tem_li)>=8: return tem_li n+=1 else: return tem_li # 将img的高度调整为28,先后对图像进行如下操作:直方图均衡化,形态学,阈值分割 def pre_treat(img): height_ = 28 ratio_ = float(img.shape[1]) / float(img.shape[0]) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) gray = cv2.resize(gray, (int(ratio_ * height_), height_)) gray = cv2.equalizeHist(gray) _, binary = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY) img_ = 255 - binary # 反转:文字置为白色,背景置为黑色 return img_ def get_roi(contours): rect_list = [] for i in range(len(contours)): rect = cv2.boundingRect(contours[i]) if rect[3] > 10: rect_list.append(rect) return rect_list def get_rect(img): _, contours, hierarchy = cv2.findContours(img,cv2.RETR_TREE, cv2.CHAIN_APPROX_TC89_L1) rect_list = get_roi(contours) rect_list.sort(key= lambda x:x[0],reverse=True) rect_list=xyhw(rect_list) return rect_list def change_(img): length = 28 h,w = img.shape H = np.float32([[1,0,(length-w)/2],[0,1,(length-h)/2]]) img = cv2.warpAffine(img,H,(length,length)) M = cv2.getRotationMatrix2D((length/2,length/2),0,26/float(img.shape[0])) return cv2.warpAffine(img,M,(length,length)) def fenge(img_path): cont = 0 img = cv2.imread(img_path) img = pre_treat(img) contours = get_rect(img) folder_path=r"C:\Users\86173\Desktop\jetbrains2019.2\new\tem" file_list=[] # img=cv2.drawContours(img,contours,2,(0, 0, 255),3) print("*********************%s*************" %contours) for i in range(len(contours)): y0 = contours[i][1] y1 = contours[i][1] + contours[i][3] x0 = contours[i][0] x1 = contours[i][0] + contours[i][2] print(y0, y1, x0, x1) cropImg = img[y0:y1, x0:x1] cropImg = change_(cropImg) fenge_img=rf"{folder_path}\{cont}.png" cv2.imwrite(fenge_img, cropImg) cont += 1 file_list.append(fenge_img) return file_list
五:苦力活
通过第四步的分割,我们可以得到分割后的数字,那么第一步就是给这些分割后的数字命名,类似这样:

建议在分割的时候,用input输入来命名嗷
第二步就是把这些图片转为矩阵存入txt中:
from PIL import Image import numpy def noise_remove_pil(image_name, k): """ 8邻域降噪 Args: image_name: 图片文件命名 k: 判断阈值 Returns: """ def calculate_noise_count(img_obj, w, h): """ 计算邻域非白色的个数 Args: img_obj: img obj w: width h: height Returns: count (int) """ count = 0 width, height = img_obj.size for _w_ in [w - 1, w, w + 1]: for _h_ in [h - 1, h, h + 1]: if _w_ > width - 1: continue if _h_ > height - 1: continue if _w_ == w and _h_ == h: continue if img_obj.getpixel((_w_, _h_)) < 190: # 这里因为是灰度图像,设置小于230为非白色 count += 1 return count img = Image.open(image_name) # 灰度 gray_img = img.convert('L') w, h = gray_img.size for _w in range(w): for _h in range(h): if _w == 0 or _h == 0: gray_img.putpixel((_w, _h), 255) continue # 计算邻域非白色的个数 pixel = gray_img.getpixel((_w, _h)) if pixel == 255: continue if calculate_noise_count(gray_img, _w, _h) < k: gray_img.putpixel((_w, _h), 255) # gray_img = gray_img.resize((32, 32), Image.LANCZOS) gray_img.save(image_name) # gray_img.show() im = numpy.array(gray_img) for i in range(im.shape[0]): # 转化为二值矩阵 for j in range(im.shape[1]): if im[i, j] <190: im[i, j] = 1 else: im[i, j] = 0 return im if __name__ == '__main__': for i in range(0,10): for k in range(0,100): png_file_path=rf"C:\Users\86173\Desktop\jetbrains2019.2\model_test\{i}_{k}.png" txt_file_path=rf"C:\Users\86173\Desktop\jetbrains2019.2\model_test\txt_folder\{i}_{k}.txt" try: im = noise_remove_pil(png_file_path, 4) with open(txt_file_path,'at',encoding='utf-8')as f: for n in im: f.writelines(str(n).replace("[","").replace("]","").replace(" ","")+"\n") except Exception as e: continue
运行结果:
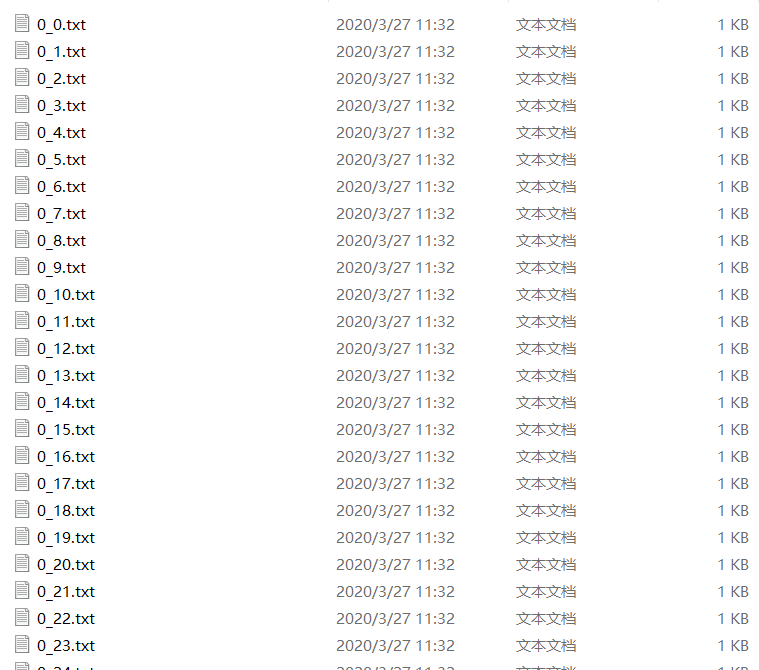

获得这样的文件,那么准备工作就结束了
六:KNN模型的使用
导入sklearn使用knn模型非常简单,代码量很少
import numpy as np from os import listdir from sklearn.neighbors import KNeighborsClassifier as kNN def np2vector(im): returnVect = np.zeros((1, 784)) for i in range(28): # 读一行数据 lineStr = im[i] # 每一行的前28个元素依次添加到returnVect中 for j in range(28): returnVect[0, 28 * i + j] = int(lineStr[j]) # 返回转换后的1x784向量 return returnVect def img2vector(filename): #创建1x784零向量 returnVect = np.zeros((1, 784)) #打开文件 fr = open(filename) #按行读取 for i in range(28): #读一行数据 lineStr = fr.readline() #每一行的前28个元素依次添加到returnVect中 for j in range(28): returnVect[0,28*i+j] = int(lineStr[j]) #返回转换后的1x784向量 return returnVect def handwritingClassTest(im): #测试集的Labels hwLabels = [] #返回trainingDigits目录下的文件名 trainingFileList = listdir(r"C:\Users\86173\Desktop\jetbrains2019.2\model_test\txt_folder") #返回文件夹下文件的个数 m = len(trainingFileList) #初始化训练的Mat矩阵,测试集 trainingMat = np.zeros((m, 784)) #从文件名中解析出训练集的类别 for i in range(m): #获得文件的名字 fileNameStr = trainingFileList[i] #获得分类的数字 classNumber = int(fileNameStr.split('_')[0]) #将获得的类别添加到hwLabels中 hwLabels.append(classNumber) trainingMat[i,:] = img2vector(r'C:\Users\86173\Desktop\jetbrains2019.2\model_test\txt_folder\%s' % (fileNameStr)) #构建kNN分类器 neigh = kNN(n_neighbors = 4, algorithm = 'auto') #拟合模型, trainingMat为测试矩阵,hwLabels为对应的标签 neigh.fit(trainingMat, hwLabels) vectorUnderTest = np2vector(im) classifierResult = neigh.predict(vectorUnderTest) return classifierResult
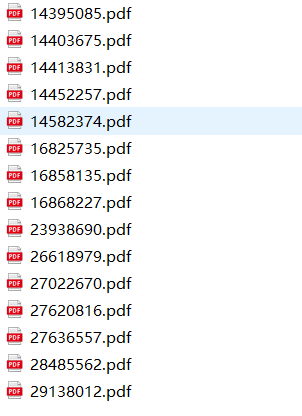
有这个模型,我们调用一下,就可以获取到对应的发票号码了
最终运行结果:
最后:
knn的原理比较简单,但是因为是在工作之余写的,写的比较匆忙,有些步骤说的不够详细,如果有什么问题欢迎在评论区留言,如果有改进方案那就更好了,博主只是一个初入机器学习的小学生,欢迎各位大佬的指点,谢谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号