

python基础(注释/变常量/数据优化/数据类型)
目录
2.如何使用注释
3.注释快捷键
4.python代码编写规范
二、变量与变量
1.什么是变量
2.如何使用变量
3.变量的语法格式
4.变量的命名规范
5.变量的命名风格
6.常量
三、python底层优化与垃圾回收机制
1.python底层优化
2.python垃圾回收机制
四、数据类型
1.整型int
2.浮点型float
3.字符串str
4.列表list
5.字典dict
6.布尔值bool
7.元组tuple
8.集合set
2.如何使用注释
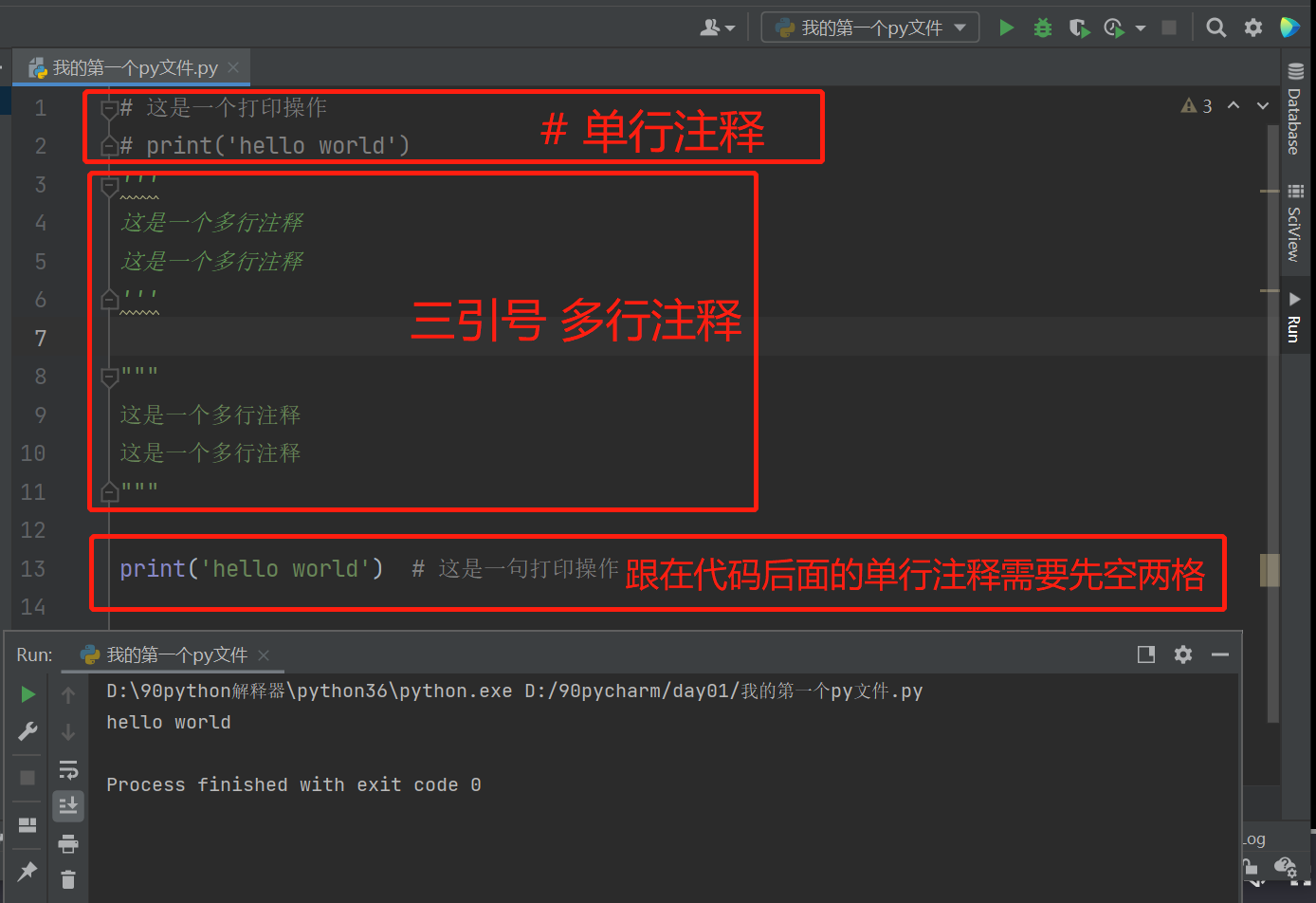
方式1:#号加空格 单行注释 (注意:#号与注释文本之间需要一个空格,需要单行注释跟在代码后面,就需要空两格再接#号)
方式2:使用三引号(单双引号都可以)多行注释
3.注释快捷键
注释的内容后直接选中内容然后使用键盘的Ctrl+问号(?);
多行代码写完不需要运行的时候也可以选中内容后直接用这个快捷键变成注释,可以只运行需要的代码行。
4.python代码编写规范
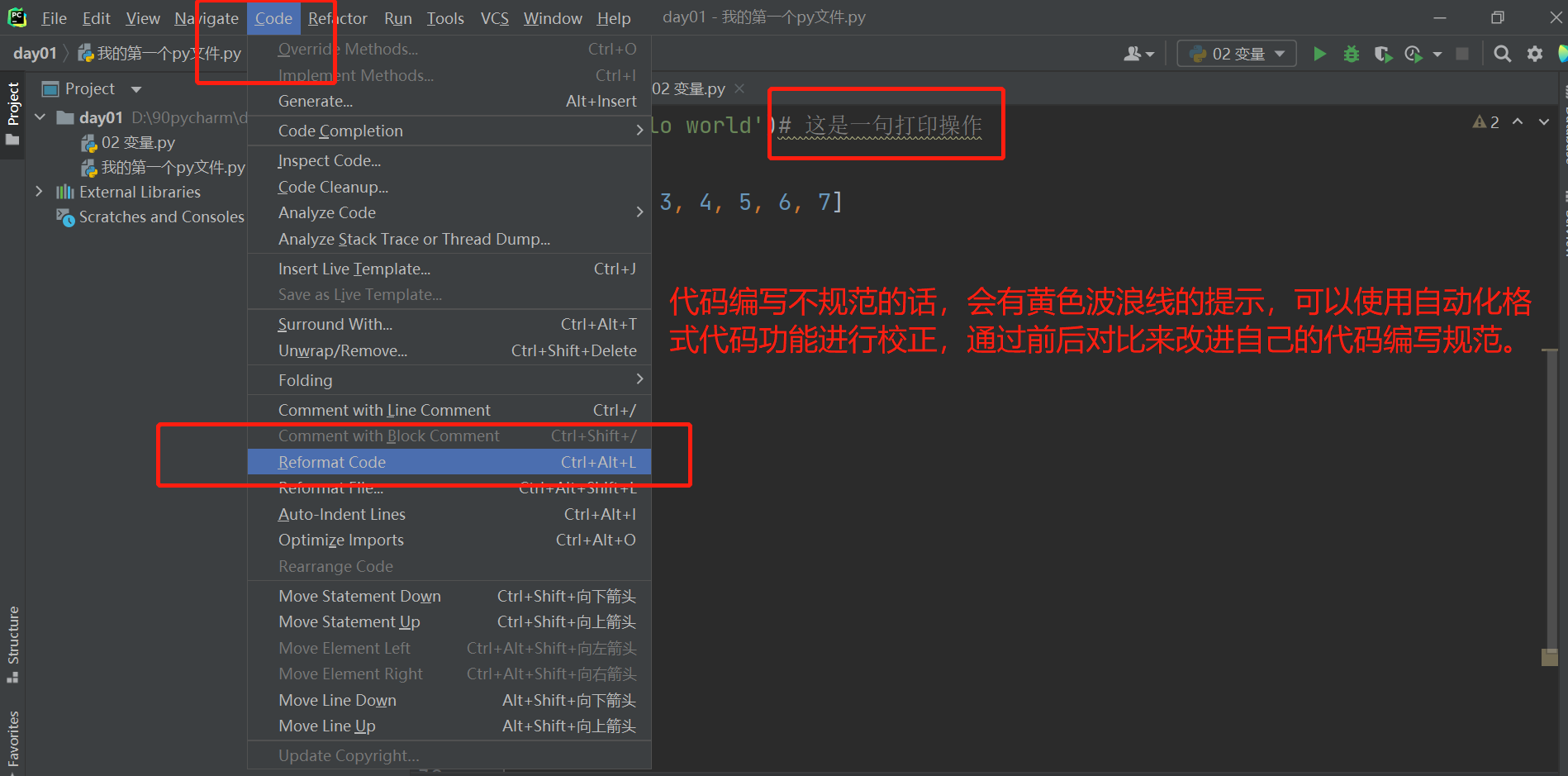
pycharm这个软件提供自动化格式代码功能,也就是说如果编写不规范可以直接用这个功能进行校正。
自动化格式代码功能的快捷键是键盘的Ctrl+alt+L,在软件里面使用的话就点菜单栏的Code-Reformat code.
二、变量与常量
1.什么是变量
即变化的量,用于记录事物的某种状态。
2.如何使用变量
在日常生活中,举个例子,我们会这样使用:(:冒号右边就是变量)
姓名:张三
年龄:20
爱好:学习
在程序中,是这样使用的:(= 号 右边就是变量,非数字的需要用单引号)
name = 'Aily'
age = 20
habby = 'study'
3.变量的语法格式
在程序中的变量有它的语法格式,比如:
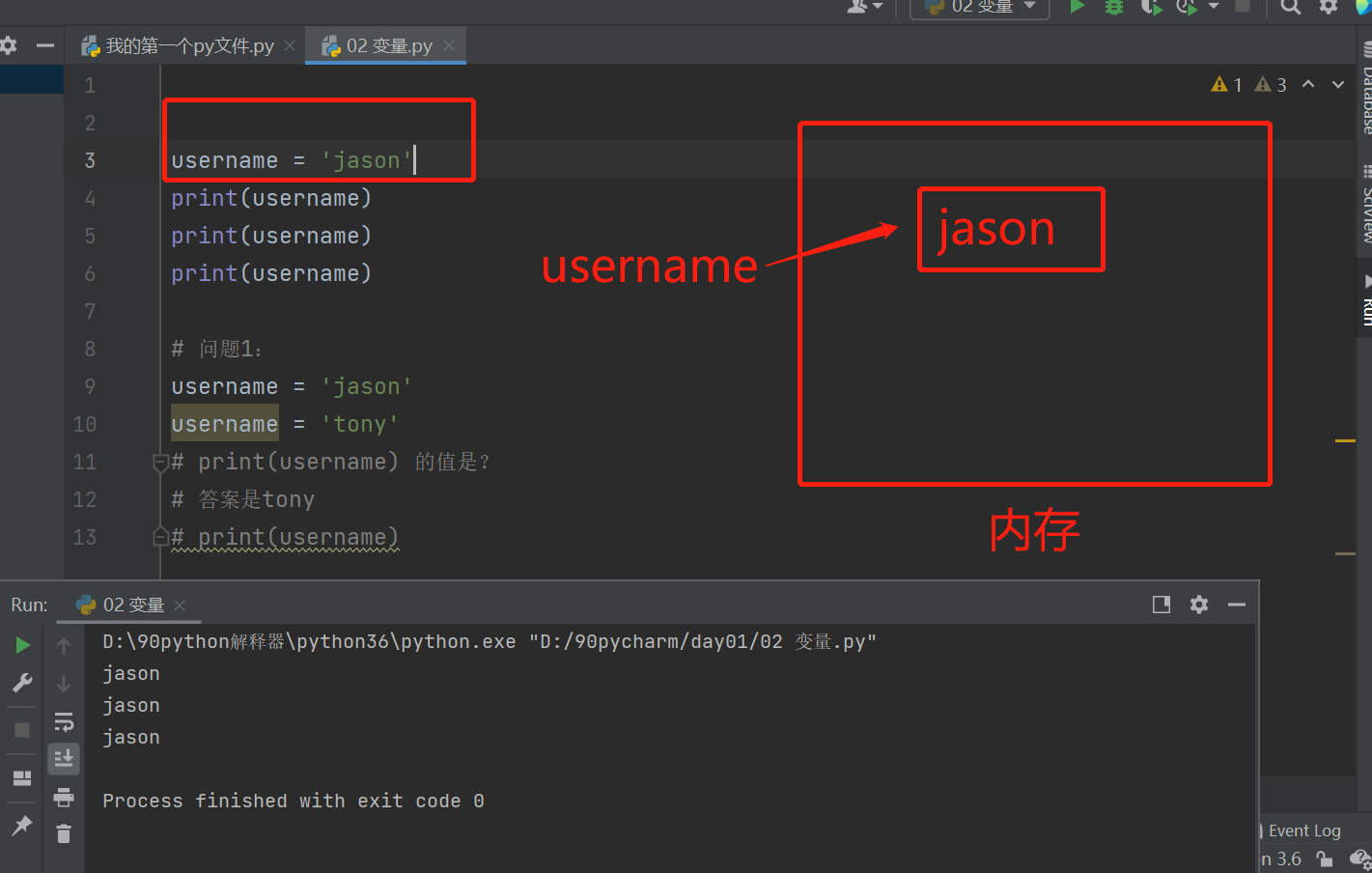
username = 'jason'
username我们称之为变量名;=符号我们称之为赋值符号(不叫等于号);jason我们称之为变量。
那么这个语法的底层逻辑是什么样的呢?还是举这个例子:
username = 'jason'
它的底层逻辑可以这样理解:
1.在内存中有一块空间存储这个变量 jason
2.把这个变量jason所在的内存编号地址绑定给变量名username
3.之后如果需要访问这个变量jason,就需要通过变量名username进行访问
注意:只要遇到赋值符号 = 号,我们都先看符号右边,再看符号左边。
4.变量的命名规范
①变量名只能由字母、数字、下划线三种随机任意组合。
例如:username(可以);_(可以);ABC@EF(不可以);A1(可以);abc_123(可以)
②变量名不能以数字开头,也尽量不要使用下划线开头,因为下划线有特殊含义,一般是指在程序中这个下划线这个变量名指向的变量暂时用不上,但是为了一定的规范,需要用这个变量名把值取出来先放在那里。
③变量名一定要做到见名知意,不建议使用拼音或者汉字,会显得自己档次很低,平时多积累一些英语单词,实在不会的去百度搜索一下。
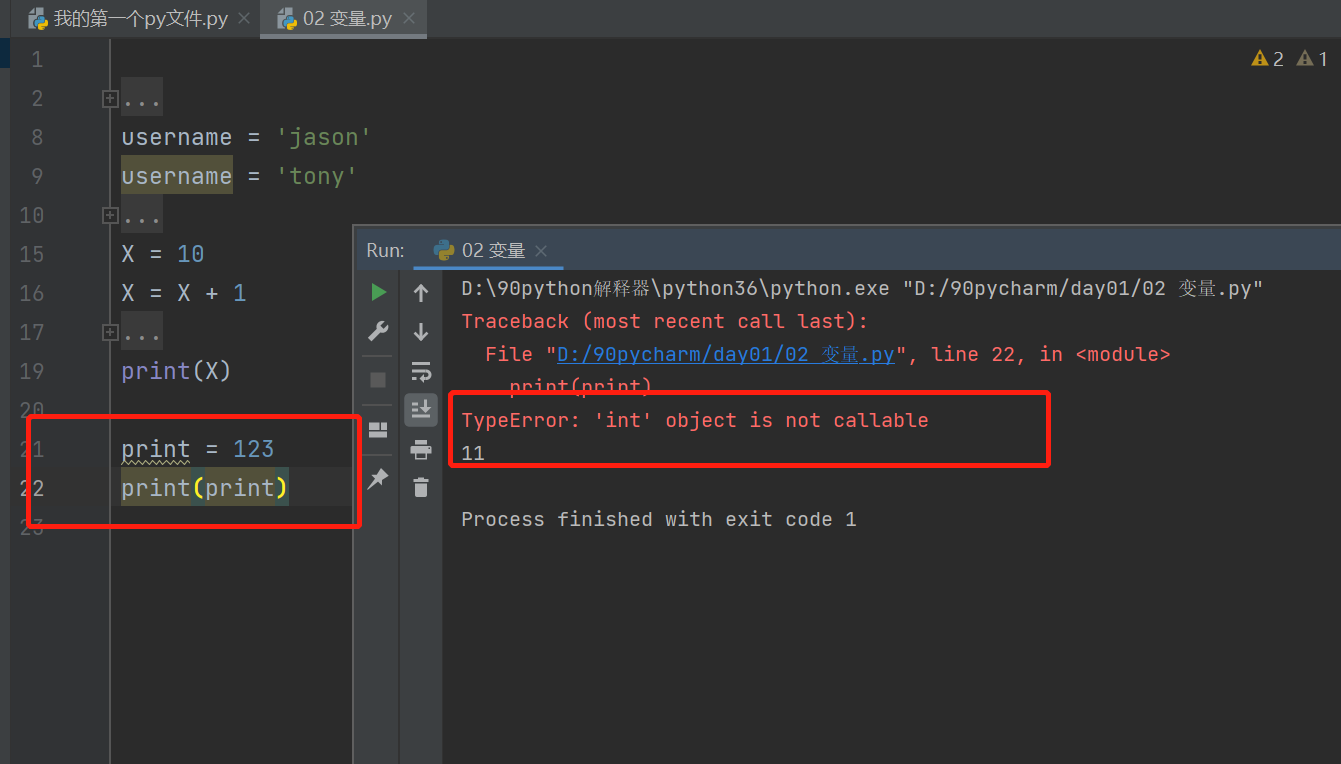
④变量名不能与关键字冲突,比如print不能作为变量名,因为print是一个打印命令,如果作为变量名了,print作为打印命名就会失效。
5.变量的命名风格
主要了解一下两种风格:
驼峰体(JavaScript 常用),又分为大驼峰和小驼峰;
大驼峰:所有单词的首字母都是大写,比如:UserNameFromDb
小驼峰:第一个单词的首字母是小写,其余单词首字母大写,比如:userNameFromDb
下划线(Python常用):单词与单词之间用下划线隔开,比如:user_name_from_db
6.常量
即不变的量,主要用于记录一些不变的状态。比如:圆周率π、重力加速度g...
在python中是不存在真正意义上的常量的,行内墨守成规的把全大写的变量看成常量。
比如:HOST = '127.0.0.1' 这种情况一般在配置文件中比较常见。
其他编程语言中是存在真正意义上的常量的,定义了就无法修改。
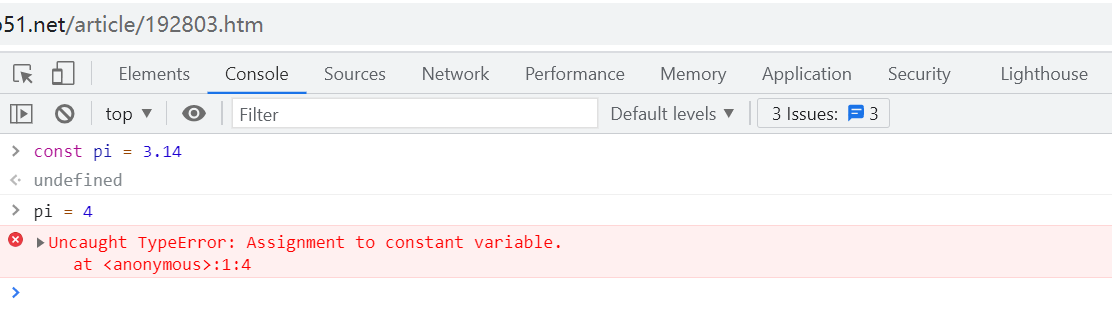
比如: const pi = 3.14
pi = 4
就直接报错,不允许修改
三、python底层优化与垃圾回收机制
1.python底层优化
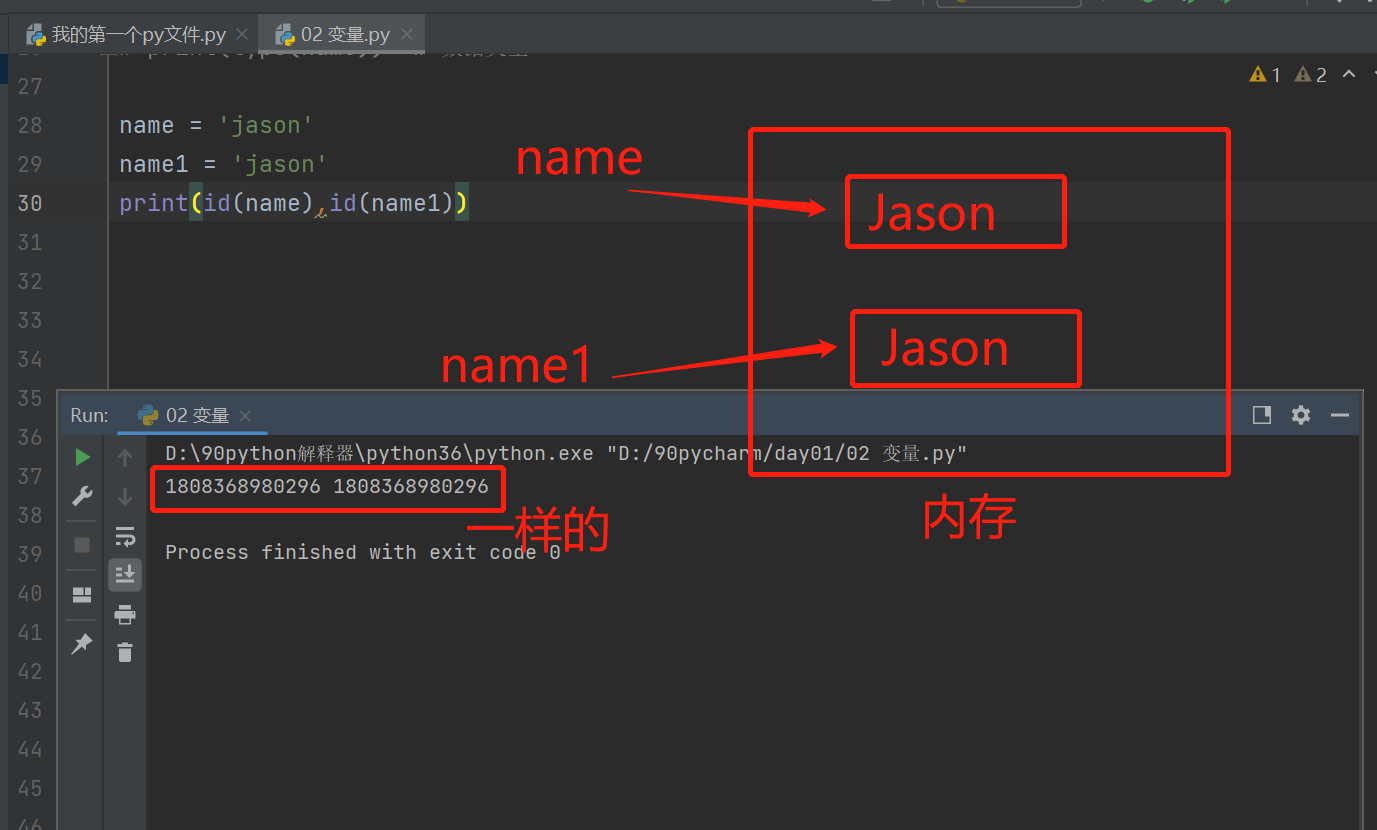
当数据量很小的时候,如有多个变量名的需要使用一样的变量,那么这些变量会指向同一个地址。
一个变量名只能指向一个地址,但是一个地址可以有多个变量名指向。
2.python垃圾回收机制
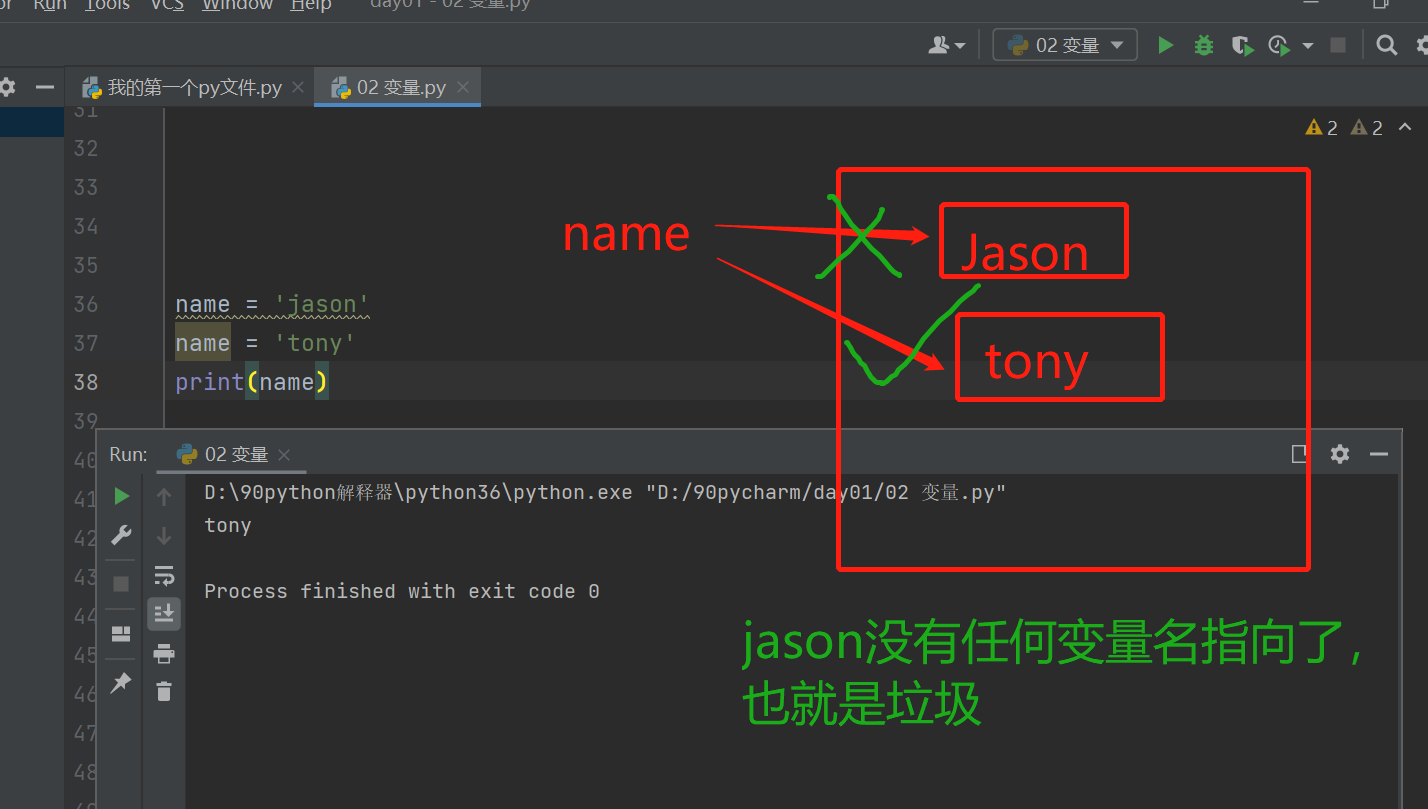
垃圾数据是指在内存中没有任何变量名指向的数据。
针对垃圾数据,Python开发了一套自动化回收方案。一共分为三大机制:
1:引用计数,即内存中变量身上有几个变量名绑定那么引用计数就是几,主要计数不为零,就不属于垃圾;
2:标记清除:当内存即将占满的时候,Python会自动暂停程序的运行,把内存中的数据从头到尾进行扫码打上标记,之后一次性清除标记的数据。
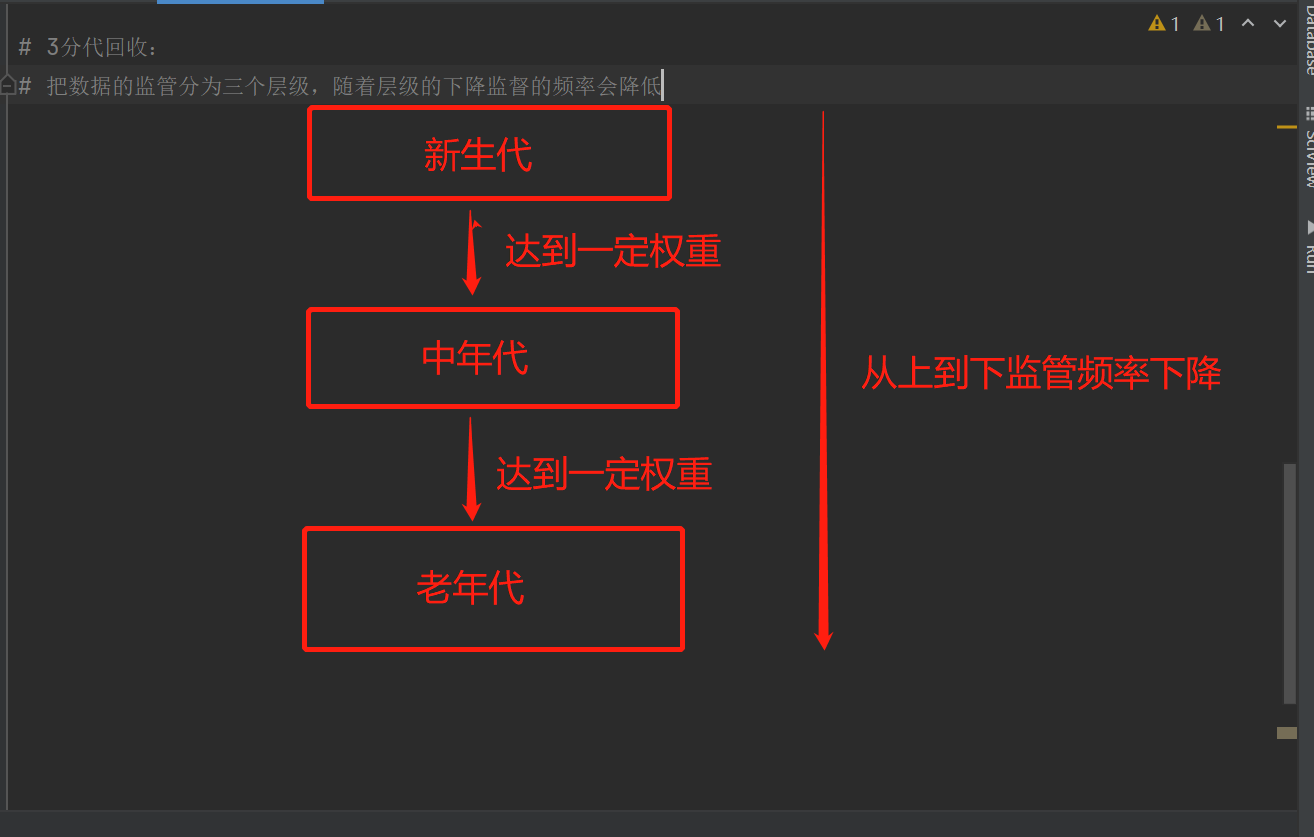
3.分代回收:说的通俗一些,把数据按使用频率或者存在时间长短,分别被判定为新生代、中年代以及老年代三个层级。数据刚进入内存的时候,都会现在新生代,然后每次扫描都会发现这个数据被使用,那么达到一定的频率权重之后就会进入中年代,然后再达到一定的频率权重之后就会进入老年代。随着层级的下降,监管的频率也会降低,减少监管的压力。
四、数据类型
在现实生活中,数据存储的方式和表现形式有很多种,比如文本、表格、视频、音频、图片...
在IT的世界中,数据的存储也一样存在多种多样的存储方式和表现形式。这里主要列举Python常见的8中数据类型:
1.整型int
也就是整数,用于记录一些整数数据,比如人的年龄,班级的人数...
eg:age = 18 直接写的整数就是整型
2.浮点型float
也就是小数,可以用于记录一些小数的数据,比如人的薪资,身高...
eg:salary = 3.1 直接写的小数就是浮点型
3.字符串str
主要用于记录描述描述性性质的数据,比如年龄,邮箱,地址...
引号引起来的部分。
有四种定义方式:
①单引号 name = 'jason'
②双引号 name = "jason"
③三单引号 name = '''jason''' (注意:左侧出现赋值符号和变量名则为字符串,否则为注释)
④三双引号 name = """jason""" (注意:左侧出现赋值符号和变量名则为字符串,否则为注释)
为啥需要这么多种方式呢,目的是为了防止字符串文本内还有其他的数据需要用到引号,所以需要区别开。
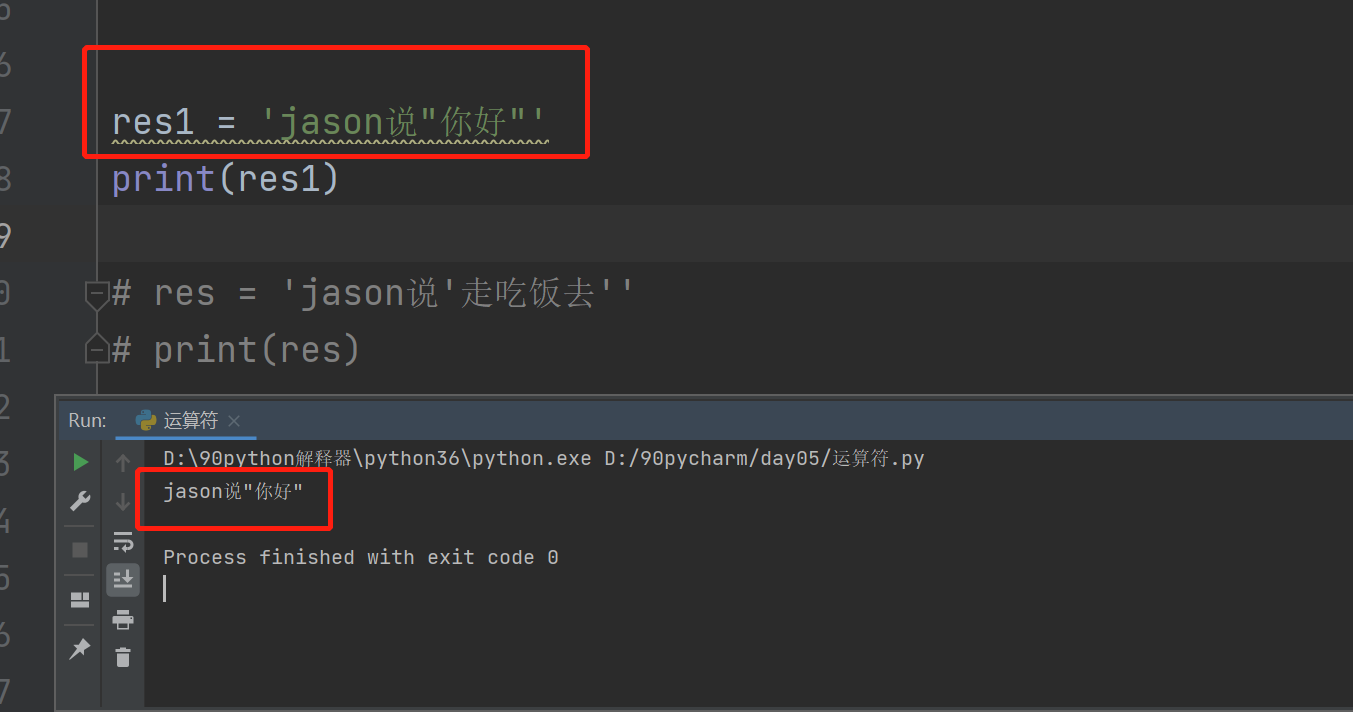
比如说:res = 'jason说"你好"'
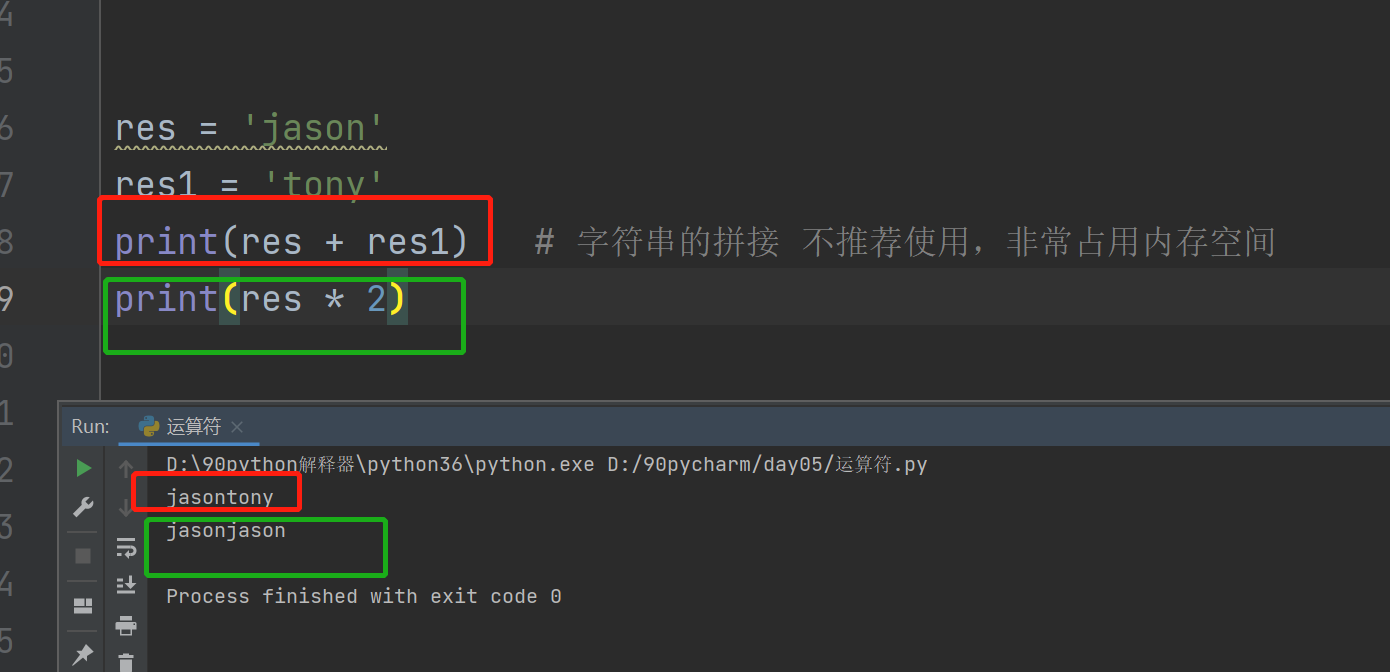
字符串可以相加或者相乘,实现字符串的拼接,但是不推荐使用,会很占用内存空间。
4.列表list
作用:能够存储多个数据并且方便取出
中括号括起来的部分
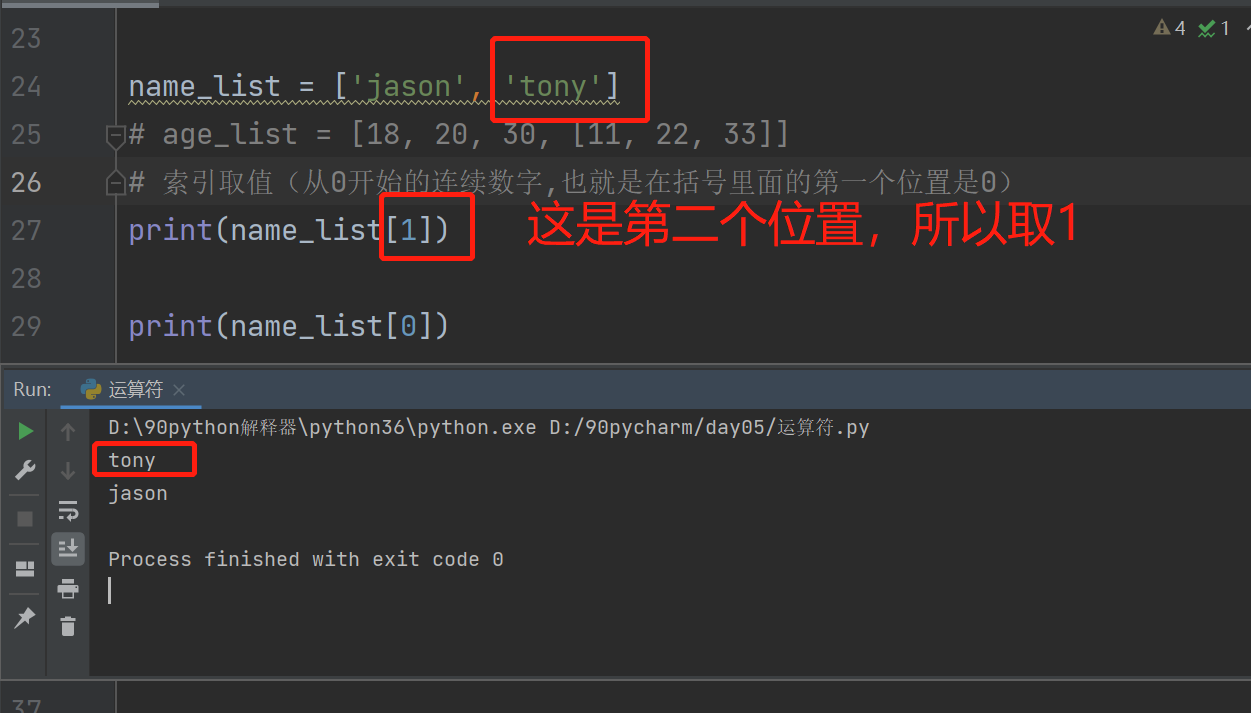
name_list = ['jason', 'tony']
索引取值(从0开始的连续数字,也就是在括号里面的第一个位置是0)
name_list = ['jason', 'tony']
print(name_list[1]) # tony
print(name_list[0]) # jason
#小练习:
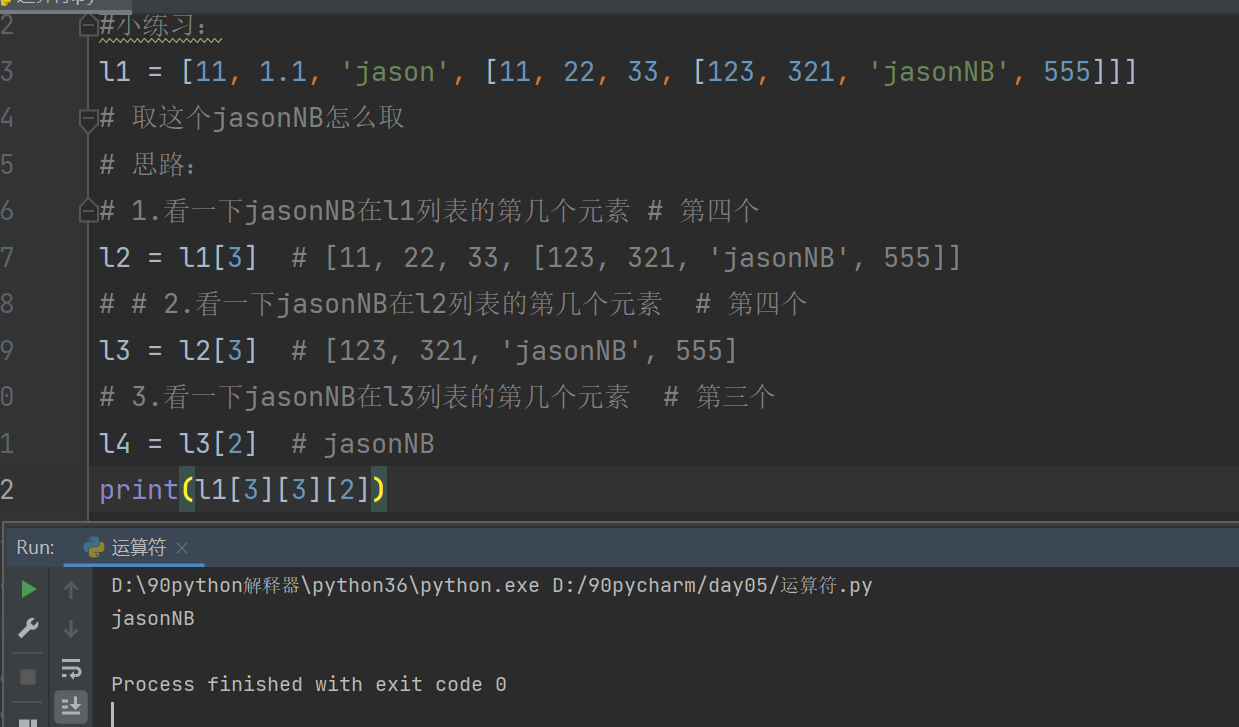
L1 = [11, 1.1, 'jason', [11, 22, 33, [123, 321, 'jasonNB', 555]]]
# 这个jasonNB怎么取
# 思路:
# 1.看一下jasonNB在l1列表的第几个元素 # 第四个
L2 = L1[3] # [11, 22, 33, [123, 321, 'jasonNB', 555]]
# 2.看一下jasonNB在l2列表的第几个元素 # 第四个
L3 =L2[3] # [123, 321, 'jasonNB', 555]
# 3.看一下jasonNB在l3列表的第几个元素 # 第三个
L4 = [l3[2]] # jasonNB
print(L1[3][3][2]
5.字典dict
作用:能够更加精确的存储数据
定义:大括号括起来的内容,内部可以存放多个元素,元素之间用逗号隔开,采用K:V键值对的形式
K是对V的描述性质的信息(一般是字符串)
V是真正的数据,相当于是变量的值,可以是任意类型的数据。
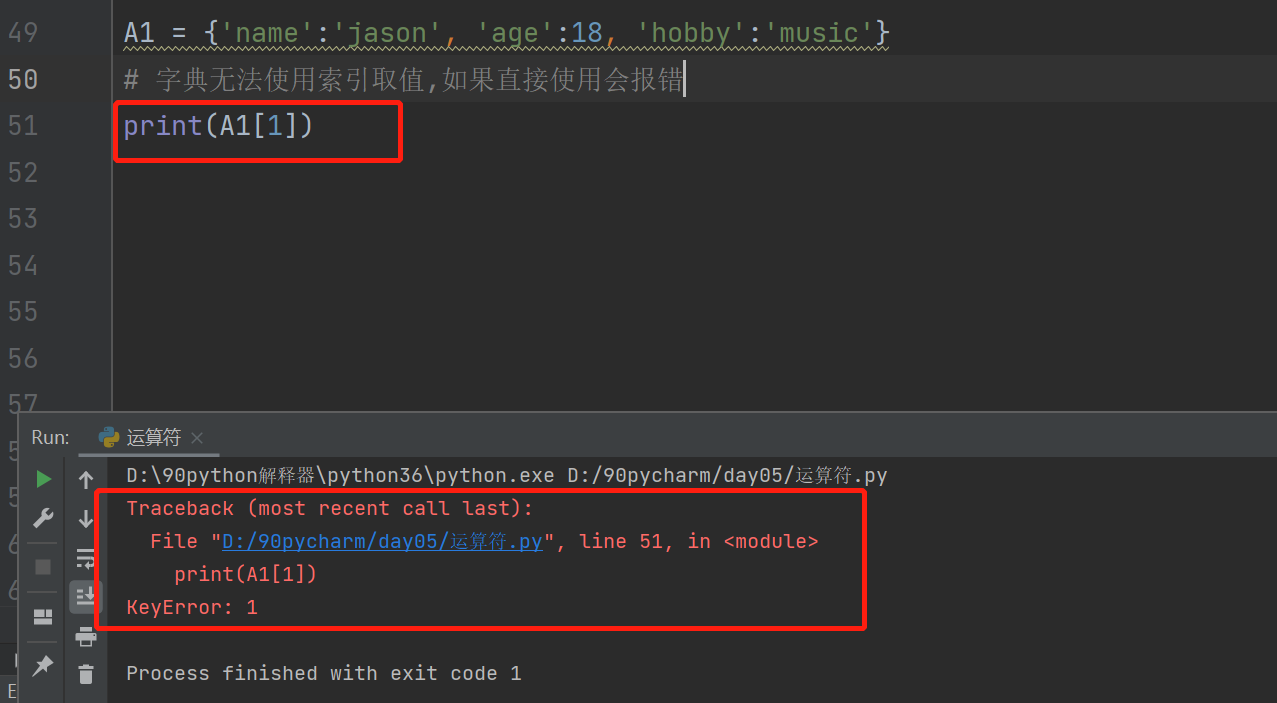
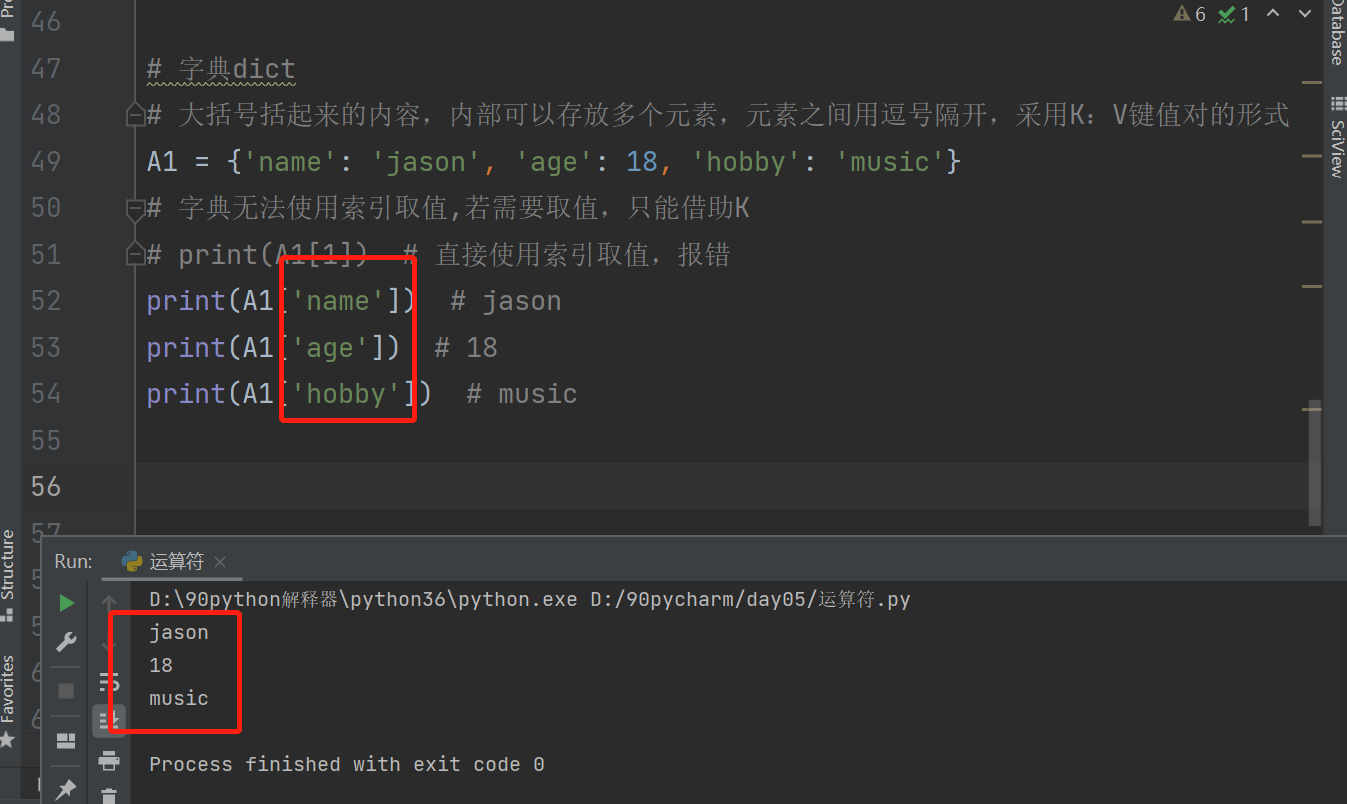
A1 = {'name':'jason', 'age':18, 'hobby':'music'}
# 字典无法直接使用索引取值,如果需要取值,只能借助K,比如需要取jason:
# print(A1[1]) # 直接使用索引取值,报错
# print(A1['name']) # jason #通过K值'name'来取值
#小练习:
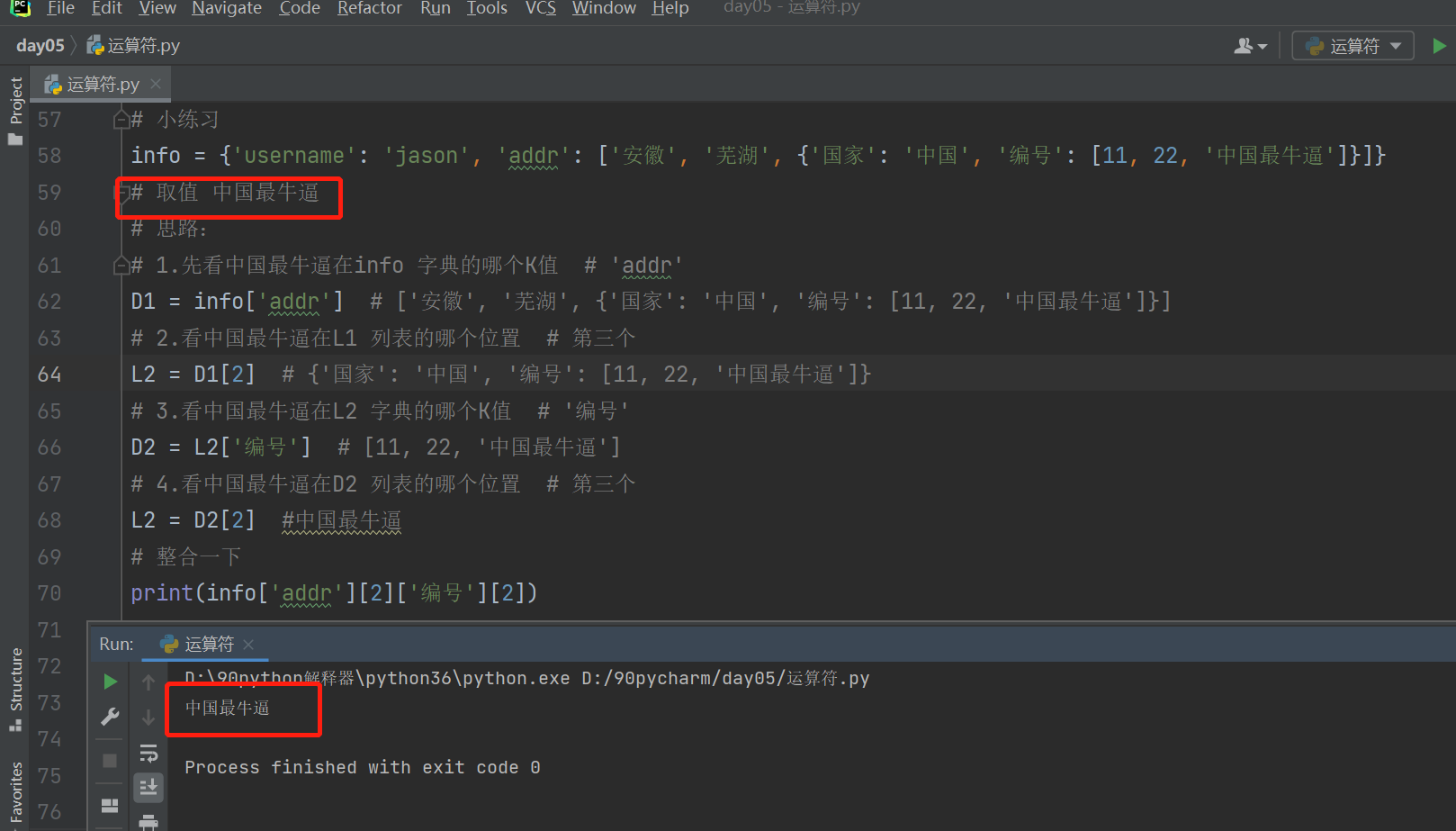
info = {'username': 'jason', 'addr': ['安徽', '芜湖', {'国家': '中国', '编号': [11, 22, '中国最牛逼']}]}
# 如何取值 中国最牛逼?
# 思路:
# 1.先看中国最牛逼在info 字典的哪个K值 # 'addr'
D1 = info['addr'] # ['安徽', '芜湖', {'国家': '中国', '编号': [11, 22, '中国最牛逼']}]
# 2.看中国最牛逼在L1 列表的哪个位置 # 第三个
L2 = D1[2] # {'国家': '中国', '编号': [11, 22, '中国最牛逼']}
# 3.看中国最牛逼在L2 字典的哪个K值 # '编号'
D2 = L2['编号'] # [11, 22, '中国最牛逼']
# 4.看中国最牛逼在D2 列表的哪个位置 # 第三个
L2 = D2[2] #中国最牛逼
# 整合一下
print(info['addr'][2]['编号'][2])
6.布尔值bool
作用:用于判断事物的对错,是否可行等
定义:只有两种状态:
True :对的 正确的 可行的
False :错误 不可行的
布尔值的变量命名一般是is开头
is_right = True
is_delete = False
is_alive = True
在Python中所有的数据类型都可以转化成布尔值:
False有以下情况:0, None, ' ', [ ], { }(空字符串、空列表、空字典)
Ture:除了以上False 的情况外,其他的都是
普及一下,现实生活中的数据存储与销户,其实很大概率上并没有删除数据,而是修改了数据的某个唯一标识,然后通过代码筛选过滤掉了。
7.元组tuple
作用:与列表几乎一致,可以看成是不变的列表
定义:小括号括起来的内容,内部可以存放多个元素,元素之间用逗号隔开,元素的数据类型有限制,元素不支持修改
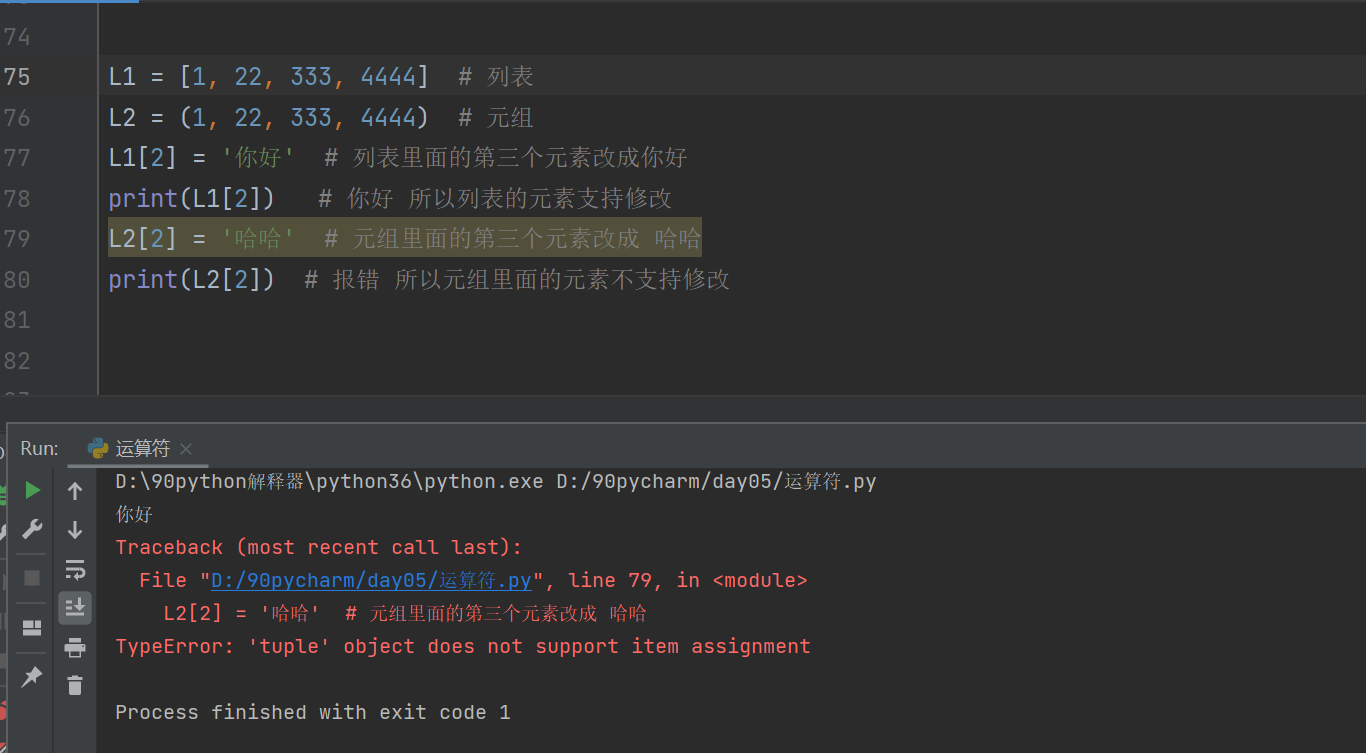
L1 = (1, 22, 333, 4444)
举例子看一下:
L1 = [1, 22, 333, 4444] # 列表
L2 = (1, 22, 333, 4444) # 元组
L1[2] = '你好' # 列表里面的第三个元素改成你好
print(L1[2]) # 你好 所以列表的元素支持修改
L2[2] = '哈哈' # 元组里面的第三个元素改成 哈哈
print(L2[2]) # 报错 所以元组里面的元素不支持修改
8.集合set
作用:去重和关系运算
定义:用大括号括起来,内部可以存放多个元素,元素之前用逗号隔开,不是K:V值键对的形式,集合里面的数据默认不可变
A1 = {11, 22, 33, 44}
如何定义空值呢?固定搭配:set()
res3 = {}
print(type(res3)) # <class 'dict'>
print(type({11, 22, 333})) # <class 'set'>
res4 = set()
print(res4) # set()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号