项目部署Django+celery+redis
celery介绍
1、celery应用举例
1、Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理,
如果你的业务场景中需要用到异步任务,就可以考虑使用celery
2、你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,
你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情
3、Celery 在执行任务时需要通过一个消息中间件来接收和发送任务消息,以及存储任务结果, 一般使用rabbitMQ or Redis
2、Celery有以下优点
1、简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
2、高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
3、快速:一个单进程的celery每分钟可处理上百万个任务
4、灵活: 几乎celery的各个组件都可以被扩展及自定制
3、Celery基本工作流程图

user:用户程序,用于告知celery去执行一个任务。
broker: 存放任务(依赖RabbitMQ或Redis,进行存储)
worker:执行任务
4、Celery 特性
1)方便查看定时任务的执行情况, 如 是否成功, 当前状态, 执行任务花费的时间等.
2)可选 多进程, Eventlet 和 Gevent 三种模型并发执行.
3)Celery 是语言无关的.它提供了python 等常见语言的接口支持.
celery 组件
1、Celery 扮演生产者和消费者的角色
Celery Beat : 任务调度器. Beat 进程会读取配置文件的内容, 周期性的将配置中到期需要执行的任务发送给任务队列.
Celery Worker : 执行任务的消费者, 通常会在多台服务器运行多个消费者, 提高运行效率.
Broker : 消息代理, 队列本身. 也称为消息中间件. 接受任务生产者发送过来的任务消息, 存进队列再按序分发给任务消费方(通常是消息队列或者数据库).
Producer : 任务生产者. 调用 Celery API , 函数或者装饰器, 而产生任务并交给任务队列处理的都是任务生产者.
Result Backend : 任务处理完成之后保存状态信息和结果, 以供查询.
2、celery架构图
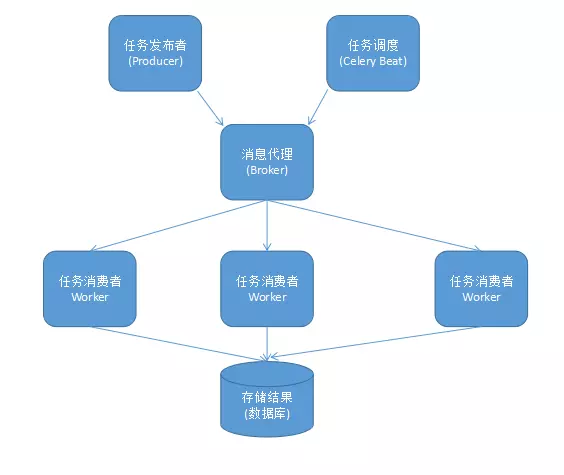
3. 产生任务的方式
1) 发布者发布任务(WEB 应用)
2) 任务调度按期发布任务(定时任务)
4. celery 依赖三个库: 这三个库, 都由 Celery 的开发者开发和维护.
billiard : 基于 Python2.7 的 multisuprocessing 而改进的库, 主要用来提高性能和稳定性.
librabbitmp : C 语言实现的 Python 客户端
kombu : Celery 自带的用来收发消息的库, 提供了符合 Python 语言习惯的, 使用 AMQP 协议的高级借口.
安装相关包与管理命令
1、安装相关软件包

pip3 install Django==2.0.4 pip3 install celery==4.3.0 pip3 install redis==3.2.1 pip3 install django-celery==3.1.17 pip3 install ipython==7.6.1 find ./ -type f | xargs sed -i 's/\r$//g' # 批量将当前文件夹下所有文件装换成unix格式
2、celery管理
celery multi start w1 w2 -A celery_pro -l info #一次性启动w1,w2两个worker
celery -A celery_pro status #查看当前有哪些worker在运行
celery multi stop w1 w2 -A celery_pro #停止w1,w2两个worker
celery multi start celery_test -A celery_test -l debug --autoscale=50,5 # celery并发数:最多50个,最少5个
ps auxww|grep "celery worker"|grep -v grep|awk '{print $2}'|xargs kill -9 # 关闭所有celery进程
3、django_celery_beat管理
celery -A celery_test beat -l info -S django #启动心跳任务
ps -ef | grep -E "celery -A celery_test beat" | grep -v grep| awk '{print $2}' | xargs kill -TERM &> /dev/null # 杀死心跳所有进程
安装相关包 与 管理命令
1、在Django中使用celery介绍(celery无法再windows下运行)
1)在Django中使用celery时,celery文件必须以tasks.py
2)Django会自动到每个APP中找tasks.py文件
2、创建一个Django项目celery_test,和app01
3、在与项目同名的目录下创建celery.py


# -*- coding: utf-8 -*- from __future__ import absolute_import import os from celery import Celery # 只要是想在自己的脚本中访问Django的数据库等文件就必须配置Django的环境变量 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_test.settings') # app名字 app = Celery('celery_test') # 配置celery class Config: BROKER_URL = 'redis://192.168.56.11:6379' CELERY_RESULT_BACKEND = 'redis://192.168.56.11:6379' app.config_from_object(Config) # 到各个APP里自动发现tasks.py文件 app.autodiscover_tasks() celery.py
4、在与项目同名的目录下的 init.py 文件中添加下面内容
# -*- coding:utf8 -*- from __future__ import absolute_import, unicode_literals # 告诉Django在启动时别忘了检测我的celery文件 from .celery import app as celery_ap __all__ = ['celery_app']
5、创建app01/tasks.py文件
# -*- coding:utf8 -*- from __future__ import absolute_import, unicode_literals from celery import shared_task import time # 这里不再使用@app.task,而是用@shared_task,是指定可以在其他APP中也可以调用这个任务 @shared_task def add(x,y): print('########## running add #####################') return x + y @shared_task def minus(x,y): time.sleep(30) print('########## running minus #####################') return x - y
6、将celery_test这个Django项目拷贝到centos7.3的django_test文件夹中
7、保证启动了redis-server
8、启动一个celery的worker
celery multi start w1 w2 -A celery_pro -l info #一次性启动w1,w2两个worker
celery -A celery_pro status #查看当前有哪些worker在运行
celery multi stop w1 w2 -A celery_pro #停止w1,w2两个worker
celery multi start celery_test -A celery_test -l debug --autoscale=50,5 # celery并发数:最多50个,最少5个
ps auxww|grep "celery worker"|grep -v grep|awk '{print $2}'|xargs kill -9 # 关闭所有celery进程
9、测试celery
./manage.py shell import tasks t1 = tasks.minus.delay(5,3) t2 = tasks.add.delay(3,4) t1.get() t2.get()
1.5 在django中使用计划任务功能
1、在Django中使用celery的定时任务需要安装django-celery-beat
pip3 install django-celery-beat
2、在Django的settings中注册django_celery_beat
INSTALLED_APPS = (
...,
'django_celery_beat',
)
3、执行创建表命令
python3 manage.py makemigrations
python3 manage.py migrate
4、在与项目同名的目录下的celery.py中添加定时任务
# -*- coding: utf-8 -*- from __future__ import absolute_import import os from celery import Celery from celery.schedules import crontab from datetime import timedelta from kombu import Queue # 只要是想在自己的脚本中访问Django的数据库等文件就必须配置Django的环境变量 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_test.settings') # app名字 app = Celery('celery_test') # 配置celery class Config: BROKER_URL = 'redis://192.168.56.11:6379' # broker CELERY_RESULT_BACKEND = 'redis://192.168.56.11:6379' # backend CELERY_ACCEPT_CONTENT = ['application/json'] # 指定任务接受的内容类型(序列化) CELERY_TASK_SERIALIZER = 'json' # 任务的序列化方式 CELERY_RESULT_SERIALIZER = 'json' # 任务执行结果的序列化方式 CELERY_TIMEZONE = 'Asia/Shanghai' # 时区设置,计划任务需要,推荐 Asia/Shanghai ENABLE_UTC = False # 不使用UTC时区 CELERY_TASK_RESULT_EXPIRES = 60 * 60 # celery任务执行结果的超时时间 CELERY_ANNOTATIONS = {'*': {'rate_limit': '500/s'}} # CELERYD_PREFETCH_MULTIPLIER = 10 # 每次取任务的数量 CELERYD_MAX_TASKS_PER_CHILD = 16 # 每个worker执行了多少任务就会死掉,防止内存泄漏 app.config_from_object(Config) app.autodiscover_tasks() #crontab config app.conf.update( CELERYBEAT_SCHEDULE = { # 每隔3s执行一次add函数 'every-3-min-add': { 'task': 'app01.tasks.add', 'schedule': timedelta(seconds=10) }, # 每天下午15:420执行 'add-every-day-morning@14:50': { 'task': 'app01.tasks.minus', 'schedule': crontab(hour=19, minute=50, day_of_week='*/1'), }, }, ) # kombu : Celery 自带的用来收发消息的库, 提供了符合 Python 语言习惯的, 使用 AMQP 协议的高级接口 Queue('transient', routing_key='transient',delivery_mode=1)
5、app01/tasks.py
# -*- coding:utf8 -*- from __future__ import absolute_import, unicode_literals from celery import shared_task import time # 这里不再使用@app.task,而是用@shared_task,是指定可以在其他APP中也可以调用这个任务 @shared_task def add(): print('########## running add #####################') return 'add' @shared_task def minus(): time.sleep(30) print('########## running minus #####################') return 'minus'
6、管理命令
'''1、celery管理 '''
celery multi start celery_test -A celery_test -l debug --autoscale=50,5 # celery并发数:最多50个,最少5个
ps auxww|grep "celery worker"|grep -v grep|awk '{print $2}'|xargs kill -9 # 关闭所有celery进程
'''2、django-celery-beat心跳服务管理 '''
celery -A celery_test beat -l info -S django #启动心跳任务
ps -ef | grep -E "celery -A celery_test beat" | grep -v grep| awk '{print $2}' | xargs kill -TERM &> /dev/null # 杀死心跳所有进程
使用 Celery Once 来防止 Celery 重复执行同一个任务
1、产生重复执行原因
1. 当我们设置一个ETA(预估执行时间)比visibility_timeout(超时时间)长的任务时,会出现重复执行问题
2. 因为每过一次 visibility_timeout 时间,celery就会认为这个任务没被worker执行成功,重新分配给其它worker再执行
2、Celery Once解决方法
1. Celery Once 也是利用 Redis 加锁来实现,他的使用非常简单,参照 GitHub 的使用很快就能够用上。
2. Celery Once 在 Task 类基础上实现了 QueueOnce 类,该类提供了任务去重的功能
3. 所以在使用时,我们自己实现的方法需要将 QueueOnce 设置为 base
@celery.task(base=QueueOnce, once={'keys': ['a']})
def slow_add(a, b):
sleep(30)
return a + b
4. 后面的 once 参数表示,在遇到重复方法时的处理方式,默认 graceful 为 False,那样 Celery 会抛出 AlreadyQueued 异常,手动设置为 True,则静默处理。
5. 可以手动设置任务的 key,可以指定 keys 参数。
3、celery once使用
参考官方:https://github.com/cameronmaske/celery-once
#! /usr/bin/env python # -*- coding: utf-8 -*- '''第一步: 安装''' pip install -U celery_once '''第二步: 增加配置''' from celery import Celery from celery_once import QueueOnce from time import sleep celery = Celery('tasks', broker='amqp://guest@localhost//') celery.conf.ONCE = { 'backend': 'celery_once.backends.Redis', 'settings': { 'url': 'redis://localhost:6379/0', 'default_timeout': 60 * 60 } } '''第三步: 修改 delay 方法''' example.delay(10) # 修改为 result = example.apply_async(args=(10)) '''第四步: 修改 task 参数''' @celery.task(base=QueueOnce, once={'graceful': True, keys': ['a']}) def slow_add(a, b): sleep(30) return a + b # 参考官方:https://github.com/cameronmaske/celery-once
redis会丢失消息 RabbitMQ不会丢失消息的原因
1、redis丢失消息的原因
1. 用 Redis 作 broker 的话,任务会存在内存里面,如果 celery 进程要结束了,就会在临死之前把队列存进 Redis,下次启动时再从 Redis 读取。
2. 但是如果可见性超时时间过长在断电或者强制终止职程(Worker)的情况会“丢失“重新分配的任务。
3. 比如当 celery 被 kill -9 了,任务将无法存进 Redis,内存中的任务会丢失,或者任务太多导致celery出现异常。
2、RabbitMQ如何保证可靠消费
Redis: 没有相应的机制保证消息的消费,当消费者消费失败的时候,消息体丢失,需要手动处理
RabbitMQ: 具有消息消费确认,即使消费者消费失败,也会自动使消息体返回原队列,同时可全程持久化,保证消息体被正确消费

 浙公网安备 33010602011771号
浙公网安备 33010602011771号