

GIL全局解释器锁
一、什么是GIL
GIL并不是Python的特性,Python完全可以不依赖于GIL。GIL全称Global Interpreter Lock。它是在实现Python解析器(CPython)时所引入的一个概念。GIL无疑就是一把全局排他锁。
Python GIL其实是功能和性能之间权衡后的产物,它尤其存在的合理性,也有较难改变的客观因素。因为GIL的存在,只有IO Bound场景下得多线程会得到较好的性能,如果对并行计算性能较高的程序可以考虑把核心部分也成C模块,或者索性用其他语言实现
总结
1.GIL是Cpython解释器的特点
2.python同一个进程内的多个线程无法利用多核优势(不能并行但是可以并发)
3.同一个进程内的多个线程要想运行必须先抢GIL锁
4.所有的解释型语言几乎都无法实现同一个进程下的多个线程同时被运行
二、验证GIL的存在
from threading import Thread
import time
m = 100
def test():
global m
tmp = m
tmp -= 1
m = tmp
for i in range(100):
t = Thread(target=test)
t.start()
time.sleep(3) # 让子线程先运行完毕
print(m)
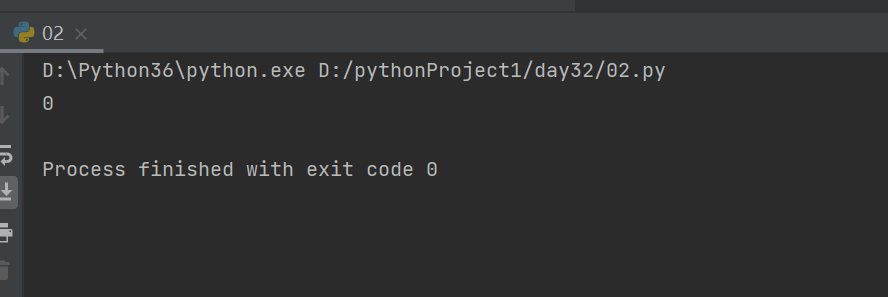
从结果为0可以得出,GIL确实存在,在Cpytho中并不会存在并行的情况。
三、死锁现象
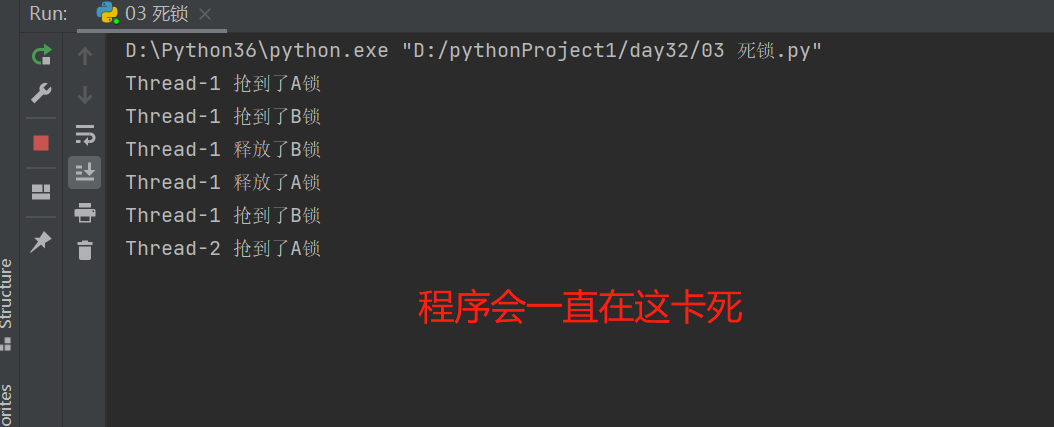
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading import Thread, Lock
import time
A = Lock()
B = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A.acquire()
print('%s 抢到了A锁' % self.name) # current_thread().name 获取线程名称
B.acquire()
print('%s 抢到了B锁' % self.name)
time.sleep(1)
B.release()
print('%s 释放了B锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
def func2(self):
B.acquire()
print('%s 抢到了B锁' % self.name)
A.acquire()
print('%s 抢到了A锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
B.release()
print('%s 释放了B锁' % self.name)
for i in range(10):
obj = MyThread()
obj.start()
四、在python中多线程有作用吗
例如有四个任务,每个任务耗时10s
任务分两种情况
① IO密集型(遇到IO情况就会保存进度切换任务,异步)
1.开设多个进程,耗时10s多
2.开设多个线程,耗时10s多,要比开设多个进程耗时时间短,因为开设线程不需要从内存中在开辟一段内存,拷贝代码
② 计算密集型(一直占用cpu,直至结束任务,同步)
1.开设多个进程,耗时10s多
2.开设多个线程,耗时40s多
# io密集型
from multiprocessing import Process
from threading import Thread
import threading
import os, time
def work():
time.sleep(2)
if __name__ == '__main__':
l = []
print(os.cpu_count()) # 本机为16核
start = time.time()
for i in range(4000):
# p=Process(target=work) #耗时49.25s多,大部分时间耗费在创建进程上
p = Thread(target=work) # 耗时2.32多
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print('run time is %s' % (stop - start))
# 计算密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
print(os.cpu_count()) # 本机为6核
start=time.time()
for i in range(6):
# p=Process(target=work) #耗时5.81s多
p=Thread(target=work) #耗时40.22s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
总结 :IO密集型
① 开设多进程没有太大的优势,还会消耗许多资源
② 开设多线程有优势,不需要消耗额外的资源,消耗的时间比多进程少一些
计算密集型
① 开设多进程可以利用多核优势,节省时间
② 开设多线程没有优势,耗时时间长

 浙公网安备 33010602011771号
浙公网安备 33010602011771号