

linux常用文本处理命令
sort命令
sort命令的作用:
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
语法格式:
sort [参数] [文件]
参数说明
-n :按照数值的大小排序
-r :取反的顺序排序
-t :指定排序是所用的栏位分隔符
-k :指定某一列来排序
案例
将以下日期以天的大小从大到小进行排序

使用 -t 使用'-'进行分区,然后使用-k 发现天数是在第三区,在使用-n与-r参数进行数值从大到小惊醒排序

uniq命令
uniq命令的作用:
uniq命令用于去除文本当中连续重复的行列,如果是多个重复的行列,但是没有连续uniq命令就删除不了了
所以我们在使用uniq命令的同时会搭配sort命令一起使用
语法格式:
uniq [参数] [文件]
参数:
-c或--count :在每列旁边显示该行重复出现的次数。
-d或--repeated :只显示重复出现的行列。
-u或--unique :只显示没有重复的行列。
案例
将以下文件内容中重复的内容去除
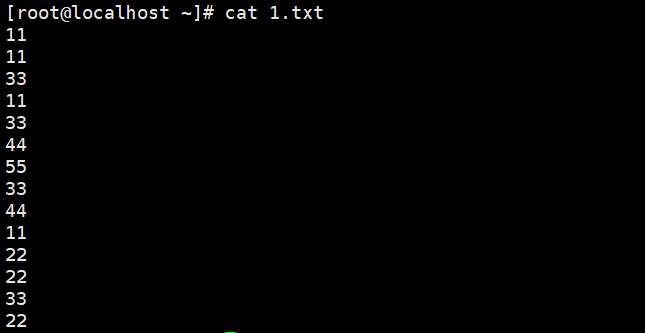
如果单纯的使用uniq命令删除重复的内容,我们会发现还是会存在相同内容的行列,
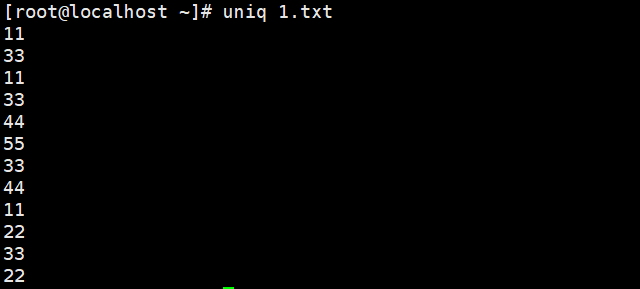
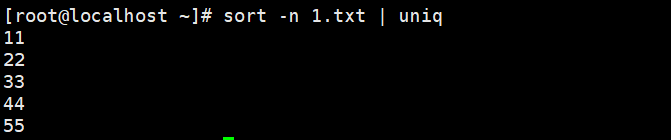
这时候我们就需要搭配sort排序命令来将重复的内容进行排序然后去重了
cut命令
cut命令的作用:
cut命令主要是用来显示文件内容中指定的部分
语法格式:
cut [参数] [文件]
参数说明
-d :自定义分隔符,默认为制表符‘TAB’
-f :显示指定字段的内容,需要与-d一起使用
-c :以字符为单位分割,仅显示字符范围内的内容
案例1
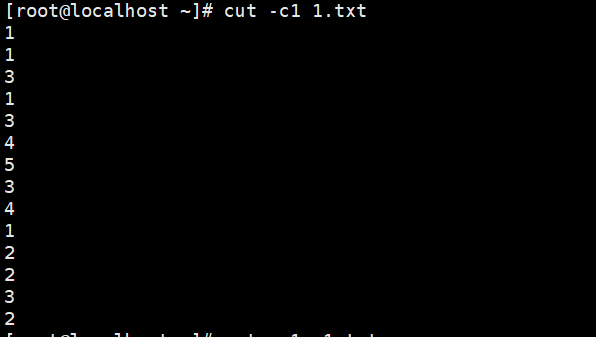
仅显示以下第一列的内容
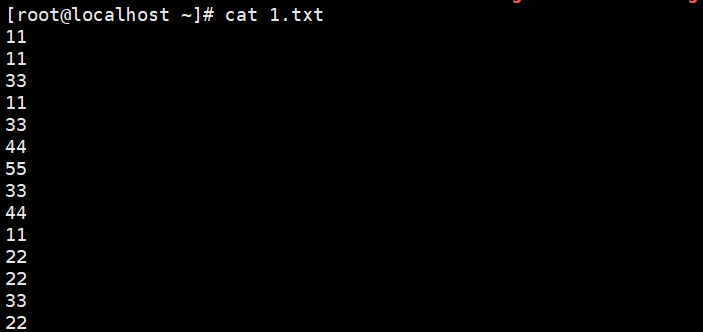
使用cut -c1 1.txt
案例2
将以下学生信息的成绩内容打印出来
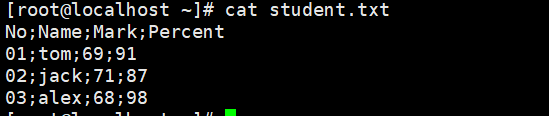
我们可以看到该每个内容都有分隔符;所以我们可以使用-d 与-f参数来取出内容

tr命令
tr命令的作用:
tr的英文全称是“ transform ”,即转换的意思。该命令的作用是一种可将字符进行替换、压缩、删除,他可以将一组字符转换成另一组字符
语法格式:
tr [参数] [字符1] [字符2] < [文件]
参数
没有参数:将字符1替换成字符2
-d :删除字符1中出现所有字符
案例1
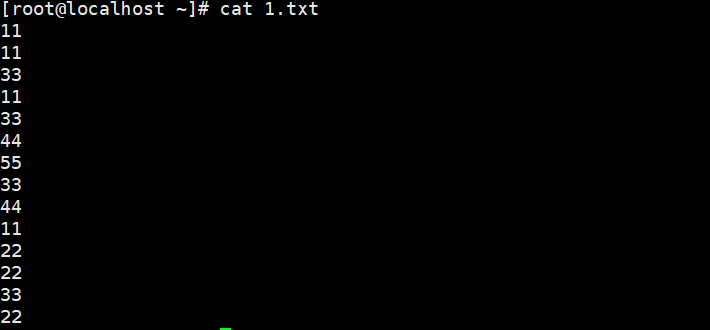
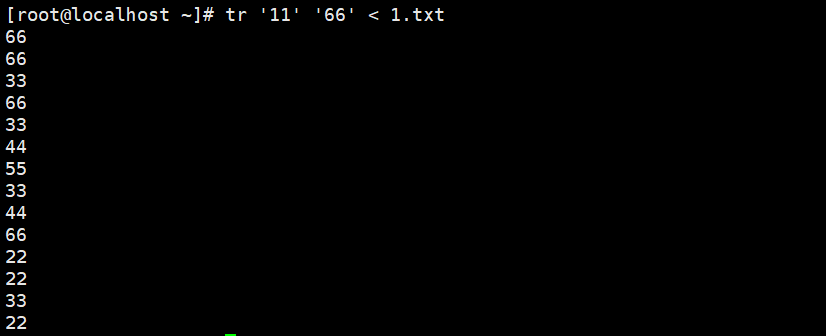
将文件里所有的11替换成6
案例2
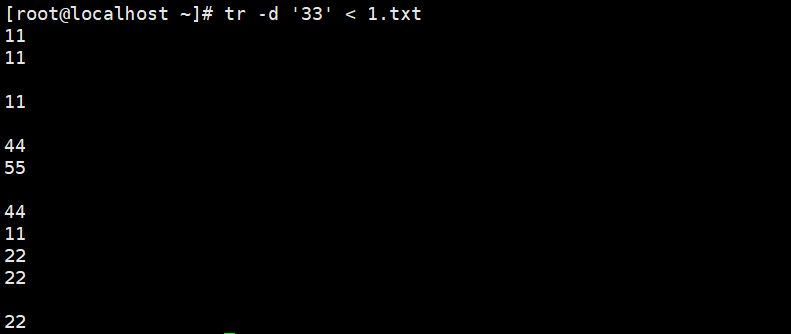
将文件里所有的33删除
使用 tr -d 命令可以删除文本里的内容
wc命令
wc命令的作用:
wc命令主要用于统计指定文件中的字节数、字数、行数,并将统计结果显示输出。
语法格式:
wc [参数] [文件]
参数
-w :统计指定文件的字数并显示 (一个字被定义为由空白、跳格或换行字符分隔的字符串)
-l : 统计指定文件的行数并显示
-c:统计指定文件的字节数并显示
没有参数:显示指定文件的总统计数
案例
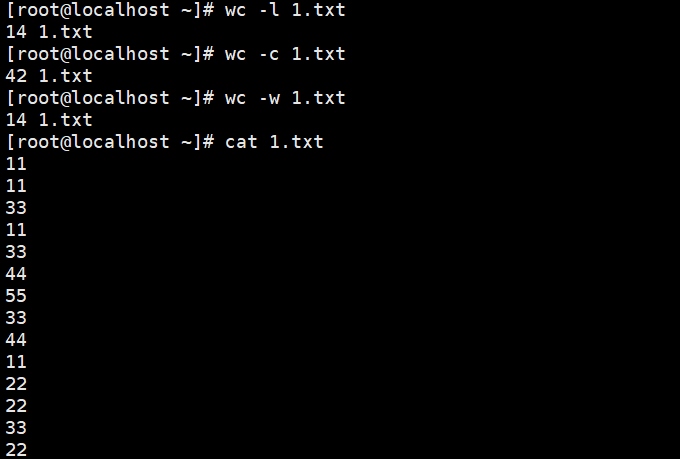
统计1.txt文件的字数,行数,字节数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号