

python内置模块
一、re模块
基本操作方法
import re
s = 'abacbacbd'
# 第一个参数填写正则表达式,第二个参数填写待匹配的文本 根据正则筛选符合条件的数据形成一个列表 如果没有找到则返回一个空列表
res = re.findall('a', s)
print(res) # ['a', 'a', 'a']
res1 = re.findall('f', s)
print(res1) # []
# search()函数会在整个字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
res2 = re.search('a', s)
print(res2) # <_sre.SRE_Match object; span=(0, 1), match='a'> 返回一个结果对象
print(res2.group()) # a 使用group可以取出结果
res3 = re.search('f', s)
print(res3) # None
print(res3.group()) # 报错
# match()函数只检测字符串开头位置是否匹配,匹配成功才会返回结果,否则返回None
res4 = re.match('a',s)
print(res4) # 返回一个结果对象
print(res4.group()) # a
res5 = re.match('b',s)
print(res5) # 返回一个None
print(res5.group()) # 报错
其他方法
import re
s = 'abacbacbd'
res = re.split('[ab]', s, 2) # 先按 'a'切割得到'','bacbacbd' 再按'b'切割得到'','','acbacbd',2是切割次数,不填默认按照条件切完
print(res) # ['', '', 'acbacbd']
s1 = 'aba564cbacbd'
res1 = re.sub('\d', 'H', s1, 1) # 按照正则将s1中数字替换成H 也可以在最后面添加可以替换的次数 不填默认全换
print(res1) # abaH64cbacbd
res2 = re.subn('\d','H',s1) #按照正则将s1中数字替换成H 也可以在最后面添加可以替换的次数 不填默认全换
print(res2) # ('abaHHHcbacbd', 3) 以元组的形式返回一个结果,后面的是替换的次数
常用方法
import re
regexp_obj = re.compile('\d+') # 将正则表达式编译成正则表达式对象 方便重复使用该正则
res = regexp_obj.search('absd213j1hjj213jk')
res1 = regexp_obj.match('123hhkj2h1j3123')
res2 = regexp_obj.findall('1213k1j2jhj21j3123hh')
print(res, res1, res2) # <_sre.SRE_Match object; span=(4, 7), match='213'> <_sre.SRE_Match object; span=(0, 3), match='123'> ['1213', '1', '2', '21', '3123']
res = re.finditer('\d+','ashdklah21h23kj12jk3klj112312121kl131') # 将满足正则条件的放入迭代器中
print([i.group() for i in res]) # ['21', '23', '12', '3', '112312121', '131']
分组优先机制
import re
res = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','110105199812067023')
print(res)
print(res.group()) # 110105199812067023
print(res.group(1)) # 10105199812067
print(res.group(2)) # 023
print(res.group(3)) # 报错
# group()里面填数字就是拿括号括起来的值,从左到右,没有了还拿就会报错
# 无名分组
# findall针对分组优先展示
res = re.findall("^[1-9]\d{14}(\d{2}[0-9x])?$",'110105199812067023')
print(res) # ['023']
# 取消分组优先展示 在分组里面填写一个?:来路取消分组
res1 = re.findall("^[1-9](?:\d{14})(?:\d{2}[0-9x])?$",'110105199812067023')
print(res1) # ['110105199812067023']
# 有名分组
# 可以在分组里面填写?P<名字>来给分组起名
res = re.search("^[1-9](?P<H>\d{14})(?P<J>\d{2}[0-9x])?$",'110105199812067023')
print(res.group(1)) # 按照索引取值 10105199812067
print(res.group('H')) # 按照名字取值 10105199812067
print(res.group('J')) # # 按照名字取值 023
二、collections模块
该模块内部提供了一些高阶数据类型
具名元组(namedtuple)
具名元组(namedtuple) 是 python 标准库 collections 中的工厂函数。
它接受两个参数,第一个参数表示类的名称,第二个参数是类的字段名。
后者可以是可迭代对象,
也可以是空格隔开的字符串。然后,我们通过一串参数的形式将参数传递到构造函数中。这样,我们既可以通过字段名访问元素,也可以用索引访问元素。
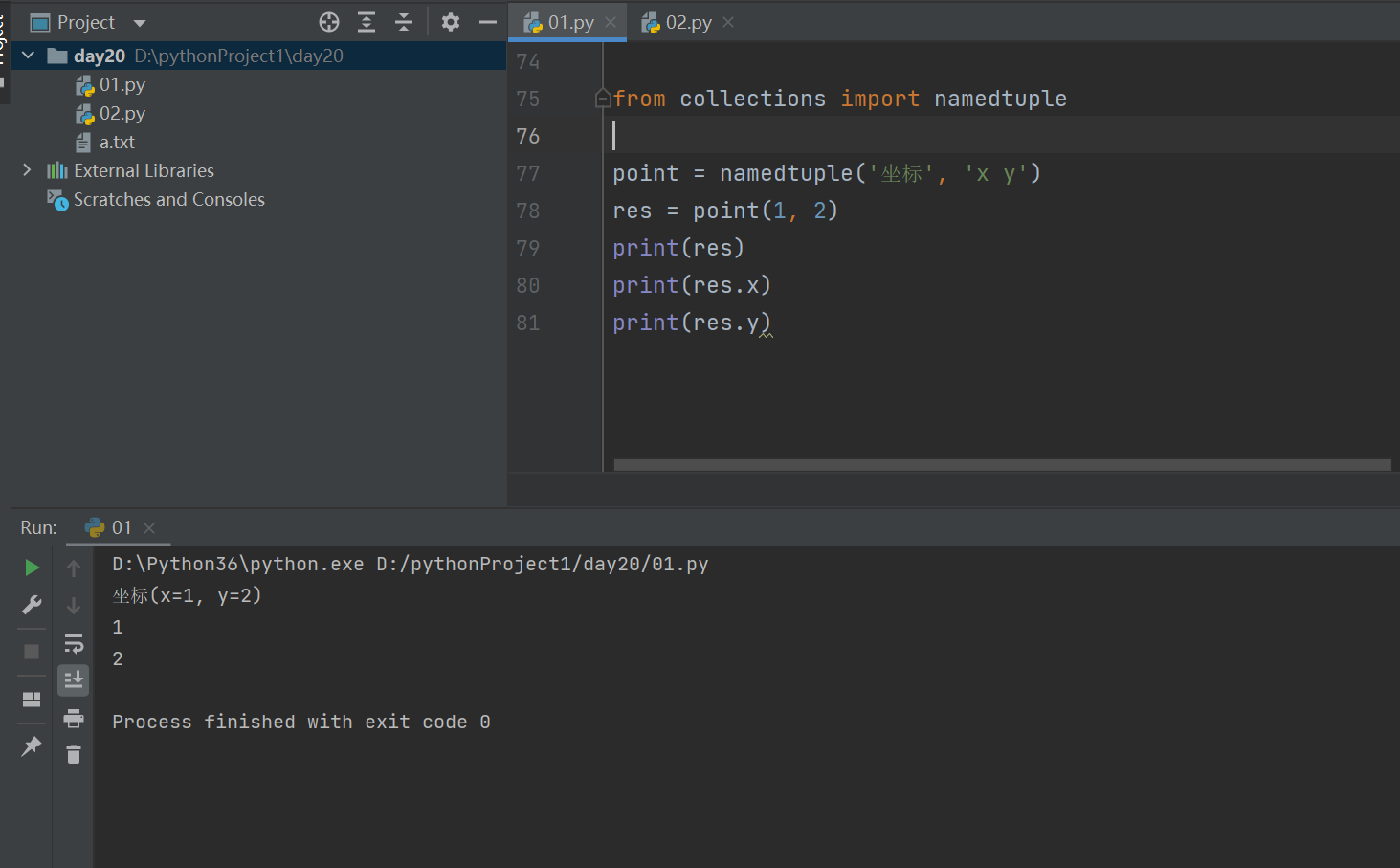
from collections import namedtuple
point = namedtuple('坐标', 'x y')
res = point(1, 2)
print(res)
print(res.x)
print(res.y)
双端队列(deque)
# 队列模块
import queue # 内置队列模块:FIFO
# 初始化队列
# q = queue.Queue()
# 往队列中添加元素
# q.put('first')
# q.put('second')
# q.put('third')
# 从队列中获取元素
# print(q.get())
# print(q.get())
# print(q.get())
# print(q.get()) # 值去没了就会原地等待
# 双端队列模块
from collections import deque
q = deque([11,22,33])
q.append(44) # 从右边添加
q.appendleft(55) # 从左边添加
print(q.pop()) # 从右边取值
print(q.popleft()) # 从做边取值
有序字典(OrderedDict)
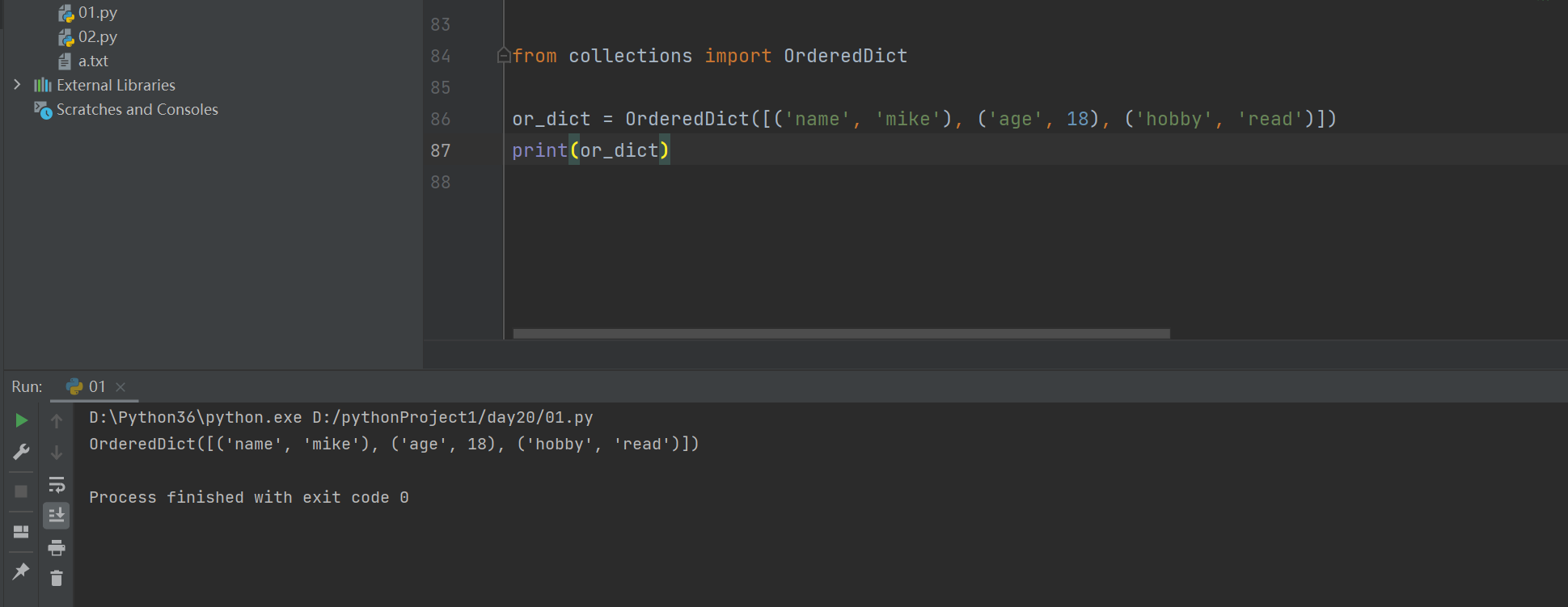
字典本身是无序的,使用OrderedDict可以使字典变成有序的
from collections import OrderedDict
or_dict = OrderedDict([('name','mike'), ('age',18), ('hobby','read')])
print(or_dict)
默认字典(defaultdict)
默认字典的构造函数接受一个工厂函数default_factory作为参数,可以将一个类型名看做是一个工厂函数,比如list,tuple,str
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>60:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
print(my_dict)
计数器(Counter)
Counter可以计数字符出现的次数,然后将字符和出现的次数的数据存入字典中
from collections import Counter
s = 'alkdsjklajdslkajdkljzxklcj'
res = Counter(s)
print(res) # Counter({'l': 5, 'k': 5, 'j': 5, 'a': 3, 'd': 3, 's': 2, 'z': 1, 'x': 1, 'c': 1})

三、time模块
时间的三种表现模式:
1.时间戳
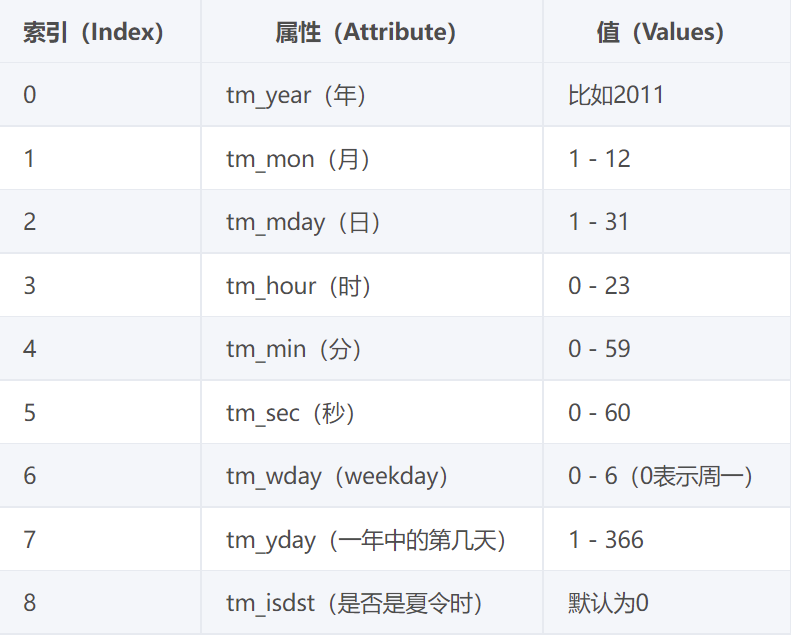
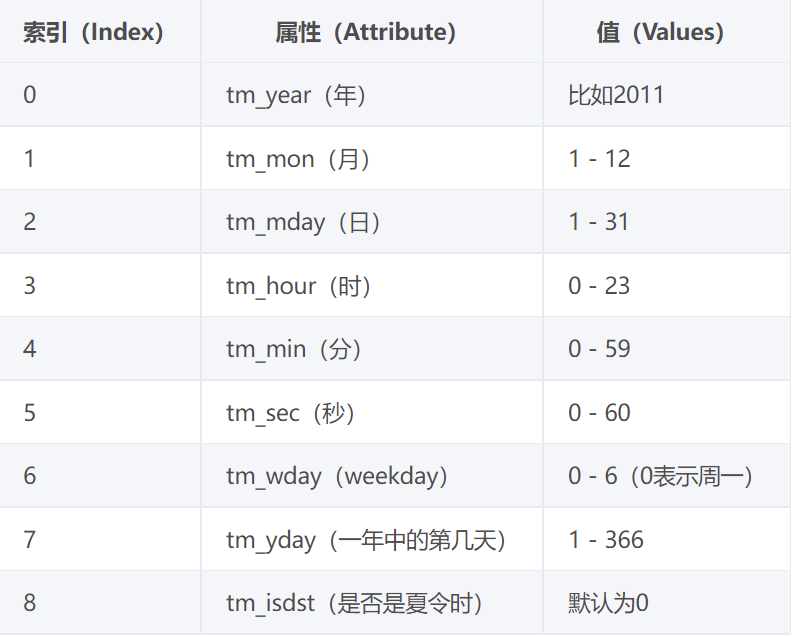
2.结构化时间(一般是给计算机看的)
3.格式化时间(一般是给给人看)
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
格式转换

import time
time.sleep(5) # 阻塞括号中的秒数
print(time.time()) # 时间戳
print(time.localtime()) # 结构化当地的时间
print(time.gmtime()) # 结构化uc时间
print(time.strftime('%Y-%m-%d-%H-%M-%S')) # 格式化时间
四、datetime模块
import datetime res = datetime.date.today() # 年月日 2021-11-25 print(res) #2021-11-25 print(res.year) #2021 print(res.month) #11 print(res.day) #25 res1 = datetime.datetime.today() # 年月日时分秒 2021-11-25 19:08:59.779221 print(res1) #2021-11-25 19:13:29.968774 print(res1.year) #2021 print(res1.month) #11 print(res1.day) #25 print(res1.hour) #19 print(res1.minute) #13 print(res1.second) #29 print(res.weekday()) #3 获取星期(weekday星期是0-6) 0表示周一 print(res.isoweekday()) #4 获取星期(weekday星期是1-7) 1表示周一
时间差(timedelta)
import datetime
now_time = datetime.datetime.today() tel_time = datetime.timedelta(5) print(now_time-tel_time) # 五天前的日期 2021-11-20 19:22:04.084645 print(now_time+tel_time) # 五天后的日期 2021-11-30 19:22:04.084645 """ 日期对象 = 日期对象 +/- timedelta对象 timedelta对象 = 日期对象 +/- 日期对象 """

 浙公网安备 33010602011771号
浙公网安备 33010602011771号