

正则表达式
一、什么是正则表达式
利用一些特殊符号来筛选出字符串中负符合条件的数据
二、字符组
用中括号括起来,里面填写需要的字符,会返回满足条件的字符,字符组默认单个单个字符匹配
[0123456789] # 匹配0到9任意一个数字 可以简写为[0-9]
同理[a-z],[A-Z] # 匹配a到z和A到Z的其中任意一个字母
[0-9a-zA-Z] # 匹配0到9、a到z、A到Z其中的任意一个字符
三、特殊符号
. # 匹配换行符以外所有字符 \d # 匹配数字 ^ # 匹配字符串开头 $ # 匹配字符串结尾 # ^和$可以精确限制查找的数据 a|b 匹配a或者b () #匹配括号内的表达式也表示一个组(不会影响正则表达式的匹配单纯的分组而已) [...] # 匹配字符组中的字符 [^...] # 匹配除了字符组中字符的所有字符
四、量词
1.量词必须搭配字符组、特殊符号或者其他字符使用,单独不能使用
2.量词只能影响前面的一个表达式(ab* # 只影响b)
3.字符组、特殊符号或者其他字符没有量词时都是单个单个匹配
* # 重复零次或者更多次
+ # 重复一次或者更多次
? # 重复零次或者一次
{n} # 重复n次
{n,} # 重复n次或更多次
{n,m} # 重复n次到m次
ps:正则表达式中量词默认都是'贪婪匹配'
五、贪婪匹配与非贪婪匹配
1.什么是正则表达式的贪婪与非贪婪匹配
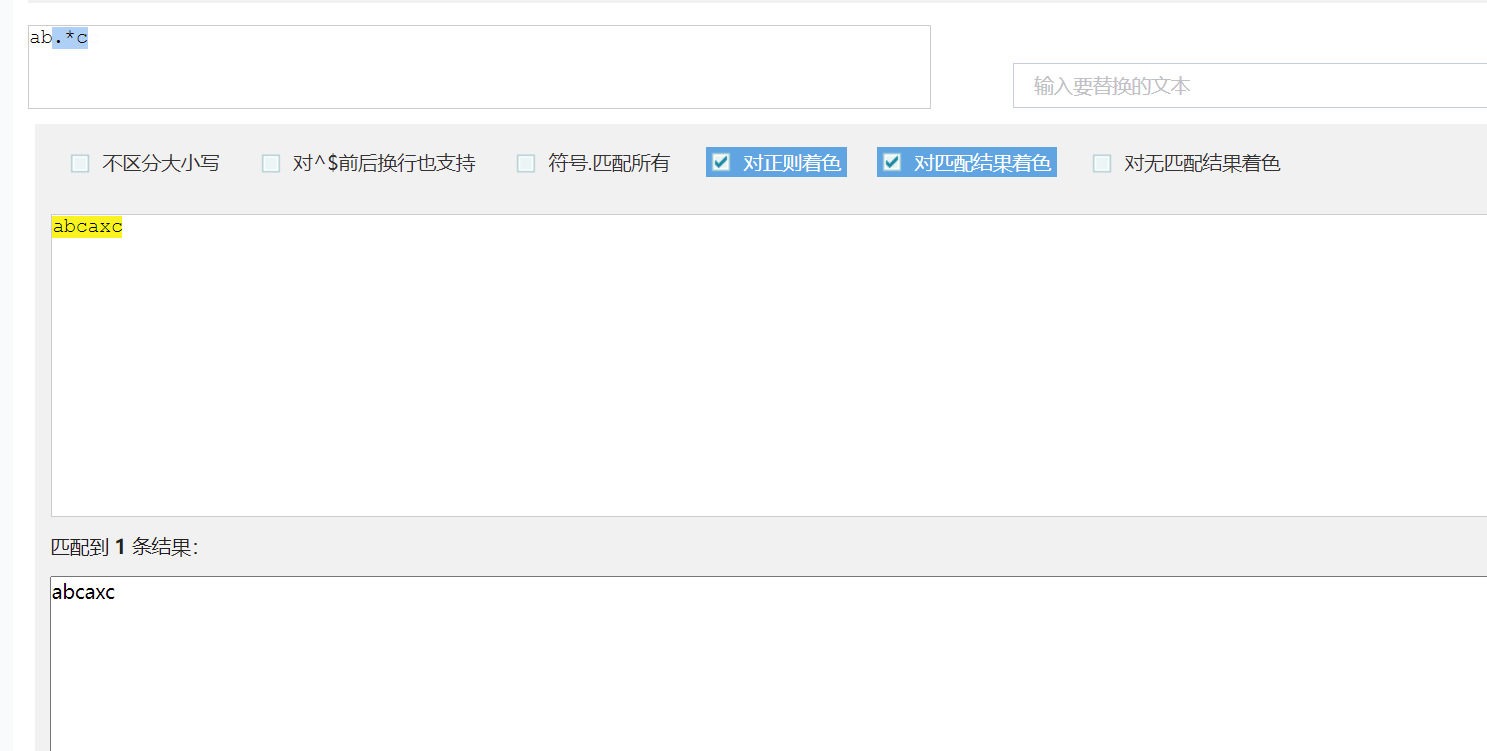
如:String str="abcaxc";
使用贪婪模式 p="ab.*c";
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如下图使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab.*c)。
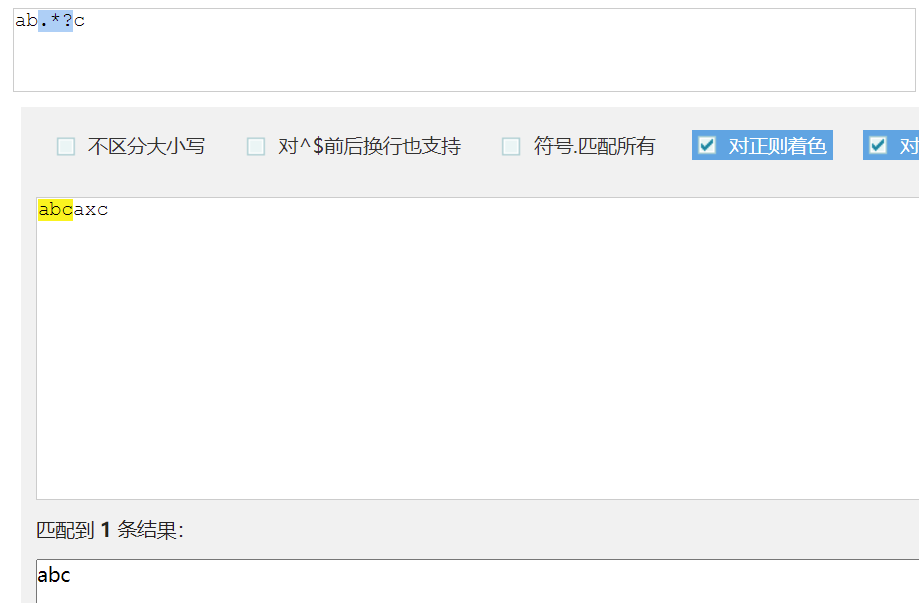
使用非贪婪模式 p="ab.*?c";
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。如下图使用模式p匹配字符串str,结果就是匹配到:abc(ab.*c)。
2.编程中如何区分两种模式
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
六、取消转义
在原生的正则表达式中使用\取消转义(每个\取消一个字符的转义)
在python中我们可以在前面加一个r来取消转义(也可以使用\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号