

文件处理
一、文件操作方法
1.read读系列
with open(r'文件路径',’r‘,encoding = 'utf8') as f : #f是变量名
1.1 print(f.read()) # 一次性读取文件内所有内容
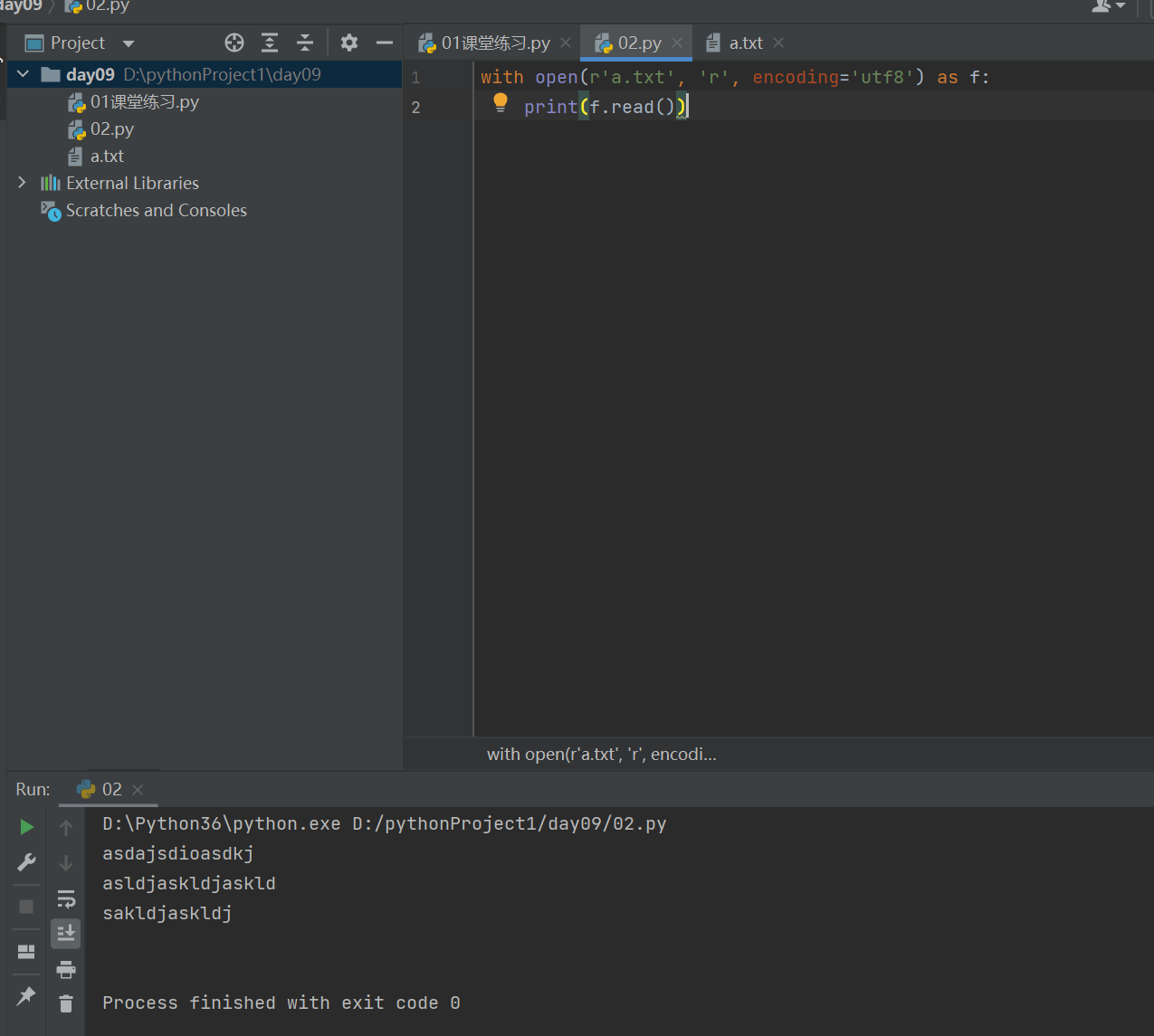
优化操作:
该方法在读取大文件时,可能会造成内存溢出的情况,解决此问题的方法就是逐行读取文件内容
可以使用 for循环来读取文件,就相当于一行一行读取文件内容
for line in f:
涉及到多行文件内容的情况下一般都是采用for循环读取文件内容
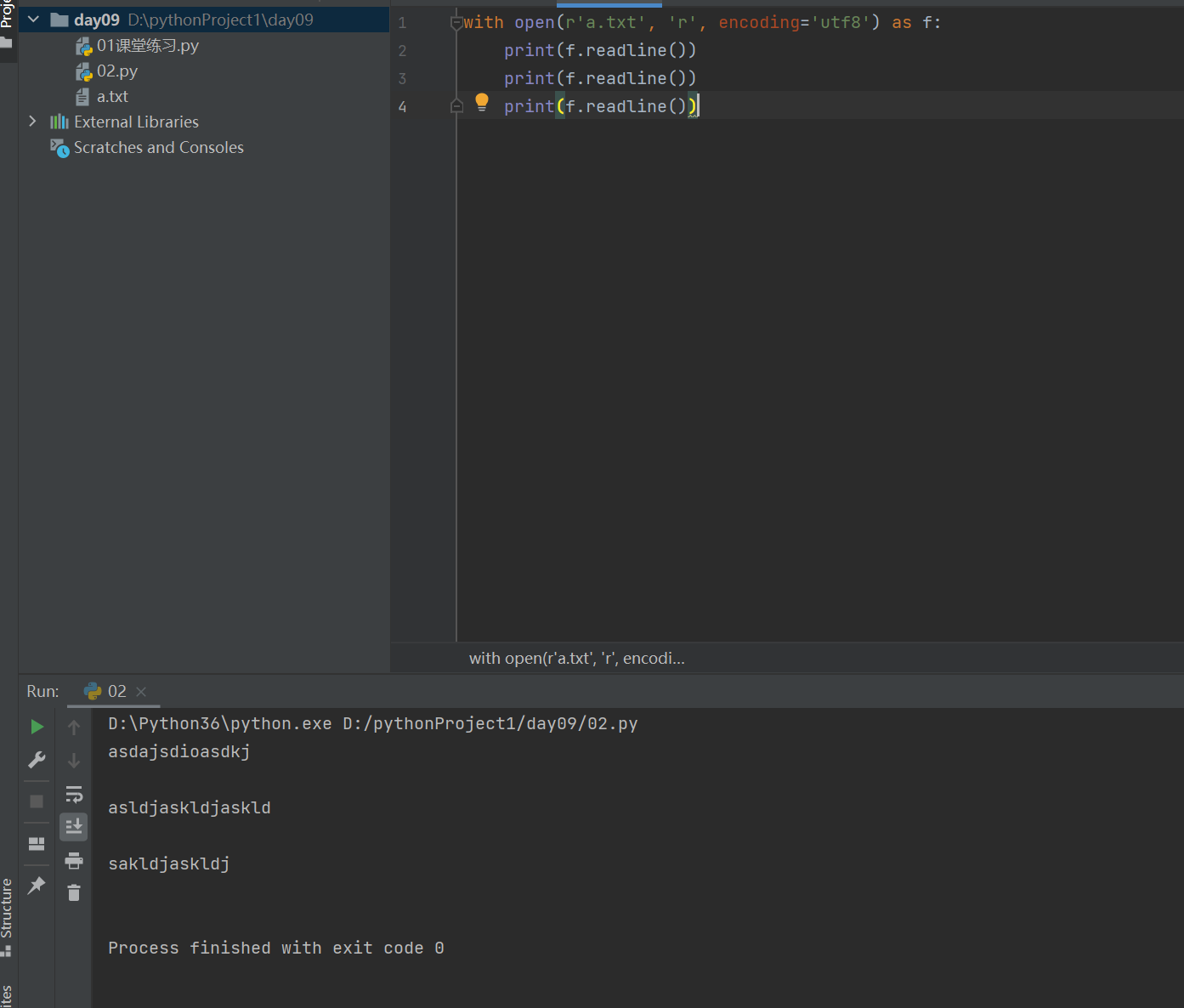
1.2 print(f.readline()) #每次读取文件内一行内容
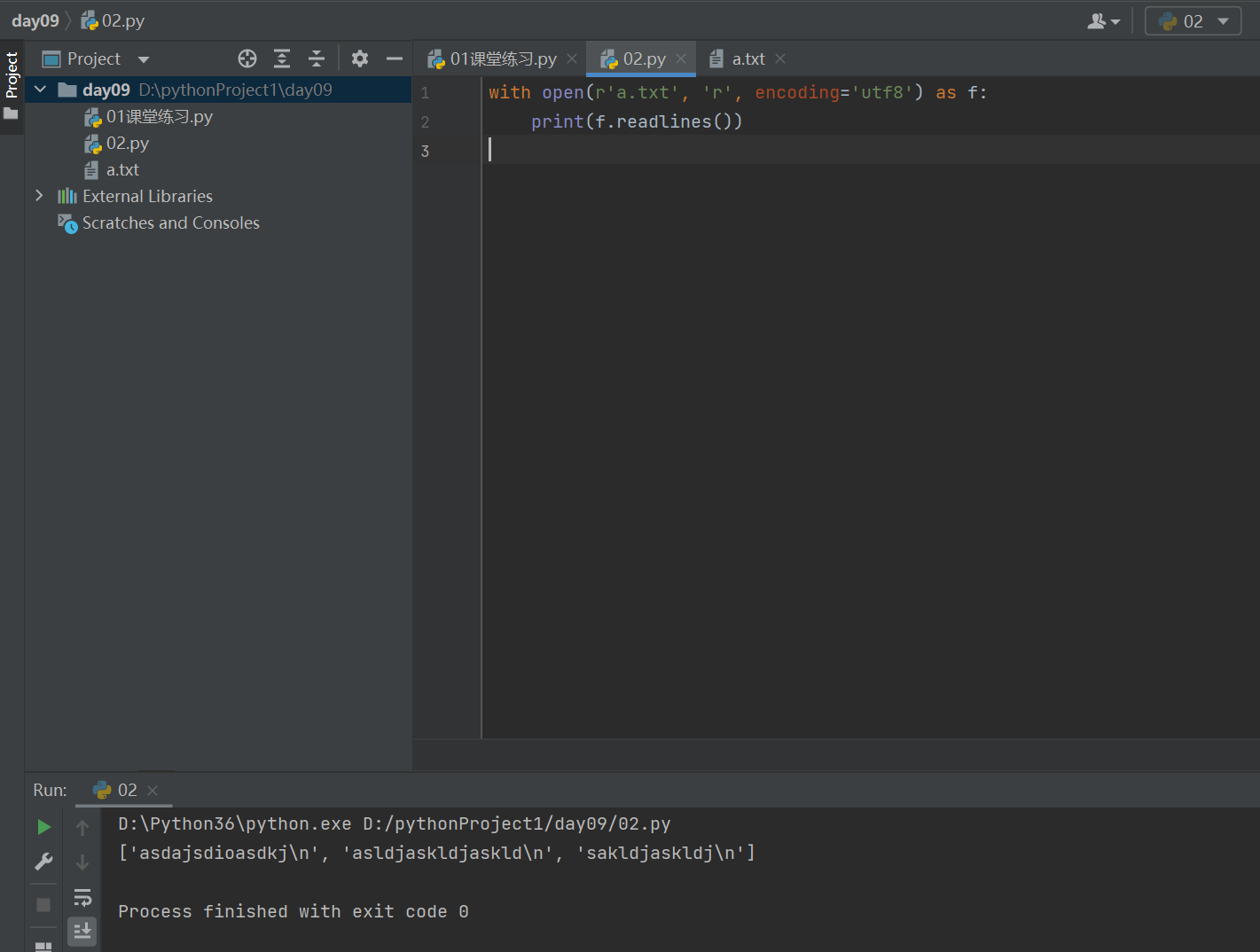
1.3 print(f.readlines()) #读取文件的所有内容,组织成列表,每个元素是文件每行的内容
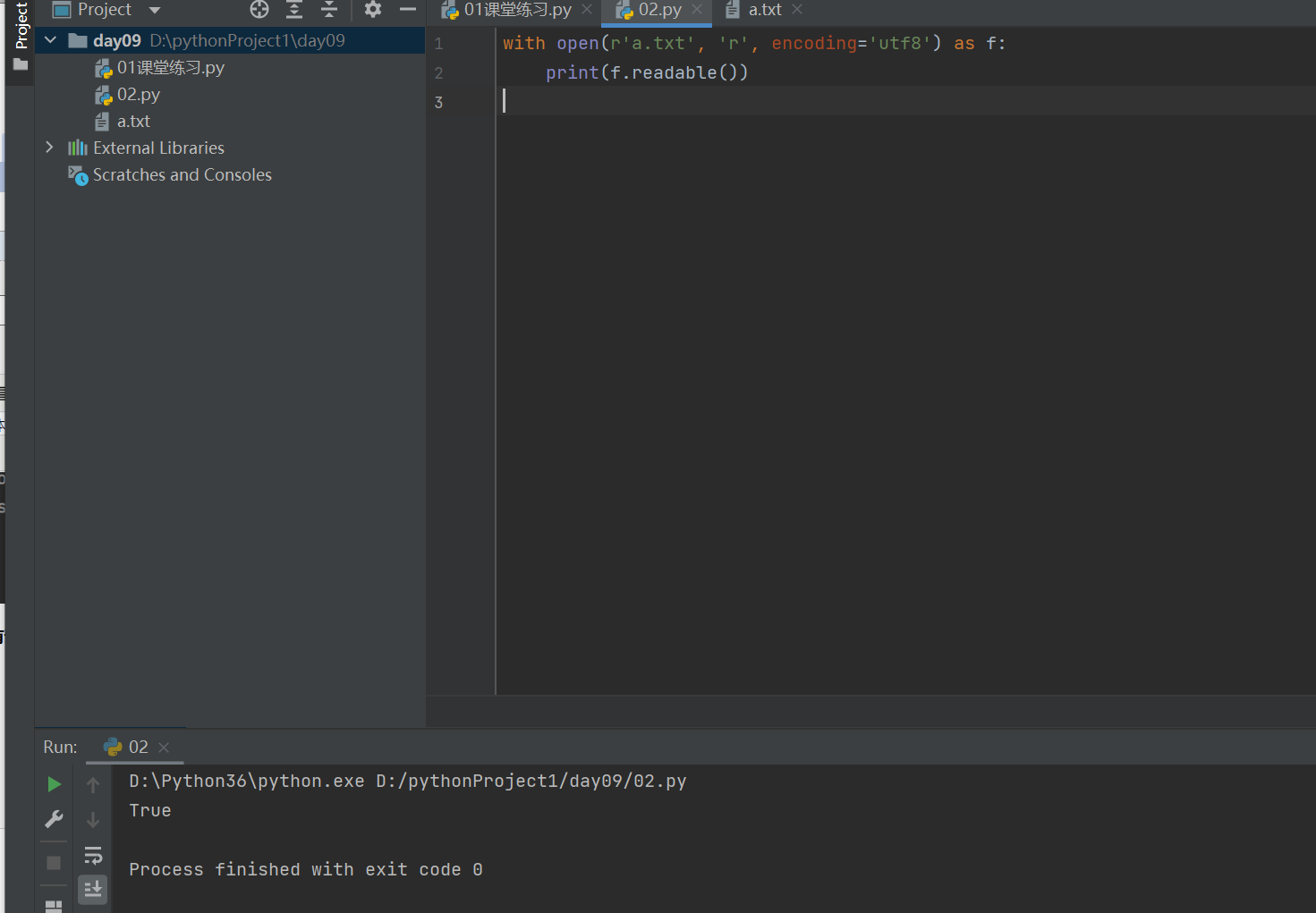
1.4 print(f.readable()) #判断当前文件是否具有读的能力
2. write写系列
2.1 f.write('内容必须是字符串') #把文件内原来的内容删除,并写入括号内的内容
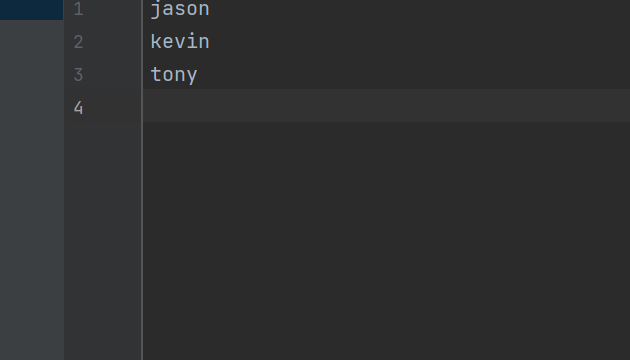
2.2 f.writelines() #可以将列表中多个字符串元素全部写入文件
with open(r'a.txt', 'w', encoding='utf8') as f:
f.writelines(['jason\n', 'kevin\n', 'tony\n'])
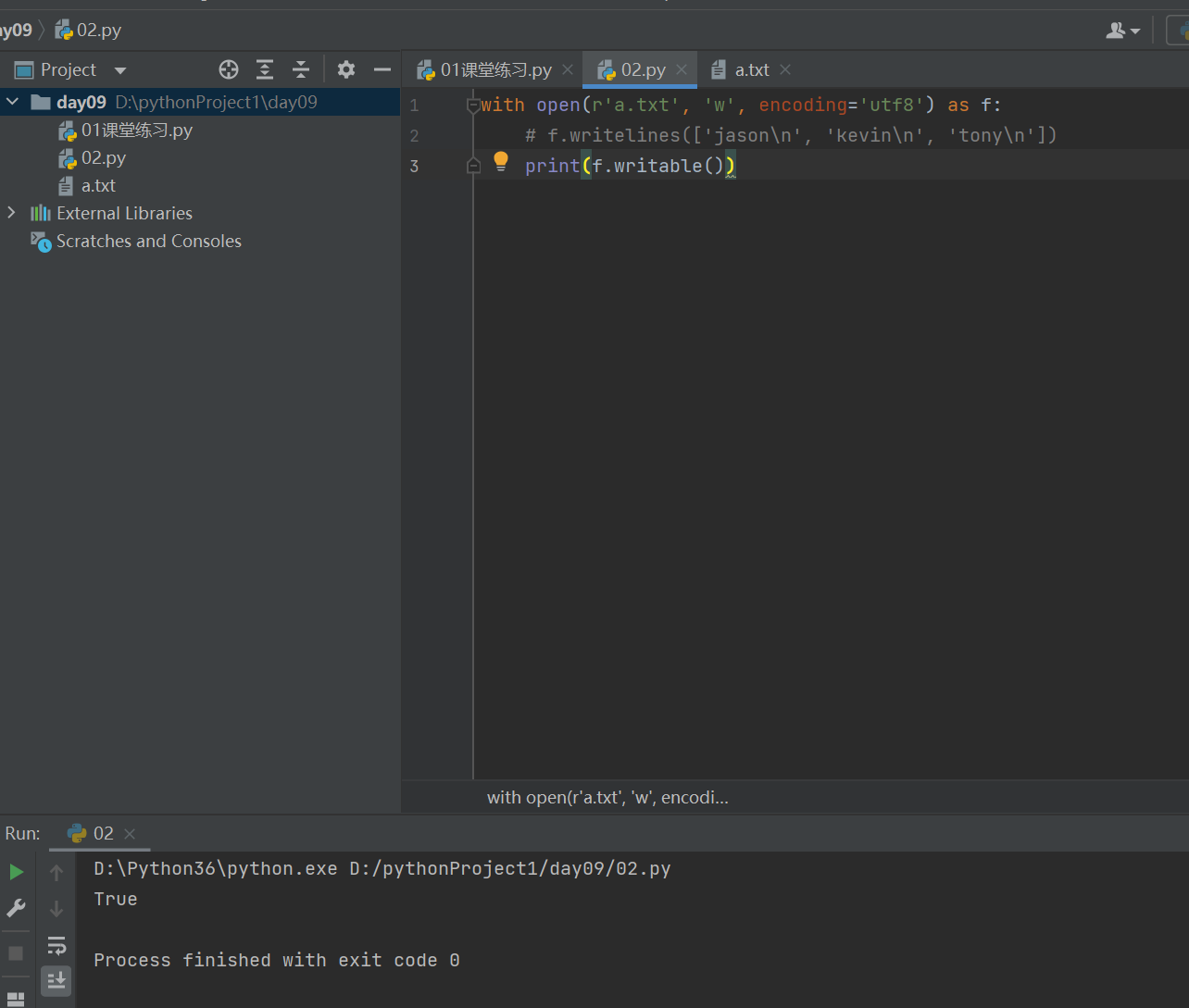
2.3 f.writeable #判断当前文件是否只具有写的能力
PS: f .flush # 直接将内存内文件存到硬盘 相当于ctlr+s
二、文件操作模式
1. t 文本模式
1.1
默认的模式文件操作模式一般只写 r w a 是因为默认成 rt wt at的模式在使用
1.2
该模式所有的操作都是以字符串为基本单位1.3
该模式必须要指定encoding参数
1.4
该模式只能操作文本

2. b 二进制模式
2.1
该模式都是使用时模式都写成 rb wb ra的形式
2.2
该模式可以操作任何类型的文件
2.3
该模式所有的操作都是以bytes类型(二进制)为基本单位
2.4
该模式不需要指定encoding参数

三、二进制读写操作
with open(r'a.txt', 'rb') as f:
print(f.read())
print(f.read(6).decode('utf8'))
with open(r'a.txt','r', encoding='utf8')as f1:
print(f.read())
print(f.read(4))
''' read()括号内可以填写数字 在t模式下表示读取的字符个数 在b模式下表示读取的字节个数 英文字符统一使用一个字节表示 中文字符同意使用三个字节来表示 '''

四、文件内的光标移动
with open(r'b.txt','rb')as f:
print(f.seek(4))
print(f.tell) #查看光标移动了多少个字节
feek.(3,1) #以当前位置为参考系,光标向右移动了三个字节
控制文件内的光标移动使用 f.seek(offset,whence)
offset表示位移量
始终是以字节为最小单位
正数从左往右移动
负数从右往左移动
whence表示模式,一共有三种模式
0:以文件开头为参考系(支持文本文件t模式和二进制b模式)
1:以当前位置为参考系(只支持b模式)
2:以文件末尾为参考系(只支持b模式)

五、文件的内容修改
文件的内容有修改有覆盖和新建两种方式
覆盖:在内存原来的地方将文件内容替换成新的内容
优点: 在文件修改过程中同一份数据只有一份
缺点: 会过多地占用内存
with open(r'c.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'c.txt', 'w', encoding='utf8') as f1:
new_data = data.replace('123', '456')
f1.write(new_data)
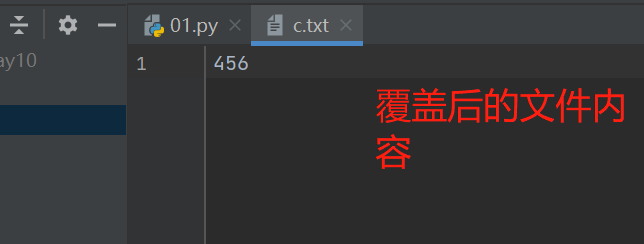
新建:在内存中新建一个地方来存放修改后的内容文件,将原来的文件删除掉
优点: 不会占用过多的内存
缺点: 在文件修改过程中同一份数据存了两份
import os
with open('c.txt', mode='rt', encoding='utf-8') as read_f, \
open('c.txt.swap', mode='wt', encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('SB', 'kevin'))
os.remove('c.txt') # 删除原文件
os.rename('c.txt.swap', 'c.txt') # 重命名文件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号