
[斯坦福2025春季新课CS336:从头开始构建大模型]自学笔记(9-11)
详解Scaling laws
缩放定律研究的关系包括:数据与表现;数据与模型大小;超参数与表现
缩放定律是为了获取数据、模型超参数与表现间的关系,尽量避免大规模实验
- Q:实际中,我们数据有限,重复的数据是如何影响缩放的?
- 可以依据定律,决定训练的epoch
考虑到重复的数据价值较少。数据选择更适合缩放。本质是在重复的好数据和新的差数据间权衡
增加不同的参数(embedding/非embedding)带来的损失变化不同,如下图

scaling law可以指导小模型上的最优学习率,迁移到大模型
详解模型推理
如何衡量推理的性能
- TTFT(Time To First Token),用户需要等多久才能看到生成的内容
- Latency(second/token):每个token的生成时间
- Throughput(token/second):每秒生成多少个token
推理的两个阶段
- 预填充(Prefill):给定提示,将其编码成向量(可并行化,如同训练过程)
- 生成(Generation):生成新的响应token(顺序生成)
低延迟选择batch size=1,减少每个token的生成时间
高吞吐量选择更大的batch size,提升每秒生成的token数量
KVCache
KVCache:对于每个seq(B),token(S),layer(L),head(H),head_dim(D_head),存储key和value的缓存
如何减少KVCche的存储开销?
- Grouped Query Attention(GQA):减少KV的头的数量。类似的还有MQA、MLA
- Cross layer attention(CLA):跨层共享KVCache
- Local attention:只缓存最近的K个token,保持KVCache的大小不变,不会随着序列长度增长。有点像稀疏注意力机制
- Linear attention:先计算KV点积,再与Q计算,复杂度为\(O(Nd^2)\),相较于 vanilla attention \(O(N^2d)\)减少计算量
其他的加速推理的方法:
量化
-
FP32 训练常用的精度
-
BF16 默认推理精度
-
FP8 [-240, 240] 可以用来训练
-
INT8 [-128, 127] 精度更低,但速度比FP8块(仅在推理时这样)
-
INT4 [-8, 7] 速度更快,精度更低
-
QAT:Quantization Aware Training,量化感知训练。用量化进行训练。
-
PTQ:Post Training Quantization,训练完成后进行量化。
量化过程,先确定量化的最大值[-127, 127]
找出量化前的最大值,然后将量化最大值 / 量化前最大值,得到量化比例。
量化前的值每个乘上比例,得到量化结果
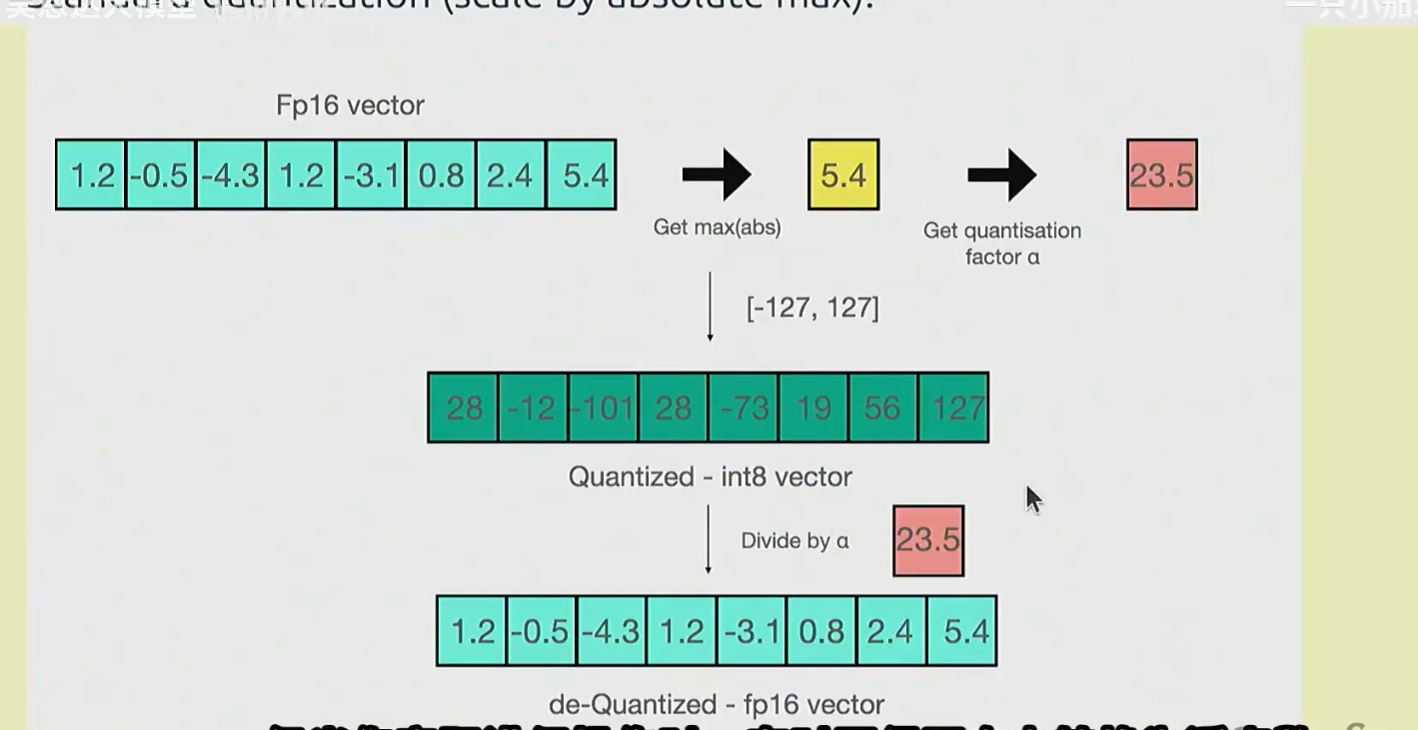
对于异常值需要找出,并单独处理
剪枝
- 对于一个大模型,确定哪些是重要的{layer, head, hidden dimension}。重要的层依据是:输出范数大,attention score不是均匀分布。或者在训练时Mask后,损失/困惑度提升
- 剪去不重要的层或参数。
- 然后再使用原来的模型对剪枝模型进行蒸馏
无损压缩
以上的方法都会损失精度
Speculative Sampling:
- 使用一个更小、更快的draft model生成少量token(e.g., 4)
- 使用target model 并行预测(很快,就像prefill),并接受符合要求的token

Speculative Sampling对draft model的改进
- Medusa:draft model并行生成多个token
- Eagle:从target model获取高层次feature,输入到 draft model 生成
工程上的优化
Continuous Batching
- 问题:推理时不像训练,有一整个batch的token。推理时,每个请求到达和完成的时间不同
- 解决方法:decode step by step,以 token 为单位进行增量解码,批次成员可动态进出。新的请求到来时(先prefill)再加入batch 进行decode,不用等到生成完成。并移除完成的请求
Page attention
- 问题:token生成的数量不可预见,会造成内存碎片
- 解决方法:将KVCache从序列拆分为不连续的block,通过页表管理块的分配与回收
- 进一步,如果前缀相同,可以增加一个指针共用KVCache
如何用好Scaling laws
MuP(Maximal Update Parametrization,也叫\(\mu P\)):MuP不研究什么是最优的超参数,只研究最优超参数随着模型尺度的变化规律,所以我们需要在某个小模型上搜索最优的超参数组合,然后迁移到大模型上,这就是MuP的使用场景和使用方法。下图展示了参数量改变时,如何修改超参数:

参考文献
但MuP不是必要的,DeepSeek使用了固定的学习率
缩放后还是有一个全局学习率,但是每层会被不同的系数缩放:μP 使不同层/参数类别具有不同的学习率有效尺度(scaled learning rate)
\(\frac{Token数量}{模型参数}=20\) 是Chinchilla的一个结论,但不是强制约束,大可以增加这个比值
常见的学习率调整策略: Warmup-Stable-Decay (WSD) Paradigm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号