
[斯坦福2025春季新课CS336:从头开始构建大模型]自学笔记(5-8)
GPU原理与分布式训练基础 & 内核优化与Triton框架应用
Triton
在triton编程中,通常以SM为原子单位进行编程,SM内部有多个SP(streaming processor),一个SP会并行处理大量线程
粒度大到小:BLock -> Warp -> Thread
- Block由若干Thread组成,一个Block被送到SM并行执行
- 一个Warp由32个Thread组成,这32个Thread同时执行同一条指令(SIMD),即不同的数据上执行相同的指令,如果发生warp divergence,GPU会串行执行每条分支路径:先执行一部分线程的指令,其他线程被禁用(stalled);再执行另一部分,如下图所示。
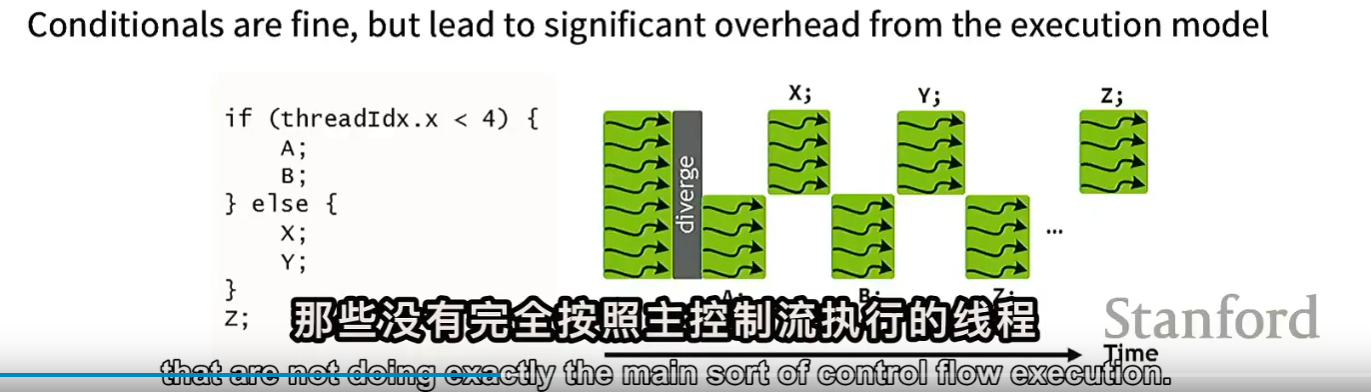
如果计算资源过剩,但是效率受限带宽:可以不去保留中间的激活值,在backward时,重新计算前向激活值。
关于DRAM的优化
burst mode:当你访问1个数据的时候,DRAM会返回给你4个数据,这段连续的数据称为burst section。
因为将数据移动到放大器非常耗时,burst mode掩盖了将数据实际移动到放大器这个更昂贵的步骤
关于tilling的大小考虑因素
- 合并内存访问(尽量避免最后一个tilling不稀疏)
- 共享内存大小
- 矩阵维度的可除性
如何让计算更快
- 减少内存访问
- coalescing(合并内存访问)当同一 warp(或 wavefront)中的多个线程访问显存时,这些访问可以被自动合并为尽量少的连续大块内存事务,从而显著提高内存带宽利用率、降低延迟。也就是被访问的数据地址是连续的
- 算子融合
- 将数据移动到shared memory
- 用计算换取内存访问(重计算)/用精度换取内存访问(量化)
其他
- cuda synchronize的作用:保证GPU与CPU同步,因为CPU和GPU是两个不同的设备,CPU发出命令后不会等GPU完成再继续,而是并行执行
- 测试benchmark前,需要进行warmup,避免测量到冷启动时间
- profiler GPU/CPU 性能分析软件
- Q:为什么 python 能成为深度学习语言?
- A:因为 python 虽然性能低,但是 cpu 不会是瓶颈,更多的是因为 gpu 的计算等待耗时
- Q:torch.compile 将未优化的 python 代码进行优化例如融合,但为什么还需要自己写算子?
- A:torch.compile 很擅长矩阵运算,但对于新的架构,复杂的运算,也许需要自己写 triton 算子
详解大模型并行化策略 & 手撕大模型并行训练
DDP(Distributed Data Parallel)
DDP的总通信成本为2*#params(前向+后向各一次all-reduce)
Zero-1
优化器被切分
- 每张显卡,基于自己被分配到的batch子集计算梯度
- 每张梯度Reduce、Scatter自己的梯度,通信成本为 #params
- 每个机器使用梯度,基于自己分配到的优化器state,更新对应的部分参数
- all-gather参数,通信成本为 #params
Zero-2
优化器和梯度被切分
与Zero-1相似,在forward时会计算所有参数的梯度,但是对于当前优化器状态对应的参数的无关梯度会被立即释放(虽然 ZeRO-2 计算了全量梯度,但通信和内存只保留 1/N)
Zero-3
也被称为Fully Sharded Data Parallel(FSDP)
优化器、梯度和参数都被切分
- 对每个分片模块:all-gather 参数 → 前向 → 释放全量参数,通信成本:#params
- 对每个分片模块:all-gather 参数 → 反向(计算输入梯度 + 参数梯度)→ reduce-scatter 梯度 → 释放全量参数,总通信成本为 #params * 2
- 本地更新自己负责的参数分片和 optimizer state
通信和计算的时间开销会被重叠(overlap),因为通信和计算可以并行进行
Zero-3的缺点:不会减少激活值的内存占用
Model Parallel 相关
PP
或zero-3很像,把模型放在不同的GPU,但是不再gater模型参数,而是激活值
layer-wise parallel,模型的一层放在一张GPU。进阶版:pipeline parallelism
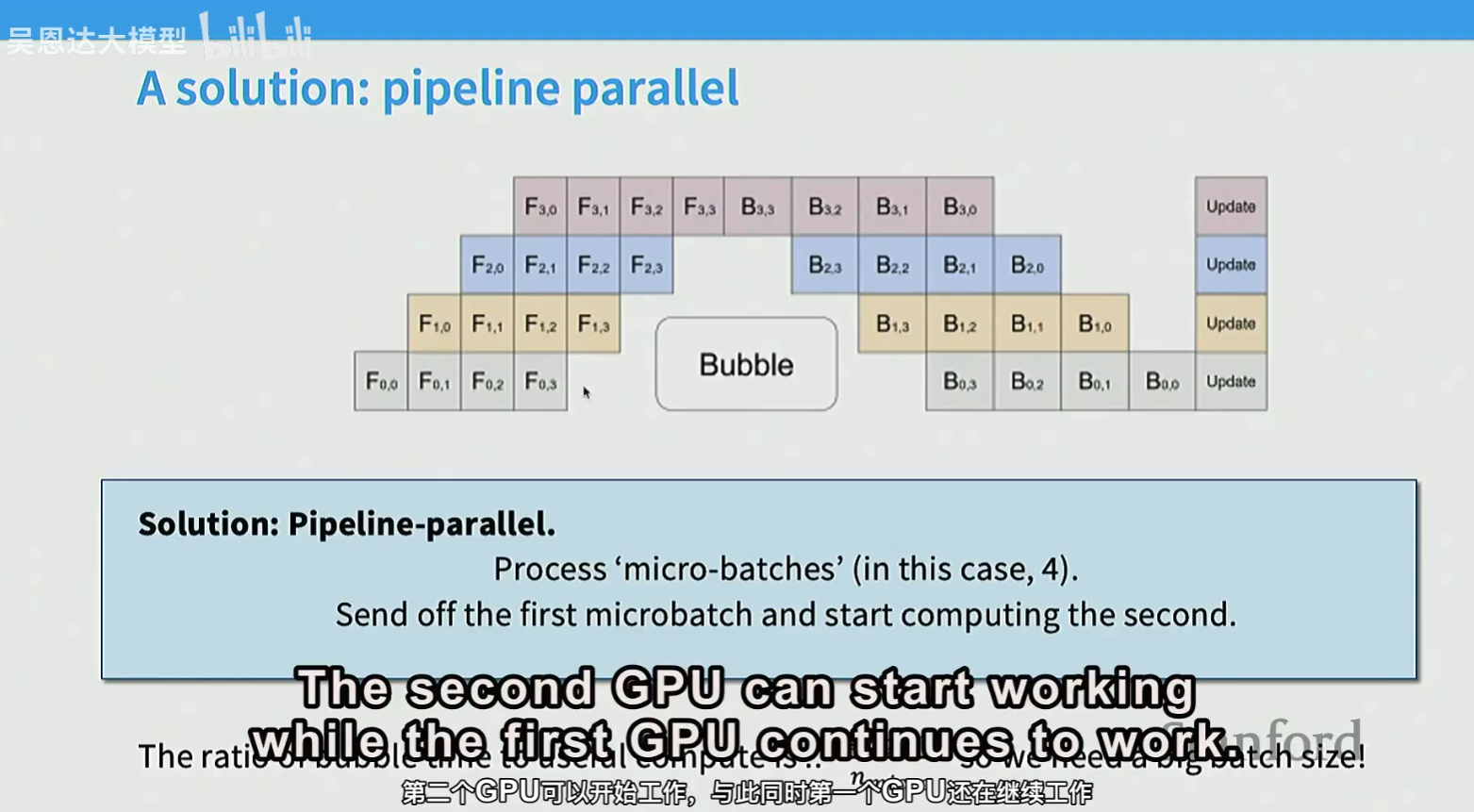
pipeline parallel适合通信较慢的场景。通信可以与计算高度重叠,从而对通信带宽和延迟的依赖更小
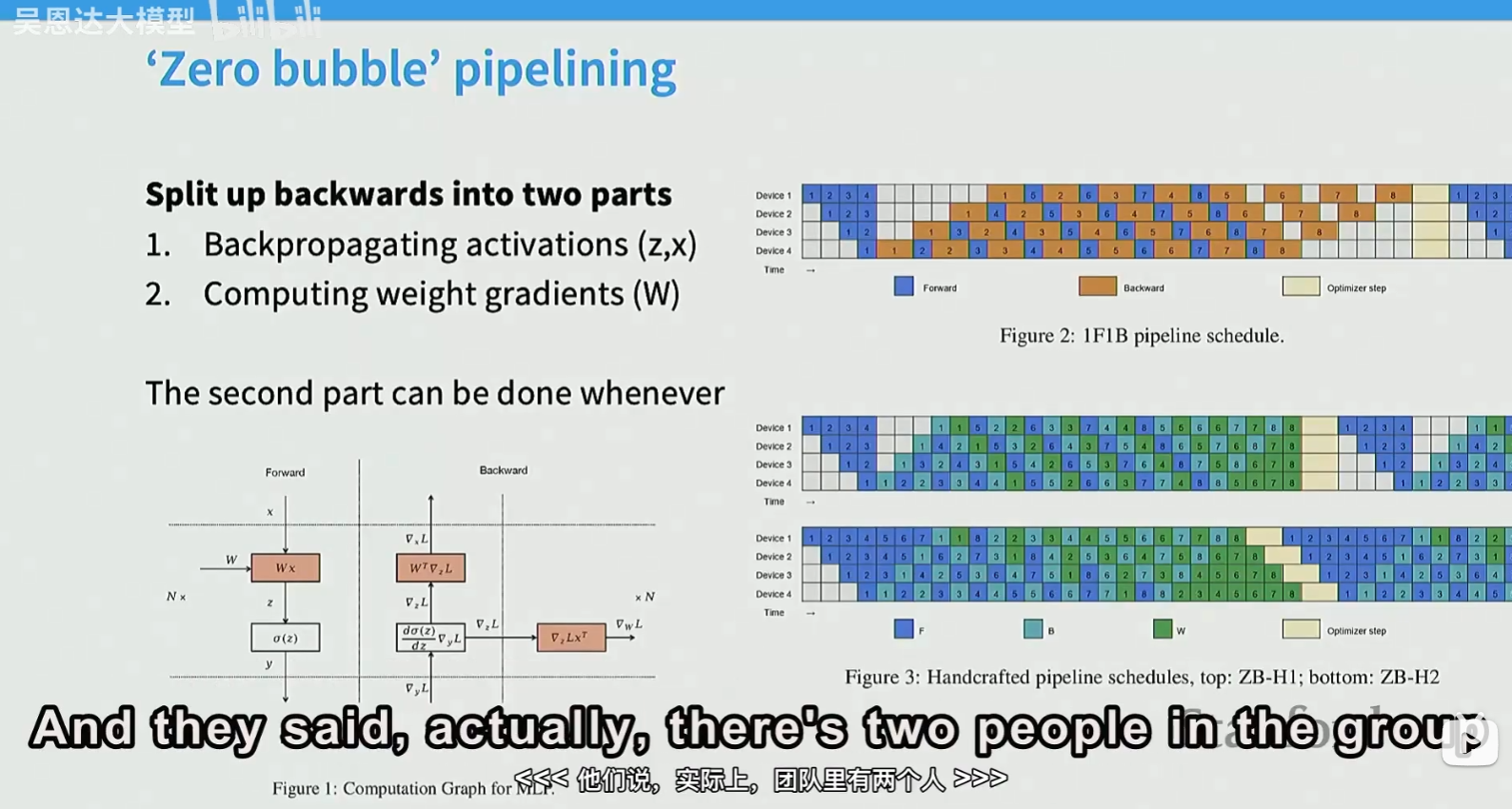
增大batch size,减少bubble。或者将backward的计算拆成两部分,可以实现zero bubble pipelining:
TP
由于大部分都是矩阵运算,所以出现了tensor parallelism(张量并行):将矩阵分解计算,然后求和
由于每层同步进行,需要非常快速的通信,通常使用8卡,因为一台机器最多8卡。不存在bubble
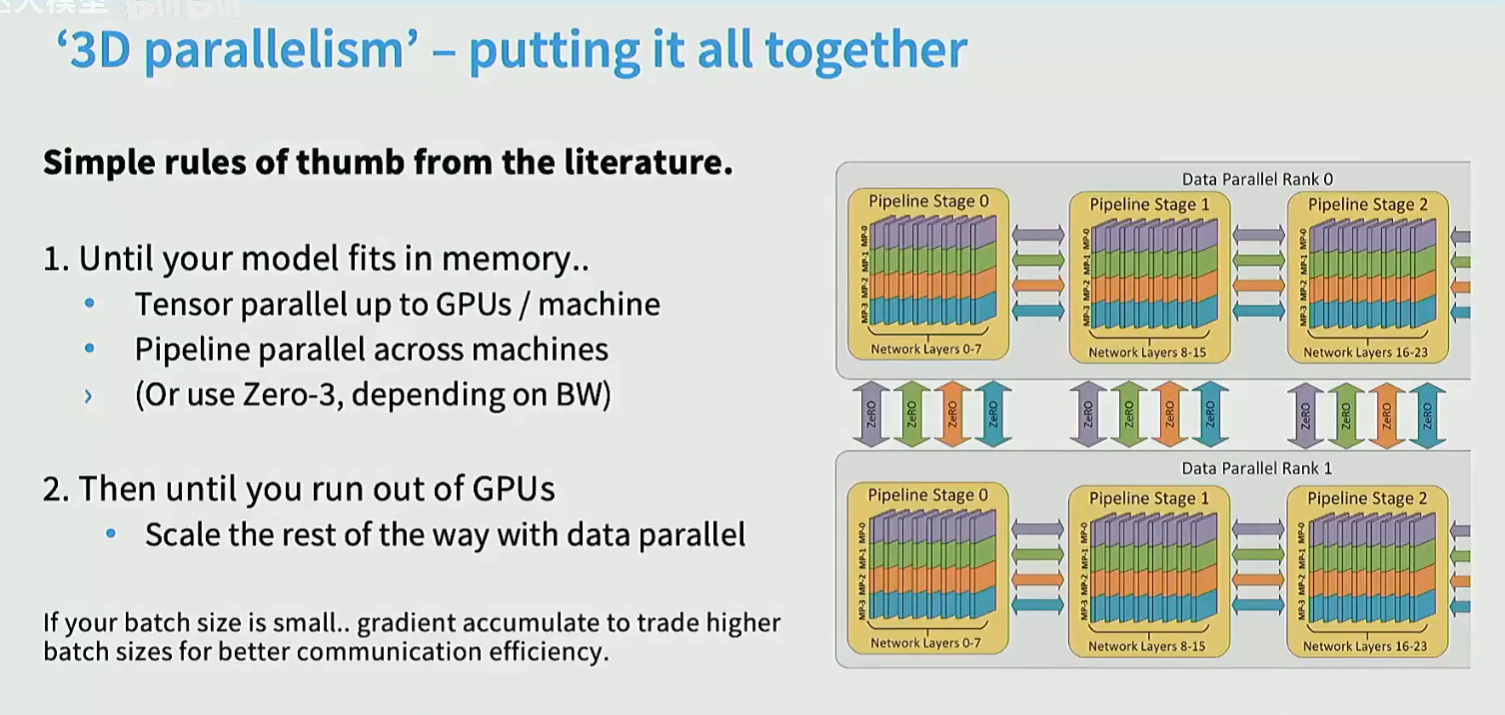
TP和PP可以同时使用,像layer norm/ dropout涉及所有参数的。通常使用PP:
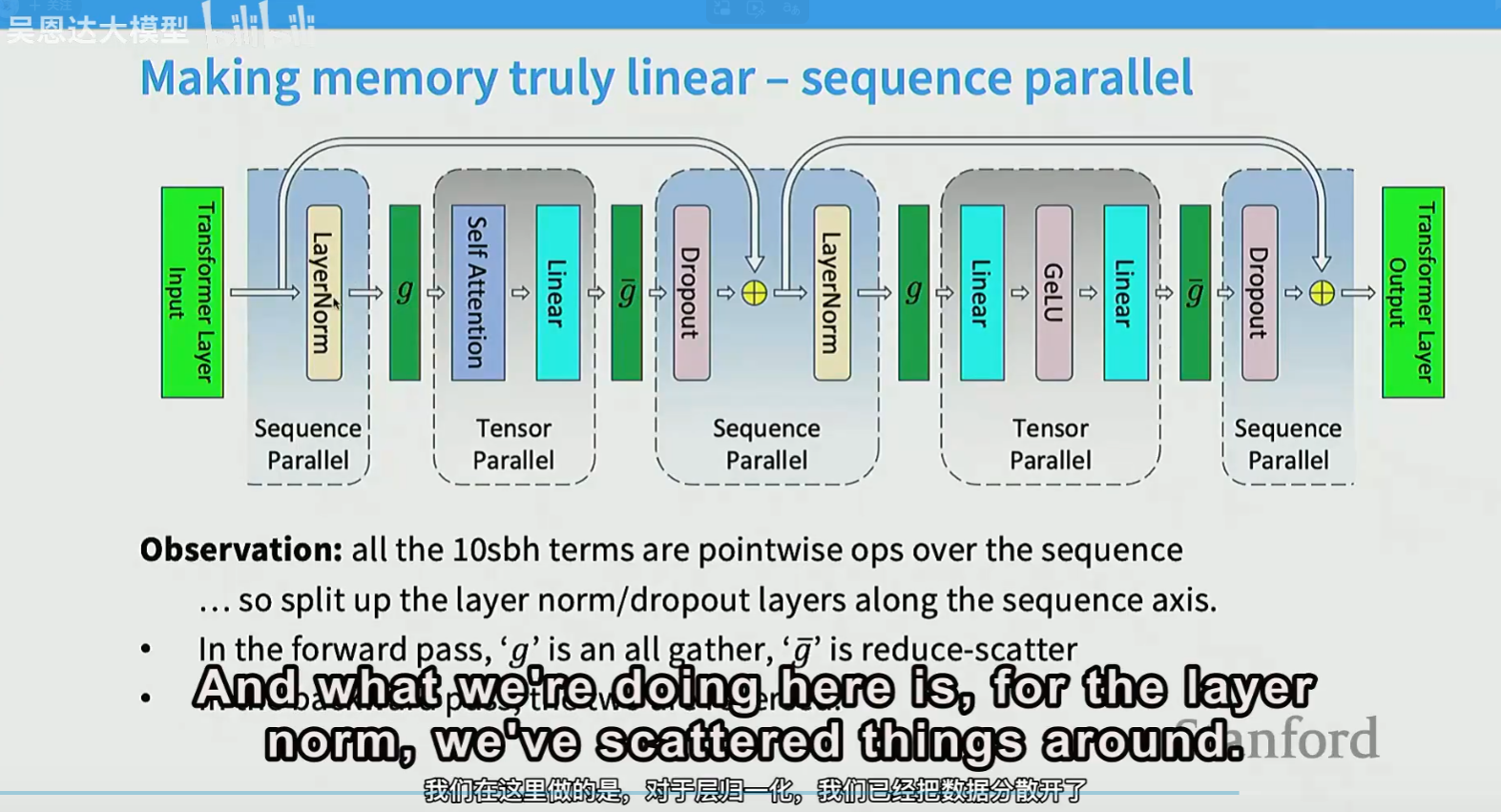
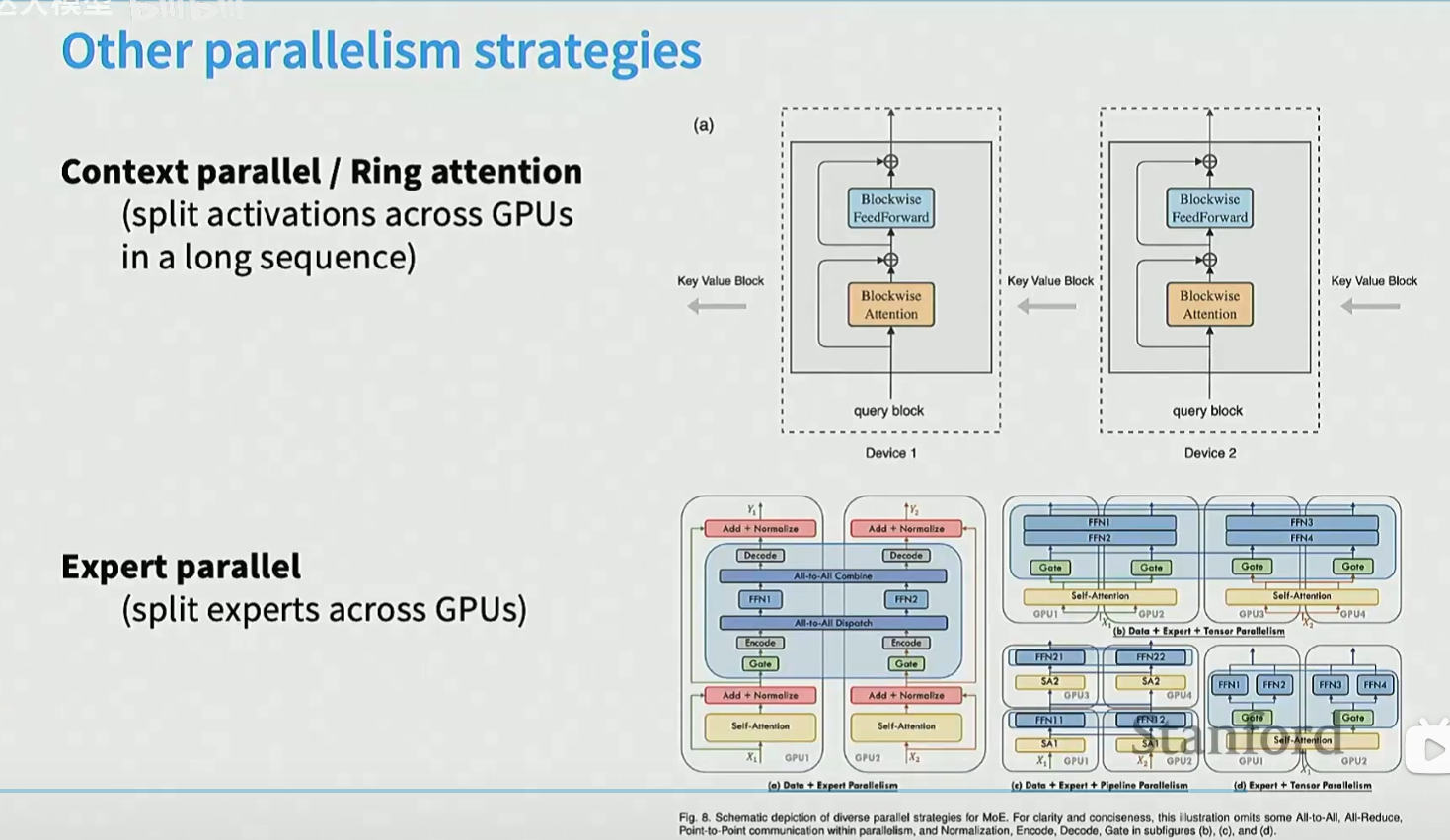
还有context parallel,适合长序列。expert parallel(本质还是TP),适合Mixture of Expert模型
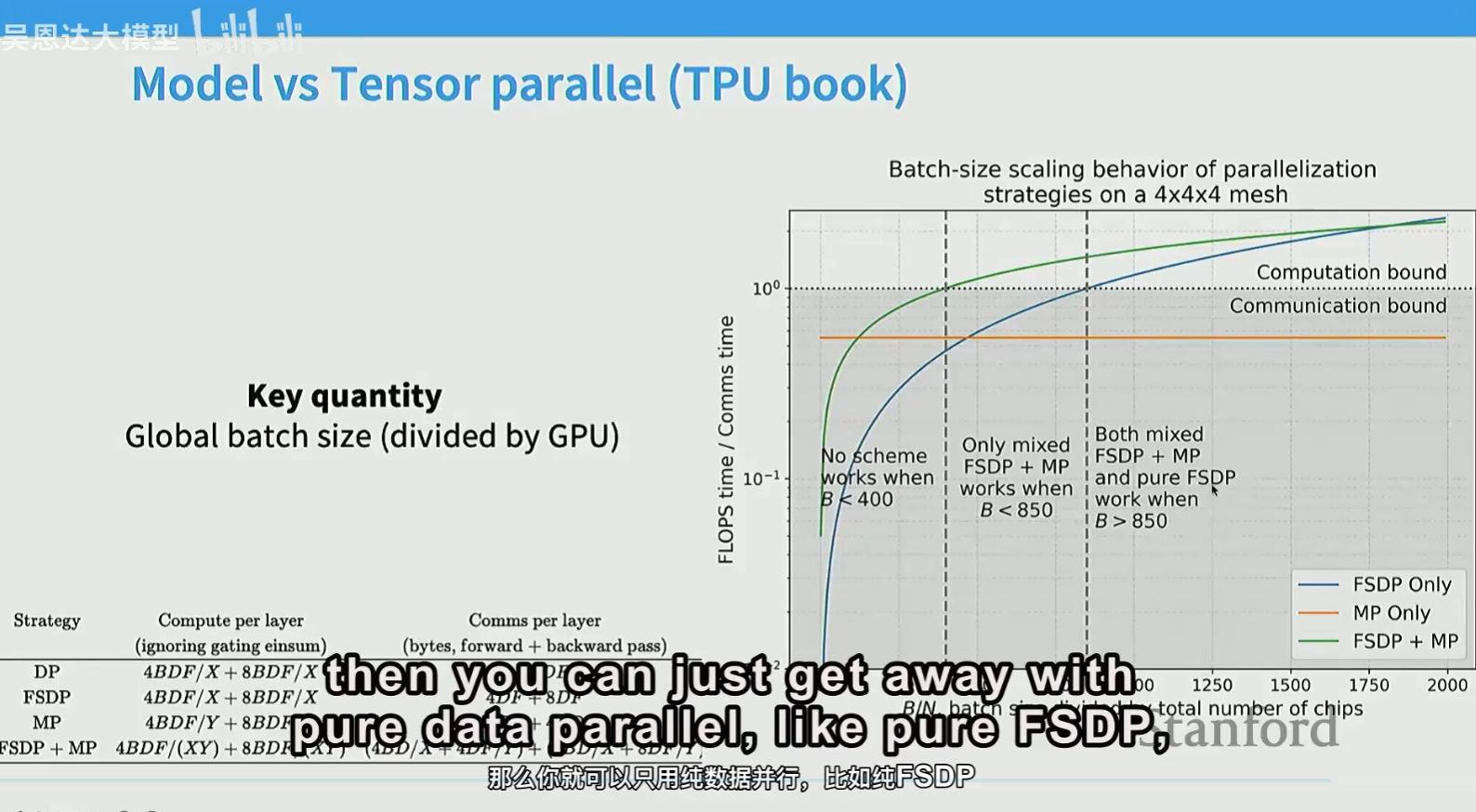
batch size和GPU数量的比值非常重要,决定了哪种并行方式最合适
如果batch size非常大,可以只用zero-3
集合通信操作(Collective Communication Operations)
- Broadcast:将device x的数据发送其他device上
- Scatter:device x上有n个不同的数据,分别发到n个device上
- Gather:Scatter的逆操作,把n个device上的数据收集到device x上
- Reduce:与Gather类似,但是在收集数据的同时进行某种操作(如求和、求最大值等)
- All-gather:与Gather类似,所有device都执行Gather操作
- Reduce-scatter:先对所有数据进行reduce,将结果的不同部分scatter到不同device上
- All-reduce:Reduce-scatter + all-gather
NVLink可以直接连接GPU,从而绕过CPU,无需经过宿主机内核。即使是跨节点,可以通过NVSwitch直接连接GPU。这比PCIe(数据要先经过CPU,因为它是通用设备通信总线,包含声卡、固态硬盘等)和以太网要快得多。
NCCL nvidia的集体操作通信库,需要执行collective操作时,CPU会调用这个库
使用torch.distributed时,backend如果没有GPU,可以使用gloo
torch.cuda.synchronize() # 等待cuda kernels的执行完成
dist.barrier() # 所有进程都到达这个屏障后才能继续往下执行
发送数据和计算的overlapping,可以通过异步调用实现
recompute:重新计算
store in memory:存在内存中,但要承担通信传输的成本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号