

使用vscode debug远程项目(以vLLM为例)
本机上需要准备的事项
- 安装 vscode;下载远程连接插件:Remote - SSH,汉化插件:Chinese (Simplified) (简体中文) Language Pack for Visual Studio Code
- 配置文件中写入远程服务器相关信息
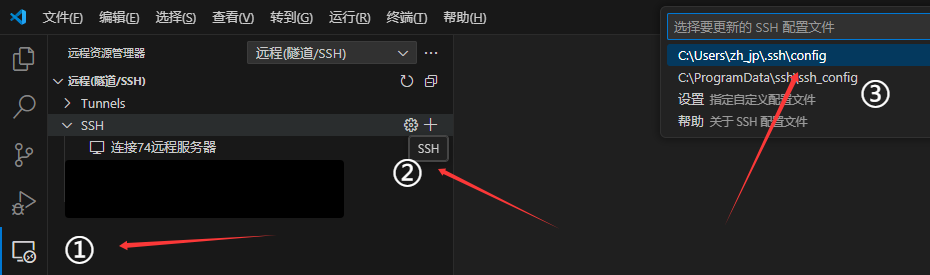
- 点击右侧靠边栏“远程资源管理器”
- 点击“SSH配置文件”
- 选择要写入的SSH配置文件(Windows11上,目录文件在C:\Users\你的用户名.ssh\config)
- 在文件中添加如下内容
Host 连接74远程服务器
HostName 10.20.152.74
Port 8222
User root
通过插件连接服务器
然后就可以,在vscode中连接相应服务器,在连接过程中需要选择服务器操作系统(本文中为Linux)、密码(本文中为root),
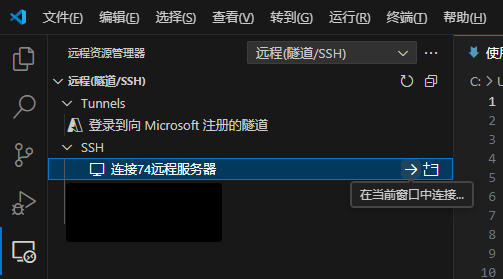
首次连接以及本机vscode版本变动后,都会在服务器上下载相应的vscode-server
在服务器上调试:以debug vllm为例
由于vllm是python项目,假设服务器上已配置项目所需conda环境
切换到项目所在目录
code /workspace/projects/vllm_0.7.3_0521/vllm
在右下角选择python环境
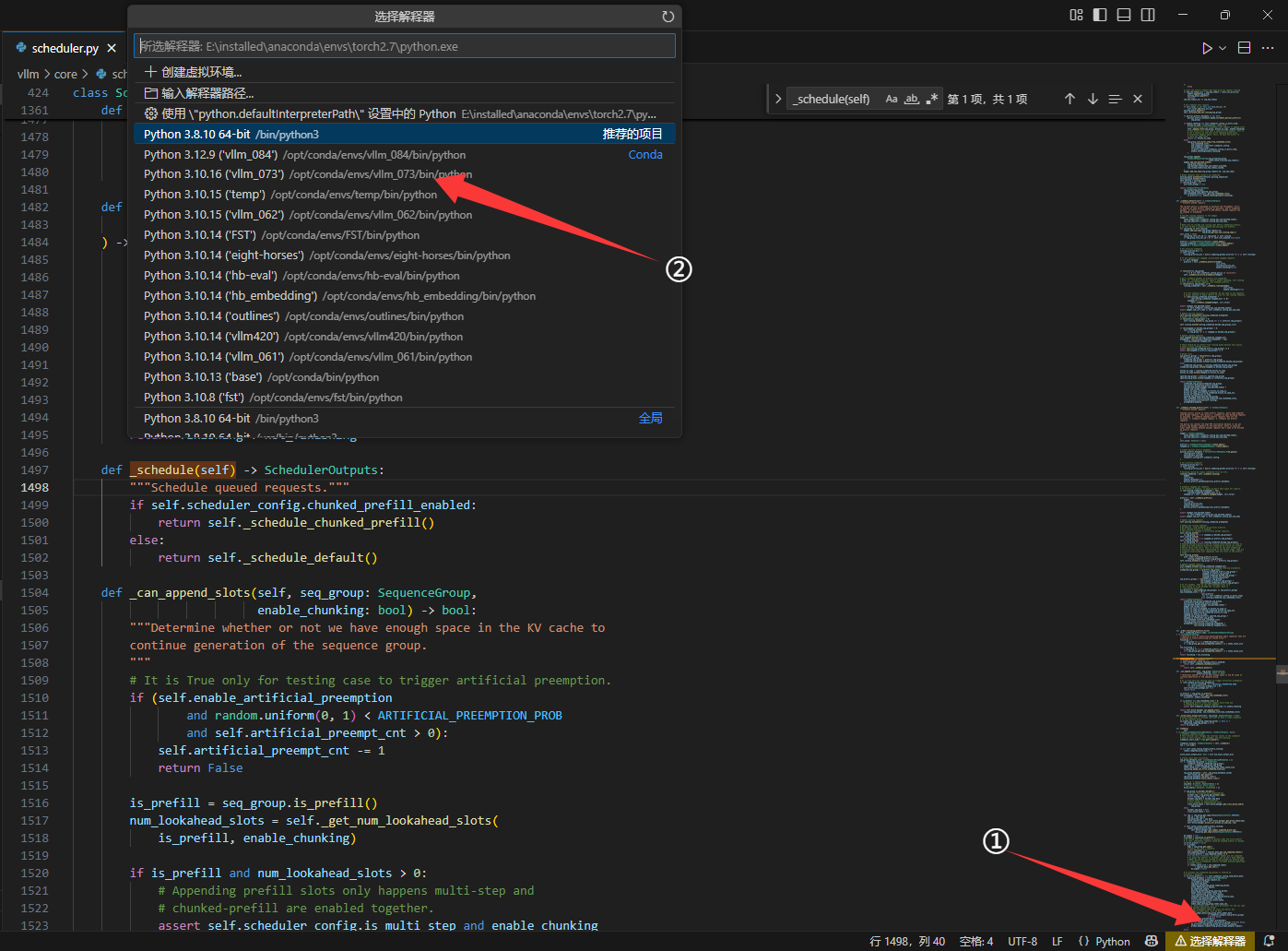
准备调试工具
为服务器上vscode配置插件:Python Debugger。注意服务器上和本机上的插件不共享,但是可以通过微软账号/github账号进行同步。
创建调试所需的 .vscode/launch.json 文件,用于指定自己运行时的参数、环境变量
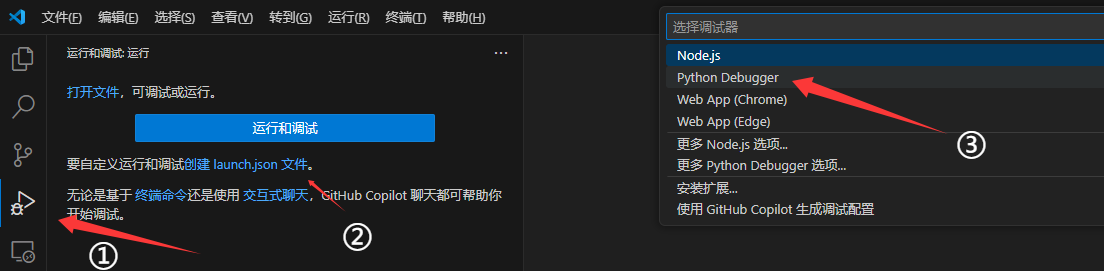
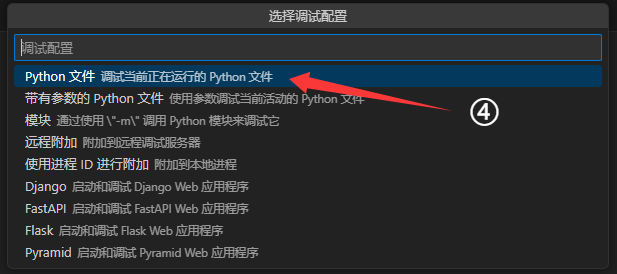
launch.json内容按需设置,这里以vllm为例
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: 启动服务器",
"type": "debugpy",
"request": "launch",
"program": "/workspace/projects/vllm_0.7.3_0521/vllm/vllm/entrypoints/openai/api_server.py",
"console": "integratedTerminal",
"args": [
"--model",
"/workspace/llm_models/HengNao-2_5-7b-chat",
"--tensor-parallel-size",
"1",
"--enforce-eager",
"--enable-prefix-caching",
"--max-model-len",
"32000",
"--served_model_name",
"HengNao-r1",
"--token-pool-size",
"80000",
"--port",
"6001",
"--guided-decoding-backend",
"outlines",
"--gpu-memory-utilization",
"0.6"
],
"justMyCode": false,
"cwd": "${workspaceFolder}",
"env": {
"PYTHONPATH": "/workspace/projects/vllm_0.7.3_0521/vllm",
"CUDA_VISIBLE_DEVICES": "1",
"VLLM_USE_V1": "0",
"LOGGING_LEVEL": "debug"
}
}
]
}
开始调试
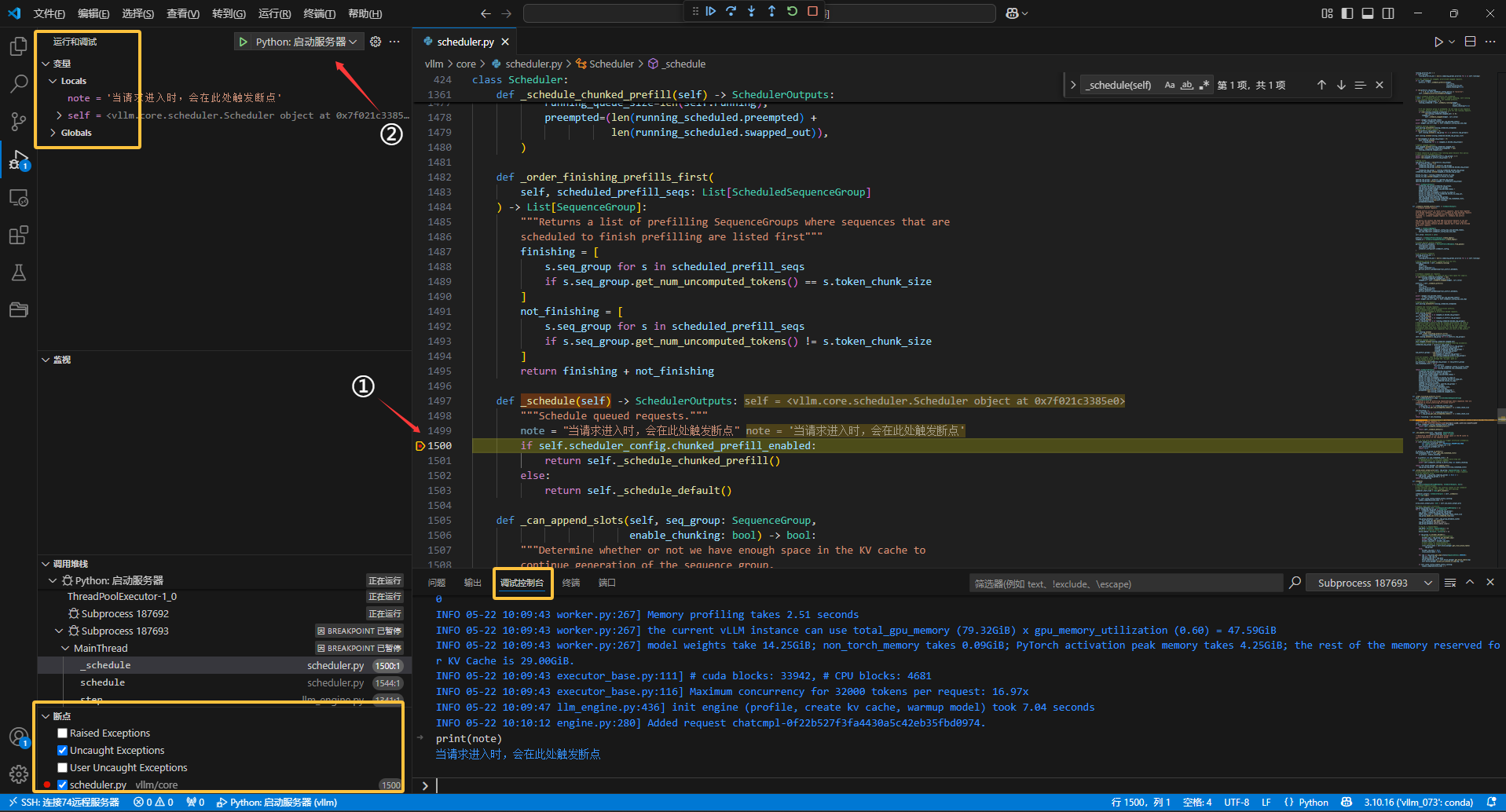
然后,就可以在项目需要检查的地方设置断点,并运行程序,当程序触发断点所在行时,vscode会自动暂停程序运行,并在左侧的变量窗口中显示当前变量的值,用户也可以在调试控制台上执行python语句
如果要调试的是远程服务器上的Docker容器
如果我们要远程调试的对象实际上一个服务器上的Docker容器,在远程调试前,需要提前确认一件事:容器开放的端口与宿主机上端口的映射关系:
docker ps
还是以本文为例:
6eabf09cf985 docker.das-security.cn/hb/dev:20250424 "bash /root/run.sh t…" 3 weeks ago Up 24 hours 0.0.0.0:8222->22/tcp, :::8222->22/tcp, 0.0.0.0:8201->6001/tcp, :::8201->6001/tcp, 0.0.0.0:8202->6002/tcp, :::8202->6002/tcp, 0.0.0.0:8200->8000/tcp, :::8200->8000/tcp hb_dev_lq
在最后一部分,就是“容器端口->宿主机端口”的映射关系
0.0.0.0:8222->22/tcp, :::8222->22/tcp, 0.0.0.0:8201->6001/tcp, :::8201->6001/tcp, 0.0.0.0:8202->6002/tcp, :::8202->6002/tcp, 0.0.0.0:8200->8000/tcp, :::8200->8000/tcp
由于映射关系“0.0.0.0:8222->22/tcp”。因此,在一开始,容器ssh端口是22,但是想要外部连接容器需要指定ssh端口为8222。同理,我在vllm中指定的端口6001,实际上是映射到宿主机的8201端口上,如果想用Postman请求,访问的地址为:
https://10.20.152.74:8201/v1/chat/completions

 浙公网安备 33010602011771号
浙公网安备 33010602011771号