

[ACM MM2024]CLIPCleaner Cleaning Noisy Labels with CLIP
这篇文章基于样本选择的噪声标签学习(Learning with Noisy labels)方法,通过引入CLIP帮助过滤噪声样本。
Introduction
噪声标签的方法包括:
- 开发鲁棒的损失函数
- 使用标签噪声转移矩阵对噪声标签进行建模
然而这些方法在处理高噪声比和复杂的噪声模式(两个图片很相近但是标签不同,例如“狼”和“狗”)时通常不是最优的。
而近些年基于样本选择的方法更为流行。样本选择基于这样的事实:在训练过程中,模型倾向于更早地拟合干净样本,而不是噪声样本,这使得干净样品的损失相对较小。同样,这类方法也存在局限性:
- 一些标签噪声存在于视觉上非常相似的类别之间(hard noise)。
- “自我确认(self-confirmation)”偏置:训练中的模型至少部分地在噪声标签上进行训练引起的。
例如下图中,(a)灰色的线表示样本选择的边界阈值,在被选择的样本中(c)中展示了干净样本,(b)中展示了噪声样本。可以看到许多噪声样本由于有着相似的颜色和纹理被误认为是干净样本。

针对上面提到的样本选择局限性,作者引入了CLIP,这带来了两个优势:
- 样本选择考虑到了类别之间的视觉和语义相似性,因此可以补偿仅依赖视觉信息进行样本选择可能产生的偏差。
- 样本选择与训练模型无关,因此不受噪声标签和“自我确认”偏差的影响。
需要注意的是,作者在文章强调:
- 最终分类器与用于样本选择的CLIP的VL模型不同。
- 我们坚持仅使用CLIP进行样本选择,并且不对其进行训练/微调。
Method
CLIP回顾
每个样本有一对文本和图像,正样本表示匹配的图像-文本对,负样本为图像和其他文本以及文本和其他图像的组合。CLIP的损失函数为:
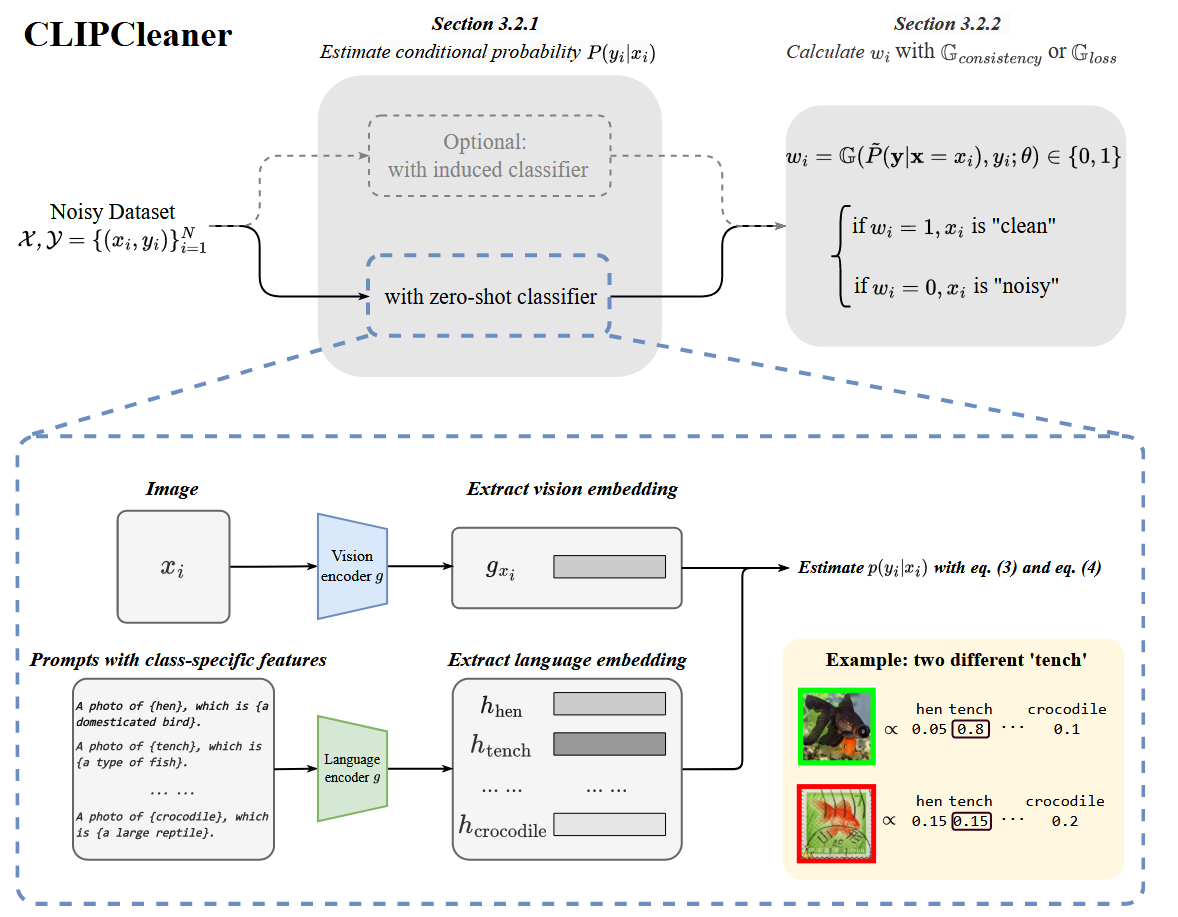
CLIP的zero-shot分类器
CLIP本身没有分类头,对于样本的类别概率预测\(P(y|\textbf{x}=x_i)\),使用zero-shot classifier进行预测。简洁得说就是,比较图像特征与文本特征的相似性,选择最相似的文本作为预测类别。因为文本和标签是一一对应的,所以可以直接使用文本作为标签。
文中还给出了CLIP zero-shot分类器比一般的分类器好的解释,但个人觉得没什么有用的信息。作者把一般的分类器(线性层输出经过softmax)称为诱导分类器(induced classifier)\(P_{induced}(\mathrm{y}|\mathrm{x}=x_i)=\mathrm{softmax}(f^{\prime}(g(x_i)))\)。作者比较了两者和真实概率分布的距离:
忽略不可控误差项和常见误差项(蓝色部分)。两个分类器的误差项分别为\(\varepsilon_{domain}\)和\(\varepsilon_{induced}\)控制。
- \(\varepsilon_{domain}\)表示由CLIP预训练分布\(Q\)和真实分布\(P_{true}\)之间的域偏移引起的偏差项
- \(\varepsilon_{induced}\)表示训练数据集中的标签噪声引起的差分项。
结论是:1. zero-shot分类器受域偏移和prompt质量的影响;2. 诱导分类器受噪声数据集的标签噪声的影响。显然,对于后者,我们能做的是提升prompt的质量。更好的prompt工程,可以减少\(\varepsilon_{domain}\)。
在prompt的生成中,在动物分类任务中使用类别特定特征,例如不同动物物种的独特颜色或习性:
例如:
- A photo of {hen}, which is {a domesticated bird}.
- A photo of {tench}, which is {a type of fish}.
- A photo of {crocodile}, which is {a large reptile}.
整个选择的过程:
选择指标的计算
得到预测概率分布后,作者考虑了两种指标判断是否选择样本:基于一致性和基于损失:
在文中采取保守策略,对不同的样本选择结果进行交集,优先考虑样本选择的精度。
MixFix
受 FixMatch 启发,我们还基于训练模型\(f\)检查未标记子集中每个样本的当前预测\(\textbf{p}_i\),对于没有被筛选的样本,作者设置了两个阈值,进一步得吸收潜在的干净样本
\(w_i=1\)表示对应的样本被选择。
与 FixMatch对所有样本使用一个阈值不同,我们通常设置\(\theta_r\le\theta_r'\)。这使我们能够充分利用噪声标签来区分“吸收”和“重新标记”过程。
实验
在实验中,有一个数据集值得注意,在这里作者的方法表现得并不突出。Clothing1M数据集比其他数据集更细粒度,对于这种细粒度的噪声数据集,样本选择可能不是最优策略。
Table 5: Testing accuracy (%) on Clothing1M.
参考文献
- Feng, Chen, Georgios Tzimiropoulos, and Ioannis Patras. "CLIPCleaner: Cleaning Noisy Labels with CLIP." Proceedings of the 32nd ACM International Conference on Multimedia. 2024.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号