
理解爬虫原理
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851
1. 简单说明爬虫原理
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前
2. 理解爬虫开发过程
1).简要说明浏览器工作原理(流程)
(1):向服务器发起请求,通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器的响应。
(2):获取响应内容 如果服务器正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML、JSON、二进制文件(如图片、视频等类型)。
(3):解析内容 得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是JSON,可以直接转成JOSN对象进行解析,可能是二进制数据,可以保存或者进一步处理
(4):保存内容 保存形式多样,可以保存成文本,也可以保存至数据库,或者保存成特定格式的文件。
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
url='http://news.gzcc.cn/html/xiaoyuanxinwen/' res=requests.get(url)
3).了解网页
写一个简单的html文件
<html> <head> <meta charset="utf-8"> <title>html简单实例</title> </head> <body> <h1>这是第一个标题</h1> <h2>这是第二个标题</h2> <h3>这是第三个标题</h3> <h4>这是第四个标题</h4> <h5>这是第五个标题</h5> <h6>这是第六个标题</h6> <p>这是个段落</p> <hr /> <!---这是一条水平线---> <font side = "6">这是六号<br>字体</font> </body> </html>
4).使用 Beautiful Soup 解析网页;
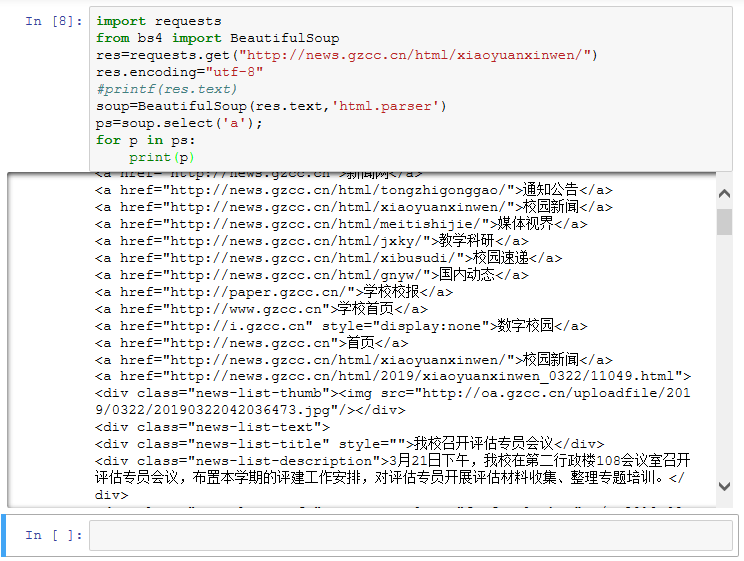
(1)输出该网页中所有的a标签
(2)输出类名为search-input的标签

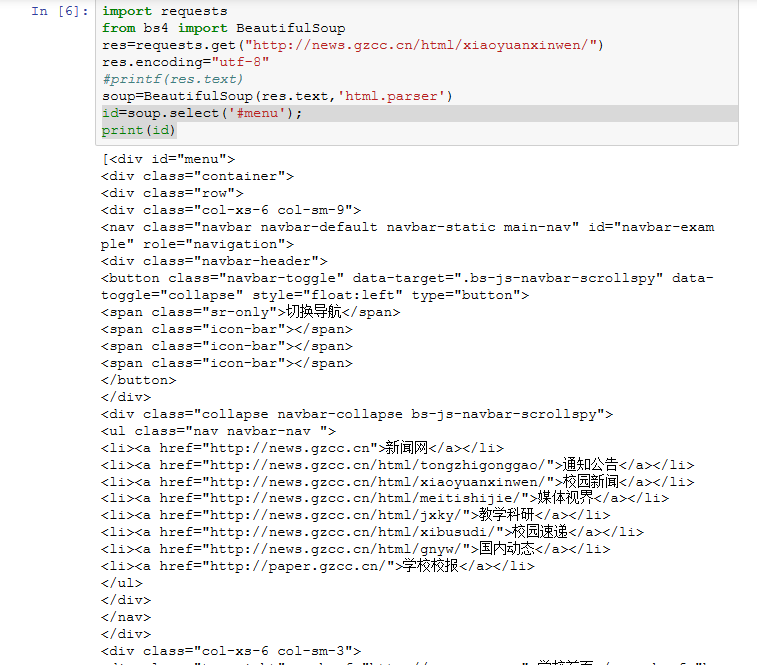
(3)输出id名为menu的标签。
3.提取一篇校园新闻的标题、发布时间、发布单位


 浙公网安备 33010602011771号
浙公网安备 33010602011771号