Spark SQL
1.请分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生。
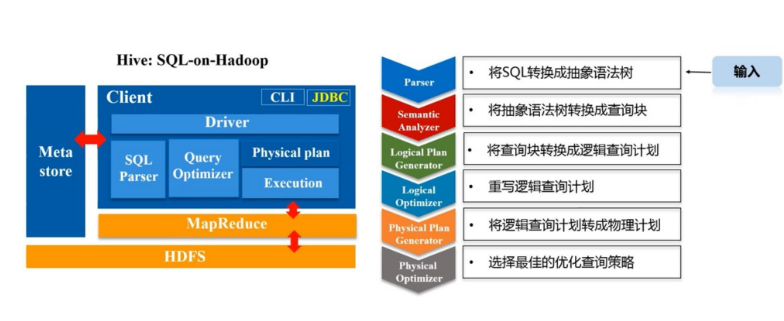
为什么推出sparksql

2. 简述RDD 和DataFrame的联系与区别?
区别:
RDD是分布式的java对象的集合,但是对象内部结构对于RDD而言却是不可知的。
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,相当于关系数据库中的一张表
联系
1.都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
2、都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action才会运算
3.都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
4、三者都有partition的概念
5.三者有许多共同的函数,如filter,排序等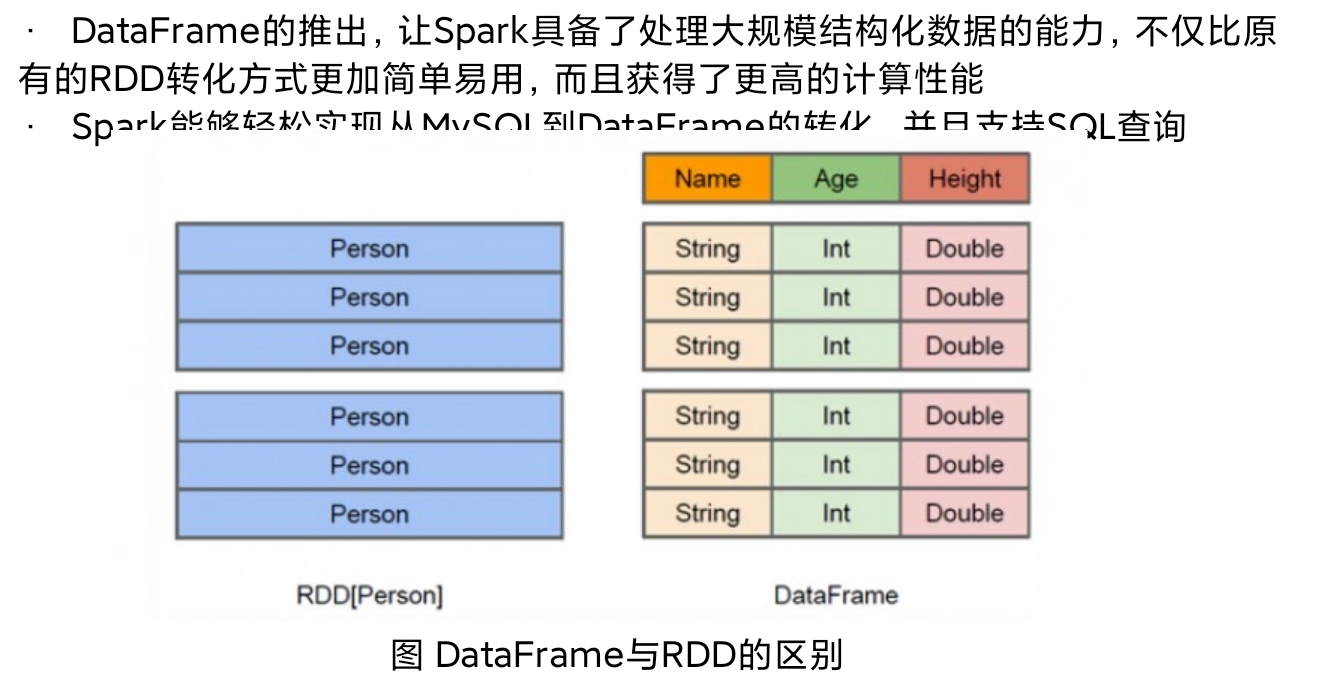

3.DataFrame的创建
spark.read.text(url)
file=‘file:///文件目录’

spark.read.json(url)

spark.read.format("text").load("people.txt")
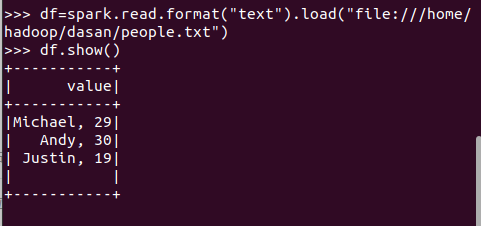
spark.read.format("json").load("people.json")
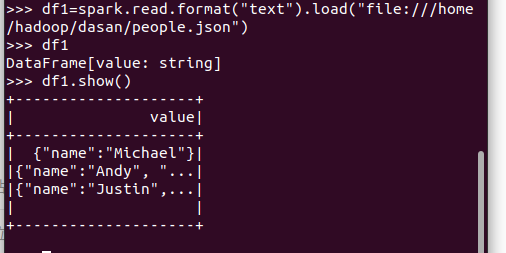
描述从不同文件类型生成DataFrame的区别。
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
4.PySpark-DataFrame各种常用操作
基于df的操作:
打印数据 df.show()默认打印前20条数据
df1 = spark.read.text("file:///home/hadoop/dasan/people.txt") df1.show()
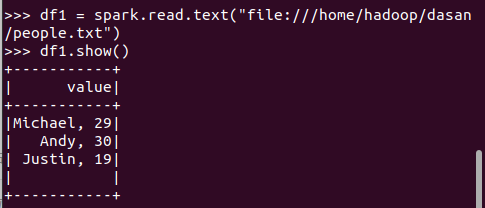
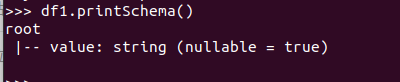
打印概要 df.printSchema()
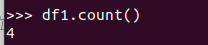
查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

df1
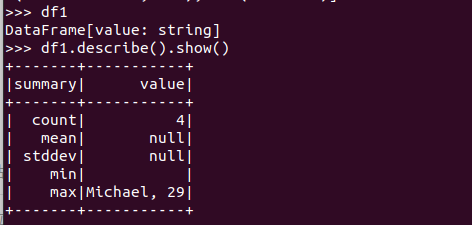
查询概况 df.describe().show()
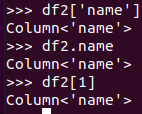
取列 df[‘name’], df.name, df[1]
基于spark.sql的操作:
创建临时表虚拟表 df.registerTempTable('people')
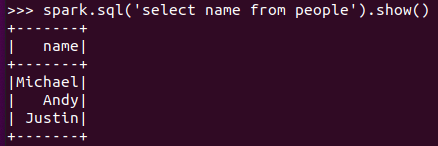
spark.sql执行SQL语句 spark.sql('select name from people').show()
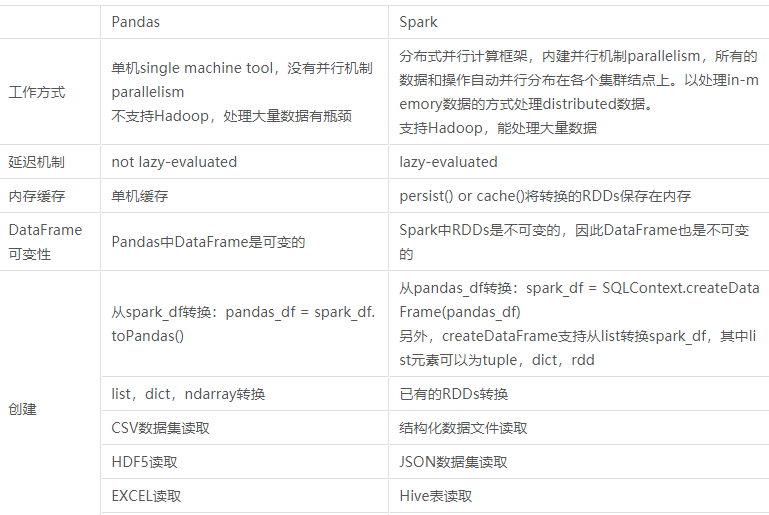
5. Pyspark中DataFrame与pandas中DataFrame
分别从文件创建DataFrame
比较两者的异同
pandas中DataFrame转换为Pyspark中DataFrame
下载pandas
pip install pandas
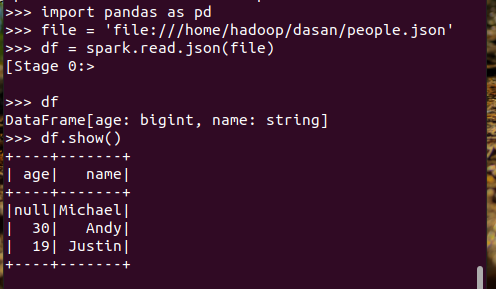
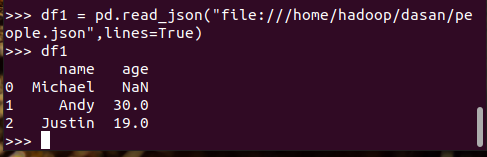
Pyspark中DataFrame转换为pandas中DataFrame
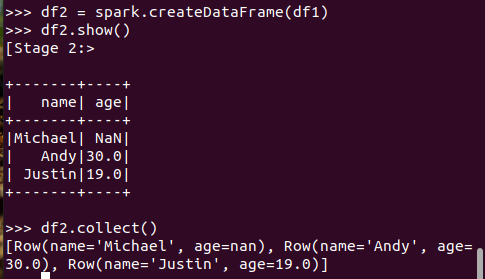
6.从RDD转换得到DataFrame
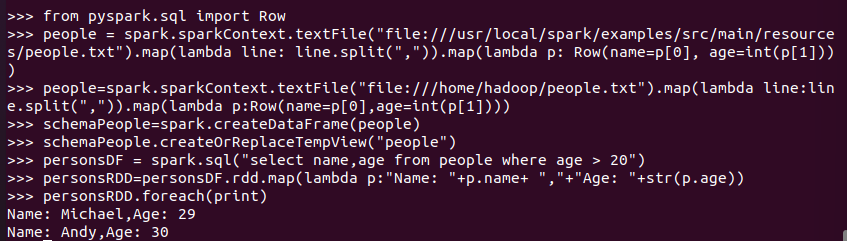
6.1 利用反射机制推断RDD模式
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame
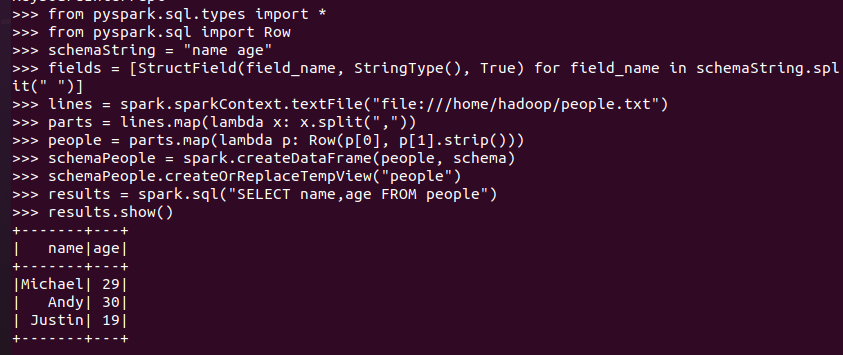
6.2 使用编程方式定义RDD模式
#下面生成“表头”
#下面生成“表中的记录”
#下面把“表头”和“表中的记录”拼装在一起
7. DataFrame的保存
df.write.text(dir)
df.write.json(dri)
df.write.format("text").save(dir)
df.write.format("json").save(dir)
df.write.format("json").save(dir)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号