RDD操作综合实例
一、准备文件
1.下载小说或长篇新闻稿
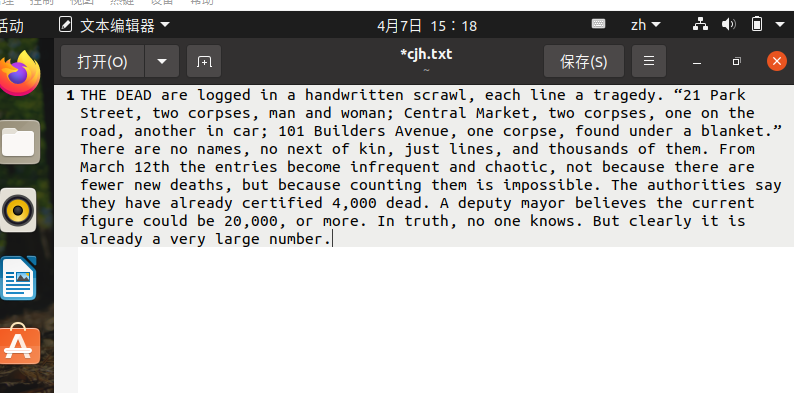
2.上传到hdfs上
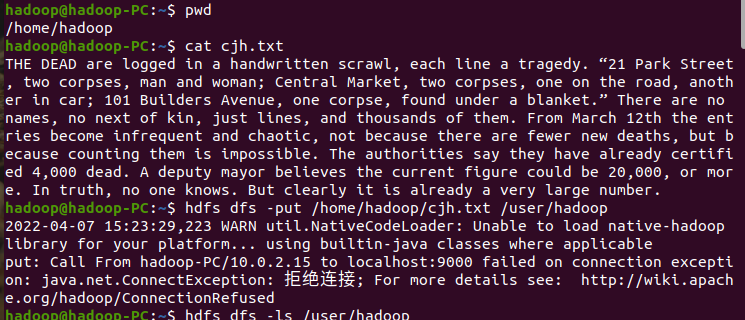
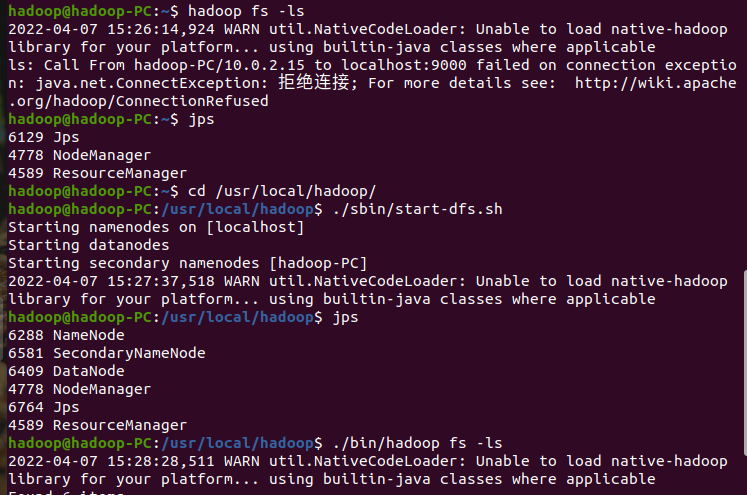
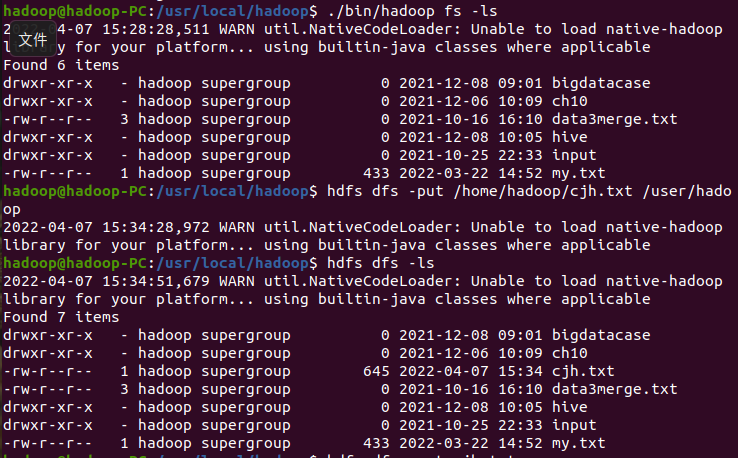
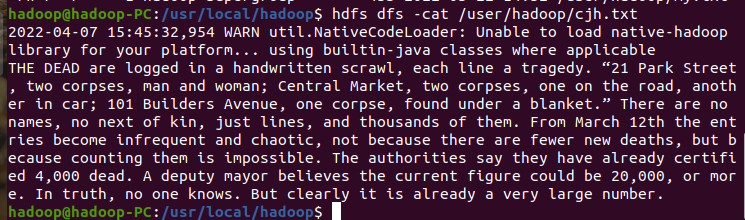
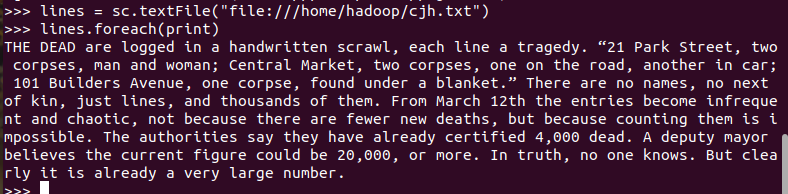
二、读文件创建RDD
输入pyspark
三、分词

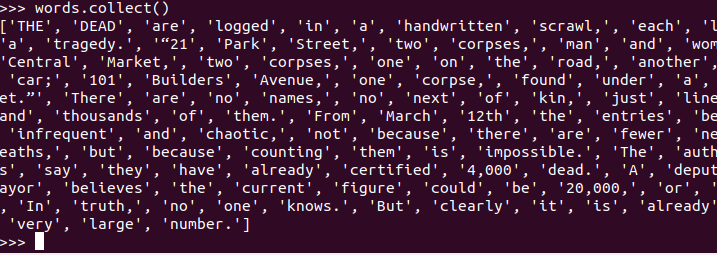
四、排除大小写lower(),map(),标点符号re.split(pattern,str),flatMap(),,停用词,可网盘下载stopwords.txt,filter(),,长度小于2的词filter()
先导入re然后用re.split分词(\W+会匹配所有非单词字符,(\W+)会返回这些,但我们不需要返回,所以这里用\W+即可)
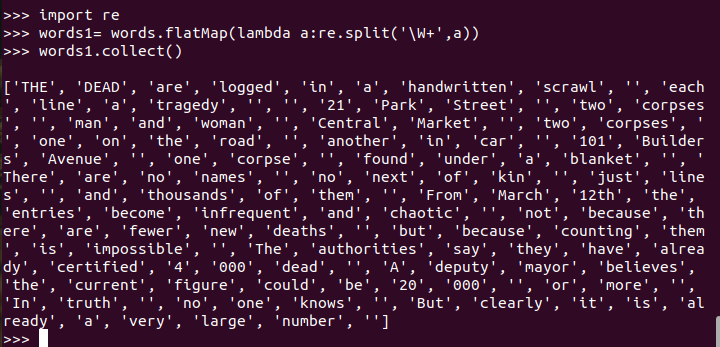
排除大小写lower(),map()
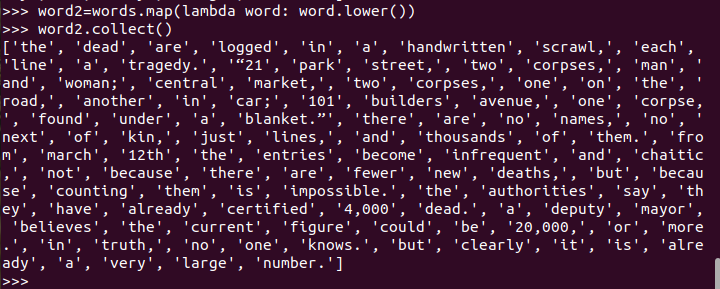
停用词,可网盘下载stopwords.txt,filter()

长度小于2的词filter()

五、统计词频
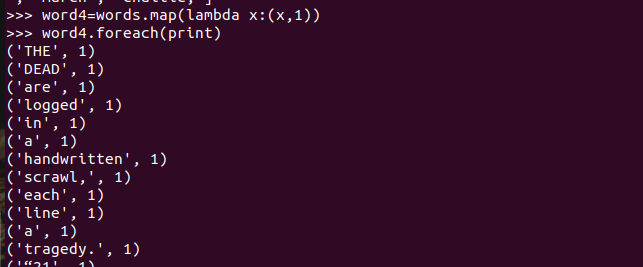
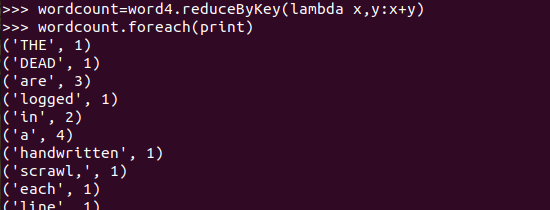
六、按词频排序
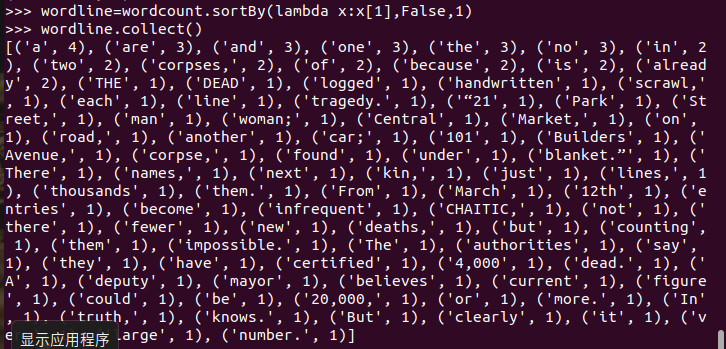
七、
1.输出到文件


2.查看结果
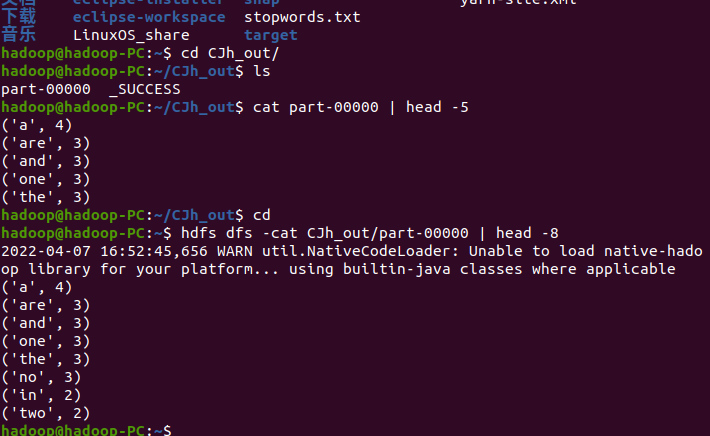
B. 一句话实现:文件入文件出

C.和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点。
在spark中读取数据后数据是一条字符串/一行字符串视作一个linus,也叫做一个rdd对象(每个转换算子的操作都会形成新的rdd对象),spark中词频统计需要先用flatMap进行切分并压平,然后处理切分的字符串后形成新的键值对,再对形成的键值对进行词频的统计,然后再排序输出。而在python中,则没有压平等这类操作。
D.求Top值



 浙公网安备 33010602011771号
浙公网安备 33010602011771号