Redis
为什么要用Redis :1、速度快 【 数据库DB 内存 磁盘 】 传统数据库 磁盘从数据库获取数据需要I/O操作,但是Redis直接存储在内存上,不用IO操作; redis底层是C语言实现; redis采用非阻塞式IO模式(epoll)模型; Redis是单线程,避免线程切换带来的线程竞争; RESP协议
2、支持各种数据结构
3、持久化(这是相对传统MemCache)
4、事务【只可保证隔离性和一致性,不支持原子性,弱持久性】
Redis是一个支持持久化的内存数据库【如果没有开启持久化,内存里的数据会断电、重启丢失,也即redis重启后数据就全丢失了】,Redis有两种持久化的文件,RDB文件(snapshot 快照概念),AOF文件(append概念)
redis的事务和关系数据库的事务不可同日而语,redis的事务只能保证隔离性和一致性,无法保证原子性和持久性。
redis事务不支持原子性,不支持回滚操作,事务中间一条命令执行失败,既不会导致前面已经执行的命令会滚,也不会中断后面的命令的执行;RDB持久化只备份当前内存中的数据集,事务执行完毕时,其数据还在内存中,并未立即写入磁盘,所以rdb持久化不能保证redis事务的持久性。AOF持久化是先执行命令,执行成功后再将命令追加到日志文件中去(采用写后日志),即使aof每次执行命令后立即将日志文件刷盘,也可能丢失一条命令数据,因此aof也不能严格保证redis事务的持久性。
作者:Impossible安徒生
链接:https://www.jianshu.com/p/7f346f9d29c1
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RDB 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
1、RDB方式,是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
2、redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。
3、对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis极高的性能。
4、如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
5、虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
AOF 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
2、在重写即将开始之际,redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
3、与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
4、当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
5、当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。
1、RDB需要定时持久化,风险是可能会丢两次持久之间的数据,量可能很大。
2、AOF每秒fsync一次指令硬盘,如果硬盘IO慢,会阻塞父进程;风险是会丢失1秒多的数据;在Rewrite过程中,主进程把指令存到mem-buffer中,最后写盘时会阻塞主进程。
1、对于我们应该选择RDB还是AOF,官方的建议是两个同时使用。这样可以提供更可靠的持久化方案。
2、redis的备份和还原,可以借助第三方的工具redis-dump。
Redis通常被作为缓存组件,除了可以缓存数据,Redis还可以有以下功能: 最新列表功能,如果总数很大,尽量不要select a from db limit k 这样,可以用redisLPUSH命令构建List,一个个顺序塞进去; 排行榜应用,用到有序集合zset,每次插入数据会自动调整顺序值,保证value值按照一定顺序连续排列,然后使用Zrevrange方法获取排行榜 ; 计数器,由于Redis的命令都是原子性的,可以用incr,decr命令进行原子性操作,来构建技术系统,而且Redis是单线程,可以避免并发问题,
PS 为什么需要缓存? 随着内容信息越来越复杂,用户数和访问量越来越大,我们的应用需要支撑更多的并发量,我们应用服务器和数据库服务器所做的计算也越来越多,但是往往我们应用服务器资源有限,数据库每秒能接受的请求也是有限的,我们需要有效利用有限的资源来提供尽可能更大的吞吐量,就可以引入缓存,1-4中每个环节【标准流程: 用户请求从界面(浏览器或app界面(1))到网络转发(2)、应用服务(3)再到存储(数据库或文件系统(4)),然后返回界面呈现内容】中的请i去可以从缓存中直接获取目标数据并返回,从而减少计算量,有效提升响应速度。
应用场景:如果Redis只是用来从事只读的,并分担读压力的缓冲层,就可以不用持久化,即使Redis崩溃了,顶多是在一次启动Redis后开始读取,传统数据库或其他方式将将数据填满,所以不用涉及持久化。
如果Redis是从事写缓冲工作,如经常更新数据,在Redis中进行数据的更新,最后将结果刷入到传统数据库中,这是一个解决高并发,更新值,降低传统数据库负担的方式,就需要使用持久化,可根据应用逻辑和对数据容忍丢失度的要求来调整RDB和AOF文件的保存方式等级。
Redis的基本数据类型:
a、String
b、hash
c、list 可以做简单的消息队列功能
d、set 存放的是一堆不重复的值,可用作去重
e、sorted set 比set多一个权重参数score,集合中的元素能按score排列
为什么redis 快 : 1)是在内存操作 2)单线程,避免了频繁上下文切换 3)采用了非阻塞I/O多路复用机制
应用场景:
1、Redis的事务 号称QPS十万
可以用来做限流,使用incr命令,数据不停叠加,当大于我们限制的时间之后,就把它进行释放,这个过程中可以让它不访问我们的网站。
Expire 可以自动重新生效,设置24 hour 这个key会自动过期,但是 MySQL还需自己手动写脚本删除。
increby offset 偏移量,可以设置不同的Redis,用Redis集群,这样可以设置不同的步长进行增长(或不同的权重)。
2、Redis的事务 可用来解决热点查询问题
Redis可用于一些频繁操作并且是非事务性的操作,比如查询基本信息,查询权限等操作【Redis为弱事务,不支持原子性,并且为弱持久性】
3、各种数据类型常见应用场景:
String:
Setnx tian 1 执行结果为Integer 1
Setnx tian 2 执行结果为Integer 0
不可以更改(第二次不管改还是放,都为0,只允许当前的key存在1个)可以给锁添加一个加锁时间 ttl (time to live)
以上特性可以用于做分布式锁, 确保互斥;只能先del再改,但无法保证无死锁,原子性
使用NX命令。Setnx废弃
Set tian EX 10 NX
Expire,可以防止死锁,给其加了过期时间,使其有效时间内有互斥性
Set tian 1 EX 10 NX 命令 将tian这个key存在的生命周期设为10s,相当于把超时时间和NX操作结合
SET key value NX 效果等同于 SETNX key value
存在问题: 分布式锁误删怎么办?
一般存在业务时间和 加锁时间,而误删通常都是因为 业务时间>加锁时间
a、如果业务超时,则需要充分预计业务时间 , 锁快到期,业务没执行完,开启(守护线程),将锁重新进行续时操作。 确保锁的时间>业务时间。
b、如果不停的重试,还是业务时间>加锁时间(变相死锁),此时需要有重试次数的限制,强行打断
c、为了进一步保证分布式锁无误删情况, 由于 Set Nx只是保证了原子操作,delete的时候未判断是否是自己的锁,所以可以将key设置未productid或uuID或线程id,那么这个时候,delete时做equals方法对比,看是否为当前线程ID或... , 这样便可防止误删
Redis用redlock(Redis distributed lock)算法保证分布式集群的高可用性
Hash:
支持结构化存储方案(二维结构) 、xml文档
hset命令,可以设置一个value 。hmset命令可以设置多个value
hmset userinfo 12345:name liuqian 12345: age 23 12345:sex woman
然后用hmget命令可快速获取某个属性(不用在大量数据里进行遍历,然后再找)
然后可以用hmget命令可快速获取某个属性(不用在大量数据里进行遍历,然后再找)
总结,能很好的维护一条或多条信息
List队列: 消息时间线,最新消息 先进后出
key<String> value <obj[]>
命令: lpush A 1 2 3 4
lpop A 得到的结果是4 拿到新消息
rpop A 得到的结果是1 拿到老消息
Set: 可用于点赞,抽奖等活动,是无序且,一个集合里某个元素只能有一个
命令: Smembers 集合名称,查看集合元素
Spop 集合名称 数目, 从集合中随机弹出几个元素
Sadd 集合名称 集合元素
抽奖示例:
Sadd choujiang a b c d
Spop choujiang 2 (从集合里随机弹出2个元素)
Smembers choujiang 将不包含被弹出的元素
点赞示例:
Sadd like:9527 a b c
Scard like:9527 (统计点赞人数,将得到3)
Smembers like:9527 展示具体点赞人数 a,b,c
Srem like:9527 a 删除点赞的某个人
Smembers like:9527 a 可以判断给9527点赞的是否包含a这个人
Set还有一些运算,交集,并集,差集
很适合用于社交关注模型: 1、共同关注的人 2、我关注的人也关注她 3、可能认识的人
ZSet:有序集合 ,比set多了一个score ;
可用来判断哪家卖的多的场景
zadd mendian1 10 apple 20 orange 30 banana
zrange mendian1 0 -1 (可以withscore,带上分数,从小到大打印出来(有序))
微博:可看近7天,连续3天点击量最多的 ,展示7日排行前10点击量的
点击新闻:ZINCRBY hostNews:20190819 1 守护香港 (则20188月19日守护香港点击增加1)
展示当日排行前十点击的: ZREVRANGE hostNews:20190819 0 9 WITHSCORES
7日搜索榜单计算,ZUNIONSCORE hotNews:20190813 20190819 7 hostNews :20190813 hostNews:2019014........hostNews:20190819
展示7日排行前十:ZREVRANGE hostNews:20180813-20190819 0 9 WITHSCORES
ZADD key score member //往有序集合加元素
ZREM key member [member ...] //往有序集合key中删除元素
ZSCORE key member //返回集合key中元素member的分
ZINCRBY key increament member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop[WITHSCORES] 正序获取有序集合key从start到下标 stop 的元素
ZREVRANGE... 逆序获取
ZSet集合操作
并集计算
并集计算
bitmap:1byte=8bit
非黑即白的数据,
例子1、统计今年有多少人登录了我们的网站
例子2、连续上课3天的同学
例子3、找在一年中上课听达200天的同学
bitmap的默认初始值为0
setbit class 1 1 设置1号同学听课了
getbit class 1 得到1,表示1号同学听课
strlen class (Integer) 1 表示占用1个byte位
优点:
代码逻辑简单,mysql会更复杂
空间占用小, 1byte = 8bit
bitmap相当于分配一个bit数组, bit[]
而 1byte = 8 bit bit[0] = 1 , bit[1]=0 ,bit[2]=0.....等等
1个byte空间可以记录7个学号的信息如果超出1个byte,比如有9号同学,还会开辟一个新空间
听课统计某个同学次数:
setbit A 1 1
setbit A 2 1
setbit A 366 1
bitcount A 0 -1 返回3,即记录了A同学一年听了3次课
相关:缓存雪崩、缓存穿透、缓存击穿
缓存击穿:
缓存击穿类似缓存雪崩,缓存击穿是某个热点的key失效(缓存雪崩是大规模key失效),大并发集对其进行请求,就会造成大量请求缓存没有读到数据,从而导致高并发访问数据库,引起数据库压力剧增。
解决方案:1、使用互斥锁(mutex key),在缓存失效的时候,判断拿出来的值为空,不立即去访问数据库,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX(Set if not exists)或者Memcache的ADD去set一个mutex key,当操作返回成功时,再进行访问数据库操作并回设缓存,否则就重试整个get缓存的方法 ;2、 提前使用互斥锁, 在value内部设置一个超时值timeout1,timeout1比实际的memcache timeout,timeout2小,当从cache中读取到timeout1时,发现已经快过期,就马上延长timeout1并重新设置到cache,然后再从数据库加载数据并设置到cache中; 3、设置永不过期【可以物理设置永不过期,针对热点key不设置过期时间; 逻辑不过期:把过期时间存在key对应的 value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建】
解决:、1、【布隆过滤器,作用相当于筛选器】 可以设置误判率,误判率越小,误删概率就越小(但是代价是更低的性能和占用更大空间,因为误判率越小、哈希函数就越多、同一个key相应对应越多的的hash值,这些位置值都为1才算这个key存在)
所以要根据自己的业务来进行取舍,不是把误判率设置得越小越好
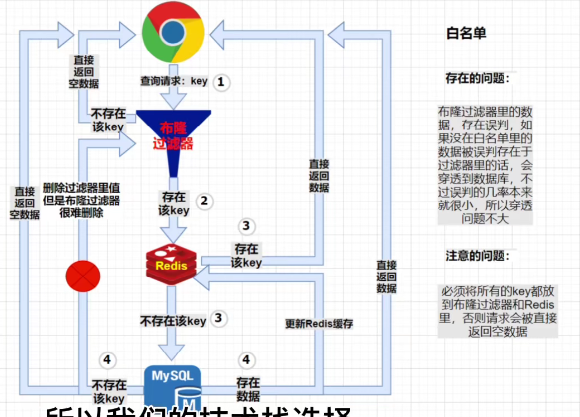
2、缓存淘汰机制
缓存雪崩:
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致大规模key在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案: 导致缓存雪崩的原因是1、Redis宕机 2、采用了相同的过期时间
所以我们可以均匀过期,设置不同的过期时间,让缓存失效的时间尽量均匀; 热点数据缓存永远不过期(物理、逻辑上)。
缓存穿透:
指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,如果恶意攻击不断请求数据库中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至导致数据库承受不住宕机崩溃。
解决方案:1、采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截,从而避免对底层存储系统的查询压力 2、如果一个查询返回的数据为空(不管数据不存在还是系统故障),我们仍把这个空结果进行缓存,过期时间设置较短,不超过5分钟。
————————————————
持久化部分内容原文链接:https://blog.csdn.net/ljheee/article/details/76284082
场景题:
微博评论如何设计数据库
直接用hash存,id content根据需求,自己控制缓存的field,评论时写redis缓存,修改、删除先操作缓存,将数据库修改、删除丢给消息队列处理。实现了异步。 但是Hash不支持范围查询
zadd 微博 评论id 评论id+评论的内容
id做scope,可以用id删除,后面的评论内容也能显示。
之前看到过这个问题,当时没有回,因为你举的例子看不太懂,隔了这么多天还没人回你,我就来说一下吧,你的例子让人看不太懂!上面的解决办法也就只能是按你说的实际例子来说一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号