RabbitMQ进阶--集群,分布式事务
一.RabbitMQ集群搭建
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。
在实际使用过程中多采取多机多实例部署方式,为了便于同学们练习搭建,有时候你不得不在一台机器上去搭建一个rabbitmq集群,本章主要针对单机多实例这种方式来进行开展。
搭建集群之前需要先检查是否RabbbitMQ可以正常的运行:
#查看rabbitMQ的进程
ps aux|grep rabbitmq
#查看rabbitMQ状态
systemctl status rabbitmq-server

注意:确保RabbitMQ可以运行的,确保完成之后,把单机版的RabbitMQ服务停止,后台看不到RabbitMQ的进程为止
systemctl stop rabbitmq-server
单机多实例搭建
场景:假设有两个rabbitmq节点,分别为rabbit-1, rabbit-2,rabbit-1作为主节点,rabbit-2作为从节点。
启动命令:RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit-1 rabbitmq-server -detached
结束命令:rabbitmqctl -n rabbit-1 stop
第一步:启动第一个节点rabbit-1
sudo RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit-1 rabbitmq-server start &
启动第二个节点rabbit-2
注意:web管理插件端口占用,所以还要指定其web插件占用的端口号
RABBITMQ_SERVER_START_ARGS=”-rabbitmq_management listener [{port,15673}]”

验证是否两个服务都启动了“
ps aux|grep rabbitmq
rabbit-1操作作为主节点
#停止应用
> sudo rabbitmqctl -n rabbit-1 stop_app
#目的是清除节点上的历史数据(如果不清除,无法将节点加入到集群)
> sudo rabbitmqctl -n rabbit-1 reset
#启动应用
> sudo rabbitmqctl -n rabbit-1 start_app
rabbit2操作为从节点
# 停止应用
> sudo rabbitmqctl -n rabbit-2 stop_app
# 目的是清除节点上的历史数据(如果不清除,无法将节点加入到集群)
> sudo rabbitmqctl -n rabbit-2 reset
# 将rabbit2节点加入到rabbit1(主节点)集群当中【Server-node服务器的主机名】
> sudo rabbitmqctl -n rabbit-2 join_cluster rabbit-1@'Server-node'
# 启动应用
> sudo rabbitmqctl -n rabbit-2 start_app
验证集群状态
sudo rabbitmqctl cluster_status -n rabbit-1

Web监控
注意在访问的时候:web结面的管理需要给15672 node-1 和15673的node-2 设置用户名和密码。如下:
#rabbit-1 配置
rabbitmqctl -n rabbit-1 add_user admin admin
rabbitmqctl -n rabbit-1 set_user_tags admin administrator
rabbitmqctl -n rabbit-1 set_permissions -p / admin ".*" ".*" ".*"
#rabbit-2 配置
rabbitmqctl -n rabbit-2 add_user admin admin
rabbitmqctl -n rabbit-2 set_user_tags admin administrator
rabbitmqctl -n rabbit-2 set_permissions -p / admin ".*" ".*" ".*"
主机访问端口15762,从机访问端口1673

Tips:
如果采用多机部署方式,需读取其中一个节点的cookie, 并复制到其他节点(节点之间通过cookie确定相互是否可通信)。cookie存放在/var/lib/rabbitmq/.erlang.cookie。
例如:主机名分别为rabbit-1、rabbit-2
1、逐个启动各节点
2、配置各节点的hosts文件( vim /etc/hosts)
ip1:rabbit-1
ip2:rabbit-2
其它步骤雷同单机部署方式
一主一从配置特点
RabbitMQ 集群部署可以提高消息服务的可用性和可靠性。在讨论一主一从(一个主节点和一个从节点)的配置特点之前,需要了解一些基本概念:
队列(Queue): RabbitMQ中用于存储消息的数据结构。
镜像队列(Mirrored Queue): 在集群环境中,为了提高队列的可用性,可以配置队列为镜像队列,这样消息会复制到多个节点上。
主节点(Master): 对于一个镜像队列,其中一个节点会被指定为主节点,负责处理所有对队列的操作请求。
从节点(Slave): 其他拥有该队列副本的节点称为从节点,在主节点不可用时,系统会选择一个从节点升级为新的主节点。
- 当主节点或者从节点创建声明交换机时,另外一个rabbitmq节点就会同步创建
- 当从节点宕机之后,主节点依旧可以工作;而主节点宕机之后,从节点不能独立工作
- 从节点的消息发送依赖于主节点
消息写入:当客户端发送消息到RabbitMQ集群时,这些消息首先到达队列的主节点。然后,根据镜像队列的配置,主节点会负责将消息复制到所有从节点上。
消息读取:消费者可以从任何一个节点消费消息。如果消费者连接到了一个从节点,该从节点会与对应的主节点通信来获取消息。
单机模式:一个rabbitMQ节点,集群模式:多个rabbitMQ节点连接在一起,本质都是由节点构成
二.分布式事务
分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性。
例如在下单场景下,库存和订单如果不在同一个节点上,就涉及分布式事务。
MQ 事务消息 异步场景,通用性较强,拓展性较高
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 Kafka 不支持。
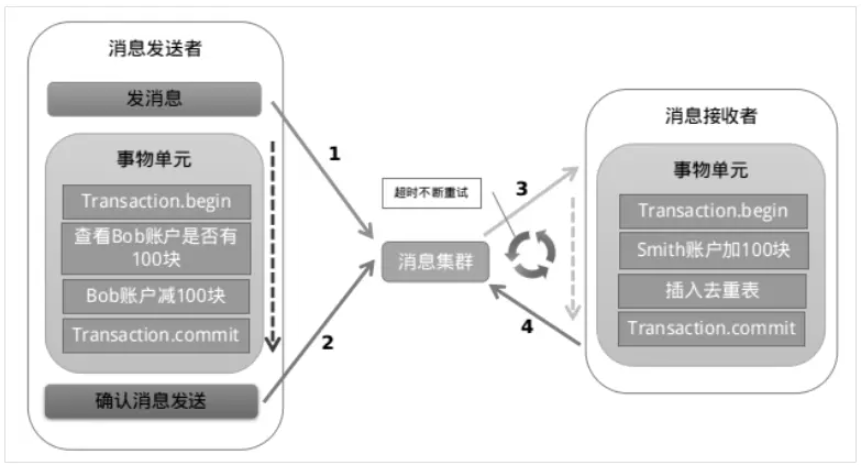
以阿里的 RabbitMQ 中间件为例,其思路大致为:
- 第一阶段Prepared消息,会拿到消息的地址。 第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
- 也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RabbitMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RabbitMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,RocketMQ事务消息部分代码也未开源。
分布式事务本身是一个技术难题,是没有一种完美的方案应对所有场景的,具体还是要根据业务场景去抉择吧。阿里RocketMQ去实现的分布式事务,现在也有除了很多分布式事务的协调器,比如LCN等,大家可以多去尝试。
------END-----

 浙公网安备 33010602011771号
浙公网安备 33010602011771号