Redis--Lesson07--Redis进阶3
一.Redis的主从复制
Redis的主从复制(Master-Slave Replication)是一种数据备份和高可用性的解决方案,通过这一机制,Redis实例之间可以实现数据的自动同步。具体来说,一个Redis服务器作为“主”节点(Master),负责处理所有的写操作;而一个或多个Redis服务器作为“从”节点(Slave),它们会自动从主节点复制数据,并且只处理读操作。主从复制的工作原理
初始化同步:当一个从节点启动时,它会向主节点发起一次全量同步请求。主节点会生成一个快照(RDB文件),并通过网络发送给从节点。同时,主节点还会将在这期间产生的所有写命令记录到一个缓冲区中。
部分重同步:在某些情况下,如网络短暂中断后,从节点重新连接到主节点时,不需要进行全量同步。Redis支持部分重同步(partial resynchronization),即从节点可以从之前同步的位置继续,只需要获取断开期间丢失的数据即可。
持续更新:一旦初始化同步完成,主节点上发生的任何改变都会实时地传播给从节点,确保数据的一致性。
优点:
- 读写分离:通过增加从节点数量,可以分散读取压力,提高系统性能。
- 数据冗余:提供了一种简单的数据冗余方式,增加了数据的安全性和系统的可靠性。
- 故障恢复:当主节点出现故障时,可以快速切换到从节点,减少系统停机时间。
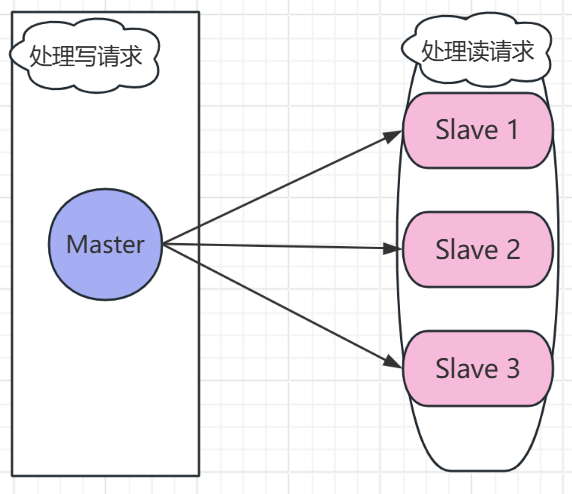
在主从复制模式中,使用读写分离,在实际的引用场景中,有80%的情况是在读操作,故而企业一般使用的就是使用一主二从!
一主二从环境配置
配置主从复制需要注意的是,一般redis默认开启master模式,也就是每个新启的服务都是主机,所以设置主从复制只需要将从机指向主机就好了
role:master
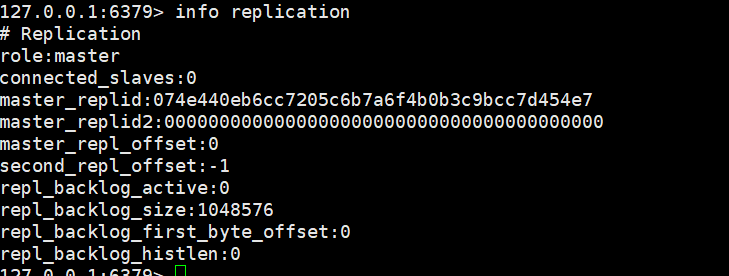
复制两分redis.config文件,方便启动不同端口的redis服务,简称一机多活模式:
复制的配置文件需要改4个位置,其它的默认就好
- 端口,端口重复肯定有redis启动不了
- pid文件
- log文件
- dump.rdb文件
修改完成之后就可以启动测试了
配置一主二从
由于默认redis都为主机模式,故而需要配置从机只需要将其中的主机改为从机就好了
slaveof host port 指定主机
127.0.0.1:6381> slaveof 127.0.0.1 6381 OK 127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.1 master_port:6381 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:0 master_link_down_since_seconds:1741859802 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:68c917c351ae60627d2d2f3c74c7a51937dbfdb0 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
在主机上进行写操作:
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379>
在主机进行读操作:
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379>
在从机进行读操作:
127.0.0.1:6380> get k1
"v1"
127.0.0.1:6380>
在从机上进行写操作:
127.0.0.1:6380> set k2 v2
(error) READONLY You can't write against a read only replica.
我们会发现,认定主机之后,本机就不能写入了,只能读取主机同步过来的数据
主从复制的基本流程
1.建立连接:当从节点启动时,它会尝试与指定的主节点建立连接,并请求进行一次全量同步。
2.全量同步(Full Resynchronization)
主节点收到从节点的同步请求后,开始执行一个后台保存操作(BGSAVE),生成一个RDB文件。同时,主节点将此期间所有客户端发送过来的写命令记录到一个缓冲区(repl-backlog buffer)中。一旦RDB文件创建完成,主节点会把这个RDB文件发送给从节点。从节点接收到RDB文件后,先清空自己的现有数据,然后加载这份RDB文件来更新数据集。最后,主节点会把在缓冲区中累积的所有写命令发送给从节点,以确保数据的最终一致性。
3.部分重同步(Partial Resynchronization)
在某些情况下,如网络中断后重新连接,Redis支持部分重同步。这意味着从节点可以从上次同步的位置继续,而不是每次都进行全量同步。这是通过使用复制积压缓冲区(replication backlog)和每个Redis实例都有一个唯一的运行ID(runid)实现的。当从节点断开并重新连接时,它可以发送其最后接收的偏移量和主服务器的运行ID。如果主服务器仍然持有该偏移量的数据,就可以直接从这部分开始同步,而不需要进行全量同步。
4.持续更新
完成初始同步后,主节点会持续地将所有的写操作异步地传播给所有已连接的从节点,保持数据的一致性。
二.Redis主从复制的基本模式
第一种
这种模式是最简单的,一个主节点直接连接多个从节点,当主节点down掉之后,所以从节点都不能写入,只能读取
第二种
串行连接,第一个为主节点 ,中间的为第一个的从节点,后一个的主节点
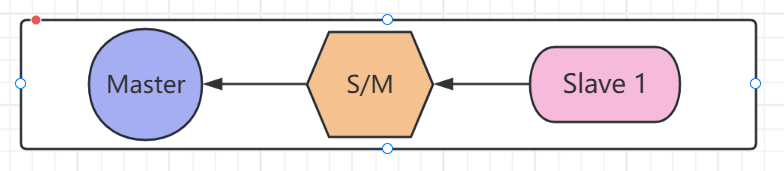
配置方式:
Master节点依旧不配置
S/M节点连接Master节点
Slave1节点连接S/M节点
在上面的模式中,由于主节点都有挂掉的风险,故而如果存在主节点挂掉之后,就不能进行写操作了,解决方式就是手动将从节点启动为主节点:
slaveof no one
执行这个命令会使当前的从节点停止与主节点的数据同步,并转换成一个独立的节点,不再作为任何主节点的复制节点。
三.了解哨兵模式
在Redis的主从复制架构中,为了确保系统的高可用性,通常需要实现一种机制来处理主节点(Master)的故障转移,即当主节点不可用时,能够自动或手动地将一个从节点(Slave)提升为新的主节点。这种机制称为“主从切换”或“故障转移”。Sentinel(哨兵)模式:Redis Sentinel 是 Redis 官方提供的一个高可用解决方案,它用于管理多个 Redis 实例,监控它们的状态,并在主节点发生故障时自动进行故障转移。
- 监控:Sentinel 持续监控主节点和从节点的健康状态。
- 通知:当检测到主节点失效时,Sentinel 会通过客户端配置的通知机制告知应用程序或其他服务。
- Sentinel 系统会选择一个从节点作为新的主节点。
- 将其他从节点重新配置为新主节点的从节点。
- 如果原主节点恢复后,它会被转换成新主节点的从节点(为了保证服务稳定)
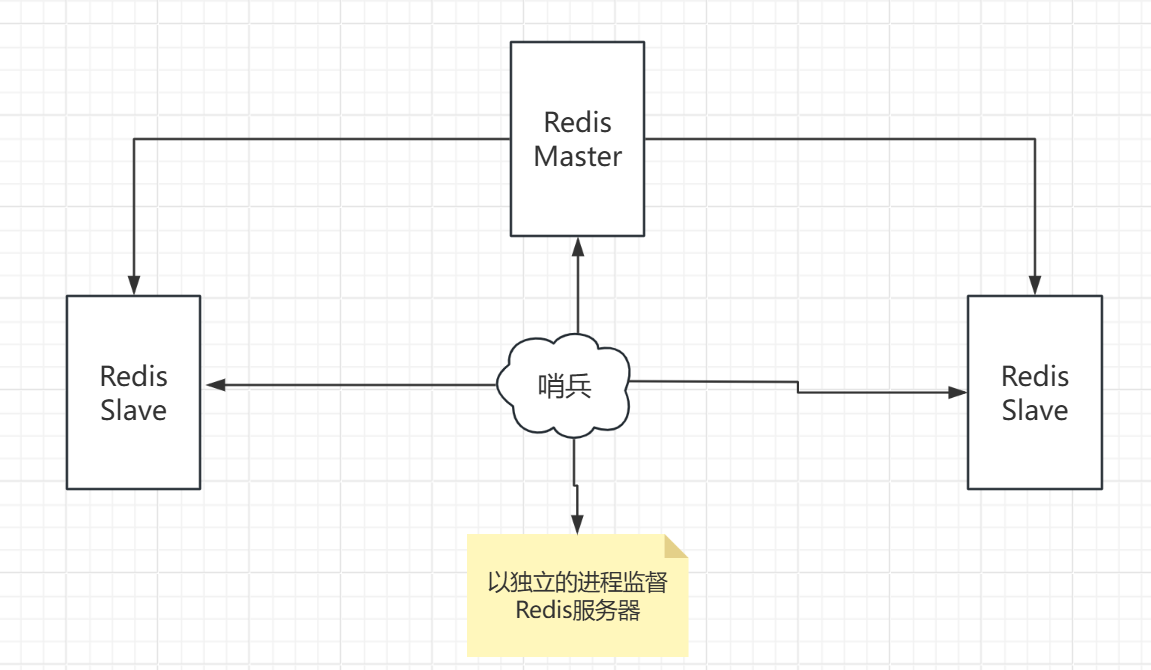
在如上图的监视过程中,使用单线程监视有一个缺点,那就是监视的线程可能会挂掉,如果挂掉之后就会导致主从切换失败;故而大多数情况下还是多哨兵模式,即多个哨兵监视,当有Master挂掉之后通过投票确定Master
假设服务器宕机后有一个哨兵发现,不会立马选举master,而是仅仅认为此主机不可用,此时为主观下线,等到其它的哨兵都发现之后,才会启动投票机制选举master,此时为客观下线
多哨兵模式:
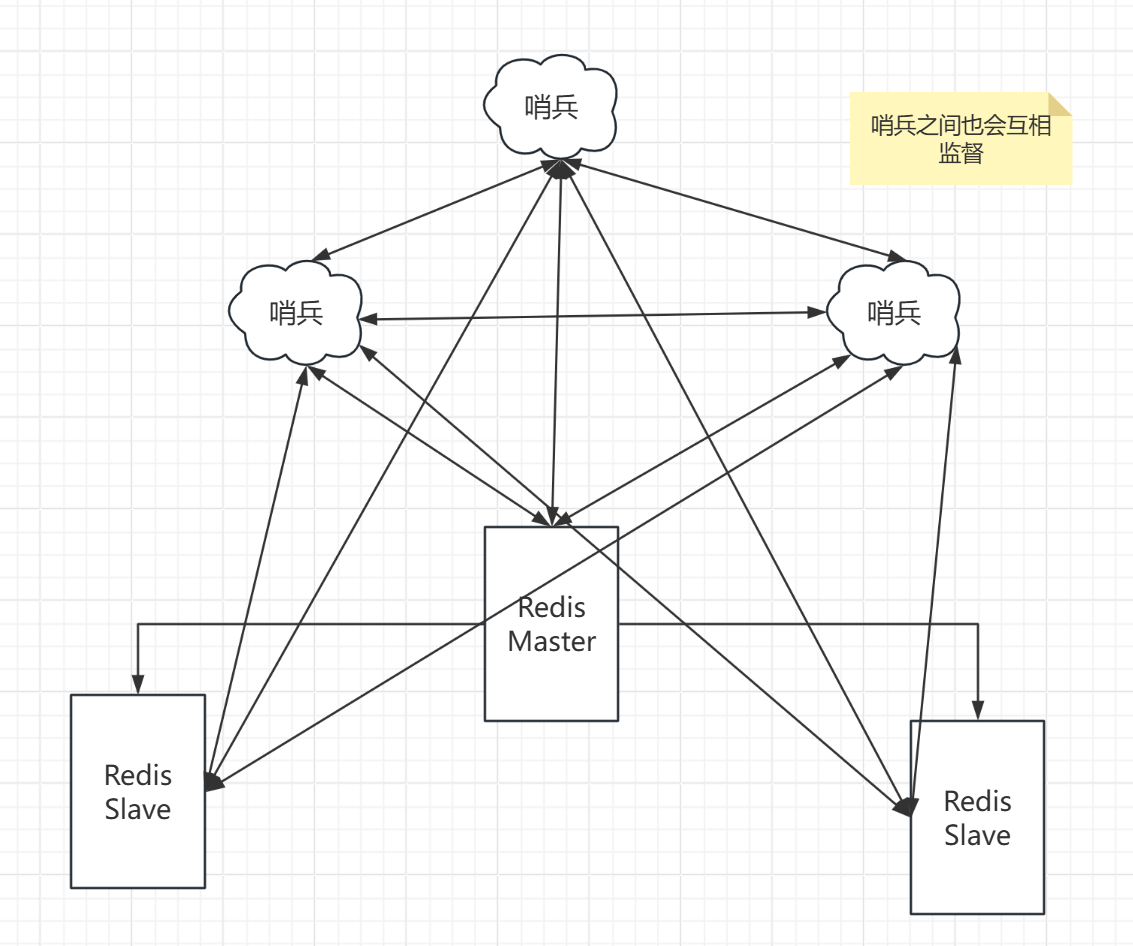
配置哨兵:
//修改sentinel文件
vim sentinel.conf
//配置sentinel.conf文件
sentinel monitor myredis 127.0.0.1 6379 1
启动哨兵模式:
redis-sentinel msfconfig/sentinel.conf
配置之后主机master为6379:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
关闭master服务,断开6379后:
127.0.0.1:6379> shutdown
not connected> exit
哨兵选举6380当了master,当然选举具有一顶点的随机性:
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:1
四.缓存穿透和雪崩
缓存穿透
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。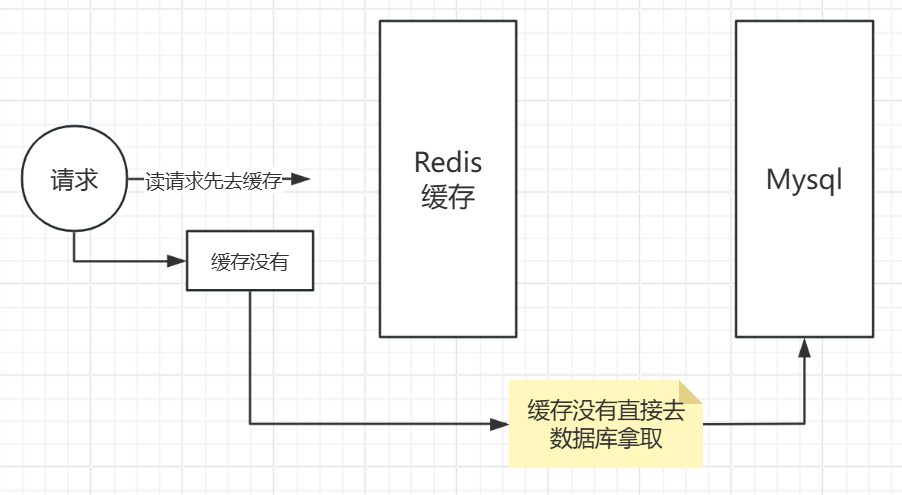
解决方案
布隆过滤器:是一种数据结构,对所有可能查询的参数以hash的形式存储,在控制层进行校验,不符合则丢弃,从而避免了对底层的存储系统的压力:
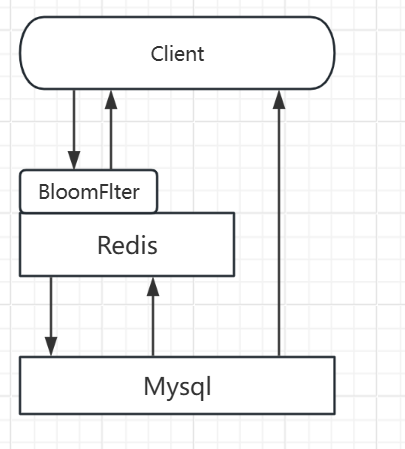
缓存空对象:如果存储不命中,即使返回空对象也将其缓存起来,同时设置一个过期时间,之后访问这个数据将从缓存中取值,保护后端数据
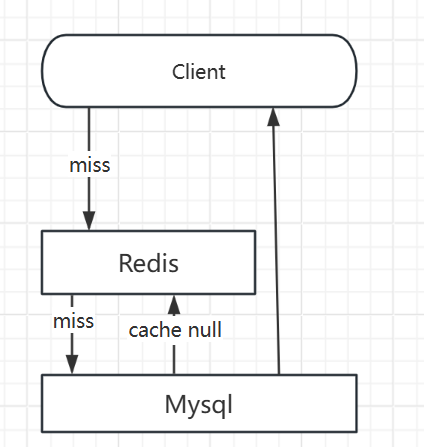
- 如果空值也需要存储,那么内存中会有很多空的键值,可能会浪费很多的存储空间
- 即使设置了过期时间,但是对于未过期这段时间来说,还是会出现和数据库不一致的情况
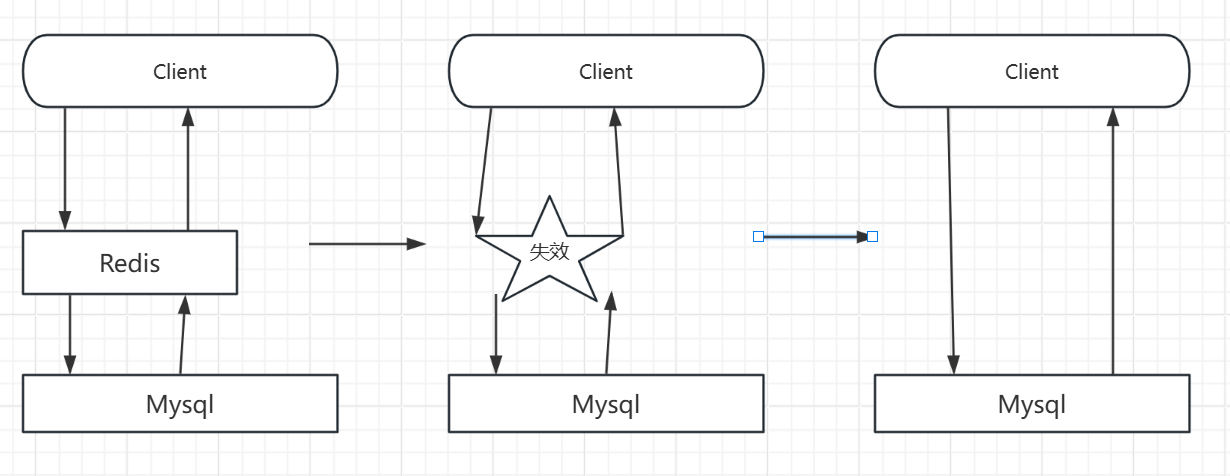
缓存击穿
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大。
解决方案
设置热点数据永不过期;从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后产生的问题。
加互斥锁:
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
Redis缓存雪崩指的是在某一时间段内,大量缓存数据同时失效或者Redis服务突然不可用,导致大量请求直接打到数据库等后端存储系统上,从而可能造成后端系统的负载骤增甚至崩溃的现象。这种情况对系统的稳定性构成了极大的威胁。详细解释
原因:通常由设置相同的过期时间给大量的key、Redis服务器宕机或网络故障等原因引起。
影响:当发生缓存雪崩时,原本应该被缓存处理的请求全部转向了后端存储,可能导致后端存储因无法承受突发的高负载而响应变慢甚至崩溃,进一步影响整个服务的可用性。
预防措施:
- 随机过期时间:为每个缓存设置不同的过期时间,避免大量缓存同时失效。
- 多级缓存机制:构建多级缓存体系,即使某一级缓存出现问题,下一级缓存仍能提供服务。
- 缓存预热:在应用启动或部署前预先加载热点数据到缓存中。
- 限流降级策略:当检测到后端压力过大时,采取限制流量或服务降级策略以保护核心服务的稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号