Tornado源码浅析
初识tornado
经典的hello world 案例:
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
application = tornado.web.Application([
(r"/index", MainHandler),
])
if __name__ == "__main__":
application.listen(8888)
tornado.ioloop.IOLoop.instance().start()
程序执行流程:
1、创建Application 对象,把正则表达式和类名MainHandler传入构造函数,即: tornado.web.Application(...)
2、执行Application 对象的 listen(...) 方法,即: application.listen(8888)
3、执行IOLoop类的类的 start() 方法,即:tornado.ioloop.IOLoop.instance().start()
程序实质:创建一个socket 监听8888端口,当请求到来时,根据请求的url和请求方式(get,post,put)来指定相应的类中的方法来处理本次请求。
在浏览器上访问:http://127.0.0.1:8888/index,则服务器给浏览器就会返回 Hello,world ,否则返回 404: Not Found(tornado内部定义的值), 即完成一次http请求和响应。
由上述分析,我们将整个Web框架分为两大部分:
-
待请求阶段(程序启动阶段),即:创建服务端socket并监听端口
-
处理请求阶段,即:当有客户端连接时,接受请求,并根据请求的不同做出相应的相应
待请求阶段(程序启动阶段)
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
application = tornado.web.Application([ ## <======= 1
(r"/index", MainHandler),
])
if __name__ == "__main__":
application.listen(8888) ## <======== 2
tornado.ioloop.IOLoop.instance().start() ## <======== 3
1. application = tornado.web.Application([(xxx,xxx)])


def __init__(self, handlers=None, default_host="", transforms=None, **settings): # 设置响应的编码和返回方式,对应的http相应头:Content-Encoding和Transfer-Encoding # Content-Encoding:gzip 表示对数据进行压缩,然后再返回给用户,从而减少流量的传输。 # Transfer-Encoding:chunck 表示数据的传送方式通过一块一块的传输。 if transforms is None: self.transforms = [] if settings.get("compress_response") or settings.get("gzip"): self.transforms.append(GZipContentEncoding) else: self.transforms = transforms # 将参数赋值为类的变量 self.handlers = [] self.named_handlers = {} self.default_host = default_host self.settings = settings # ui_modules和ui_methods用于在模版语言中扩展自定义输出 # 这里将tornado内置的ui_modules和ui_methods添加到类的成员变量self.ui_modules和self.ui_methods中 self.ui_modules = {'linkify': _linkify, 'xsrf_form_html': _xsrf_form_html, 'Template': TemplateModule, } self.ui_methods = {} # 获取获取用户自定义的ui_modules和ui_methods,并将他们添加到之前创建的成员变量self.ui_modules和self.ui_methods中 self._load_ui_modules(settings.get("ui_modules", {})) self._load_ui_methods(settings.get("ui_methods", {})) # 设置静态文件路径,设置方式则是通过正则表达式匹配url,让StaticFileHandler来处理匹配的url if self.settings.get("static_path"): # 从settings中读取key为static_path的值,用于设置静态文件路径 path = self.settings["static_path"] # 获取参数中传入的handlers,如果空则设置为空列表 handlers = list(handlers or []) # 静态文件前缀,默认是/static/ static_url_prefix = settings.get("static_url_prefix", "/static/") static_handler_class = settings.get("static_handler_class", StaticFileHandler) static_handler_args = settings.get("static_handler_args", {}) static_handler_args['path'] = path # 在参数中传入的handlers前再添加三个映射: # 【/static/.*】 --> StaticFileHandler # 【/(favicon\.ico)】 --> StaticFileHandler # 【/(robots\.txt)】 --> StaticFileHandler for pattern in [re.escape(static_url_prefix) + r"(.*)", r"/(favicon\.ico)", r"/(robots\.txt)"]: handlers.insert(0, (pattern, static_handler_class, static_handler_args)) # 执行本类的Application的add_handlers方法 # 此时,handlers是一个列表,其中的每个元素都是一个对应关系,即:url正则表达式和处理匹配该正则的url的Handler if handlers: self.add_handlers(".*$", handlers) #<================== # Automatically reload modified modules # 如果settings中设置了 debug 模式,那么就使用自动加载重启 if self.settings.get('debug'): self.settings.setdefault('autoreload', True) self.settings.setdefault('compiled_template_cache', False) self.settings.setdefault('static_hash_cache', False) self.settings.setdefault('serve_traceback', True) if self.settings.get('autoreload'): from tornado import autoreload autoreload.start()
def add_handlers(self, host_pattern, host_handlers): """Appends the given handlers to our handler list. Host patterns are processed sequentially in the order they were added. All matching patterns will be considered. """ # 如果主机模型最后没有结尾符,那么就为他添加一个结尾符。 if not host_pattern.endswith("$"): host_pattern += "$" handlers = [] # 对主机名先做一层路由映射,例如:http://www.alex.com 和 http://safe.alex.com # 即:safe对应一组url映射,www对应一组url映射,那么当请求到来时,先根据它做第一层匹配,之后再继续进入内部匹配。 # 对于第一层url映射来说,由于.*会匹配所有的url,所将 .* 的永远放在handlers列表的最后,不然 .* 就会截和了... # re.complie是编译正则表达式,以后请求来的时候只需要执行编译结果的match方法就可以去匹配了 if self.handlers and self.handlers[-1][0].pattern == '.*$': self.handlers.insert(-1, (re.compile(host_pattern), handlers)) else: self.handlers.append((re.compile(host_pattern), handlers)) # [(re.compile('.*$'), [])] # 遍历我们设置的和构造函数中添加的【url->Handler】映射,将url和对应的Handler封装到URLSpec类中(构造函数中会对url进行编译) # 并将所有的URLSpec对象添加到handlers列表中,而handlers列表和主机名模型组成一个元祖,添加到self.Handlers列表中。 for spec in host_handlers: if isinstance(spec, (tuple, list)): assert len(spec) in (2, 3, 4) spec = URLSpec(*spec) # <============== handlers.append(spec) if spec.name: if spec.name in self.named_handlers: app_log.warning( "Multiple handlers named %s; replacing previous value", spec.name) self.named_handlers[spec.name] = spec
上述代码主要完成了以下功能:加载配置信息和生成url映射,并且把所有的信息封装在一个application对象中。
加载的配置信息包括:
-
编码和返回方式信息
-
静态文件路径
-
ui_modules(模版语言中使用,暂时忽略)
-
ui_methods(模版语言中使用,暂时忽略)
-
是否debug模式运行
以上的所有配置信息,都可以在settings中配置,然后在创建Application对象时候,传入参数即可。如:application = tornado.web.Application([(r"/index", MainHandler),],**settings)
生成url映射:
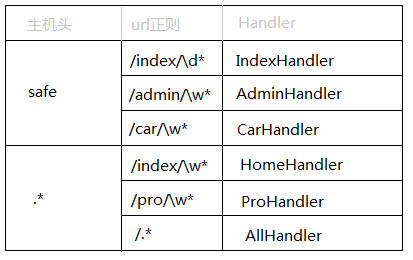
- 将url和对应的Handler添加到对应的主机前缀中,如:safe.index.com、www.auto.com
封装数据:
将配置信息和url映射关系封装到Application对象中,信息分别保存在Application对象的以下字段中:
-
self.transforms,保存着编码和返回方式信息
-
self.settings,保存着配置信息
-
self.ui_modules,保存着ui_modules信息
-
self.ui_methods,保存这ui_methods信息
-
self.handlers,保存着所有的主机名对应的Handlers,每个handlers则是url正则对应的Handler
2. application.listen(...)
def listen(self, port, address="", **kwargs):
from tornado.httpserver import HTTPServer
server = HTTPServer(self, **kwargs)
server.listen(port, address)
return server
这步执行application对象的listen方法,该方法内部又把之前包含各种信息的application对象封装到了一个HttpServer对象中,然后继续调用HttpServer对象的liseten方法。
class HTTPServer(TCPServer, Configurable,httputil.HTTPServerConnectionDelegate):
HttpServer 类继承了TCPServer类,
TCPServer类listen方法:
def listen(self, port, address=""):
sockets = bind_sockets(port, address=address)
self.add_sockets(sockets)
1.def bind_sockets 建立socket连接
bind_sockets2.add_sockets(sockets) 添加socket,进行监听
def add_sockets(self, sockets):
if self.io_loop is None:
self.io_loop = IOLoop.current() #1 <==============
# tornado.platform.select.SelectIOLoop object
# 设置成员变量self.io_loop为IOLoop的实例,注:IOLoop使用单例模式创建
for sock in sockets:
self._sockets[sock.fileno()] = sock
add_accept_handler(sock, self._handle_connection,io_loop=self.io_loop) #2 <=============
# 执行IOLoop的add_accept_handler方法,将socket句柄、self._handle_connection方法和io_loop对象当参数传入
def _handle_connection(self, connection, address): if self.ssl_options is not None: assert ssl, "Python 2.6+ and OpenSSL required for SSL" try: connection = ssl_wrap_socket(connection, self.ssl_options, server_side=True, do_handshake_on_connect=False) except ssl.SSLError as err: if err.args[0] == ssl.SSL_ERROR_EOF: return connection.close() else: raise except socket.error as err: # If the connection is closed immediately after it is created # (as in a port scan), we can get one of several errors. # wrap_socket makes an internal call to getpeername, # which may return either EINVAL (Mac OS X) or ENOTCONN # (Linux). If it returns ENOTCONN, this error is # silently swallowed by the ssl module, so we need to # catch another error later on (AttributeError in # SSLIOStream._do_ssl_handshake). # To test this behavior, try nmap with the -sT flag. # https://github.com/tornadoweb/tornado/pull/750 if errno_from_exception(err) in (errno.ECONNABORTED, errno.EINVAL): return connection.close() else: raise try: if self.ssl_options is not None: stream = SSLIOStream(connection, io_loop=self.io_loop, max_buffer_size=self.max_buffer_size, read_chunk_size=self.read_chunk_size) else: stream = IOStream(connection, io_loop=self.io_loop, max_buffer_size=self.max_buffer_size, read_chunk_size=self.read_chunk_size) future = self.handle_stream(stream, address) if future is not None: self.io_loop.add_future(future, lambda f: f.result()) except Exception: app_log.error("Error in connection callback", exc_info=True)
#1 创建的IOLoop对象为: SelectIOLoop (windows下)
def configurable_default(cls):
if hasattr(select, "epoll"):
from tornado.platform.epoll import EPollIOLoop
return EPollIOLoop
if hasattr(select, "kqueue"):
# Python 2.6+ on BSD or Mac
from tornado.platform.kqueue import KQueueIOLoop
return KQueueIOLoop
from tornado.platform.select import SelectIOLoop
return SelectIOLoop # <============
#2 然后执行add_accept_handler()
def add_accept_handler(sock, callback, io_loop=None): """Adds an `.IOLoop` event handler to accept new connections on ``sock``. When a connection is accepted, ``callback(connection, address)`` will be run (``connection`` is a socket object, and ``address`` is the address of the other end of the connection). Note that this signature is different from the ``callback(fd, events)`` signature used for `.IOLoop` handlers. .. versionchanged:: 4.1 The ``io_loop`` argument is deprecated. """ if io_loop is None: io_loop = IOLoop.current() def accept_handler(fd, events): # More connections may come in while we're handling callbacks; # to prevent starvation of other tasks we must limit the number # of connections we accept at a time. Ideally we would accept # up to the number of connections that were waiting when we # entered this method, but this information is not available # (and rearranging this method to call accept() as many times # as possible before running any callbacks would have adverse # effects on load balancing in multiprocess configurations). # Instead, we use the (default) listen backlog as a rough # heuristic for the number of connections we can reasonably # accept at once. for i in xrange(_DEFAULT_BACKLOG): try: connection, address = sock.accept() except socket.error as e: # _ERRNO_WOULDBLOCK indicate we have accepted every # connection that is available. if errno_from_exception(e) in _ERRNO_WOULDBLOCK: return # ECONNABORTED indicates that there was a connection # but it was closed while still in the accept queue. # (observed on FreeBSD). if errno_from_exception(e) == errno.ECONNABORTED: continue raise callback(connection, address) io_loop.add_handler(sock, accept_handler, IOLoop.READ)
执行其中的 io_loop.add_handler io_loop对象为: SelectIOLoop 所以执行它的add_handler()
class SelectIOLoop(PollIOLoop): # <============
def initialize(self, **kwargs):
super(SelectIOLoop, self).initialize(impl=_Select(), **kwargs)
执行PollIOLoop 的add_handler()
def add_handler(self, fd, handler, events):
fd, obj = self.split_fd(fd)
self._handlers[fd] = (obj, stack_context.wrap(handler)) #1 <==========
self._impl.register(fd, events | self.ERROR)
stack_context.wrap其实就是对函数进行一下封装,即:函数在不同情况下上下文信息可能不同。
def wrap(fn): """Returns a callable object that will restore the current `StackContext` when executed. Use this whenever saving a callback to be executed later in a different execution context (either in a different thread or asynchronously in the same thread). """ # Check if function is already wrapped if fn is None or hasattr(fn, '_wrapped'): return fn # Capture current stack head # TODO: Any other better way to store contexts and update them in wrapped function? cap_contexts = [_state.contexts] if not cap_contexts[0][0] and not cap_contexts[0][1]: # Fast path when there are no active contexts. def null_wrapper(*args, **kwargs): try: current_state = _state.contexts _state.contexts = cap_contexts[0] return fn(*args, **kwargs) finally: _state.contexts = current_state null_wrapper._wrapped = True return null_wrapper def wrapped(*args, **kwargs): ret = None try: # Capture old state current_state = _state.contexts # Remove deactivated items cap_contexts[0] = contexts = _remove_deactivated(cap_contexts[0]) # Force new state _state.contexts = contexts # Current exception exc = (None, None, None) top = None # Apply stack contexts last_ctx = 0 stack = contexts[0] # Apply state for n in stack: try: n.enter() last_ctx += 1 except: # Exception happened. Record exception info and store top-most handler exc = sys.exc_info() top = n.old_contexts[1] # Execute callback if no exception happened while restoring state if top is None: try: ret = fn(*args, **kwargs) except: exc = sys.exc_info() top = contexts[1] # If there was exception, try to handle it by going through the exception chain if top is not None: exc = _handle_exception(top, exc) else: # Otherwise take shorter path and run stack contexts in reverse order while last_ctx > 0: last_ctx -= 1 c = stack[last_ctx] try: c.exit(*exc) except: exc = sys.exc_info() top = c.old_contexts[1] break else: top = None # If if exception happened while unrolling, take longer exception handler path if top is not None: exc = _handle_exception(top, exc) # If exception was not handled, raise it if exc != (None, None, None): raise_exc_info(exc) finally: _state.contexts = current_state return ret wrapped._wrapped = True return wrapped
上述代码本质上就干了以下这么四件事:
-
把包含了各种配置信息的application对象封装到了HttpServer对象的request_callback字段中
-
创建了服务端socket对象
-
单例模式创建IOLoop对象,然后将socket对象句柄作为key,被封装了的函数_handle_connection作为value,添加到IOLoop对象的_handlers字段中
-
向epoll中注册监听服务端socket对象的读可用事件
3. tornado.ioloop.IOLoop.instance().start()
该步骤则就来执行epoll的epoll方法去轮询已经注册在epoll对象中的socket句柄,当有读可用信息时,则触发操作
def start(self): if self._running: raise RuntimeError("IOLoop is already running") self._setup_logging() if self._stopped: self._stopped = False return old_current = getattr(IOLoop._current, "instance", None) IOLoop._current.instance = self self._thread_ident = thread.get_ident() self._running = True # signal.set_wakeup_fd closes a race condition in event loops: # a signal may arrive at the beginning of select/poll/etc # before it goes into its interruptible sleep, so the signal # will be consumed without waking the select. The solution is # for the (C, synchronous) signal handler to write to a pipe, # which will then be seen by select. # # In python's signal handling semantics, this only matters on the # main thread (fortunately, set_wakeup_fd only works on the main # thread and will raise a ValueError otherwise). # # If someone has already set a wakeup fd, we don't want to # disturb it. This is an issue for twisted, which does its # SIGCHLD processing in response to its own wakeup fd being # written to. As long as the wakeup fd is registered on the IOLoop, # the loop will still wake up and everything should work. old_wakeup_fd = None if hasattr(signal, 'set_wakeup_fd') and os.name == 'posix': # requires python 2.6+, unix. set_wakeup_fd exists but crashes # the python process on windows. try: old_wakeup_fd = signal.set_wakeup_fd(self._waker.write_fileno()) if old_wakeup_fd != -1: # Already set, restore previous value. This is a little racy, # but there's no clean get_wakeup_fd and in real use the # IOLoop is just started once at the beginning. signal.set_wakeup_fd(old_wakeup_fd) old_wakeup_fd = None except ValueError: # Non-main thread, or the previous value of wakeup_fd # is no longer valid. old_wakeup_fd = None try: while True: # Prevent IO event starvation by delaying new callbacks # to the next iteration of the event loop. with self._callback_lock: callbacks = self._callbacks self._callbacks = [] # Add any timeouts that have come due to the callback list. # Do not run anything until we have determined which ones # are ready, so timeouts that call add_timeout cannot # schedule anything in this iteration. due_timeouts = [] if self._timeouts: now = self.time() while self._timeouts: if self._timeouts[0].callback is None: # The timeout was cancelled. Note that the # cancellation check is repeated below for timeouts # that are cancelled by another timeout or callback. heapq.heappop(self._timeouts) self._cancellations -= 1 elif self._timeouts[0].deadline <= now: due_timeouts.append(heapq.heappop(self._timeouts)) else: break if (self._cancellations > 512 and self._cancellations > (len(self._timeouts) >> 1)): # Clean up the timeout queue when it gets large and it's # more than half cancellations. self._cancellations = 0 self._timeouts = [x for x in self._timeouts if x.callback is not None] heapq.heapify(self._timeouts) for callback in callbacks: self._run_callback(callback) for timeout in due_timeouts: if timeout.callback is not None: self._run_callback(timeout.callback) # Closures may be holding on to a lot of memory, so allow # them to be freed before we go into our poll wait. callbacks = callback = due_timeouts = timeout = None if self._callbacks: # If any callbacks or timeouts called add_callback, # we don't want to wait in poll() before we run them. poll_timeout = 0.0 elif self._timeouts: # If there are any timeouts, schedule the first one. # Use self.time() instead of 'now' to account for time # spent running callbacks. poll_timeout = self._timeouts[0].deadline - self.time() poll_timeout = max(0, min(poll_timeout, _POLL_TIMEOUT)) else: # No timeouts and no callbacks, so use the default. poll_timeout = _POLL_TIMEOUT if not self._running: break if self._blocking_signal_threshold is not None: # clear alarm so it doesn't fire while poll is waiting for # events. signal.setitimer(signal.ITIMER_REAL, 0, 0) try: event_pairs = self._impl.poll(poll_timeout) except Exception as e: # Depending on python version and IOLoop implementation, # different exception types may be thrown and there are # two ways EINTR might be signaled: # * e.errno == errno.EINTR # * e.args is like (errno.EINTR, 'Interrupted system call') if errno_from_exception(e) == errno.EINTR: continue else: raise if self._blocking_signal_threshold is not None: signal.setitimer(signal.ITIMER_REAL, self._blocking_signal_threshold, 0) # Pop one fd at a time from the set of pending fds and run # its handler. Since that handler may perform actions on # other file descriptors, there may be reentrant calls to # this IOLoop that modify self._events self._events.update(event_pairs) while self._events: fd, events = self._events.popitem() try: fd_obj, handler_func = self._handlers[fd] handler_func(fd_obj, events) except (OSError, IOError) as e: if errno_from_exception(e) == errno.EPIPE: # Happens when the client closes the connection pass else: self.handle_callback_exception(self._handlers.get(fd)) except Exception: self.handle_callback_exception(self._handlers.get(fd)) fd_obj = handler_func = None finally: # reset the stopped flag so another start/stop pair can be issued self._stopped = False if self._blocking_signal_threshold is not None: signal.setitimer(signal.ITIMER_REAL, 0, 0) IOLoop._current.instance = old_current if old_wakeup_fd is not None: signal.set_wakeup_fd(old_wakeup_fd)
对于上述代码,执行start方法后,程序就进入“死循环”,也就是会一直不停的轮询的去检查是否有请求到来,
如果有请求到达,则执行封装了HttpServer类的_handle_connection方法和相关上下文的stack_context.wrap(handler)
请求来了
轮询过程中,当有请求到达时,先执行, accept_handler 接收请求地址,调用callback方法,即: _handle_connection()
def add_accept_handler(sock, callback, io_loop=None):
if io_loop is None:
io_loop = IOLoop.current()
def accept_handler(fd, events):
for i in xrange(_DEFAULT_BACKLOG):
try:
connection, address = sock.accept()
except socket.error as e:
# _ERRNO_WOULDBLOCK indicate we have accepted every
# connection that is available.
if errno_from_exception(e) in _ERRNO_WOULDBLOCK:
return
# ECONNABORTED indicates that there was a connection
# but it was closed while still in the accept queue.
# (observed on FreeBSD).
if errno_from_exception(e) == errno.ECONNABORTED:
continue
raise
callback(connection, address) # <=============
io_loop.add_handler(sock, accept_handler, IOLoop.READ)
创建封装了客户端socket对象和IOLoop对象的IOStream实例(用于之后获取或输出数据)。
def _handle_connection(self, connection, address):
# ... 省略
try:
if self.ssl_options is not None:
# ...省略
else:
stream = IOStream(connection, io_loop=self.io_loop,
max_buffer_size=self.max_buffer_size,
read_chunk_size=self.read_chunk_size)
future = self.handle_stream(stream, address)
if future is not None:
self.io_loop.add_future(future, lambda f: f.result())
except Exception:
app_log.error("Error in connection callback", exc_info=True)
class IOStream(BaseIOStream): def __init__(self, socket, *args, **kwargs): self.socket = socket self.socket.setblocking(False) super(IOStream, self).__init__(*args, **kwargs)
class BaseIOStream(object): """A utility class to write to and read from a non-blocking file or socket. We support a non-blocking ``write()`` and a family of ``read_*()`` methods. All of the methods take an optional ``callback`` argument and return a `.Future` only if no callback is given. When the operation completes, the callback will be run or the `.Future` will resolve with the data read (or ``None`` for ``write()``). All outstanding ``Futures`` will resolve with a `StreamClosedError` when the stream is closed; users of the callback interface will be notified via `.BaseIOStream.set_close_callback` instead. When a stream is closed due to an error, the IOStream's ``error`` attribute contains the exception object. Subclasses must implement `fileno`, `close_fd`, `write_to_fd`, `read_from_fd`, and optionally `get_fd_error`. """ def __init__(self, io_loop=None, max_buffer_size=None, read_chunk_size=None, max_write_buffer_size=None): """`BaseIOStream` constructor. :arg io_loop: The `.IOLoop` to use; defaults to `.IOLoop.current`. Deprecated since Tornado 4.1. :arg max_buffer_size: Maximum amount of incoming data to buffer; defaults to 100MB. :arg read_chunk_size: Amount of data to read at one time from the underlying transport; defaults to 64KB. :arg max_write_buffer_size: Amount of outgoing data to buffer; defaults to unlimited. .. versionchanged:: 4.0 Add the ``max_write_buffer_size`` parameter. Changed default ``read_chunk_size`` to 64KB. """ self.io_loop = io_loop or ioloop.IOLoop.current() self.max_buffer_size = max_buffer_size or 104857600 # A chunk size that is too close to max_buffer_size can cause # spurious failures. self.read_chunk_size = min(read_chunk_size or 65536, self.max_buffer_size // 2) self.max_write_buffer_size = max_write_buffer_size self.error = None self._read_buffer = collections.deque() self._write_buffer = collections.deque() self._read_buffer_size = 0 self._write_buffer_size = 0 self._write_buffer_frozen = False self._read_delimiter = None self._read_regex = None self._read_max_bytes = None self._read_bytes = None self._read_partial = False self._read_until_close = False self._read_callback = None self._read_future = None self._streaming_callback = None self._write_callback = None self._write_future = None self._close_callback = None self._connect_callback = None self._connect_future = None # _ssl_connect_future should be defined in SSLIOStream # but it's here so we can clean it up in maybe_run_close_callback. # TODO: refactor that so subclasses can add additional futures # to be cancelled. self._ssl_connect_future = None self._connecting = False self._state = None self._pending_callbacks = 0 self._closed = False
1.tornado.web.RequestHandler
这是所有业务处理handler需要继承的父类,接下来,介绍一些RequestHandler类中常用的一些方法:
#1 initialize
def __init__(self, application, request, **kwargs):
super(RequestHandler, self).__init__()
self.application = application
self.request = request
self._headers_written = False
self._finished = False
self._auto_finish = True
self._transforms = None # will be set in _execute
self._prepared_future = None
self._headers = None # type: httputil.HTTPHeaders
self.path_args = None
self.path_kwargs = None
self.ui = ObjectDict((n, self._ui_method(m)) for n, m in
application.ui_methods.items())
# UIModules are available as both `modules` and `_tt_modules` in the
# template namespace. Historically only `modules` was available
# but could be clobbered by user additions to the namespace.
# The template {% module %} directive looks in `_tt_modules` to avoid
# possible conflicts.
self.ui["_tt_modules"] = _UIModuleNamespace(self,
application.ui_modules)
self.ui["modules"] = self.ui["_tt_modules"]
self.clear()
self.request.connection.set_close_callback(self.on_connection_close)
self.initialize(**kwargs)
def initialize(self):
pass
从源码中可以看出initialize函数会在RequestHandler类初始化的时候执行,但是源码中initialize函数并没有做任何事情,
这其实是tornado为我们预留的修改源码的地方,这就允许程序在执行所有的handler前首先执行我们在initialize中定义的方法。
#2 write
def write(self, chunk):
if self._finished:
raise RuntimeError("Cannot write() after finish()")
if not isinstance(chunk, (bytes, unicode_type, dict)):
message = "write() only accepts bytes, unicode, and dict objects"
if isinstance(chunk, list):
message += ". Lists not accepted for security reasons; see http://www.tornadoweb.org/en/stable/web.html#tornado.web.RequestHandler.write"
raise TypeError(message)
if isinstance(chunk, dict):
chunk = escape.json_encode(chunk)
self.set_header("Content-Type", "application/json; charset=UTF-8")
chunk = utf8(chunk)
self._write_buffer.append(chunk)
write方法接收字典和字符串类型的参数,如果用户传来的数据是字典类型,源码中会自动用json对字典进行序列化,最终序列化成字符串。
self._write_buffer是源码中定义的一个临时存放需要输出的字符串的地方,是列表形式。
#3 flush
def flush(self, include_footers=False, callback=None):
chunk = b"".join(self._write_buffer)
self._write_buffer = []
if not self._headers_written:
self._headers_written = True
for transform in self._transforms:
self._status_code, self._headers, chunk = \
transform.transform_first_chunk(
self._status_code, self._headers,
chunk, include_footers)
if self.request.method == "HEAD":
chunk = None
if hasattr(self, "_new_cookie"):
for cookie in self._new_cookie.values():
self.add_header("Set-Cookie", cookie.OutputString(None))
start_line = httputil.ResponseStartLine('',
self._status_code,
self._reason)
return self.request.connection.write_headers(
start_line, self._headers, chunk, callback=callback)
else:
for transform in self._transforms:
chunk = transform.transform_chunk(chunk, include_footers)
if self.request.method != "HEAD":
return self.request.connection.write(chunk, callback=callback)
else:
future = Future()
future.set_result(None)
return future
flush方法会self._write_buffer列表中的所有元素拼接成字符串,并赋值给chunk,然后清空self._write_buffer列表,然后设置请求头,最终调用request.write方法在前端页面显示。
#4 render
def render(self, template_name, **kwargs):
"""Renders the template with the given arguments as the response."""
if self._finished:
raise RuntimeError("Cannot render() after finish()")
html = self.render_string(template_name, **kwargs)
# Insert the additional JS and CSS added by the modules on the page
js_embed = []
js_files = []
css_embed = []
css_files = []
html_heads = []
html_bodies = []
由上述源码可看出render方法是根据参数渲染模板:
js和css部分的源码:
for module in getattr(self, "_active_modules", {}).values():
embed_part = module.embedded_javascript()
if embed_part:
js_embed.append(utf8(embed_part))
file_part = module.javascript_files()
if file_part:
if isinstance(file_part, (unicode_type, bytes)):
js_files.append(file_part)
else:
js_files.extend(file_part)
embed_part = module.embedded_css()
if embed_part:
css_embed.append(utf8(embed_part))
file_part = module.css_files()
if file_part:
if isinstance(file_part, (unicode_type, bytes)):
css_files.append(file_part)
else:
css_files.extend(file_part)
head_part = module.html_head()
if head_part:
html_heads.append(utf8(head_part))
body_part = module.html_body()
if body_part:
html_bodies.append(utf8(body_part))
由上述源码可看出,静态文件(以JavaScript为例,css是类似的)的渲染流程是:
首先通过module.embedded_javascript() 获取需要插入JavaScript字符串,添加到js_embed 列表中;
进而通过module.javascript_files()获取已有的列表格式的JavaScript files,最终将它加入js_files.
下面对js_embed和js_files做进一步介绍:
js_embed源码:
if js_embed:
js = b'<script type="text/javascript">\n//<![CDATA[\n' + \
b'\n'.join(js_embed) + b'\n//]]>\n</script>'
sloc = html.rindex(b'</body>')
html = html[:sloc] + js + b'\n' + html[sloc:]
上图源码即生成script标签,这是一些我们自己定义的一些JavaScript代码;最终是通过字符串拼接方式插入到整个html中。
js_files源码:
if js_files:
# Maintain order of JavaScript files given by modules
paths = []
unique_paths = set()
for path in js_files:
if not is_absolute(path):
path = self.static_url(path)
if path not in unique_paths:
paths.append(path)
unique_paths.add(path)
js = ''.join('<script src="' + escape.xhtml_escape(p) +
'" type="text/javascript"></script>'
for p in paths)
sloc = html.rindex(b'</body>')
html = html[:sloc] + utf8(js) + b'\n' + html[sloc:]
上述源码即生成script标签,这是一些需要引入的JavaScript代码块;最终是通过字符串拼接方式插入到整个html中。
需要注意的是:其中静态路径是调用self.static_url(path)实现的。
def static_url(self, path, include_host=None, **kwargs):
self.require_setting("static_path", "static_url")
get_url = self.settings.get("static_handler_class",
StaticFileHandler).make_static_url
if include_host is None:
include_host = getattr(self, "include_host", False)
if include_host:
base = self.request.protocol + "://" + self.request.host
else:
base = ""
return base + get_url(self.settings, path, **kwargs)
由上述代码可看出:源码首先会判断用户有没有设置静态路径的前缀,然后将静态路径与相对路径进行拼接成绝对路径,
接下来按照绝对路径打开文件,并对文件内容(f.read())做md5加密,最终将根目录+静态路径前缀+相对路径拼接在前端html中展示。
#5 render_string
1. 创建Loader对象,并执行load方法
-- 通过open函数打开html文件并读取内容,并将内容作为参数又创建一个 Template 对象
-- 当执行Template的 __init__ 方法时,根据模板语言的标签 {{}}、{%%}等分割并html文件,最后生成一个字符串表示的函数
2. 获取所有要嵌入到html模板中的变量,包括:用户返回和框架默认
3. 执行Template对象的generate方法
-- 编译字符串表示的函数,并将用户定义的值和框架默认的值作为全局变量
-- 执行被编译的函数获取被嵌套了数据的内容,然后将内容返回(用于响应给请求客户端)
def render_string(self, template_name, **kwargs):
template_path = self.get_template_path()
if not template_path:
frame = sys._getframe(0)
web_file = frame.f_code.co_filename
while frame.f_code.co_filename == web_file:
frame = frame.f_back
template_path = os.path.dirname(frame.f_code.co_filename)
with RequestHandler._template_loader_lock:
if template_path not in RequestHandler._template_loaders:
loader = self.create_template_loader(template_path)
RequestHandler._template_loaders[template_path] = loader
else:
loader = RequestHandler._template_loaders[template_path]
t = loader.load(template_name)
namespace = self.get_template_namespace()
namespace.update(kwargs)
return t.generate(**namespace)
示例html:

源码模板语言处理部分的截图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号