【CUDA并行程序设计系列(3)】CUDA线程模型
前言
CUDA并行程序设计系列是本人在学习CUDA时整理的资料,内容大都来源于对《CUDA并行程序设计:GPU编程指南》、《GPU高性能编程CUDA实战》和CUDA Toolkit Documentation的整理。通过本系列整体介绍CUDA并行程序设计。内容包括GPU简介、CUDA简介、环境搭建、线程模型、内存、原子操作、同步、流和多GPU架构等。
本系列目录:
- 【CUDA并行程序设计系列(1)】GPU技术简介
- 【CUDA并行程序设计系列(2)】CUDA简介及CUDA初步编程
- 【CUDA并行程序设计系列(3)】CUDA线程模型
- 【CUDA并行程序设计系列(4)】CUDA内存
- 【CUDA并行程序设计系列(5)】CUDA原子操作与同步
- 【CUDA并行程序设计系列(6)】CUDA流与多GPU
- 关于CUDA的一些学习资料
在前一章的代码虽然是在GPU上执行,但并没有涉及到并行运行。GPU计算的应用情景在很大程度上取决于能否从许多问题中发掘出大规模并行性。本文将介绍CUDA的线程模型,通过实例代码(矢量加法和矩阵加法)演示CUDA下的并行程序设计。
矢量加法
我们通过比较在CPU和GPU的矢量加法的例子来看CUDA的并行执行,矢量加法CPU的代码如下:
#include <stdio.h>
#define N 10
void vecAdd(int *a, int *b, int *c)
{
int tid = 0;
while (tid < N)
{
c[tid] = a[tid] + b[tid];
++tid;
}
}
int main(void)
{
int a[N], b[N], c[N];
for (int i = 0; i < N; ++i)
{
a[i] = -i;
b[i] = i * i;
}
vecAdd (a, b, c);
for (int i = 0; i < N; ++i)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
return 0;
}
GPU实现的代码如下:
#include <stdio.h>
#define N 10
__global__ void vecAdd(int *a, int *b, int *c)
{
int tid = threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main(void)
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
for (int i = 0; i < N; ++i)
{
a[i] = -i;
b[i] = i * i;
}
cudaMalloc( (void **)&dev_a, N * sizeof(int) );
cudaMalloc( (void **)&dev_b, N * sizeof(int) );
cudaMalloc( (void **)&dev_c, N * sizeof(int) );
cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice );
cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice );
vecAdd<<<1, N>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost );
for (int i = 0; i < N; ++i)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
关于cudaMalloc()、cudaMemcpy()在前一章已经讲过,这里不再解释。通过比较可以看到,这两段代码非常相似,主要区别有两点:
-
调用核函数时使用
vecAdd<<<1, N>>>(dev_a, dev_b, dev_c)。 -
核函数
vecAdd中的for循环不见了,还使用了一个未定义的threadIdx。
使用<<<...>>>启动核函数是告诉运行时如何启动核函数,在这两个参数中,第一个参数表示设备在执行核函数数使用的并行线程块(block)的数量,第二个参数表示每个线程块启动线程(thread)的数量。显然,本例中启动了1个线程块,每个线程块启动N个线程,每个线程将并行运行核函数。关于线程、线程块将在下一节解释。
这种运行方式引出了一个问题:既然GPU将运行核函数的N各副本,那如何在代码中知道当前正在运行的是哪一个线程?这时就要使用内置的threadIdx,threadIdx.x代表当前线程的编号,这样就可以计算位于这个索引出得数据,N个线程,每个线程处理一个索引,就完成了矢量加法。
代码也可以改下成如下方式:
__global__ void vecAdd(int *a, int *b, int *c)
{
int tid = blockIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main(void)
{
···
vecAdd<<<N, 1>>>(dev_a, dev_b, dev_c);
···
}
这将启动N个线程块,每个线程块启动一个线程,内置的blockIdx.x代表当前线程块的编号。
线程、线程块以及线程网格
线程是并行程序的基本构建块,和C语言的线程是一样的。在前面已经看到,一个线程块中可以有多个线程。事实上,线程块又组成了一个线程网络(grid)。线程网格(Grid)、线程块(Block)和线程(Thread)的结构图如下所示:
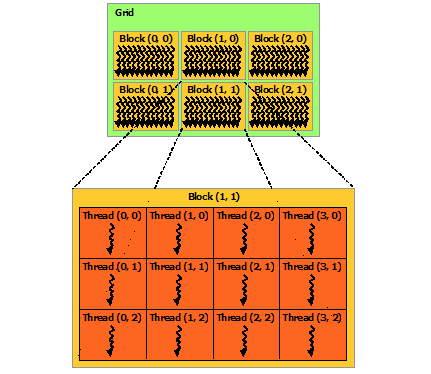
<<<...>>> 中的参数类型是int或dim3,dim3是CUDA定义的一种数据类型,代表一个三维的数据(x,y,z),不过目前为止第三维只能是1。因此,可以用这个数据结构创建一个二维的线程块和线程网络。如上图,每个线程块的X轴方向上开启了4个线程,Y轴方向上开启了3个线程,每个线程块开启了4 * 3=12个线程。在线程网络上,X轴方向上开启了3个线程块,Y轴方向上开启了2个线程块,线程网格共有3 * 2=6个线程块。整个线程网络线程总数为(4 * 3)*(3 * 2)=72,当然,这只是一个小的例子,在实际的程序的线程数可能是这个数量的1万倍甚至更多。
由于程序中可能不止用到一个维度的线程索引,有可能用到X轴和Y轴两个维度,因此,前面在核函数中使用threadIdx.x、blockIdx.x就不适用了,需要修改核函数,计算不同维度的索引。从上图也可以看出,threadIdx.x、blockIdx.x成了相对索引。除了计算不同维度的相对索引外,有时可能还需要线性计算出相对整个线程网络的绝对线程索引。因此,CUDA定义了一些新的数据结构来保存线程索引相关量:
- gridDim.x-线程网络X维度上线程块的数量
- gridDim.y-线程网络Y维度上线程块的数量
- blockDim.x-一个线程块X维度上的线程数量
- blockDim.y-一个线程块Y维度上的线程数量
- blockIdx.x-线程网络X维度上的线程块索引
- blockIdx.y-线程网络Y维度上的线程块索引
- threadIdx.x-线程块X维度上的线程索引
- threadIdx.y-线程块Y维度上的线程索引
图中的各个对应的值为:
- gridDim.x=3
- gridDim.y=2
- blockDim.x=4
- blockDim.y=3
要计算当前线程相对于整个线程网络的绝对索引,可使用如下代码:
idx = (blockIdx.x * blockDim.x) + threadIdx.x;
idy = (blockIdx.y * blockDim.y) + threadIdx.y;
thread_idx = ((gridDim.x * blockDim.y) * idy) + idx;
矩阵加法
本节用一个计算矩阵加法的CUDA C代码来展示二维线程模型,因为矩阵是二维的,所以非常适合使用二维线程来处理。我们将在每个线程块中分别在X维度和Y维度启动TPB个线程。
#include <stdio.h>
#define N 1024
#define TPB 16
__global__ void MatAdd(int A[N][N], int B[N][N], int C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int a[N][N], b[N][N], c[N][N];
int main()
{
//int a[N][N], b[N][N], c[N][N];
int (*dev_a)[N], (*dev_b)[N], (*dev_c)[N];
for (int y = 0; y < N; ++y)
{
for (int x = 0; x < N; ++x)
{
a[x][y] = x + y * N;
b[x][y] = x * x + y * N;
}
}
cudaMalloc( &dev_a, N * N * sizeof(int) );
cudaMalloc( &dev_b, N * N * sizeof(int) );
cudaMalloc( &dev_c, N * N * sizeof(int) );
cudaMemcpy(dev_a, a, N * N * sizeof(int), cudaMemcpyHostToDevice );
cudaMemcpy(dev_b, b, N * N * sizeof(int), cudaMemcpyHostToDevice );
dim3 threadsPerBlock(TPB, TPB);
dim3 numBlocks( (N + TPB - 1) / threadsPerBlock.x, (N + TPB -1) / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N * N * sizeof(int), cudaMemcpyDeviceToHost );
int temp = 0;
for (int y = 0; y < N; ++y)
{
for (int x = 0; x < N; ++x)
{
temp = a[x][y] + b[x][y];
if (temp != c[x][y])
{
printf ("Failure at %d %d\n", x, y);
}
}
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
在这段代码中,矩阵中每个索引使用一个线程来计算,通过
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
来计算当前线程的绝对坐标,该坐标正好对应于矩阵的位置。
需要注意的是,C语言使用太大的数组时,最好把数组定义为全局的,否则受栈的限制,可能会报错:
Segmentation fault: 11
参考文献
- 库克. CUDA并行程序设计. 机械工业出版社, 2014.
- 桑德斯. GPU高性能编程CUDA实战. 机械工业出版社, 2011.
- CUDA C Programming Guide
- CUDA Toolkit Documentation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号