图
一. 思维导图
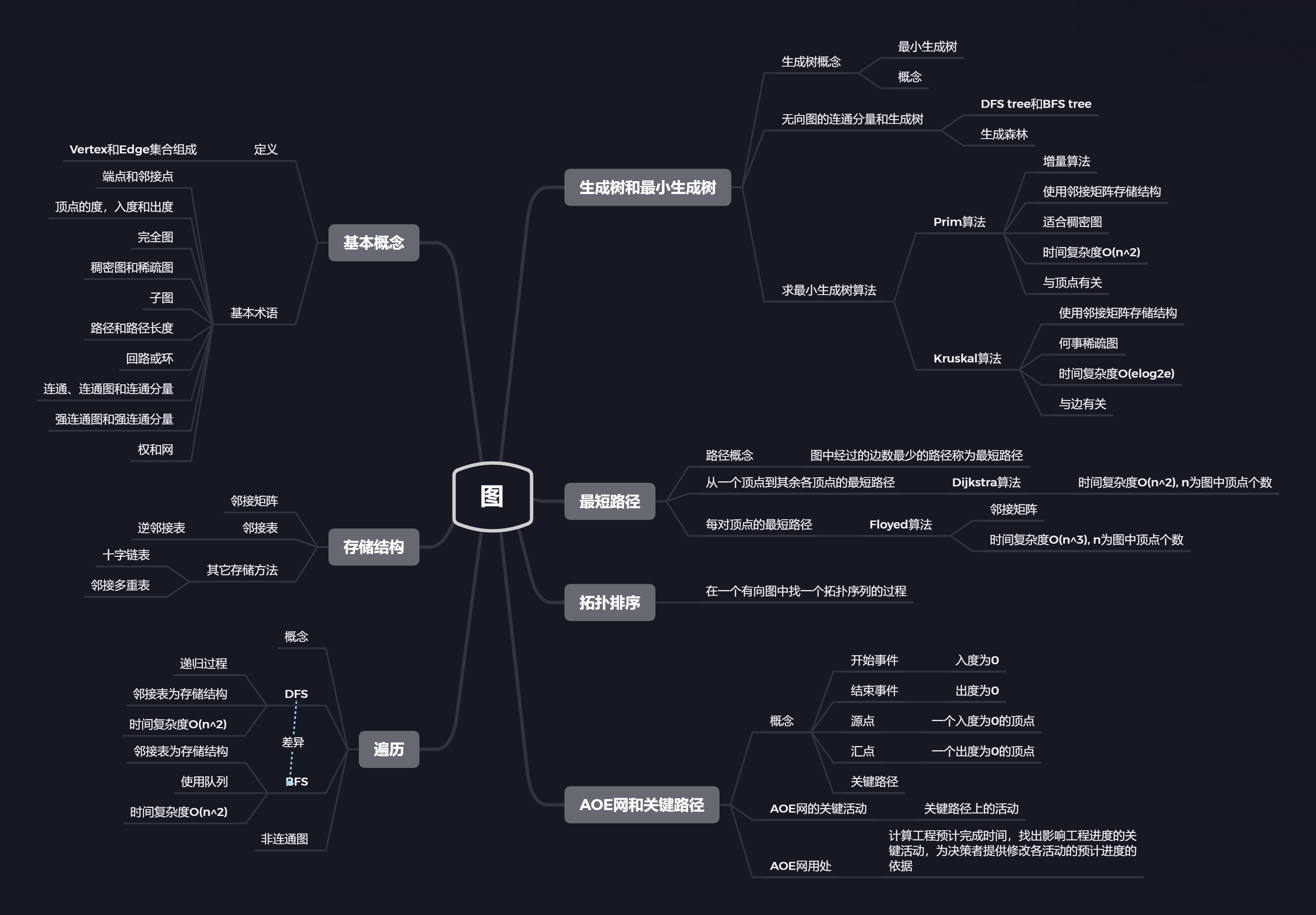
二.概念笔记
-
图的基本术语
-
完全图:若无向图的每两个顶点之间都存在着一条边,有向图的每两个顶点之间都存在着方向相反的两条边,称此图为完全图;无向完全图包含n(n-1)/2条边,有向完全图包含包含n(n-1)条边。
-
连通图:图G中的任意两个顶点都是连通的。
-
连通分量:无向图G中的极大连通子图;连通图的连通分量只有一个(本身),非连通图有多个连通分量。
-
-
图的存储结构和基本运算算法
-
图的完整邻接矩阵类型声明:
#define MAXV 1000 //最大顶点个数 typedef int InfoType; typedef struct { int no; //顶点的编号 InfoType info; //顶点的其它信息 }VertexType; //顶点的类型 typedef struct { int edges[MAXV][MAXV];//邻接矩阵数组 int n, e; //顶点数,边数 VertexType vexs[MAXV];//存放顶点信息 }MyGraph; //完整的图邻接矩阵类型 -
邻接矩阵:采用邻接矩阵数组表示顶点之间相邻关系的存储结构。
-
邻接矩阵特点:
- 图的邻接矩阵表示是唯一的;
- 存储空间皆为O(n^2),适合存储边较多的稠密图;
- 无向图的邻接矩阵数组一定是一个对称矩阵,因此可以采用压缩存储的思想,在存储时只需存放上/下三角部分的元素;
- 对于无向图,邻接矩阵数组的第i行或第i列非零元素、非∞元素的个数正好是顶点i的度;
- 对于有向图,邻接矩阵数组的第i行或第i列非零元素、非∞元素的个数正好是顶点i的出度或入度;
- 在邻接矩阵中,判断图中两个顶点之间是否有边或者求两个顶点之间边的权的执行时间为O(1), 所以在需要提取边权值的算法中通常采用邻接矩阵存储结构。
-
邻接表:是一种顺序和链式存储相结合的存储方法。
-
邻接表的特点:
- 邻接表的表示不唯一,这是因为在每个顶点对应的单链表中各边结点的链接次序可以是任意的,取决于建立邻接表的算法和边的输入次序;
- 对于有n个顶点和e条边的无向图,其邻接点有n个头结点和2e个边结点,对于有n个顶点和e条边的有向图,其邻接表有n个头结点和e个边结点。显然,对于边数较少的稀疏图,邻接表比邻接矩阵更节省存储空间;
- 对于无向图,邻接表中顶点i对应的第i个单链表的边结点数目正好是顶点i的度;
- 对于有向图,邻接表中顶点i对应的第i个单链表的边结点数目仅仅是顶点i的出度。顶点i的入度为邻接表中所有adjvex域值为i的边结点数目;
- 在邻接表中,查找顶点i关联的所有边是非常快速的,所有在需要提取某个顶点的所有邻接点的算法中通常采用邻接表存储结构。
-
-
图的遍历
-
图的遍历:从给定图中任意指定的顶点(称为初始点)出发,按照某个搜索方法沿着图的边访问图中的所有顶点,使每个顶点仅被访问一次的过程。
-
DFS和BFS的差异:
- DFS求出的路径不一定是最短路径,BFS一定是最短路径;
- DFS算法求出的路径中的顶点可能在同一层中,则该路径不一定是最短路径;
- BFS算法求出的路径中的所有顶点一定在不同层中,则该路径一定是最短路径。
-
-
生成树和最小生成树
-
生成树:是一个极小连通子树,其中含有图中的全部顶点,和构成一棵树的(n-1)条边;一颗有n个顶点的生成树(连通无回路图)有且仅有(n-1)条边。
-
构造生成最小树的准则:
- 必须只使用该图的边来构造最小生成树;
- 必须使用且仅使用(n-1)条边来连接图的n个顶点;
- 不能使用产生回路的边。
-
Prim算法生成最小生成树的步骤:(采用邻接矩阵)
- 初始化U={v}, 以v到其它顶点的所有边为候选边;
- 重复以下步骤(n-1)次,使得其它(n-1)个顶点被加入到U中;
1. 从候选边中挑选权值最小的边加入TE,设该边在V-U中的顶点是k, 将k加入U中;
2. 考察当前V - U中的所有顶点j,修改候选边,若(k, j)的权值小于原来和顶点j关联的候选边,则用(k, j)取代后者作为候选边。
一言以蔽之,便是一步步地选择最小边,并在U集合中添加相应的顶点,每一步都是从U和V-U两个顶点集合中选择最小边,而且每一步都是在前面的基础上进行的。
-
Kruskal算法构造最小生成树的步骤:
- 置U的初值为V(即包含有G中的全部顶点),TE的初值为空集(即图T中的每一个顶点都构成一个分量);
- 将图G中的边按权值从小到大的顺序依次选取,若选取的边未使生成树T形成回路,则加入TE,否则舍弃,直到TE中包含(n-1)条边为止。(n为顶点)
-
-
最短路径
- Dijkstra算法基本思想:设G=(V,E)是一个带权有向图,把图中的顶点集合V分成两组。
第1组为已求出最短路径的顶点集合(用S表示,初始时S中只有一个源点,以后每求得一- 条最短路径v...u,就将顶点u加入到集合S中,直到全部顶点都加入到S中,算法就结束了);
第2组为其余未确定最短路径的顶点集合(用U表示),按最短路径长度的递增次序依次把第2组的顶点加人S中。 - Floyd算法基本思想:递推产生一个矩阵序列A0,A1, ..., Ak, ..., An-1, 其中Ak[i][j]表示i --> j的路径上所经过的顶点编号不大于k的最短路径长度。
- Dijkstra算法基本思想:设G=(V,E)是一个带权有向图,把图中的顶点集合V分成两组。
-
AOE网和拓扑排序
在AOE网中,若不存在回路,则所有活动可排列成一个线性序列。
三. 疑难问题
- Q: 使用prim算法和Kruskal算法会混淆,不知道二者的区别,写课堂派的题目时有点懵。
- A:二者区别:Prim是从点开始找,而Kruskal是从边开始找最小的树;Prim做的题中每两个地点是只有一条路的,而Kruskal不管多少条路都适用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号