

python利用difflib判断两个字符串的相似度
我们再工作中可能会遇到需要判断两个字符串有多少相似度的情况(比如抓取页面内容存入数据库,如果相似度大于70%则判定为同一片文章,则不录入数据库)
那这个时候,我们应该怎么判断呢?
不要着急,python自带的difflib库就可以帮助我们解决这个问题。
首先,difflib是python自带的,所以不需要安装,直接引用即可。
活不多少,直接上代码
代码如下:
import difflib #判断相似度的方法,用到了difflib库 def get_equal_rate_1(str1, str2): return difflib.SequenceMatcher(None, str1, str2).quick_ratio() #执行方法进行验证 if __name__ == '__main__': a = '任正非称,对华为不会出现“断供”这种极端情况,我们已经做好准备了。任正非称,今年春节时,我们判断出现这种情况是2年以后。\ 我还有两年时间去足够足够准备了。孟晚舟事件时我们认为这个时间提前了,我们春节都在加班。保安、清洁工、服务人员,春节期间有5000人\ 都在加班,加倍工资都在供应我们的战士战斗,大家都在抢时间。(新浪科技)' b = ' 任正非称,对华为不会出现“断供”这种极端情况,我们已经做好准备了。任正非称,今年春节时,我们判断出现这种情况是2年以后。\ 我还有两年时间去足够足够准备了。孟晚舟事件时我们认为这个时间提前了,我们春节都在加班。保安、清洁工、服务人员,春节期间有5000人\ 都在加班,加倍工资都在供应我们的战士战斗,大家都在抢时间。' print(get_equal_rate_1(a, b))
结果为:
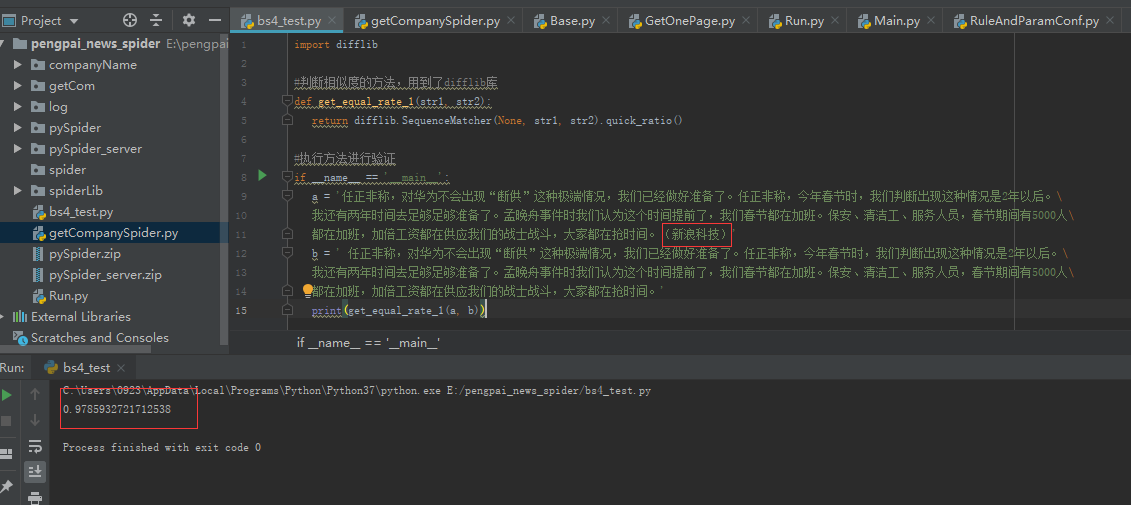
可以看到,这两个字符串的形似度为0.978... ...很明显是同一片文章。
通过difflib库,我们就完成了两个字符串相似度的计算,哈哈,简单吧!
希望能帮到需要的人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号