3.2 优势演员–评论家算法(Advantage Actor-Critic, A3C)
优势演员–评论家算法(Advantage Actor-Critic, A3C)
演员–评论家(Actor–Critic)算法
策略梯度定理提供了一种能够基于单步转移估计梯度的架构:
\[\nabla_\theta J(\theta) = \mathbb{E}_{s \sim \rho_\theta, a \sim \pi_\theta}[\nabla_\theta \log \pi_\theta(s,a) Q_\varphi(s,a)]
\]
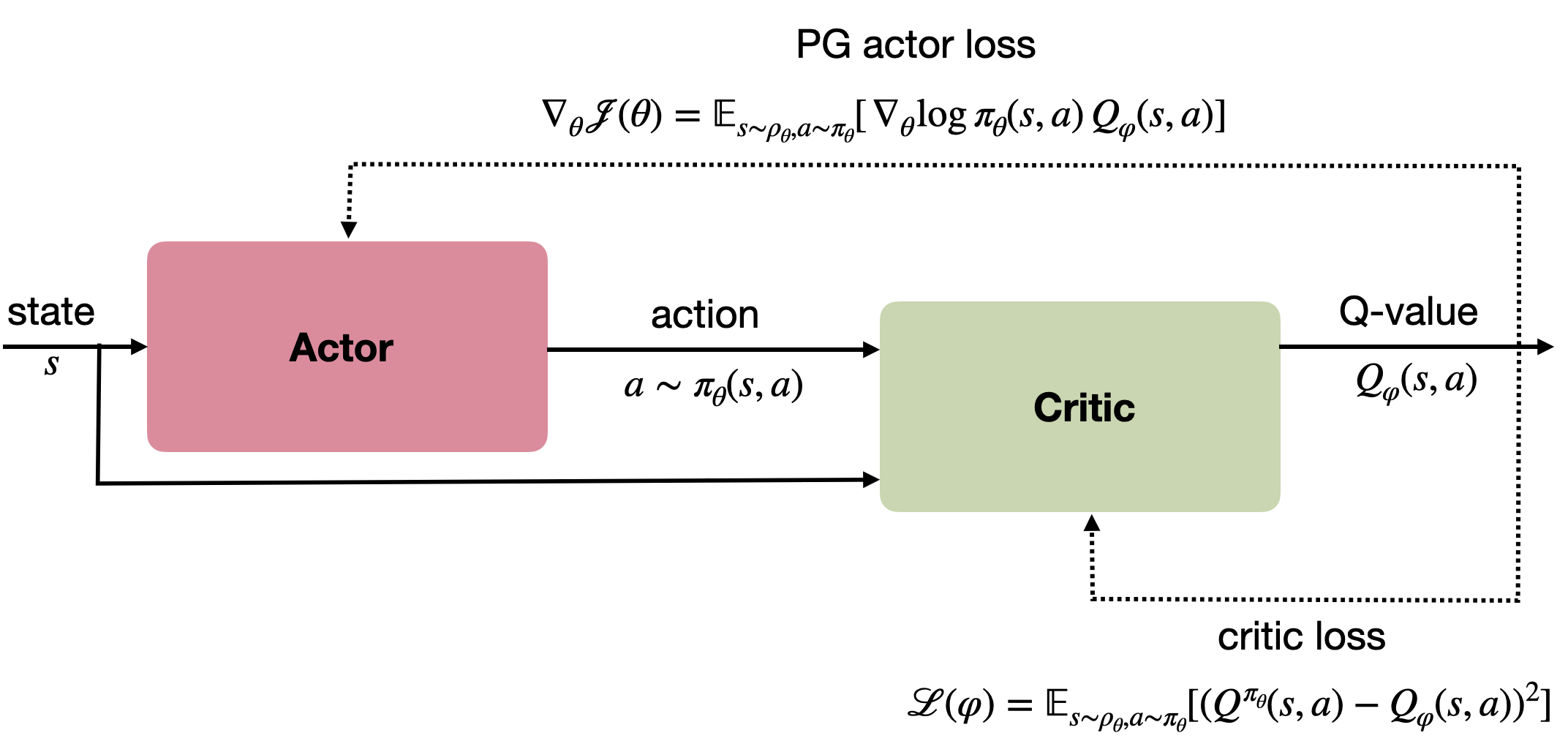
评论者(Critic)可使用任意优势估计器(advantage estimator)进行训练,例如 DQN 或其变体:
\[\mathcal{L}(\varphi) = \mathbb{E}_{s_t,a_t}[(r + \gamma Q_{\varphi'}(s',\arg\max_{a'} Q_\varphi(s',a')) - Q_\varphi(s,a))^2]
\]
大多数策略梯度算法都属于 Actor–Critic 架构,不同算法的区别在于梯度估计项 \(\psi_t\) 的定义:
| 算法 | \(\psi_t\) 定义 |
|---|---|
| REINFORCE | \(\psi_t = R_t\) |
| REINFORCE + 基线 | \(\psi_t = R_t - b\) |
| 策略梯度定理 | \(\psi_t = Q^\pi(s_t,a_t)\) |
| 优势 Actor–Critic | \(\psi_t = A^\pi(s_t,a_t)\) |
| TD Actor–Critic | \(\psi_t = r_{t+1} + \gamma V^\pi(s_{t+1}) - V^\pi(s_t)\) |
| n-step A2C | \(\psi_t = \sum_{k=0}^{n-1} \gamma^k r_{t+k+1} + \gamma^n V^\pi(s_{t+n}) - V^\pi(s_t)\) |
偏差–方差权衡:
- 若 \(\psi_t\) 主要依赖真实奖励 → 偏差小、方差大;
- 若 \(\psi_t\) 主要依赖估计值 → 方差小、偏差大。
A2C、GAE 等方法旨在平衡这一权衡。
优势演员–评论家算法(A2C)
A2C 结合了 Monte Carlo 与 TD 学习,通过 n-step 更新 实现折中:
\[\nabla_\theta J(\theta) = \mathbb{E}[\nabla_\theta \log \pi_\theta(s_t,a_t)(\sum_{k=0}^{n-1} \gamma^k r_{t+k+1} + \gamma^n V_\varphi(s_{t+n}) - V_\varphi(s_t))]
\]
架构:
- Actor:输出策略 \(\pi_\theta(s)\)(动作概率分布)
- Critic:输出状态值 \(V_\varphi(s)\)
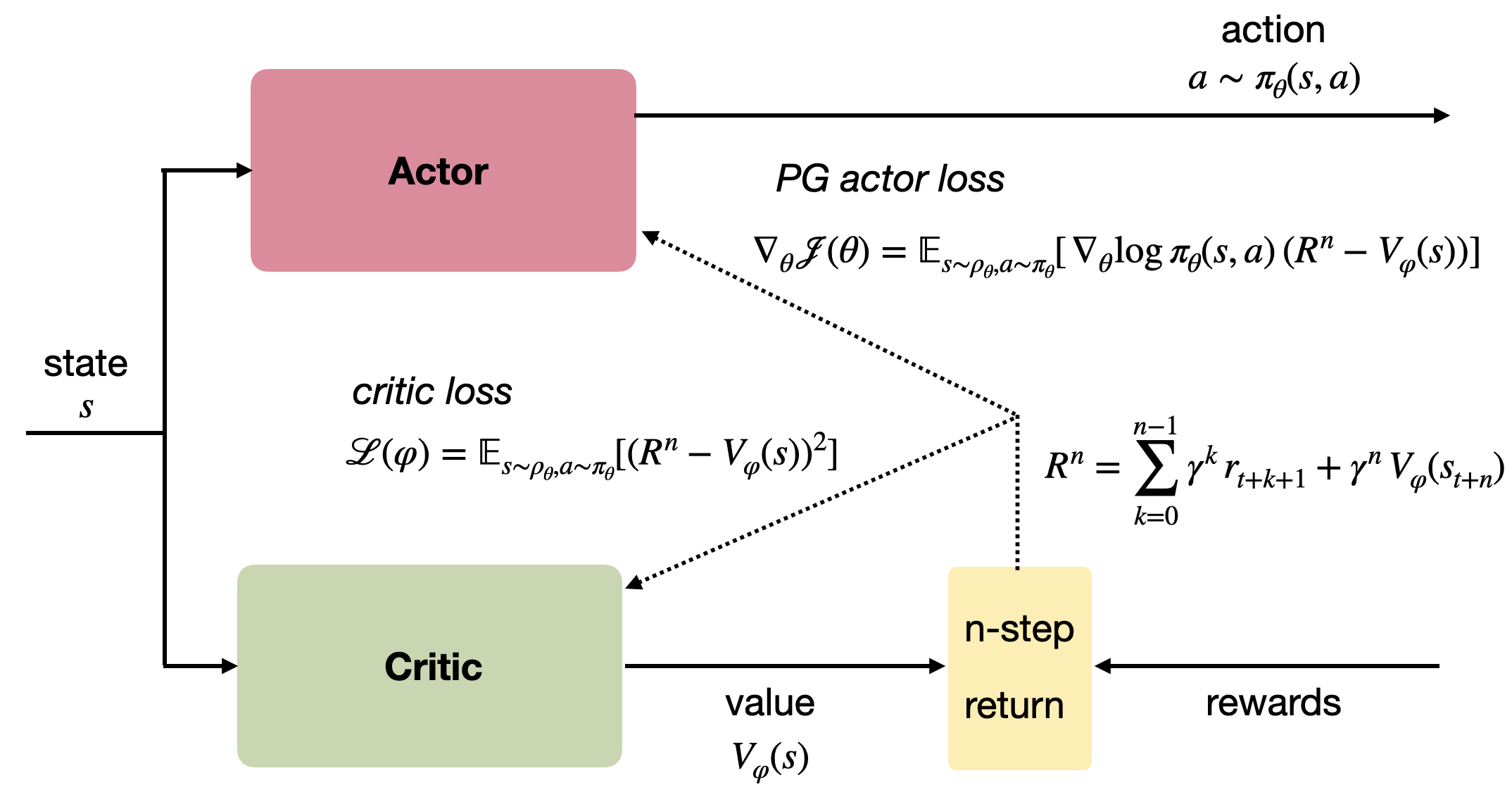
算法步骤
- 收集批量转移 \((s,a,r,s')\);
- 计算 n 步回报:\[R_t = \sum_{k=0}^{n-1} \gamma^k r_{t+k+1} + \gamma^n V_\varphi(s_{t+n}) \]
- 更新演员(Actor):\[\nabla_\theta J(\theta) = \sum_t \nabla_\theta \log \pi_\theta(s_t,a_t)(R_t - V_\varphi(s_t)) \]
- 更新评论者(Critic):\[\mathcal{L}(\varphi) = \sum_t (R_t - V_\varphi(s_t))^2 \]
该算法与 REINFORCE 类似,但允许非终止任务并引入了并行学习的评论者。
单机 A2C 伪代码
- 初始化 \(\pi_\theta, V_\varphi\)
- 重复以下步骤:
- 采样 n 步轨迹;
- 若非终止状态,设 \(R=V_\varphi(s_n)\),否则 \(R=0\);
- 反向累积奖励并更新梯度:\[d\theta \!+= \!\nabla_\theta \log \pi_\theta(s_k,a_k)(R - V_\varphi(s_k)) \]\[d\varphi \!+=\! \nabla_\varphi (R - V_\varphi(s_k))^2 \]
- 参数更新:\[\theta \leftarrow \theta + \eta d\theta,\quad \varphi \leftarrow \varphi + \eta d\varphi \]
分布式 A2C
为解决输入–输出相关性问题,A2C 使用多线程并行学习:
- 全局网络保存参数;
- 多个工作线程(workers)独立采样;
- 每个线程计算梯度后上传至全局网络;
- 全局网络汇总并更新参数;
- 参数再广播回各线程。
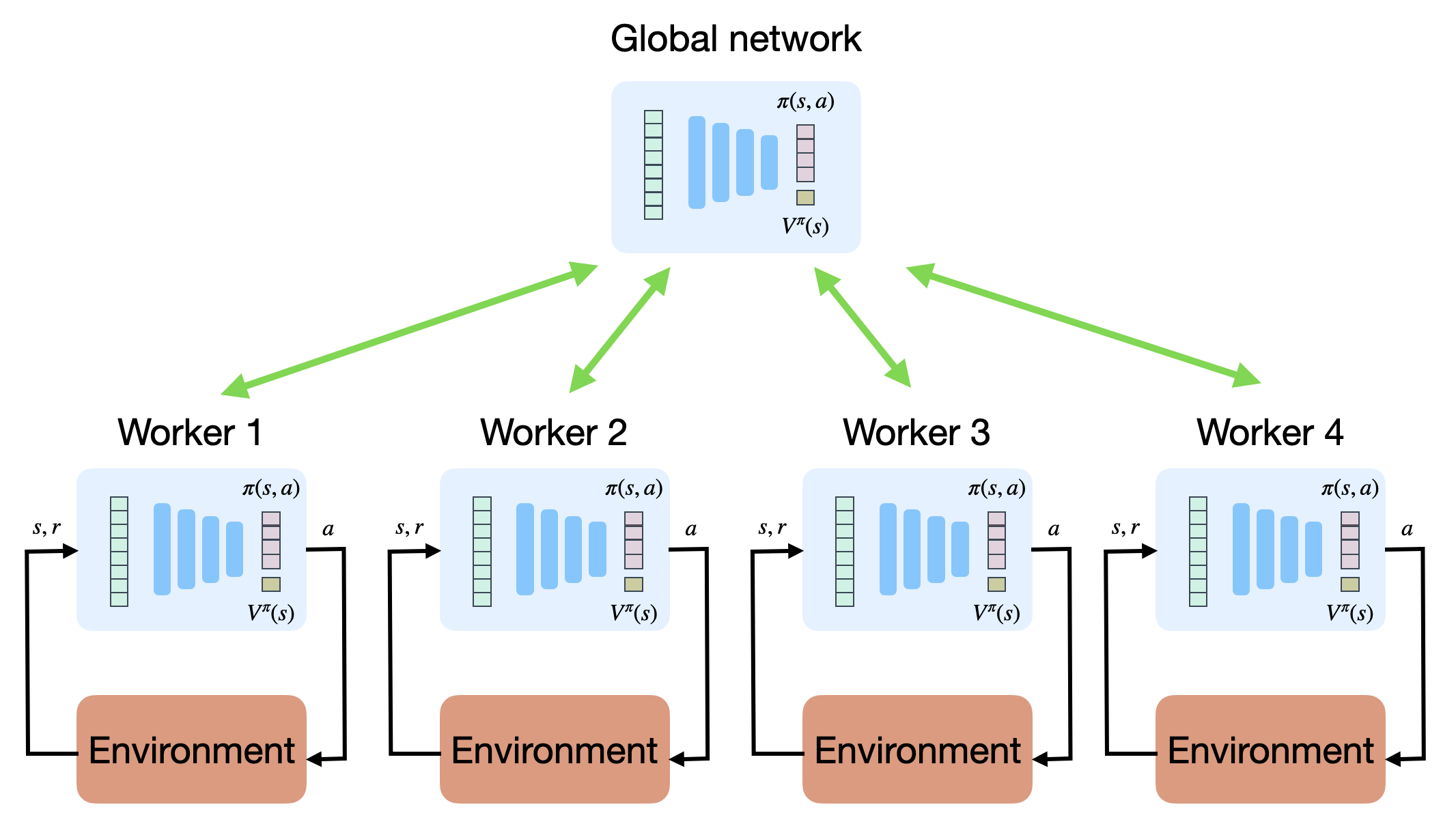
这种并行方式能显著减少相关样本,提高稳定性。
异步优势演员–评论家(A3C)
A3C [@Mnih2016] 取消了线程间同步机制:
每个 worker 异步读取并更新全局参数(采用 HogWild! 异步更新 [@Niu2011])。
优点:
- 无需等待其他线程;
- 利用 CPU 并行计算;
- 收敛更快(1 天解决 Atari 游戏,性能超 DQN)。
熵正则化(Entropy Regularization)
为鼓励探索,A3C 在策略梯度中加入熵项:
\[\nabla_\theta J(\theta) = \mathbb{E}[\nabla_\theta \log \pi_\theta(s_t,a_t)(R_t - V_\varphi(s_t)) + \beta \nabla_\theta H(\pi_\theta(s_t))]
\]
其中:
\[H(\pi_\theta(s_t)) = -\sum_a \pi_\theta(s_t,a)\log \pi_\theta(s_t,a)
\]
熵项度量策略的随机性——鼓励保持非确定性,从而提高探索效率。
演员–评论家网络结构
Actor 与 Critic 可:
- 完全独立(无共享层);
- 部分共享特征层(如卷积层);
- 完全共享底层特征(多头输出)。
总损失为:
\[\mathcal{L}(\theta) = \mathcal{L}_{actor} + \mathcal{L}_{critic}
\]
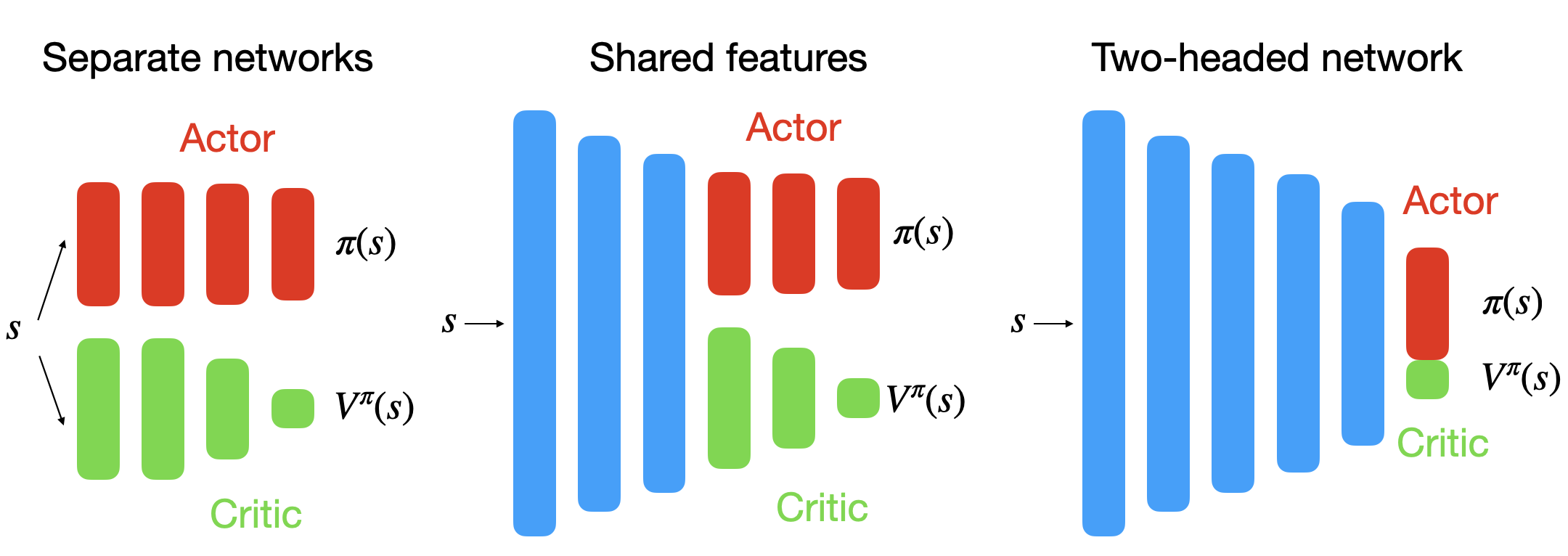
在图像输入任务(如 Atari)中通常共享卷积层;
在连续控制任务(如 Mujoco)中则更常用独立网络。
连续动作空间
离散动作:使用 softmax 输出动作概率。
连续动作:假设动作服从参数化分布(通常为高斯分布)。
设策略为:
\[\pi_\theta(s,a) = \mathcal{N}(\mu_\theta(s),\sigma_\theta^2(s))
\]
即:
\[\pi_\theta(s,a) = \frac{1}{\sqrt{2\pi\sigma^2_\theta(s)}} \exp\left[-\frac{(a - \mu_\theta(s))^2}{2\sigma^2_\theta(s)}\right]
\]
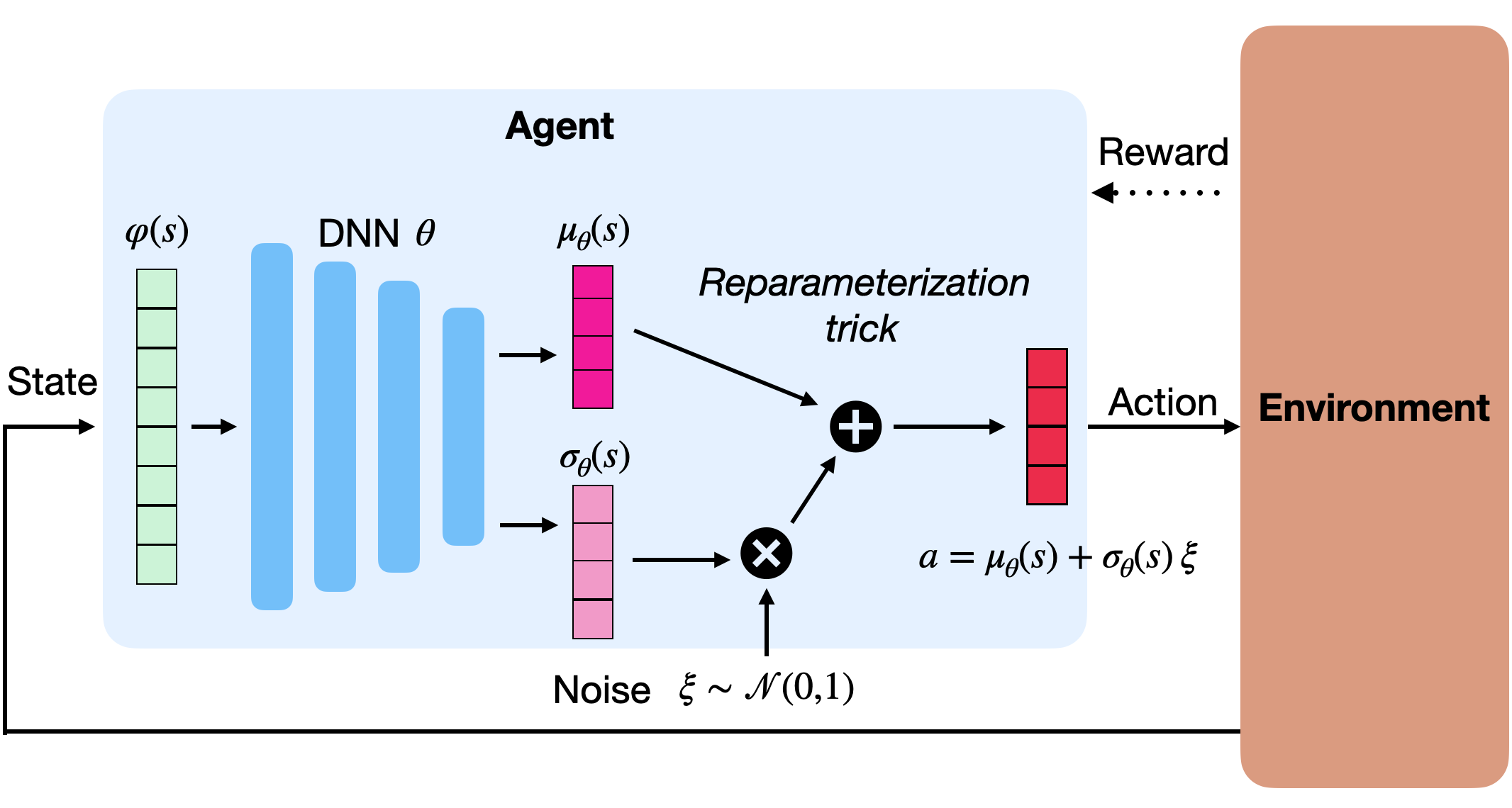
使用重参数化技巧(Reparameterization Trick):
\[a = \mu_\theta(s) + \sigma_\theta(s)\xi, \quad \xi \sim \mathcal{N}(0,1)
\]
梯度可解析为:
\[\nabla_\mu \log \pi = \frac{a - \mu}{\sigma^2}, \quad \nabla_\sigma \log \pi = \frac{(a - \mu)^2}{\sigma^3} - \frac{1}{\sigma}
\]
该技巧允许对随机策略进行反向传播(如变分自编码器中)。
扩展:
- 固定全局 \(\sigma\);
- 每个维度独立 \(\sigma\);
- 学习型协方差矩阵 \(\Sigma\)。
为避免高斯分布无限支持导致的动作越界问题,可使用 Beta 分布策略 [@Chou2017],其支持范围为 \([0,1]\),可轻松映射至动作限制范围。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号