

决策树算法及应用
| 博客班级 | https://edu.cnblogs.com/campus/ahgc/machinelearning |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/ahgc/machinelearning/homework/12086 |
| 学号 | 3180701321 |
| 一、【实验目的】 | |
| 理解决策树算法原理,掌握决策树算法框架; | |
| 理解决策树学习算法的特征选择、树的生成和树的剪枝; | |
| 能根据不同的数据类型,选择不同的决策树算法; | |
| 针对特定应用场景及数据,能应用决策树算法解决实际问题。 | |
| 二、【实验内容】 | |
| 设计算法实现熵、经验条件熵、信息增益等方法。 | |
| 实现ID3算法。 | |
| 熟悉sklearn库中的决策树算法; | |
| 针对iris数据集,应用sklearn的决策树算法进行类别预测。 | |
| 针对iris数据集,利用自编决策树算法进行类别预测。 | |
| 三、【实验报告要求】 | |
| 对照实验内容,撰写实验过程、算法及测试结果; | |
| 代码规范化:命名规则、注释; | |
| 分析核心算法的复杂度; | |
| 查阅文献,讨论ID3、5算法的应用场景; | |
| 查询文献,分析决策树剪枝策略。 |
四、实验内容及结果
实验代码及截图
1.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
from math import log
import pprint
书上题目5.1
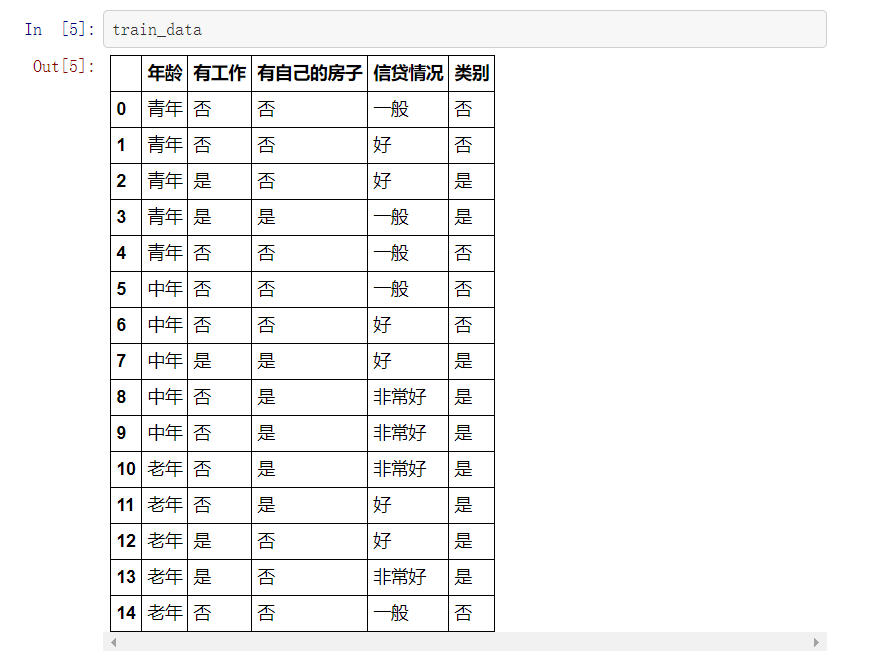
def create_data():
datasets = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否'],
]
labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']
# 返回数据集和每个维度的名称
return datasets, labels

datasets, labels = create_data()

train_data = pd.DataFrame(datasets, columns=labels)

熵
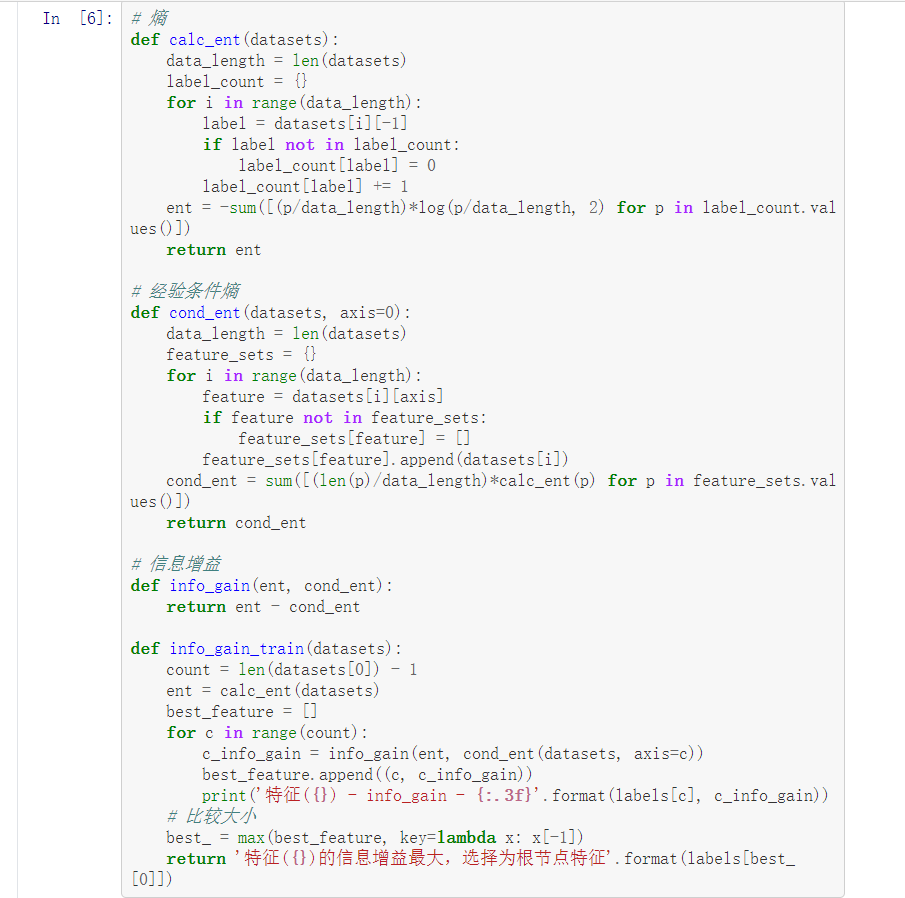
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()])
return ent
经验条件熵
def cond_ent(datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p)/data_length)*calc_ent(p) for p in feature_sets.values()])
return cond_ent
信息增益
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(datasets):
count = len(datasets[0]) - 1
ent = calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
print('特征({}) - info_gain - {:.3f}'.format(labels[c], c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
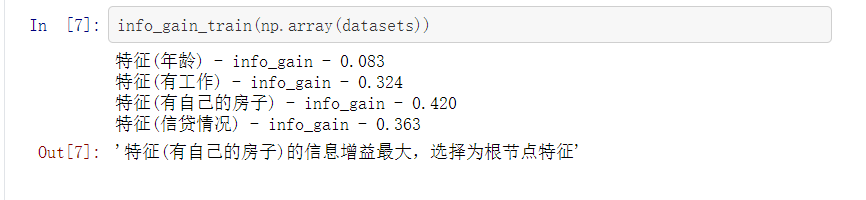
info_gain_train(np.array(datasets))
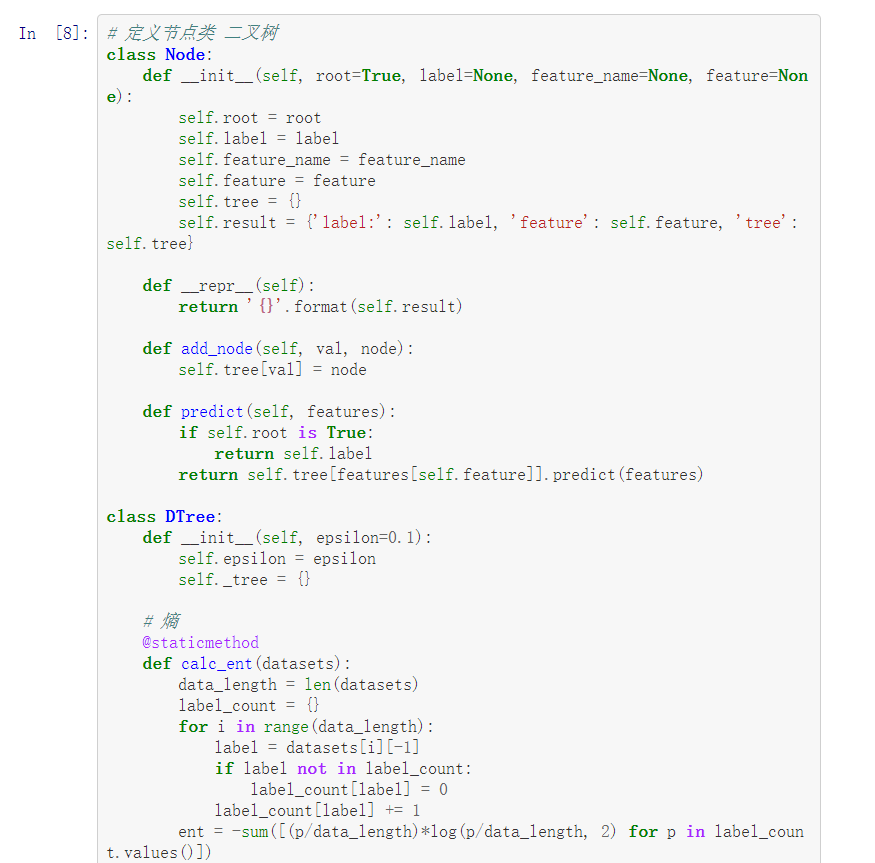
定义节点类 二叉树
class Node:
def init(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {'label:': self.label, 'feature': self.feature, 'tree': self.tree}
def __repr__(self):
return '{}'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
return self.tree[features[self.feature]].predict(features)
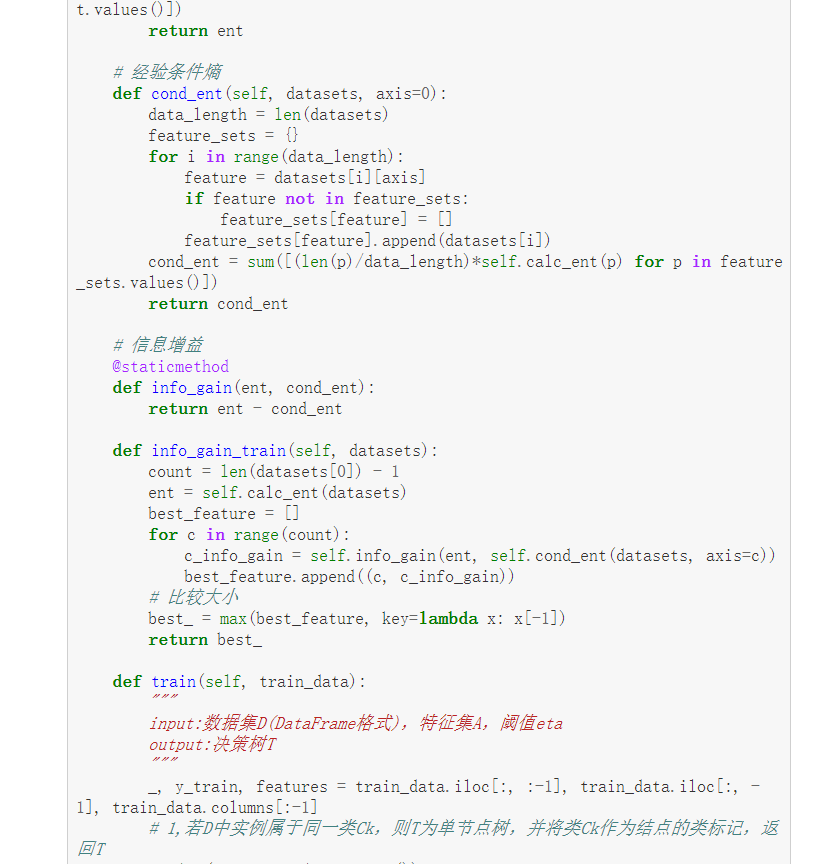
class DTree:
def init(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# 熵
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p)/data_length)*self.calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data.iloc[:, :-1], train_data.iloc[:, -1], train_data.columns[:-1]
# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回T
if len(y_train.value_counts()) == 1:
return Node(root=True,
label=y_train.iloc[0])
# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回T
if len(features) == 0:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回T
if max_info_gain < self.epsilon:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 5,构建Ag子集
node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1)
# 6, 递归生成树
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
# pprint.pprint(node_tree.tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
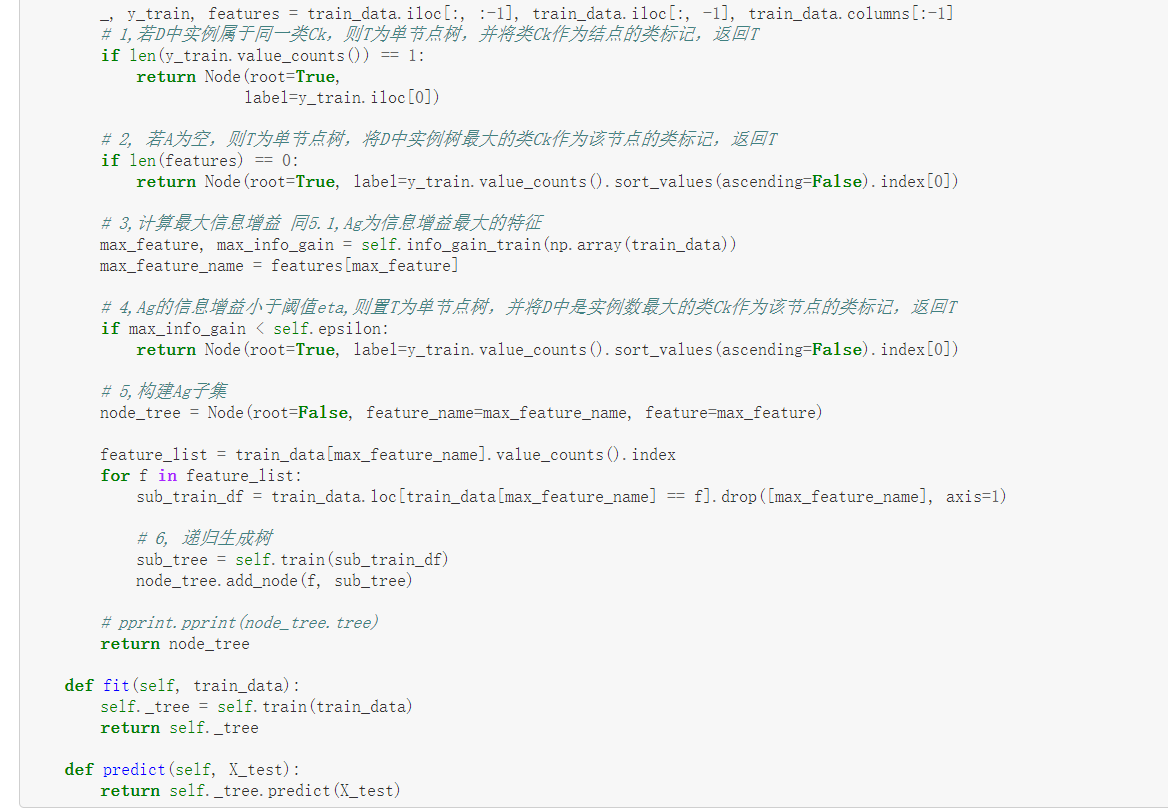
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)


data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
# print(data)
return data[:,:2], data[:,-1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)

from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz

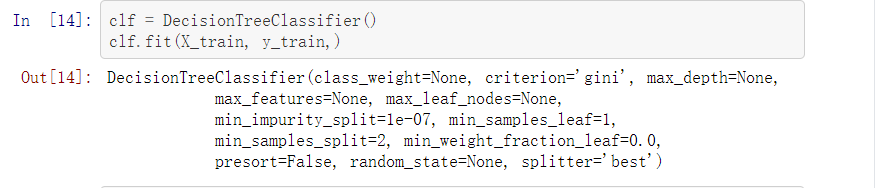
clf.score(X_test, y_test)

tree_pic = export_graphviz(clf, out_file="mytree.pdf")
with open('mytree.pdf') as f:
dot_graph = f.read()

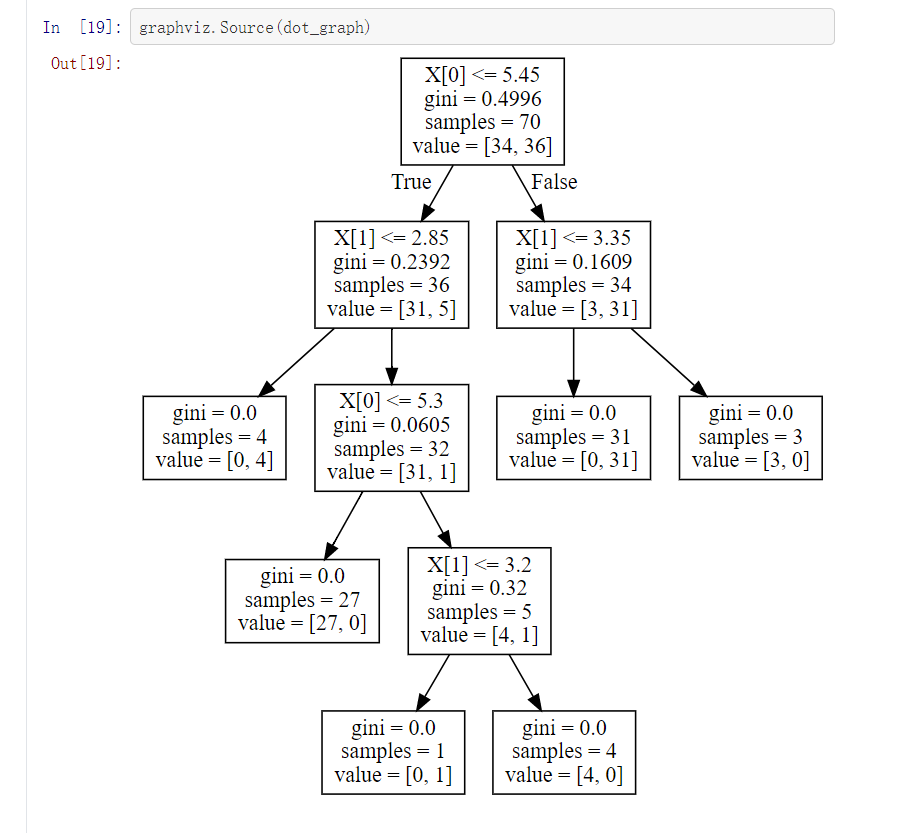
五、实验小结
本次实验是关于决策树的算法,其实决策树本质上是从训练数据集中归纳出一组分类规则。在判断一个决策树的性能好坏时,应该关注特征属性的本质和分类性能。决策树虽然也是一个良好的分类算法,但是它也面对一下问题:比如多度拟合,当数据中有噪声或训练样例的数量太少以至于不能产生目标函数的有代表性的采样时。分析决策树剪枝策略:剪枝的目的在于:缓解决策树的"过拟合",降低模型复杂度,提高模型整体的学习效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号