Java异常处理
2014-08-01 11:22 Loull 阅读(411) 评论(0) 收藏 举报Java异常类层次结构图:
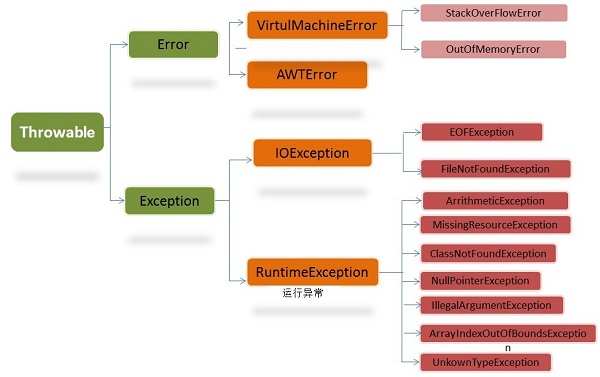
图1 Java异常类层次结构图
图示try、catch、finally语句块的执行:
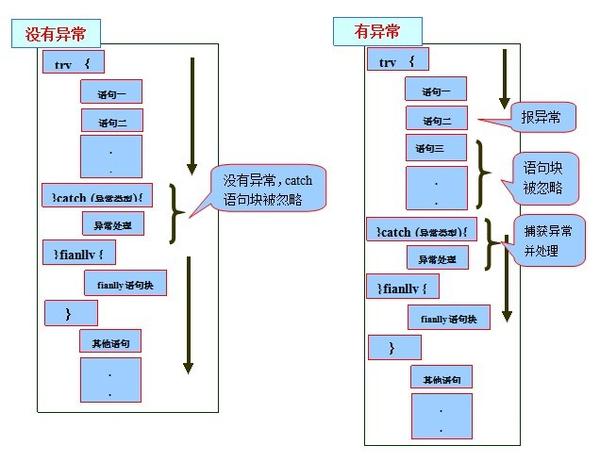
图2 图示try、catch、finally语句块的执行
RuntimeException
RuntimeException 是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。Java编译器不去检查它,也就是说,当程序中可能出现这类异常时,即使没有用try...catch语句捕获它,也没有用throws字句声明抛出它,还是会编译通过,这种异常可以通过改进代码实现来避免。
如果Java虚拟机追溯到方法调用栈最底部main()方法时,如果仍然没有找到处理异常的代码块,将按照下面的步骤处理:
第一、调用异常的对象的printStackTrace()方法,打印方法调用栈的异常信息。
第二、如果出现异常的线程为主线程,则整个程序运行终止;如果非主线程,则终止该线程,其他线程继续运行。
通过分析思考可以看出,越早处理异常消耗的资源和时间越小,产生影响的范围也越小。因此,不要把自己能处理的异常也抛给调用者。
运行时异常和受检查异常
Exception类可以分为两种:运行时异常和受检查异常。
运行时异常表示无法让程序恢复运行的异常,导致这种异常的原因通常是由于执行了错误的操作。一旦出现错误,建议让程序终止。
受检查异常表示程序可以处理的异常。如果抛出异常的方法本身不处理或者不能处理它,那么方法的调用者就必须去处理该异常,否则调用会出错,连编译也无法通过。
最佳解决方案
对于运行时异常,我们不要用try...catch来捕获处理,而是在程序开发调试阶段,尽量去避免这种异常,一旦发现该异常,正确的做法就会改进程序设计的代码和实现方式,修改程序中的错误,从而避免这种异常。捕获并处理运行时异常是好的解决办法,因为可以通过改进代码实现来避免该种异常的发生。
对于受检查异常,没说的,老老实实去按照异常处理的方法去处理,要么用try...catch捕获并解决,要么用throws抛出!
对于Error(运行时错误),不需要在程序中做任何处理,出现问题后,应该在程序在外的地方找问题,然后解决。
Java异常处理的原则和技巧
1、避免过大的try块,不要把不会出现异常的代码放到try块里面,尽量保持一个try块对应一个或多个异常。
2、细化异常的类型,不要不管什么类型的异常都写成Excetpion。
3、catch块尽量保持一个块捕获一类异常,不要忽略捕获的异常,捕获到后要么处理,要么转译,要么重新抛出新类型的异常。
4、不要把自己能处理的异常抛给别人。
5、不要用try...catch参与控制程序流程,异常控制的根本目的是处理程序的非正常情况。
JAVA异常处理中的注意事项
合理使用JAVA异常机制可以使程序健壮而清晰,但不幸的是,JAVA异常处理机制常常被错误的使用,下面就是一些关于Exception的注意事项:
1. 不要忽略checked Exception
请看下面的代码:
try { method1(); //method1抛出ExceptionA } catch(ExceptionA e) { e.printStackTrace(); }
上面的代码似乎没有什么问题,捕获异常后将异常打印,然后继续执行。事实上在catch块中对发生的异常情况并没有作任何处理(打印异常不能是算是处理异常,因为在程序交付运行后调试信息就没有什么用处了)。这样程序虽然能够继续执行,但是由于这里的操作已经发生异常,将会导致以后的操作并不能按照预期的情况发展下去,可能导致两个结果:
(1)由于这里的异常导致在程序中别的地方抛出一个异常,这种情况会使程序员在调试时感到迷惑,因为新的异常抛出的地方并不是程序真正发生问题的地方,也不是发生问题的真正原因;
(2)程序继续运行,并得出一个错误的输出结果,这种问题更加难以捕捉,因为很可能把它当成一个正确的输出。
那么应该如何处理呢,这里有四个选择:
(1) 处理异常,进行修复以让程序继续执行。
(2) 重新抛出异常,在对异常进行分析后发现这里不能处理它,那么重新抛出异常,让调用者处理。
(3) 将异常转换为用户可以理解的自定义异常再抛出,这时应该注意不要丢失原始异常信息(见5)。
(4) 不要捕获异常。因此,当捕获一个unchecked Exception的时候,必须对异常进行处理;如果认为不必要在这里作处理,就不要捕获该异常,在方法体中声明方法抛出异常,由上层调用者来处理该异常。
2. 不要一次捕获所有的异常
请看下面的代码:
try { method1(); //method1抛出ExceptionA method2(); //method1抛出ExceptionB method3(); //method1抛出ExceptionC } catch(Exception e) { …… }
这是一个很诱人的方案,代码中使用一个catch子句捕获了所有异常,看上去完美而且简洁,事实上很多代码也是这样写的。但这里有两个潜在的缺陷,一是针对try块中抛出的每种Exception,很可能需要不同的处理和恢复措施,而由于这里只有一个catch块,分别处理就不能实现。二是try块中还可能抛出RuntimeException,代码中捕获了所有可能抛出的RuntimeException而没有作任何处理,掩盖了编程的错误,会导致程序难以调试。
下面是改正后的正确代码:
try { method1(); //method1抛出ExceptionA method2(); //method1抛出ExceptionB method3(); //method1抛出ExceptionC } catch(ExceptionA e) { …… } catch(ExceptionB e) { …… } catch(ExceptionC e) { …… }
3. 使用finally块释放资源
finally关键字保证无论程序使用任何方式离开try块,finally中的语句都会被执行。在以下三种情况下会进入finally块:
(1) try块中的代码正常执行完毕。
(2) 在try块中抛出异常。
(3) 在try块中执行return、break、continue。
因此,当你需要一个地方来执行在任何情况下都必须执行的代码时,就可以将这些
代码放入finally块中。当你的程序中使用了外界资源,如数据库连接,文件等,必须将释放这些资源的代码写入finally块中。
必须注意的是,在finally块中不能抛出异常。JAVA异常处理机制保证无论在任何情况下必须先执行finally块然后在离开try块,因此在try块中发生异常的时候,JAVA虚拟机先转到finally块执行finally块中的代码,finally块执行完毕后,再向外抛出异常。如果在finally块中抛出异常,try块捕捉的异常就不能抛出,外部捕捉到的异常就是finally块中的异常信息,而try块中发生的真正的异常堆栈信息则丢失了。
请看下面的代码:
Connection con = null; try { con = dataSource.getConnection(); …… } catch(SQLException e) { …… throw e;//进行一些处理后再将数据库异常抛出给调用者处理 } finally { try { con.close(); } catch(SQLException e) { e.printStackTrace(); …… } }
运行程序后,调用者得到的信息如下
java.lang.NullPointerException
at myPackage.MyClass.method1(methodl.java:266)
而不是我们期望得到的数据库异常。这是因为这里的con是null的关系,在finally语句中抛出了NullPointerException,在finally块中增加对con是否为null的判断可以避免产生这种情况。
4. 异常不能影响对象的状态
异常产生后不能影响对象的状态,这是异常处理中的一条重要规则。 在一个函数中发生异常后,对象的状态应该和调用这个函数之前保持一致,以确保对象处于正确的状态中。如果对象是不可变对象(不可变对象指调用构造函数创建后就不能改变的对象,即创建后没有任何方法可以改变对象的状态),那么异常发生后对象状态肯定不会改变。如果是可变对象,必须在编程中注意保证异常不会影响对象状态。
有三个方法可以达到这个目的:
(1) 将可能产生异常的代码和改变对象状态的代码分开,先执行可能产生异常的代码,如果产生异常,就不执行改变对象状态的代码。
(2) 对不容易分离产生异常代码和改变对象状态代码的方法,定义一个recover方法,在异常产生后调用recover方法修复被改变的类变量,恢复方法调用前的类状态。
(3) 在方法中使用对象的拷贝,这样当异常发生后,被影响的只是拷贝,对象本身不会受到影响。
5. 丢失的异常
请看下面的代码:
public void method2() { try { …… method1(); //method1进行了数据库操作 } catch(SQLException e) { …… throw new MyException(“发生了数据库异常:”+e.getMessage); } } public void method3() { try { method2(); } catch(MyException e) { e.printStackTrace(); …… } }
上面method2的代码中,try块捕获method1抛出的数据库异常SQLException后,抛出了新的自定义异常MyException。这段代码是否并没有什么问题,但看一下控制台的输出:
MyException:发生了数据库异常:对象名称 'MyTable' 无效。
at MyClass.method2(MyClass.java:232)
at MyClass.method3(MyClass.java:255)
原始异常SQLException的信息丢失了,这里只能看到method2里面定义的MyException的堆栈情况;而method1中发生的数据库异常的堆栈则看不到,如何排错呢,只有在method1的代码行中一行行去寻找数据库操作语句了,祈祷method1的方法体短一些吧。
JDK的开发者们也意识到了这个情况,在JDK1.4.1中,Throwable类增加了两个构造方法,public Throwable(Throwable cause)和public Throwable(String message,Throwable cause),在构造函数中传入的原始异常堆栈信息将会在printStackTrace方法中打印出来。但对于还在使用JDK1.3的程序员,就只能自己实现打印原始异常堆栈信息的功能了。实现过程也很简单,只需要在自定义的异常类中增加一个原始异常字段,在构造函数中传入原始异常,然后重载printStackTrace方法,首先调用类中保存的原始异常的printStackTrace方法,然后再调用super.printStackTrace方法就可以打印出原始异常信息了。可以这样定义前面代码中出现的MyException类:
public class MyExceptionextends Exception { //构造函数 public SMException(Throwable cause) { this.cause_ = cause; } public MyException(String s,Throwable cause) { super(s); this.cause_ = cause; } //重载printStackTrace方法,打印出原始异常堆栈信息 public void printStackTrace() { if (cause_ != null) { cause_.printStackTrace(); } super.printStackTrace(s); } public void printStackTrace(PrintStream s) { if (cause_ != null) { cause_.printStackTrace(s); } super.printStackTrace(s); } public void printStackTrace(PrintWriter s) { if (cause_ != null) { cause_.printStackTrace(s); } super.printStackTrace(s); } //原始异常 private Throwable cause_; }
6. 不要使用同时使用异常机制和返回值来进行异常处理
下面是我们项目中的一段代码
try { doSomething(); } catch(MyException e) { if(e.getErrcode == -1) { …… } if(e.getErrcode == -2) { …… } …… }
假如在过一段时间后来看这段代码,你能弄明白是什么意思吗?混合使用JAVA异常处理机制和返回值使程序的异常处理部分变得“丑陋不堪”,并难以理解。如果有多种不同的异常情况,就定义多种不同的异常,而不要像上面代码那样综合使用Exception和返回值。
修改后的正确代码如下:
try { doSomething(); //抛出MyExceptionA和MyExceptionB } catch(MyExceptionA e) { …… } catch(MyExceptionB e) { …… }
7. 不要让try块过于庞大
出于省事的目的,很多人习惯于用一个庞大的try块包含所有可能产生异常的代码,
这样有两个坏处:
阅读代码的时候,在try块冗长的代码中,不容易知道到底是哪些代码会抛出哪些异常,不利于代码维护。
使用try捕获异常是以程序执行效率为代价的,将不需要捕获异常的代码包含在try块中,影响了代码执行的效率。
参考:
http://lavasoft.blog.51cto.com/62575/18920/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号