

机器学习-正则化方法
在机器学习里,我们叫这种现象为“过拟合”,即使用少量样本去拟合了所有没见过的样本。
另外,在机器学习中,我们训练模型的数据不可避免的存在一些测量误差或者其他噪音,比如下图中10个点,我们可以找到唯一的9阶多项式 来拟合所有点;也可以使用线性模型 y = 2x 拟合。
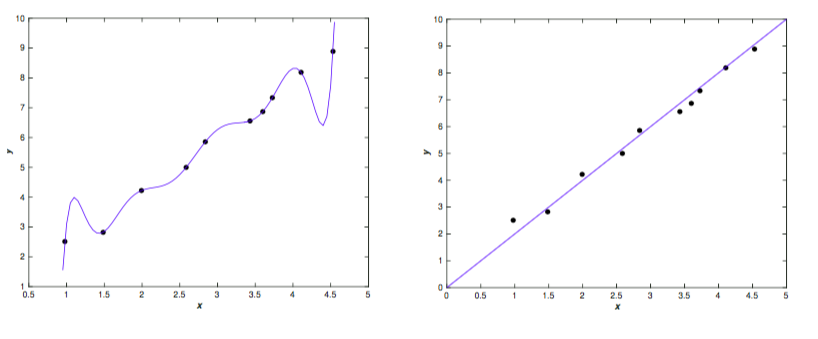
图1
从上图可以看出,左侧的拟合结果显然的拟合到所有噪声数据了,这使得模型变得复杂并且不具备健壮的泛化能力。
到这里,我们应该知道,过拟合的主要原因就是训练集样本太少或样本中存在噪声。如果是样本太少的原因,那直接增加训练样本就好了,但是训练样本不是你想加就能加的呀。所以我们能做的就是使用正则化技术来防止模型学到训练样本中的噪声,从而降低过拟合的可能性,增加模型的鲁棒性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号