关于pandas.ExcelWriter-从列表写入后-每个Sheet表中的首行与首列-默认数字序列号的处理
Posted on 2024-01-11 14:09 520_1351 阅读(216) 评论(0) 收藏 举报对于复杂的pandas写入数据到Excel,多个Sheet表,一般都会使用到 pandas.ExcelWriter
1、先看一段代码示例,如下,其中ResultExcelFile为文件名字符串,EC2_RI 为 多个列表组成的大列表,
Writer=pandas.ExcelWriter(ResultExcelFile) EC2_RI_Data=pandas.DataFrame(EC2_RI) EC2_RI_Data.to_excel(Writer,sheet_name="EC2-RI-QQ-5201351") Writer.close()
这样执行后的效果如下:
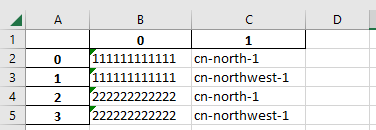
2、但是第一行,和A列都并不是我们列表的内容,很多情况下,我们并不希望看到这两部分,于是可以按如下方式处理
Writer=pandas.ExcelWriter(ResultExcelFile) EC2_RI_Data=pandas.DataFrame(EC2_RI[1:],columns=EC2_RI[0]) EC2_RI_Data.to_excel(Writer,sheet_name="EC2-RI-QQ-5201351",index=False) Writer.close()
说明:EC2_RI_Data=pandas.DataFrame(EC2_RI[1:],columns=EC2_RI[0]) 代表,以EC2_RI[1:]作为数据内容,列表的第一个子列表作为第一行每一列的名称
EC2_RI_Data.to_excel(Writer,sheet_name="EC2-RI-QQ-5201351",index=False) 代表,不要第一列(A列)的默认序列号,默认index=的值为True
最后执行的效果如下:
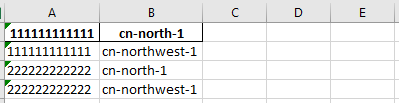
尊重别人的劳动成果 转载请务必注明出处:https://www.cnblogs.com/5201351/p/17958484
作者:一名卑微的IT民工
出处:https://www.cnblogs.com/5201351
本博客所有文章仅用于学习、研究和交流目的,欢迎非商业性质转载。
由于博主的水平不高,文章没有高度、深度和广度,只是凑字数,不足和错误之处在所难免,希望大家能够批评指出。
博主是利用读书、参考、引用、复制和粘贴等多种方式打造成自己的文章,请原谅博主成为一个卑微的IT民工!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号