基于Qlearning强化学习的水下无人航行器路径规划与避障系统matlab性能仿真
1.引言
水下无人航行器 (Autonomous Underwater Vehicle, AUV) 的路径规划与避障是海洋探索、资源开发和军事应用中的关键技术。传统的路径规划方法 (如A*、Dijkstra) 往往难以应对复杂多变的海洋环境,而强化学习 (尤其是Q-Learning) 因其无需精确环境模型、能在动态环境中自适应学习的特性,成为AUV路径规划的理想选择。
2.算法仿真效果演示
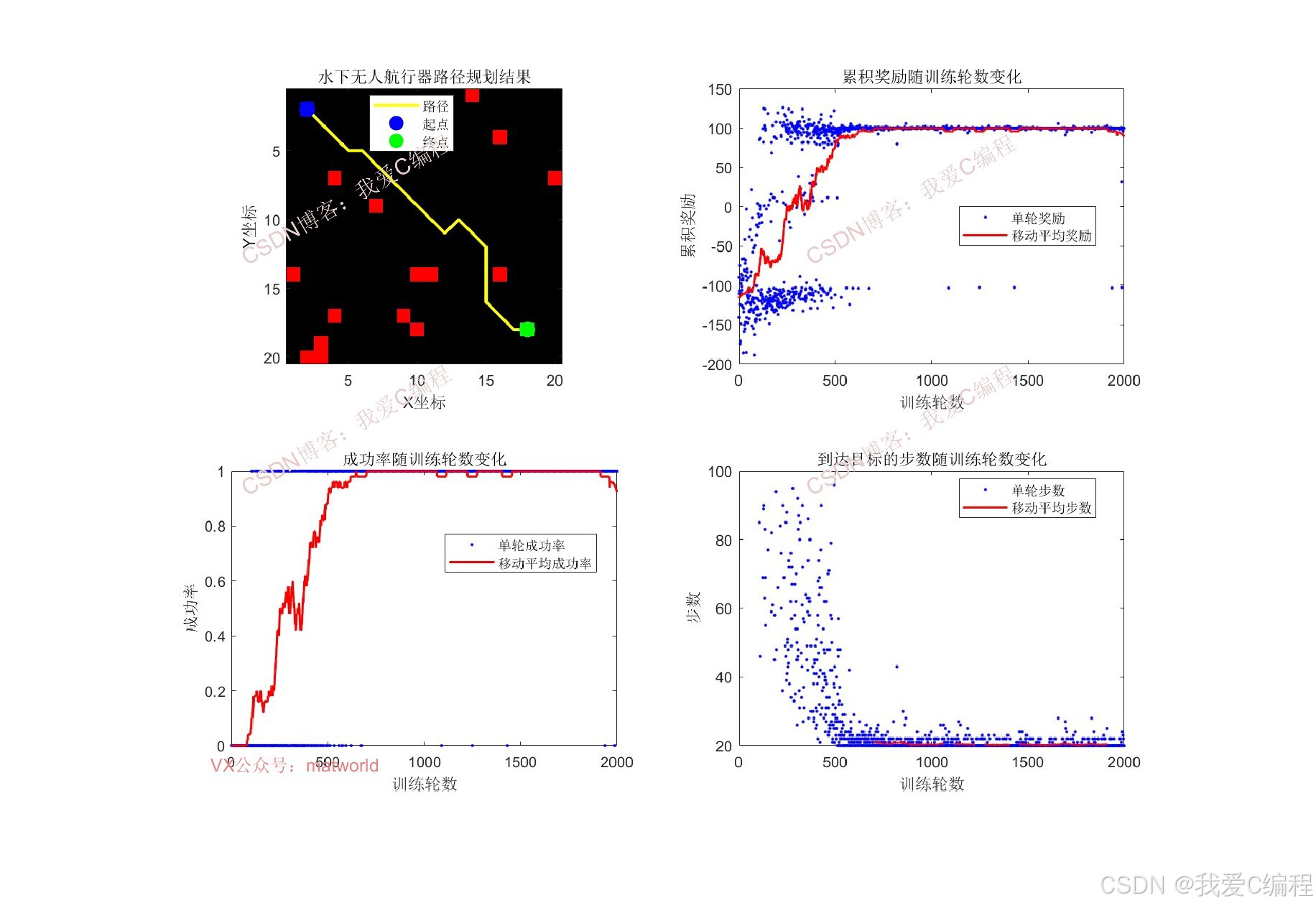
3.数据集格式或算法参数简介
%% 参数设置 gridSize = 20; % 环境网格大小 startPos = [2, 2]; % 起始位置 goalPos = [18, 18]; % 目标位置 numObstacles = 15; % 障碍物数量 maxEpisodes = 2000; % 训练轮数 maxSteps = 100; % 每轮最大步数 learningRate = 0.1; % 学习率 discountFactor = 0.99; % 折扣因子 explorationRate = 1.0; % 探索率 minExplorationRate = 0.01; % 最小探索率 explorationDecay = 0.995; % 探索率衰减率 0Z_023m
4.算法涉及理论知识概要
强化学习是一种通过智能体 (Agent) 与环境 (Environment) 交互来学习最优行为策略的机器学习方法。其核心要素包括:
智能体 (Agent):即 AUV,通过传感器感知环境状态并执行动作
环境 (Environment):即水下环境,包括障碍物、水流、目标位置等
状态 (State):智能体在环境中的当前情况表示,如位置、速度、障碍物分布等
动作 (Action):智能体可以执行的操作,如前进、转向等
奖励 (Reward):环境对智能体动作的反馈,用于评估动作的好坏
强化学习的目标是学习一个最优策略π*,使得智能体在环境中累积的长期奖励最大化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号